










一、常用的查询算法
1 顺序扫描法
将查询关键字与存储内容直接匹配,从第一条数据开始直到最后一条数据进行全表扫描,查询时间会随着数据增长越来越大
典型的场景:mysql中like模糊查询,因为无法使用索引会进行全表扫描
优点:语法简单,数据量小时,查询准确率高,误差小。
缺点:查询效率会随着数据增长越来越低。
2 倒排索引算法
存储时,会由分词器将数据内容进行且切分词,将分词与数据文档id形成索引目录,索引目录和文档内存分别进行存储,相当于将内容存储时还提炼出一部词典,记载了所有内存涉及到的分词以及包含该分词的所有文档id列表;
查询时,先将查询关键字在索引目录中进行匹配,匹配出分词,得到包含该分词的所有数据文档id,然后通过文档id反查出详细的数据内容。
就类似先查词典的目录,得到数据的位置,再查对应的数据内容详情,
因为常用的词语是有限的,词典的大小也就不会特别大,虽然文档内容可以无限大,但终归是由有限的词语重复构成的,所以只要保持机器性能足够,倒排索引查询效率不会随着文档内容增加越来越低。
典型的场景:es查询海量数据
优点:查询效率不会因为数据增长而越来越低
缺点:索引文件会占用额外的存储空间,典型的空间换时间的算法
二、全文索引的概念
全文索引是一种检索方式,其过程是在存储时先由检索程序扫描文档中每一个词,对词建立索引,记录词与文档的关系数据,然后在查询时,先根据索引查找出文档位置,再反查出文档详情。
全文检索是通过倒排索引算法实现的。
三、Lucene的概念
Lucene是一个全文检索引擎工具包,是个只提供了全文检索基础功能接口的jar包。
官网:https://lucene.apache.org
四、Lucene倒排索引数据结构
Lucene的数据结构包括物理结构和逻辑结构,物理结构叫做数据段,即Segment,数据段存储了真实保存的数据,而这些数据的逻辑结构主要是索引Index和文档Document,数据被分词器切分词后,分词被保存到索引库Index中,而数据被组装成文档Document。
新增数据时,当内存中的Segment对应缓冲区中的索引库和文档大小和数量达到阈值时,会将数据写入磁盘中的Segment文件,而当Segment的大小达到阈值时,会切片成多个Segment进行存储。
Lucene 查询很快的原因 主要是因为它的 倒排索引数据结构 ,以及索引库index中底层的关键字词典数据结构。
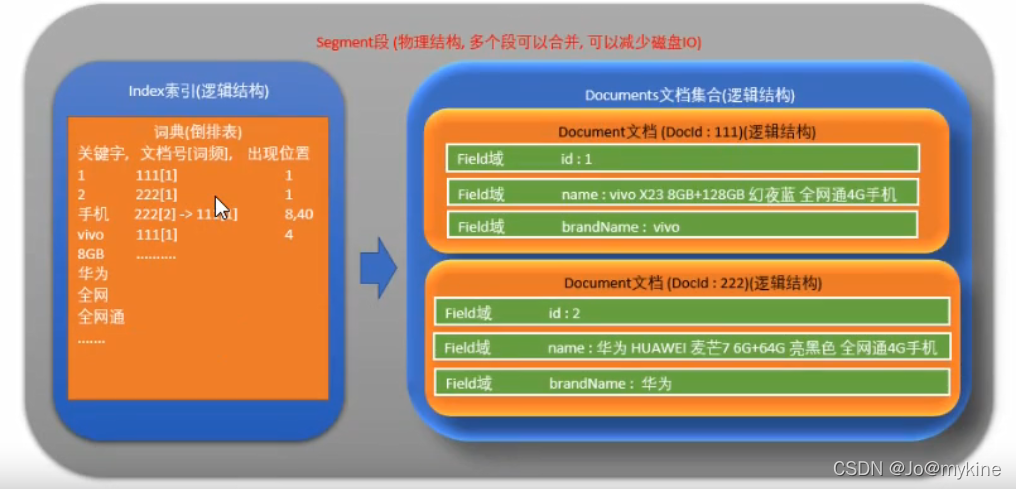
1 物理结构-数据段Segment
保存数据的物理文件,里面的数据包含Index索引库和文档Document两种逻辑结构。
2 逻辑结构-索引Index和文档Document
2.1 索引库Index
2.1.1 Index的内容
索引内容主要包含:
- 分词(即关键字)
- 文档编号
- 词频(在文档中出现的次数)
- 在文档中出现的位置
2.1.2 分词/关键字的底层数据结构
跳跃表
在lucene3以及之前使用的关键字字典数据结构就是跳跃表,跳跃表包含多个层级的链表,最底层的链表最长,包含了所有关键字节点,上面层级的链表是在下面的链表间隔若干节点形成的新链表,查询时,先查询上面的链表,当查不到时跳跃到下面的链表继续查询,直到所有层级的链表都查完,才会确认没有结果。
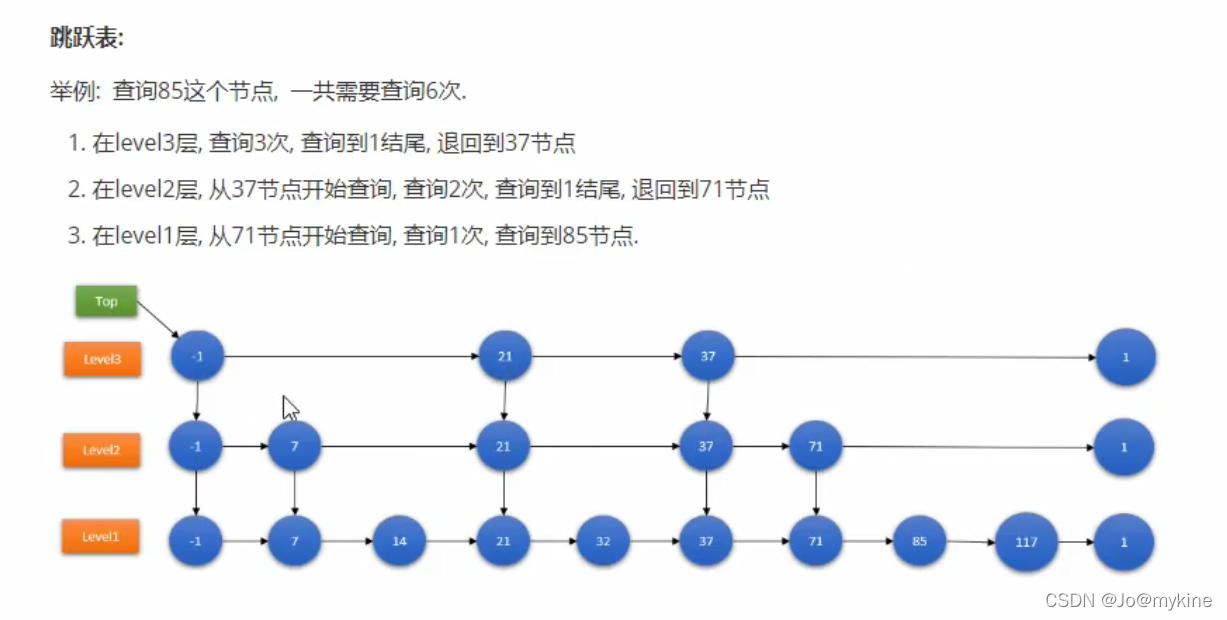
优点:结构简单、跳跃间隔、级数可控。
缺点:模糊查询支持不好
状态机结构FST
从Lucene4开始使用FST(Finite State Tranducer)的数据结构-有限状态转换机,它类似UML中状态机形状,将关键字拆分记录到路径节点上,相同的值共用同一个节点,FST比字典树trie更高级,trie只能共享前缀匹配,FST不仅共享前缀,还共享后缀,所以FST的存储更能节省空间。
FST在线测试工具:http://examples.mikemccandless.com/fst.py
FST特点:
1.词查找复杂度为O(len(str)),会从起点至某个终点,匹配状态链路
2.共享前缀、节省空间
3.内存存放前缀、磁盘存放后缀

优点:内存占用率低,压缩率一般在3~20倍之间,模糊查询支持好
缺点:结构复杂,输入要求有序,更新困难
2.2文档Document
文档内容结构
- 文档编号,类似mysql中的id
- filed,类似mysql中的字段
五、分词器Analyzer
分词器会对文档内容和搜索内容进行分词,并且过滤掉标点符号、停用词(即的、是、a、the等语气词、副词、介词、连接词等),最终切分成一个个分词。
1.使用分词器的时机
-
情景1:新增数据时,会将要保存的文档内容按照设置的Filed规则进行分词,将切分的词保存到索引库。
文本类型的filed一般是要分词的,纯数字类的filed(比如手机号、身份证号)一般是不用分词的 -
情景2: 搜索时,会将搜索关键字进行分词,切分成一个个语汇Token,用于匹配目标Filed的索引库中关键字,以便进行索引查询。
搜索时使用的分词器要和新增数据时的分词器保持一致,否则查询结果可能不如预期准确。
2.常用分词器
标准分词器StandardAnalyzer
属于Lucene自带的原生分词器的一种,支持中英文分词,但是对中文是单字分词,也就是一个汉字就认为是一个词。
空格分词器WhitespaceAnalyzer
属于Lucene自带的原生分词器的一种,支持英文分词,但不支持中文分词,本质就是只依据空格进行分词。
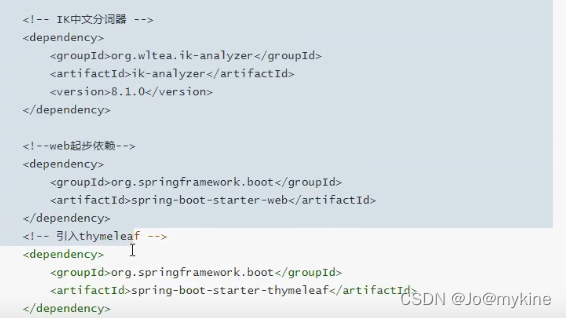
IK分词器IK-analyzer
属于第三方开发的分词器,支持中英文分词,并且对中文实现了语义化分词,虽然性能上稍有损失,但是企业级应用还是会使用它。
使用方法:
步骤一:pom文件中加依赖
<dependency>
<groupId>org.wltea.ik-analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.1.0</version>
</dependency>
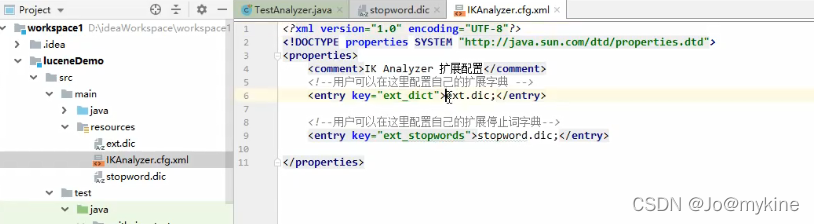
步骤二:在项目目录中附加扩展词典和停用词典
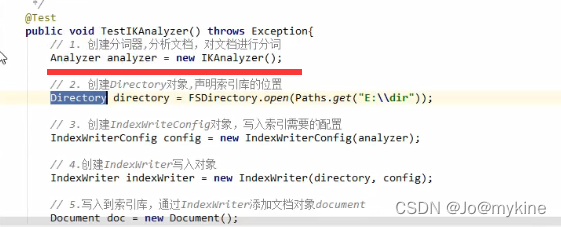
步骤三:在代码中使用IK分词器
五、CURD
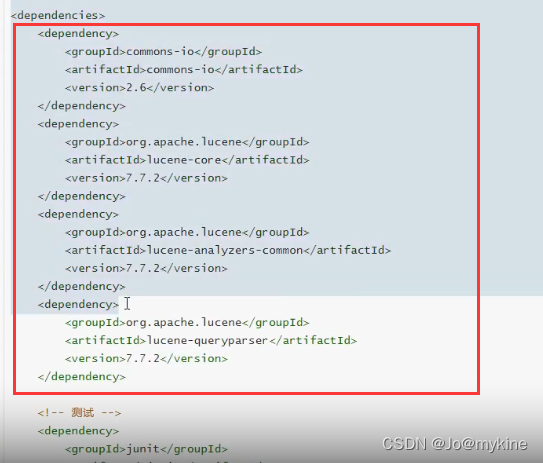
引入依赖
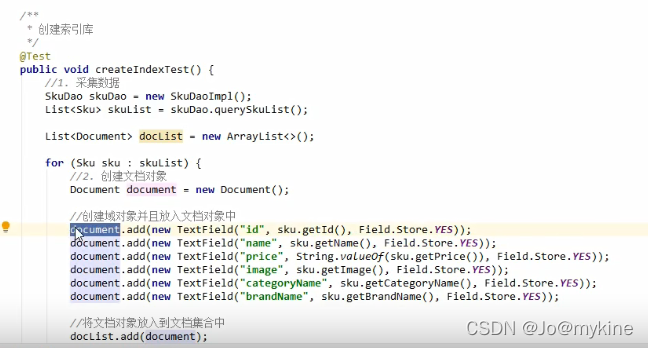
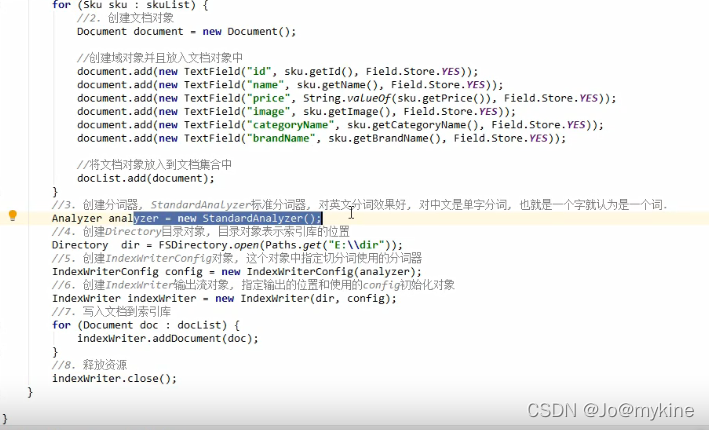
新增索引库和文档
通过设置Field类型和属性新增索引库和文档
Filed属性
新增数据时要设置Filed的属性,主要有 是否分词、是否索引、是否存储等三大属性。

Filed常用类型
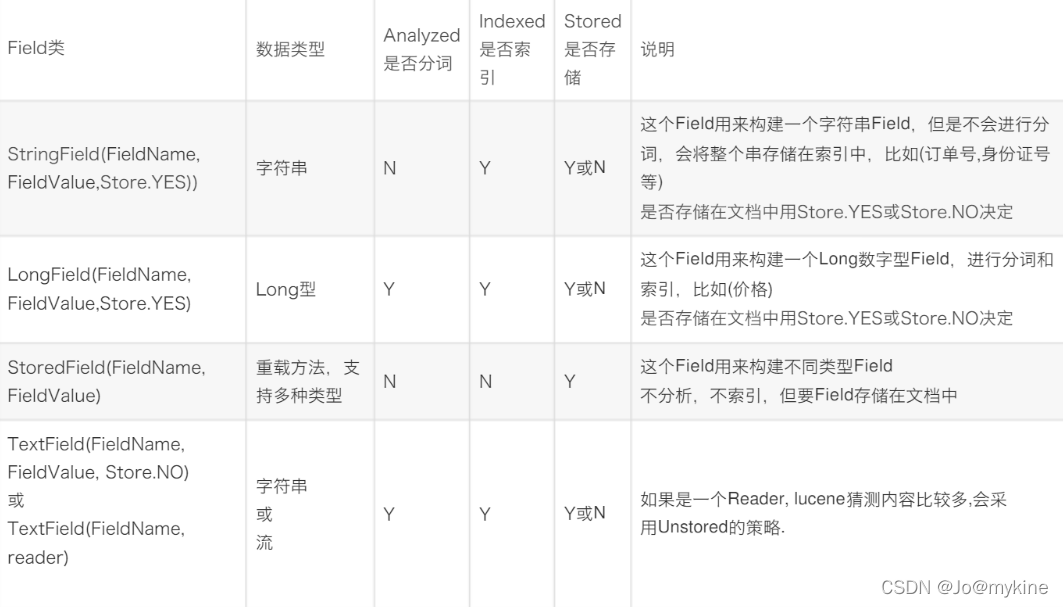
新增文档时设置filed类型
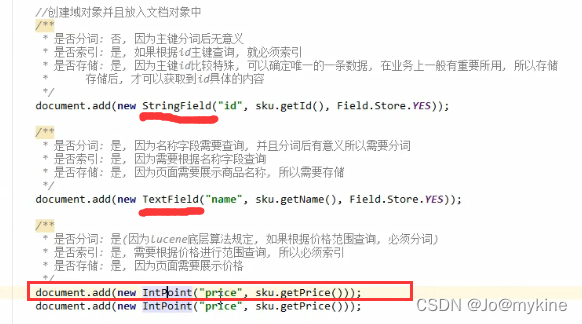
使用luke工具查看索引库和文档
下载luke-swing8工具
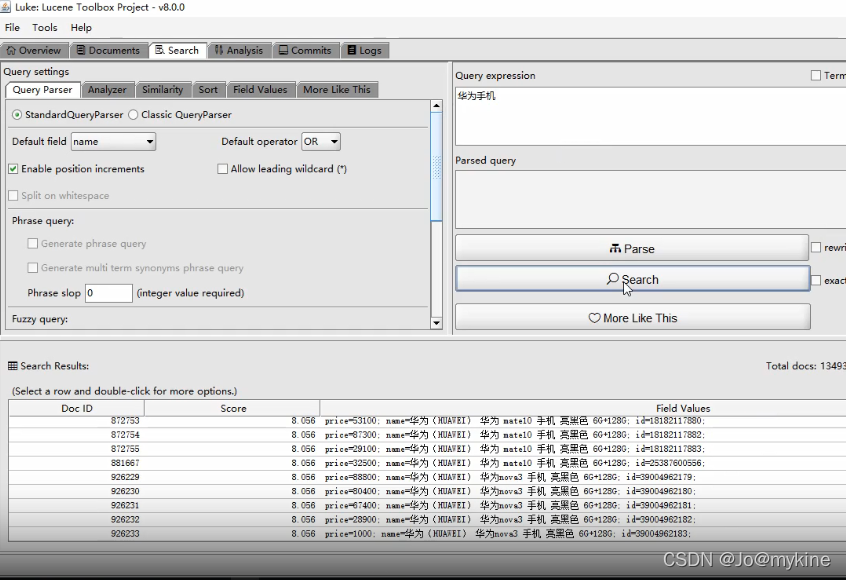
检索数据
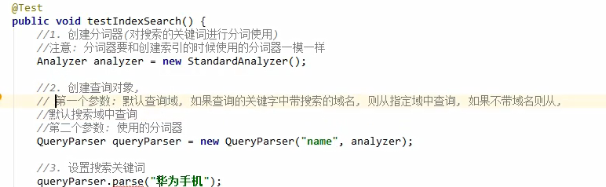
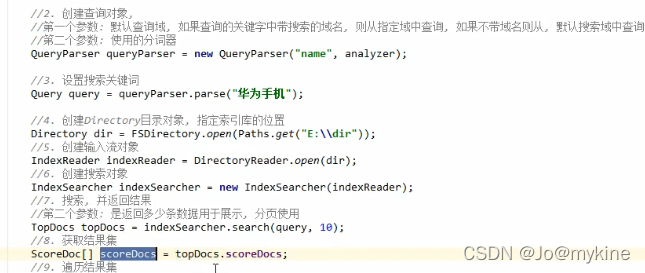
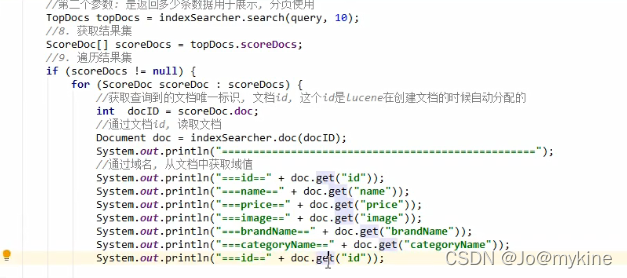
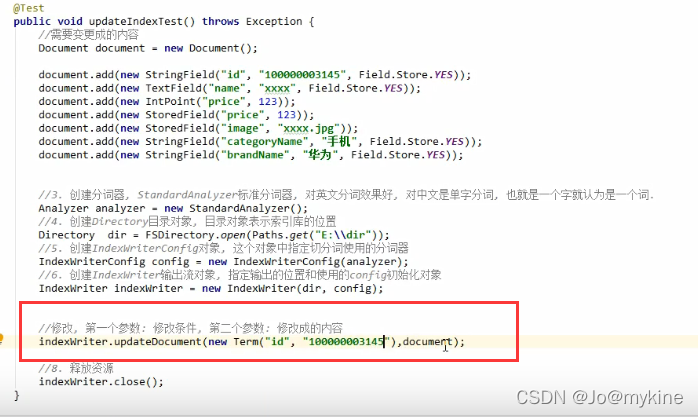
修改数据
lucene修改数据的本质是将原有数据删除,然后在尾部新增最新的数据。
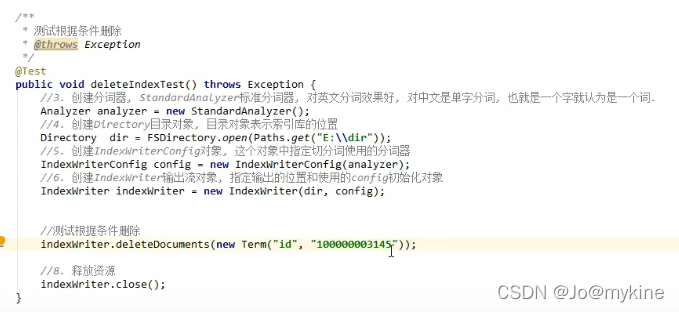
删除数据
六、优化
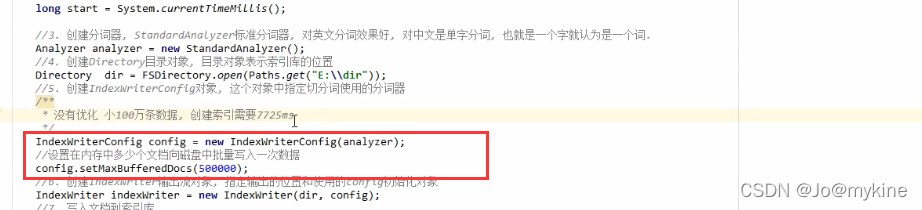
优化磁盘IO
增大配置项config.setMaxBufferedDocs(文档数量)
如果数据新增比较频繁,可以考虑通过配置内存缓冲区文档数量达到多大就写入磁盘segment文件中,通过加大内存的操作而降低刷盘次数,提高IO性能。
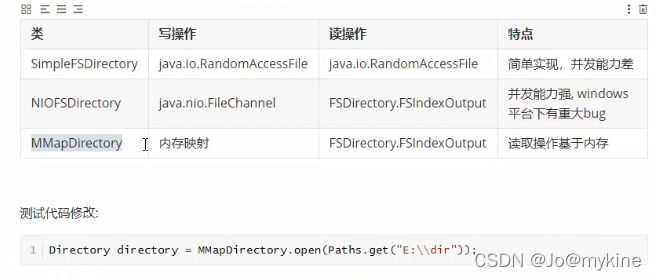
选择合适的存放位置
如果内存资源充足且运行稳定,可以考虑将索引库的读写操作都基于内存,使用MMapDirectory工具类。
七、存在的问题















 7205
7205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









