






最近一直在研究闲鱼的加密算法,无他,因为阿里的加密可以算是天花板级别的,研究和学习起来才值得。
很多人可能发现了,通过抓包得到的闲鱼数据包,sellerId等等值是加密过的。这就导致了很多人通过抓包或者协议请求得到的这部分数据很尴尬。
这个也是最近学习的研究的一个小成果了。展示:
1、先看下获取到的数据
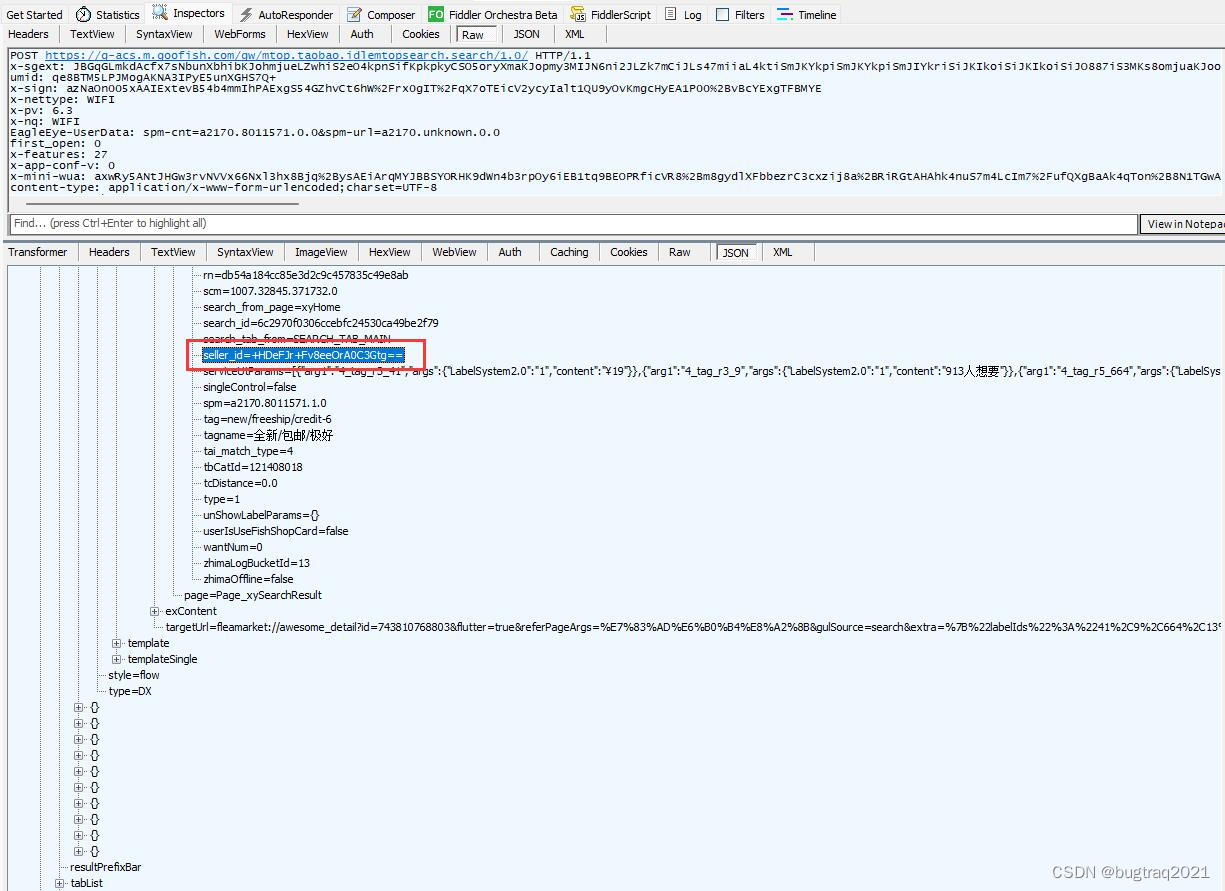
取一部分JSON数据看下:
{
"picWidth": "164.0",
"zhimaOffline": "false",
"item_type": "goods",
"disableHierarchicalSort": "0",
"pageSize": "10",
"type": "1",
"q_type": "0",
"search_from_page": "xyHome",
"tagname": "全新/包邮/极好",
"wantNum": "0",
"id": "743810768803",
"tag": "new/freeship/credit-6",
"keyword": "热水袋",
"scm": "1007.32845.371732.0",
"seller_id": "+HDeFJr+Fv8eeOrA0C3Gtg==",
"publishTime": "1697780498000",
"search_tab_from": "SEARCH_TAB_MAIN",
"picHeight": "164.0",
"cCatId": "126858768",
"biz_type": "item",
"tbCatId": "121408018",
"index": "0",
"spm": "a2170.8011571.1.0",
"catId": "50025402",
"original_q": "%E7%83%AD%E6%B0%B4%E8%A2%8B",
"p_type": "2",
"page": "1",
"position": "0",
"rn": "db54a184cc85e3d2c9c457835c49e8ab",
"tcDistance": "0.0",
"abid": "371732",
"singleControl": "false",
"cpvNavWlTbCatId": "121408018",
"layerInfo": "22845#0#371732#3_22845#14850#457261#25_22845#10269#438180#930_22845#12929#455236#30_22845#12961#449492#36_22845#12936#453772#56_22845#12926#460517#17_22845#12928#456216#51",
"item_id": "743810768803",
"oldZhima": "false",
"unShowLabelParams": "{}",
"userIsUseFishShopCard": "false",
"bucketid": "27",
"card_type": "idlefish_search_item_new_tags",
"search_id": "6c2970f0306ccebfc24530ca49be2f79",
"idle_mount_tai_task_abs": "0:T:1;768:T:0;793:T:0;130:T:0;487:C:0;592:C:0;467:T:0;573:T:0;123:T:0;350:T:0;505:T:0;965:C:0;1177:C:0;-10:C:1;353:T:0;892:T:0;1129:C:0;972:T:0;1181:T:0;193:T:0;370:T:0;-4:C:1;359:T:0;363:T:0;536:T:0;296:T:1;169:T:0;356:C:0;788:T:0;199:T:0;223:T:0;792:T:0;598:T:0;1134:T:0;126:T:0;517:T:0;542:T:0;470:T:0;593:T:0;551:T:0;194:T:0;543:T:0;225:T:0;552:T:0;500:T:0;226:T:0;366:T:0;933:T:0;1155:C:0;1156:T:0;558:T:0;1173:T:0;354:T:0;1075:T:0;514:T:0;244:T:0;893:T:0;969:T:0;227:T:0;1142:T:0;1185:T:0;361:T:0;368:T:0;789:C:0;766:T:0;797:T:0;466:T:0;533:T:0;493:C:0",
"q": "%E7%83%AD%E6%B0%B4%E8%A2%8B",
"CoinPay_Morediscount": "false",
"tai_match_type": "4",
"HideUserInfo": "false",
"serviceUtParams": "[{\"arg1\":\"4_tag_r3_41\",\"args\":{\"LabelSystem2.0\":\"1\",\"content\":\"¥19\"}},{\"arg1\":\"4_tag_r3_9\",\"args\":{\"LabelSystem2.0\":\"1\",\"content\":\"913人想要\"}},{\"arg1\":\"4_tag_r5_664\",\"args\":{\"LabelSystem2.0\":\"1\",\"content\":\"nfrIcon\"}},{\"arg1\":\"4_tag_r1_13\",\"args\":{\"LabelSystem2.0\":\"1\",\"content\":\"freeShippingIcon\"}}]",
"labelBucketId": "13",
"zhimaLogBucketId": "13"
}可见其中SellerId部分数据,采用了一种类似Base64加密的字符串展示。
但试过的人都知道,这并不是简单的Base64加密。
2、展示效果:
Java实现,看界面就是大家都很熟的IDEA啦
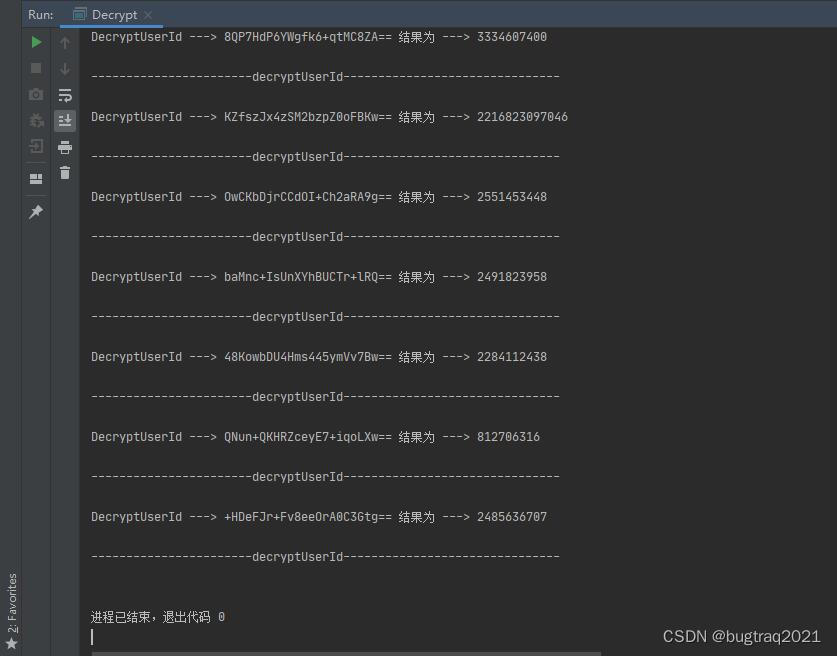
撒花!!!
继续去学习了。

















 8469
8469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









