







其他部分同 7.7赫夫曼树应用解析(叶子到根逆向求每个字符的赫夫曼编码)的编码,只更改HuffmanCoding函数来实现:如下
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
/************************************************************************/
// 求解赫夫曼编码 /************************************************************************/ void HuffmanTreeCoding(HuffmanTree &HT, HuffmanCode &HC, int* w, int n) { // w存放n个字符的权值(均>0), 构造赫夫曼树,求出n个字符的赫夫曼编码HC if (n <= 1) return; int nNodes; // 总结点和 int nodeIndex; // 根结点序号 nNodes = 2 * n - 1; HT = (HuffmanTree)malloc( sizeof(HTNode) * (nNodes+ 1) ); // 0号单元未用 HuffmanTree pTree; pTree = HT+ 1; for (nodeIndex= 1; nodeIndex <= n; ++nodeIndex,++pTree, ++w) { pTree->weight = *w; pTree->parent = 0; pTree->lchild = 0; pTree->rchild = 0; } for ( ; nodeIndex <= nNodes; ++nodeIndex, ++pTree) (*pTree).parent = 0; // 创建赫夫曼树 int minIndex1, minIndex2; for (nodeIndex = n+ 1; nodeIndex <= nNodes; nodeIndex++) // 循环n-1次 { // 在HT[1~nodeIndexs-1]中选择parent为0且weight最小的两个结点,其序号分别为minIndex1,minIndex2 Select(HT, nodeIndex- 1, minIndex1, minIndex2); HT[minIndex1].parent = HT[minIndex2].parent = nodeIndex; HT[nodeIndex].lchild = minIndex1; HT[nodeIndex].rchild = minIndex2; HT[nodeIndex].weight = HT[minIndex1].weight + HT[minIndex2].weight; } HC = (HuffmanCode)malloc( (n+ 1)* sizeof( char*)); // 分配n个字符编码的头指针向量([0]不用) char* codingSize; codingSize = ( char*)malloc( sizeof( char) * n); // 分配求编码的工作空间 unsigned int c, cdlen; c = nNodes; cdlen = 0; for ( int i= 1; i <= nNodes; i++) HT[i].weight = 0; // 遍历赫夫曼时用作结点标识 while (c) { if (HT[c].weight == 0) { // 向左 HT[c].weight = 1; if (HT[c].lchild != 0) { c = HT[c].lchild; codingSize[cdlen++] = '0'; } else if (HT[c].rchild == 0) { // 登记叶子结点的字符编码 HC[c] = ( char*)malloc((cdlen+ 1) * sizeof( char)); codingSize[cdlen] = '\0'; strcpy(HC[c], codingSize); // 复制编码(串) } } else if (HT[c].weight == 1) { // 向右 HT[c].weight = 2; if (HT[c].rchild != 0) { c = HT[c].rchild; codingSize[cdlen++] = '1'; } } else { // HT[c].weight = 2, 退回 HT[c].weight = 0; c = HT[c].parent; --cdlen; // 退到父结点,编码长度减1 } } // // 从叶子到根逆向求每个字符的赫夫曼编码 // HC = (HuffmanCode)malloc( (n+1)*sizeof(char*)); // // // 分配n个字符编码的头指针向量([0]不用) // char* codingSize; // codingSize = (char*)malloc(sizeof(char) * n); // 分配求编码的工作空间 // codingSize[n-1] = '\0'; // 编码结束符 // // for (nodeIndex = 1; nodeIndex <= n; nodeIndex++) // { // 逐个字符求赫夫曼编码 // int pos; // unsigned int c, f; // pos = n - 1; // 编码结束位置 // // for (c=nodeIndex, f=HT[nodeIndex].parent; f != 0; c=f, f = HT[f].parent) // { // 从叶子到根逆向求编码 // if (HT[f].lchild == c) // codingSize[--pos] = '0'; // else // codingSize[--pos] = '1'; // // HC[nodeIndex] = (char*)malloc((n - pos) * sizeof(char)); // // 为第i个字符编码分配空间 // strcpy(HC[nodeIndex], &codingSize[pos]); // 从codingSize复制编码串到HC // } // } free(codingSize); // 释放工作区间 return; } |
输出结果:
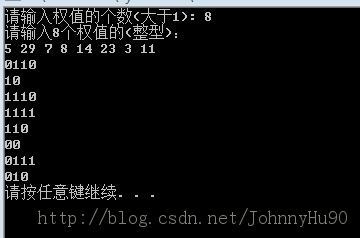















 4438
4438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









