







学习平台:B站
学习链接:python编程基础入门-廖雪峰_哔哩哔哩_bilibili
廖雪峰的官方网站:安装Python - Python教程 - 廖雪峰的官方网站
up主:放羊Wa
1)python的内置的数据结构类型
字符串:
字符串在python中有一个名字叫序列化。在C语言中,字符串是一串连续存储的字符,以"\0"作为结束符。('\'是转译符,'\0'代表acsii码为0的字符,也就是空字符)
python中的字符串本质也是同C,只是作为一个对象来处理,用法上类似C++中的string。
字符串的表示方法:
包括 单引号'、双引号"、三单引号'''、三单双引号"""。(python里面没有char类型了。这里三单引号可以允许字符串换行,这也就相当于加了一个\n,但是单引号是做不了这个事情的。)
c = '''3
'''
print(c)![]()
为什么要弄单双引号呢?这样他们可以互相转译,例如:(这样就不用转义符也可以了)
a = '"' # a = "\""
print(a)空字符串代表的事False。
ord()函数 是Python中的一个内置函数,它用于获取字符对应的ASCII码值。ASCII(American Standard Code for Information Interchange)是早期计算机系统使用的字符编码方案,它为每一个字符分配一个唯一的整数值。ord()函数接受一个单个字符作为参数,并返回其ASCII码值。例如:ord('A')。
chr()函数 是与ord()函数相对的另一个Python内置函数,用于将整数(ASCII码)转换为对应的字符。
字符串反斜杠字符串:
\n 其实是一类动作,而不是让人看见什么东西。 acsii从0到31都属于控制字符,也是不可见字符。
在windows下敲一个回车键,其实是两个符号,是\r + \n。
\' 单引号
\" 双引号
\n 换行
\a 响铃
\\ 一个反斜杠
\r 返回光标至行首
\f 换页
\t 水平制表符
\v 垂直制表符
\b 倒退光标
\0 空字符(字符的值为0)
\0xx 两位八进制表示的字符
\xXX 两位十六进制表示的字符
\uXXXX Unicode 16的十六进制字符
\UXXXXXXXX Unicode 32的十六进制字符
后两者C语言里面是没有的(C不支持 Unicode 字符集)。
raw字符(原始字符串):
转移字符的反用法,让转译失效。
格式:
r'字符串内容'(双引号、三单引号、三单双引号也是可用的)
b = r"\""python 3打印出来的内容为:\"。
字符串编码:
标准ASCII码,编码为0到127。
1个字节的表示就是 0 ~ 2**7 - 1。
一个字节的最高位是0(0b0xxxxxxx)
简体中文常用编码:GB2312,就是两个字节表示一个汉字,理论上可以表示出256×256。
Unicode:
之后出现了作为共同体的unicode,使用4个字节,可以容纳40亿的字符(可以查询unicode.org或者专门的汉字对应表 http://www.chi2ko.com/tool/CJK.htm 了解详情)。
汉字用的方案一般是gpk,而国际上用的更多的方案是utf-8。
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度 字符编码。 它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与 ASCII 相容,使得原来处理ASCII字符的软件无需或只进行少部分修改后,便可继续使用。
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification),是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容标准GB2312-80,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。
utf-8规则:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英文字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律视为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。

gb2312编码:
规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他就称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号,罗马希腊的字母,日文的假名们都编进去了,连在ASCII里本来就有的数字,标点,字母都统统重新编了两个字节长的编码,这就是常说的“全角”字符,而原来在127号以下那些就叫“半角”字符了。
GBK编码:
Chinese Internal Code Specification。只要一个字节是大于127就固定表示为一个汉字的开始,不管后面跟的是不是扩展字符集里面的内容。它包含了gb2312里有所有内容,并增加了近20000多个新的汉字和符号。但它和utf-8编码格式并不兼容。
如果在linux下推荐使用utf-8,如果在windows下推荐使用gbk(原本,现在似乎还是尽量utf-8)。
相互转换:
python源码中默认存储方式是ASCII码(现在python 3都是utf-8了,不过为了方便移植,加上好像也行)
代码中如果有中文,可以在python文件的开头写上:(注意,# 是要保留的哦,并且= 号两边不要空格)
# -*- coding: UTF-8 -*-
或者
# coding=utf-8
不是全都转为同一种,还可以在字符串前面加字母来表示,例如unicode可以加u,也就是u"XXX"。
python2 有第二种方法就是通过函数来做:
import sys
sys.setdefaultencoding('utf-8')
(但是python 3编译时会报错)
import sys
b = sys.getdefaultencoding()
print(b) # 得到的是 utf-8string = '\u4F60\u597D'
print(type(string))
print(string)
ustring = u'\u4F60\u597D'
print(type(ustring))
print(ustring)
gbkstring = ustring.encode("gbk")
print(type(gbkstring))
print(gbkstring)字符串处理:
隐式字符串拼接:
a = '123''456' = '123456'='123'+'456'
print("123","456") # 打印的是123456
字符串的运算:
+ +=(拼接)
* *=(乘以2就是把自身复制一遍)
> >=(排序是按照字典排序来的,长的不一定比短的大)
< <=
==(这可以直接比较了诶,比java方便些)
!=
a = 'ABC'
b = 'AC'
print(a > b)索引index:
字符串是不能改变的“字符”序列。(在C语言中,即使越界,也不会报错的,所以比较危险)
a = "1234567890"
a[3:6] = "456"
a[3:] = "4567890"
a[3::2] = "4680" # 步长为2
a[-1:] = "0"
a[-1:-9:1] = "" # 这里最后一项是步长
a[-1:-9:-1] = "09876543"
a[-1::-1] = "0987654321"
#aa[x:y:z] z表示步长,不能为0,z<0时,x为空时默认为-1,即最后一位,y为空时默认为-len(aa)-1,即正数第一位,所以[::-1]表示最后一位到第一位,即倒序。
常用字符串操作函数:
len(s) 返回长度
max(x) 返回序列的最大值的元素
min(x) 返回序列中最小值的元素
ord(s) 返回一个字符的编码值(ascii/ unicode值)
chr(i) 返回i这个值所对应的字符
bin(i) 将整数转换为二进制字符串
hex(i) 将整数转换为十六进制字符串
oct(i) 将整数转换为八进制字符串
str(x)
int(x)
float(x)
complex(x)
bool(x)
常用字符串方法:
S.isdigit() 判断字符串是否全为数字
S.isalpha() 判断字符串是否全为字符(英文字符)
S.islower() 判断字符串是否全为小写字符
S.isupper() 判断字符串是否全为大写字符
S.isspace() 判断字符串是否全为空白字符
S.isnumeric() 判断字符串是否为数字
S.cener(width[, fill]) 将原字符串居中,左右默认填充空格
S.count(sub[, start[, end]) 获取一个字符串中sub的个数
S.find(sub[, start[, end]) 获取字符串中sub的索引,失败返回-1
S.strip() 返回去掉左右空白字符的字符串
S.lstrip() left首字母
S.rstrip() right(右)
S.title() 生成每个英文单词首字符大写的字符串
S.upper() 生成将英文转为大写的字符串
S.lower() 生成将英文转为小写的字符串
S.replace(old, new[, count]) 将原字符串old用new代替,生成一个新的字符串
(注意,以上大多数函数得到的值是临时的,如果不赋值,不会改变原来的数)
字符串格式化:
生成一定格式的字符串,运算符为 %。
语法格式:
格式字符串 % 参数值
格式字符串 % (参数值1,参数值2,...)
示例:
fmt = "姓名:%s,年龄:%d"
name = "皮尔何"
age = 35
print( fmt % ( name , age ))
占位符:
%s 字符串
%r 字符串,使用repr()转义,而不是str()
%c 整数转为单个字符
%d 十进制整数
%o 八进制整数
%x 十六进制整数(字符a-f小写)
%X 十六进制整数(字符A-F大写)
%e 指数型浮点数(e小写),如2.9e+10
%E 指数型浮点数(E大写),如2.9E+10
%f,%F 十进制浮点数形式
%g,%G 十进制形式浮点或指数浮点自动转换
%% 等同于一个字符%
基于字典的字符串格式化:
" %(name)s 今年 %(age)d 岁 " % { "age": 35, "name": "皮尔何" }
占位符和类型码之间的格式语法:
- 号左对齐
+ 号右对齐(显示正负号)
0 补零
width 宽度
pricision 精度
练习:
关于python中的命名规范:
建议class用CamelCase(大驼峰),函数名用lower_case_with_underscores(下划线)

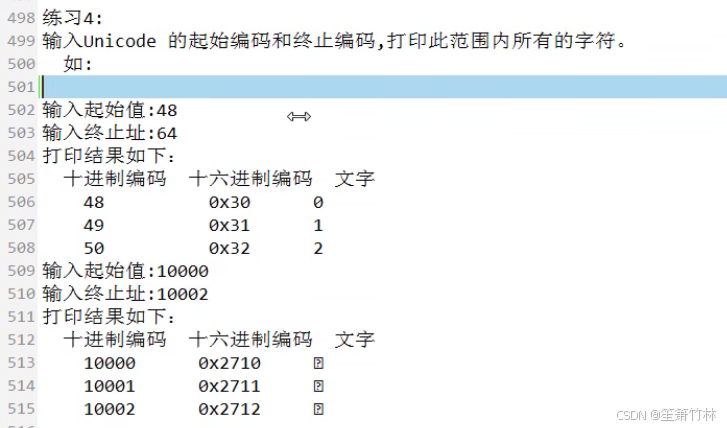

自己的练习,很潦草:
# 练习1
# len(s) # 返回长度
# max(x) # 返回序列的最大值的元素
# min(x) # 返回序列中最小值的元素
#
# ord(s) 返回一个字符的编码值(ascii/ unicode值)
# chr(i) 返回i这个值所对应的字符
#
# bin(i) 将整数转换为二进制字符串
# hex(i) 将整数转换为十六进制字符串
# oct(i) 将整数转换为八进制字符串
#
# str(x)
# int(x)
# float(x)
# complex(x)
# bool(x)
# s是字符串哦
def len_n(s):
count = 0
for i in s:
count += 1
print(count)
print("原本的"+str(len("1234")))
len_n("1234")
def max_n(s):
maxC = "\0"
for i in s:
if i > maxC:
maxC = i
print(maxC)
print("原本的"+str(max("12345")))
max_n("12345")
def ord_n(s): # 字符
# 存储ascii表,然后索引
return
def bin_n(s): # 转为二进制
# 每次先取余,然后除以2,再取余,循环往复,直到除数为0
return
print(ord("x"))
def str_n(s): # 类型转换
# 字符的编码为(utf-8编码方式:0xxxxxxx,或者110xxxxx 10xxxxxx,或者1110xxxx 10xxxxxx 10xxxxxx...)
# 整数类型的编码为(...)
# 不过这里用的是ascii码,不是unicode。这是这样子的话,不还是存储在这里吗?
return
# 练习2
# 判断字符串中单词的个数
def find(s):
count = 0
flag = 0
for i in s:
if (ord(i) >= 65 and ord(i) <= 90) or (ord(i) >= 97 and ord(i) <= 122):
flag = 1
if(ord(i) < 65 or (ord(i) > 90 and ord(i) < 97) or ord(i) > 122) and flag == 1:
count += 1
flag = 0
return count
print(find("Hello, I am a flower~"))

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









