







文章目录
leetcode-1498-Medium
1.题目
1498. 满足条件的子序列数目
2.思路
二分查找 + 快速幂
(1) 初步思路
从题意可以了解到,如果找到任意两个满足条件的最小和最大的数i和j,在[i, j]区间上,以i为左边界的任意子序列都满足题目要求,因此只要尽可能找到最大地区间[i, j]就可以确认所有满足题意的子序列数量。考虑使用二分查找(需要先排序),遍历序列nums,从最小的数i开始查找满足nums[i] + nums[j] <= target的数,因为我们要让[i, j]尽可能地大,即查找右边界,因此可以使用二分查找的右边界模板。
// 左边界模板
int l = 0, r = n - 1; // n是序列的长度
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid; // check(mid) 返回 true表示mid满足左边界条件
else l = mid + 1;
}
// 右边界模板
int l = 0, r = n - 1;
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid; // check(mid) 返回 true表示mid满足右边界条件
else r = mid - 1;
}
(2) 模拟过程
输入:nums = [3,3,6,8], target = 10
i = 0, nums[i] = 3 ⇒ 二分查找j = 2, nums[j] = 6
以i = 0为左边界,右边界在0~2之间,所有可能子序列的总数量为:2^2 = 4
i = 1, nums[i] = 3 ⇒ 二分查找j = 2, nums[j] = 6
左边界为1,右边界在1~2之间,所有可能子序列的总数量为:2^1 = 2
i = 2、3,二分查找结果不满足nums[i] + nums[j] < target
因此结果为6
(3) 存在的问题
二分查找之后确认每一组i和j之间的子序列数量,如果直接使用pow计算幂次,考虑题目中的提示:1 <= nums.length <= 10^5,结果可能会超出整型的范围,因此可以使用快速幂。
快速幂用于快速计算a ^ k % p的值,其时间复杂度为O(logk)
3.代码
int numSubseq(vector<int>& nums, int target)
{
sort(nums.begin(), nums.end());
int n = nums.size();
int i = 0, j = 0, mod = 1e9 + 7;
long long res = 0;
for (; i < n; i++)
{
// 二分查找j使得nums[i] + nums[j] <= target
int l = i, r = n - 1;
while (l < r)
{
int mid = l + r + 1 >> 1;
if (nums[mid] <= target - nums[i]) l = mid;
else r = mid - 1;
}
j = l;
if (nums[i] + nums[j] > target) break;
res = (res + quickPow(2, j - i, mod)) % mod;
}
return res;
}
int quickPow(int a, int k, int mod)
{
// 快速计算a ^ K % mod,时间复杂度O(logk)
long long res = 1, la = a;
while (k > 0)
{
if (k & 1) res = res * la % mod;
la = la * la % mod;
k >>= 1;
}
return res;
}
时间复杂度:先看循环内部,二分查找O(logn),快速幂O(logk),在此处k = j - i,即复杂度也为O(logn);数组大小为n,因此最终时间复杂度为O(nlogn)。
空间复杂度:排序递归需要消耗栈空间O(logn)
leetcode-528-Medium
1.题目
528. 按权重随机选择
2.思路
二分查找+前缀和
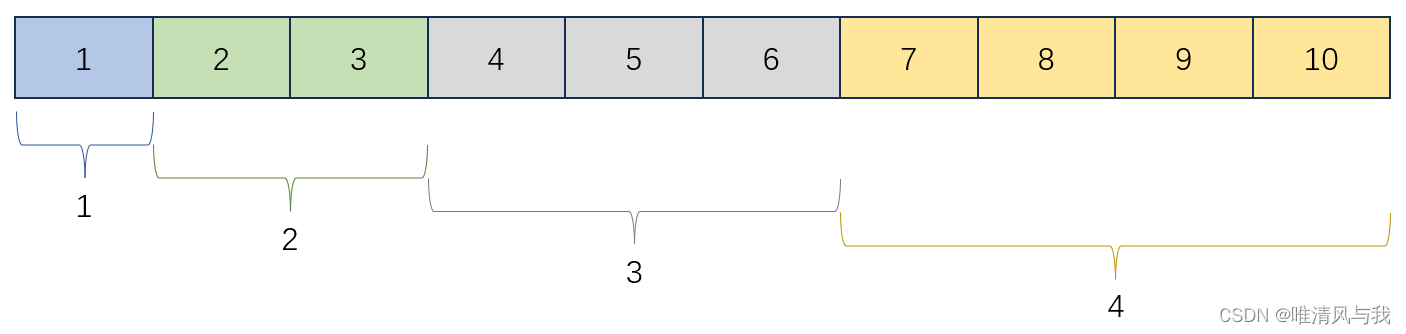
按照题意,每个下标的选取概率为该下标对应的w数组中权值占总权值和的比例。以w=[1, 2, 3, 4]为例,将权值以1为单位划分,依次排列成如下形式。我们只需要随机一个[1, sum(w)]之间的数,并且保证这个数能够均等概率地落在每一个格子上,就是符合题意地按权重随机选择。权值1对应的数为1,权值2对应的数有2、3,权值3对应的数有4、5、6,权值4对应的数有7、8、9、10,每个权值对应的数就是按w的前缀和数组W来划分的。因此我们可以随机选择[1, 10]之间的任意一个数i,查找i属于下图中的哪一块,也就是找前缀和数组W中第一个大于i的数(二分查找中的左边界模板,或者STL中的upper_bounds)。
3.代码
// leetcode_528
class Solution
{
vector<int> W;
public:
Solution(vector<int>& w)
{
W = w;
for (int i = 1; i < W.size(); i++)
{
W[i] = W[i - 1] + W[i];
}
}
int pickIndex()
{
int randint = rand() % W.back() + 1; // 1 ~ sum(w)
int l = 0, r = W.size() - 1;
while (l < r)
{
int mid = l + r >> 1;
if (W[mid] >= randint) r = mid;
else l = mid + 1;
}
return l;
}
};
时间复杂度:调用pickIndex函数使用二分,时间复杂度为O(logn)。
空间复杂度:需要存储前缀和数组W,因此空间复杂度为O(n)。
leetcode-4-Hard
1.题目
4. 寻找两个正序数组的中位数
2.思路
排序/归并/二分查找
两个数组找共同中位数,最直接的想法是合并然后排序,但是快排时间复杂度O(nlogn)不满足要求;数组有序,因此可以考虑归并或者二分。归并两个数组时间复杂度为O(m+n),也不满足题意,因此需要使用二分。
二分思路还是看题解吧,官方题解视频讲解很清晰:官方题解
简单理一下:
如果只是一个数组,我们可以很容易按照中位数将数组划分为两部分,奇数时假设中位数位于左侧:

两个数组其实也可以划分为左右两个部分,如下图所示,需要满足如下条件:(1)左侧所有数均小于右侧所有数;(2)两个数组总大小为偶数时 左侧个数=右侧个数,奇数时 左侧个数=右侧个数+1。

按上述条件划分,那么中位数一定存在于与分界线相邻的四个数中。当两个数组总数量为奇数,中位数为左侧部分中的最大数;偶数时,中位数为左侧部分的最大数与右侧部分的最小数的平均值。
假设两个数组分别为nums1、nums2,设i、j分别为两个数组在分界线右侧的数的下标。那么对于条件1,只要保证 nums1[i - 1] <= nums2[j] && nums1[i] >= nums2[j - 1] 即可;对于条件2,取左侧大小left = (n1 + n2 + 1) / 2,即向上取整即可。
比较条件已经确定了,那么怎么进行二分查找呢?
i、j分别对应nums1、nums2左侧的个数,因此i + j = (n1 + n2 + 1) / 2 = left ⇒ j = left - i,只要我们确定了其中一个数组的分界线,另一个数组的分界线也就确定了,那么选择哪一个数组来找分界线呢?
由于需要通过访问分界线两侧的数进行判断条件,因此如果我们通过找较长数组的分界线来确定较小数组的分界线,可能会导致j超出较小数组的范围,因此需要选择较小的数组来确定分界线。
3.代码
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2)
{
// 时间复杂度O(m+n)
// int n1 = nums1.size(), n2 = nums2.size();
// vector<int> nums(n1 + n2);
// int i = 0, j = 0, k = 0;
// while (i < n1 && j < n2)
// {
// if (nums1[i] <= nums2[j]) nums[k++] = nums1[i++];
// else nums[k++] = nums2[j++];
// }
// while (i < n1) nums[k++] = nums1[i++];
// while (j < n2) nums[k++] = nums2[j++];
// int mid = (n1 + n2) / 2;
// if ((n1 + n2) % 2 == 1) return nums[mid];
// else return (double)(nums[mid] + nums[mid - 1]) / 2;
// 二分,时间复杂度O(log(m+n))
int n1 = nums1.size(), n2 = nums2.size();
if (n1 > n2) return findMedianSortedArrays(nums2, nums1);
int left = (n1 + n2 + 1) >> 1; // 划分数组后左侧的大小,向上取整
int l = 0, r = n1;
while (l < r)
{
int i = l + r + 1 >> 1;
int j = left - i; // i、j分别为两个数组中分界线右侧的数下标,满足i+j = (n1 + n2 + 1) >> 1
// 分界线满足:nums1[i - 1] <= nums2[j] && nums1[i] >= nums2[j - 1]
if (nums1[i - 1] > nums2[j])
{
r = i - 1;
}
else l = i;
}
int i = l, j = left - i;
int nums1LeftMax = i == 0 ? INT_MIN : nums1[i - 1];
int nums1RightMin = i == n1 ? INT_MAX : nums1[i];
int nums2LeftMax = j == 0 ? INT_MIN : nums2[j - 1];
int nums2RightMin = j == n2 ? INT_MAX : nums2[j];
if ((n1 + n2) % 2 == 1) return max(nums1LeftMax, nums2LeftMax);
else return (double)(max(nums1LeftMax, nums2LeftMax) + min(nums1RightMin, nums2RightMin)) / 2;
}
时间复杂度:归并O(m+n),二分O(log(min(m,n)))
空间复杂度:归并O(m+n),二分O(1)
leetcode-649-Medium
1.题目
649. Dota2 参议院
2.思路
队列
原题中提到一点:“假设每一位参议员都足够聪明,会为自己的政党做出最好的策略”,那么这个最优策略是什么呢?
我们可以模拟一下整个流程,可以发现只要同一个阵营的参与员越先投票,该阵营优势就越大。因此在一轮投票过程中,当执行到某一个参议员a,而且此时a的权力没有被禁止,此时a前方的参议员都已投票完成,那么a就需要尽量限制a后面的敌对阵营,即优先禁止a后方最靠前的敌对阵营。
模拟每一轮投票,一轮完成后重组会议,当参议员不再发生改变,则某一阵营胜利。
3.代码
string predictPartyVictory(string senate)
{
int n = senate.size();
queue<char> q;
bool hasChange = true;
int preR = 0, preD = 0;
while (hasChange)
{
// 执行一轮
for (int i = 0; i < n; i++)
{
if (senate[i] == 'R')
{
if (preD > 0) preD--;
else q.push(senate[i]), preR++;
}
else
{
if (preR > 0) preR--;
else q.push(senate[i]), preD++;
}
}
// 重组会议
string tmp = "";
while (!q.empty()) tmp += q.front(), q.pop();
// 判断是否改变
hasChange = false;
if (tmp != senate)
{
hasChange = true;
n = tmp.size();
}
senate = tmp;
}
return senate[0] == 'R' ? "Radiant" : "Dire";
}
时间复杂度:O(n^2)
空间复杂度:O(n)
leetcode-443-Medium
1.题目
443. 压缩字符串
2.思路
双指针
注意原题的意思是在原数组原地压缩,然后返回压缩后的数组长度
如:[‘a’, ‘a’, ‘b’, ‘b’, ‘c’, ‘c’, ‘c’] ==> [‘a’, ‘2’, ‘b’, ‘2’, ‘c’, ‘3’, ‘c’] return 6
两个指针i和j,i指向已经完成压缩的部分的最后一位,j用于遍历原来的数组。
int dup–记录相邻同样的字符出现的次数,每次遇见不同的字符就重置
char pre–记录上一个字符串
每当chars[j]与pre不同时,先处理pre的重复次数dup,再将pre置为chars[j],并将pre存入压缩后的数组,dup重置为1

3.代码
int compress(vector<char>& chars)
{
char pre = chars[0];
int dup = 0, i = 0, j = 0;
auto handle = [&chars, &dup](int& i)
{
// 处理重复次数
int start = i;
while (dup > 0)
{
chars[i++] = '0' + dup % 10;
dup /= 10;
}
reverse(chars.begin() + start, chars.begin() + i);
};
while (j < chars.size())
{
if (j == 0 || chars[j] != pre)
{
// 处理重复次数
if (dup > 1) handle(i);
pre = chars[j];
dup = 1;
chars[i++] = pre;
}
else dup++;
j++;
}
// 处理重复次数
if (dup > 1) handle(i);
return i;
}
时间复杂度:O(n)
空间复杂度:O(1)
leetcode-2352-Medium
1.题目
2352. 相等行列对
2.思路
使用哈希表存储每一行出现的次数,然后遍历每一列,如果能在哈希表中找到该列,即出现相等行列对,然后对次数求和
哈希表的key可以是字符串,也可以是数组。
C++中map使用红黑树实现,可以将vector作为键;但是unordered_map的原理是哈希表,C++没有默认对vector哈希的方法
3.代码
int equalPairs(vector<vector<int>>& grid)
{
int res = 0;
int n = grid.size(), m = grid[0].size();
map<vector<int>, int> counts;
for (auto row : grid)
counts[row]++;
for (int j = 0; j < m; j++)
{
vector<int> tmp(n);
for (int i = 0; i < n; i++)
tmp[i] = grid[i][j];
if (counts.find(tmp) != counts.end())
res += counts[tmp];
}
return res;
}
时间复杂度:O(n^2)
空间复杂度:O(n^2)
leetcode-875-Medium
1.题目
875. 爱吃香蕉的珂珂
2.思路
二分查找
从题目中可以提取到的信息:珂珂吃完任意一堆,需要花 piles/k取上界 的时间
注意题目中的提示:

h最小为piles的大小,即当h=piles.length时,k最大能取到max(piles),因此k的取值范围是[1, max(piles)]。
从一个递增的范围内查找值,可以使用二分查找,而对于二分查找的判断条件,直接遍历piles计数后与h比较即可。
3.代码
int minEatingSpeed(vector<int>& piles, int h)
{
int l = 1, r = *max_element(piles.begin(), piles.end());
while (l < r)
{
int mid = l + r >> 1;
if (checkK(piles, mid, h)) r = mid;
else l = mid + 1;
}
return l;
}
bool checkK(vector<int>& piles, int k, int h)
{
int cnt = 0;
for (auto pile : piles)
{
cnt += pile / k + (pile % k == 0 ? 0 : 1);
}
return cnt <= h;
}
时间复杂度:O(nlog(m)),其中n为piles的大小,m为k的取值范围大小
空间复杂度:O(1)
leetcode-1657-Medium
1.题目
1657. 确定两个字符串是否接近
2.思路
(1) 初步思路
两个字符串,只需要满足:
条件1–长度相同;
条件2–保证出现的字符串完全相同;
条件3–从小到大将字符出现的次数排列,两个字符串得到的结果相同,那么通过题目中的两个操作,这两个字符串就可以转换为相同的字符串。
具体方法是:
通过一个map记录word1中出现的字符以及次数;
遍历map将次数存入word1的数组cnt1,然后将map中所有次数清零;
再将word2中出现的字符及次数存入map,此时如果出现map中没有记录的字符,那么条件2不满足,返回false;
遍历map将次数存入word2的数组出cnt2;
将cnt1、cnt2排序,如果cnt1与cnt2相同,则返回true,否则false
(2) 改进
原题的提示中提到字符串中只存在小写字母,那么可以将cnt1和cnt2的大小指定为26,那么就不再需要map统计次数了;为了满足条件2,只需要在cnt1和cnt2排序前遍历两个数组保证下标从0~25的数组都是非零或零即可。
3.代码
bool closeStrings(string word1, string word2)
{
// if (word1.size() != word2.size()) return false;
// // 满足两个条件即可:
// // 条件1--出现在两个字符串中的字符相同
// // 条件2--字符的重复次数组成的数组是相同的
// vector<int> cnt1, cnt2;
// map<char, int> cnts;
// for (auto c : word1) cnts[c]++;
// for (auto iter = cnts.begin(); iter != cnts.end(); iter++)
// {
// cnt1.push_back(iter->second);
// iter->second = 0;
// }
// for (auto c : word2)
// {
// if (cnts.find(c) != cnts.end()) cnts[c]++;
// else return false;
// }
// for (auto iter = cnts.begin(); iter != cnts.end(); iter++)
// cnt2.push_back(iter->second);
// sort(cnt1.begin(), cnt1.end());
// sort(cnt2.begin(), cnt2.end());
// return cnt1 == cnt2;
// 改进,注意提示中提到字符串中仅有小写字母,因此可以指定存储次数的数组大小为26,省去使用map的步骤
if (word1.size() != word2.size()) return false;
vector<int> cnt1(26), cnt2(26);
for (auto c : word1) cnt1[c - 'a']++;
for (auto c : word2) cnt2[c - 'a']++;
for (int i = 0; i < 26; i++)
{
if ((cnt1[i] == 0 && cnt2[i] != 0) || (cnt1[i] != 0 && cnt2[i] == 0))
return false;
}
sort(cnt1.begin(), cnt1.end());
sort(cnt2.begin(), cnt2.end());
return cnt1 == cnt2;
}
时间复杂度:O(max(n1, n2) + ClogC),n1为word1的长度,n2为word2的长度,C=26
空间复杂度:O©
leetcode-236-Medium
1.题目
236. 二叉树的最近公共祖先
2.思路
(1) 栈模拟dfs
使用dfs的顺序遍历二叉树,当第一次遇到p或q时,标记该节点为待选祖先节点。如果该节点出栈时还没有遇到第二个p或q,那么将它的父节点设置为待选祖先节点;当第二次遇到p或q时,返回栈中待选祖先节点即可
使用栈模拟dfs,需要一个标志记录栈中节点该处理左节点还是右节点,这里使用int,0–左孩子入栈,1–右孩子入栈,2–左右都入栈,该节点出栈。

假设p=6,q=0,模拟过程如下:


可以看到,第二次遇到p/q时的待选祖先节点是3,也即是正确的结果
(2)递归dfs
题解
3.代码
// 栈模拟
typedef pair<TreeNode*, bool> plb;
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
int cnt = (root == p || root == q) ? 1 : 0;
stack<pair<plb, int>> st;
st.push(make_pair(make_pair(root, cnt > 0), 0));
TreeNode* res = new TreeNode();
while (!st.empty())
{
plb top = st.top().first;
if (top.first == nullptr)
{
st.pop();
continue;
}
if (st.top().second == 0) // 左节点
{
st.top().second++;
TreeNode* node = top.first->left;
st.push(make_pair(make_pair(node, (node == p || node == q) && !(cnt > 0)), 0));
cnt += (node == p || node == q) ? 1 : 0;
}
else if (st.top().second == 1) // 右节点
{
st.top().second++;
TreeNode* node = top.first->right;
st.push(make_pair(make_pair(node, (node == p || node == q) && !(cnt > 0)), 0));
cnt += (node == p || node == q) ? 1 : 0;
}
else // 左右子节点都已入栈,该节点出栈
{
st.pop();
if (cnt == 1 && top.second)
{
st.top().first.second = true;
}
else if (cnt == 2)
{
while (!st.top().first.second) st.pop();
res = st.top().first.first;
break;
}
}
}
return res;
}
// 递归
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
if (root == nullptr || root == p || root == q) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left == nullptr) return right;
if (right == nullptr) return left;
return root;
}
时间复杂度:O(n),n为二叉树的节点数,二叉树的每一个节点都可能会被访问
空间复杂度:O(n),最坏情况下二叉树是一条链,模拟栈/递归栈需要存储所有二叉树节点















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









