







MySQL数据库操作
连接数据库
import pymysql
#连接数据库
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="shenjun",db="s12day")
cur=conn.cursor()#创建游标
#操作数据库,插入数据
reCount=cur.execute('insert into students(name,sex,age,tel,nal) values(%s,%s,%s,%s,%s)',('jack','man',22,'15455','USA'))
reCount=cur.execute('insert into students(name,sex,age,tel,nal) values(%s,%s,%s,%s,%s)',('Morocco','woma',23,'15455','USA'))
conn.commit()#提交数据到数据库
cur.close()
conn.close()
print(reCount)查找数据
import pymysql
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="shenjun",db="s12day")
cur=conn.cursor()
reCount=cur.execute("select * from students")
# res=cur.fetchone()#(1, 'Jorocco', 'man', 25, '151515', None) 返回的是第一条数据
# res1=cur.fetchone()#(3, 'oldboy', 'mals', 40, '156515', None) 返回的是第二条数据
# allres=cur.fetchall()#返回所有的查找结果
manyres=cur.fetchmany(3)#返回3条结果
# print(res)
# print(res1)
# print(allres)
print(manyres)
conn.commit()#之前数据写到日志里了,但还没真正写到数据库,只有经历这一步才真正的写到数据库里了
cur.close()
conn.close()插入数据
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',passwd='shenjun',db='s12day')
cur = conn.cursor()
li =[
('sb','man',22,'15455','USA'),
('Jom','man',22,'15455','USA'),
]
reCount = cur.executemany('insert into students(name,sex,age,tel,nal) values(%s,%s,%s,%s,%s)',li)
conn.commit()
cur.close()
conn.close()
print(reCount)事务回滚
import pymysql
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="shenjun",db="s12day")
cur=conn.cursor()
reCount=cur.execute('insert into students(name,sex,age,tel,nal) values(%s,%s,%s,%s,%s)',('jack','man',22,'15455','USA'))
reCount=cur.execute('insert into students(name,sex,age,tel,nal) values(%s,%s,%s,%s,%s)',('Morocco','woma',23,'15455','USA'))
# conn.rollback()#回滚下这两条数据就不会插入表中,当你再插入新的数据时它的ID往后顺延两个
conn.commit()#之前数据写到日志里了,但还没真正写到数据库,只有经历这一步才真正的写到数据库里了
cur.close()
conn.close()redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
redis的操作
redis的连接
import redis
r=redis.Redis(host='192.168.49.128')#连接redis
r.set("id","20170812",ex=3)#存储数据时效性为3秒,
print(r.get("name").decode())#获取key为name的属性
print(r.get("id").decode())import redis
pool=redis.ConnectionPool(host='192.168.49.128',port=6379)#创建一个连接池,避免过多的开销
r=redis.Redis(connection_pool=pool)#连接redis
r.set("id","20170812")
r.setrange("id",2,"AA")#将id的值从2开始用"AA"替换
print(r.getrange("id",3,4))#获取id值的第三个到第四个字节的值,从0开始
print(r.get("id").decode())
r.set("ID",2017021)
print(r.strlen("name"))# 返回name对应值的字节长度(一个汉字3个字节)
print(r.incr("ID",1))#自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增,amount,自增数(必须是整数)
print(r.decr("ID",1))#自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减, amount,自减数(整数)
print(r.append("name","ok"))# 在redis name对应的值后面追加内容
#print(r.keys())redis的列表操作
import redis
pool=redis.ConnectionPool(host="192.168.49.128")
r=redis.Redis(connection_pool=pool)
#r.lpush("number",11,22,33)# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 保存顺序为: 33,22,11
# rpush(name, values) 表示从右向左操作
#r.lpushx("number",34)# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
#r.linsert("number","BEFORE",11,90)#在name对应的列表的某一个值前或后插入一个新值
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
#r.lset("number",3,"shenjun")# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
#r.lrem("number",33,10)# 在name对应的list中删除指定的值,注意删除的都是33
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
#print(r.lpop("number"))# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 rpop(name) 表示从右向左操作
#r.ltrim("number",1,15)# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
#r.rpoplpush("number","number1")# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边,列表不存在就创建
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
#r.brpoplpush("number","number1",1)#从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
#r.blpop(("number","number1"),1)# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
# r.brpop(keys, timeout),从右向左获取数据
print(r.lindex("number",3))#在name对应的列表中根据索引获取列表元素
print(r.llen("number"))#name对应的list元素的个数
print(r.lrange("number",0,-1))redis的集合操作
import redis
pool=redis.ConnectionPool(host="192.168.49.128")
r=redis.Redis(connection_pool=pool)
r.sadd("set1",12,3,45,67,67)# name对应的集合中添加元素
r.sadd("set2",121,3,45,67,23)
# r.sadd("dest",1,2)
# print(r.sdiff("set2","set1"))#在第一个name对应的集合中且不在其他name对应的集合的元素集合,即在set2中而不在set1中的元素的集合
# print(r.sdiffstore("dest","set1","set2"))#相当于把sdiff获取的值加入到dest对应的集合中,如有存在dest则会覆盖它
# print(r.smembers("dest"))# 获取name对应的集合的所有成员
#print(r.sinter("set1","set2"))# 获取多一个name对应集合的并集
#print(r.sinterstore("new","set1","set2"))# 获取多个name对应集合的交集,再讲其加入到dest对应的集合中,返回的是新集合的长度
#print(r.sismember("set1",90))# 检查value是否是name对应的集合的成员
#print(r.smove("set1","set2",12))#将集合set1中的12移动到集合set2中
#print(r.spop("set1"))# 从集合的右侧(尾部)移除一个成员,并将其返回
#print(r.srandmember("set2",3))# 从name对应的集合中随机获取 numbers 个元素并返回
#r.srem("set1",67)# 在name对应的集合中删除某些值
#print(r.sunion("set1","set2"))# 获取多个name对应的集合的并集
#print(r.sunionstore("newSet","set1","set2"))# 获取多个name对应的集合的并集并存储到newSet中
#print(r.scard("dest"))
#print(r.scard("set1"))#获取name对应的集合中元素个数import redis
pool=redis.ConnectionPool(host="192.168.49.128")
r=redis.Redis(connection_pool=pool)
r.zadd("orderedSet",n1=11,n2=22,n3=23,n4=45)# 在name对应的有序集合中添加元素
#print(r.zcard("orderedSet"))# 获取name对应的有序集合元素的数量
#print(r.zcount("orderedSet",5,33))# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
#print(r.zincrby("orderedSet","n1",2))# 自增name对应的有序集合的 value 对应的分数
'''
#print(r.zrange("orderedSet",0,2,desc=True,withscores=True))
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
'''
#print(r.zrank("orderedSet","n2"))# 获取某个值在 name对应的有序集合中的排行(从 0 开始) zrevrank从大到小排序
#r.zrem("orderedSet","n1")# 删除name对应的有序集合中值是values的成员
#print(r.zremrangebyrank("orderedSet",1,5))# 根据排行范围删除
#r.zremrangebyscore("orderedSet", 23, 45)#根据分数范围删除
#print(r.zscore("orderedSet","n3"))# 获取name对应有序集合中 value 对应的分数
#print(r.zinterstore("zset1",("orderedSet","zset2"),aggregate="MAX"))# 获取两个有序集合的交集并放入dest集合,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
print(r.zunionstore("zset1",("orderedSet","zset2"),aggregate="MAX"))# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAXredis的哈希操作
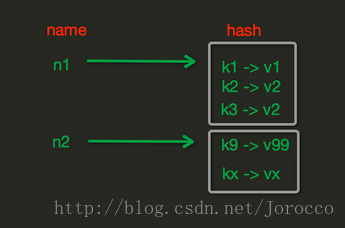
import redis
r=redis.Redis(host="192.168.49.128")
'''
哈希单个设置
'''
# r.hset("stu",id,2013112314)#name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# print(r.hget("stu",id))# 在name对应的hash中获取根据key获取value
'''
哈希批量设置
'''
# r.hmset("stu",{'s1':'13','s2':'14'})# 在name对应的hash中批量设置键值对
# print(r.hmget("stu",'s1','s2'))# 在name对应的hash中获取多个key的值
# print(r.hgetall("stu"))#获取name对应hash的所有键值
# print(r.hlen("stu"))# 获取name对应的hash中键值对的个数
# print(r.hkeys("stu"))# 获取name对应的hash中所有的key的值
# print(r.hvals("stu"))# 获取name对应的hash中所有的value的值
# print(r.hexists("stu","s1"))# 检查name对应的hash是否存在当前传入的key
# r.hdel("stu",id)# 将name对应的hash中指定key的键值对删除
# print(r.hincrby("stu","s1",2))#自增name对应的hash中的指定key的值,不存在则创建key=amount
'''
增量迭代式获取数据,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
'''
cursor1,data1=r.hscan("stu",match="s2")
cursor2,data2=r.hscan("stu",cursor=cursor1)
print(cursor2,data2)redis的其他模块操作
import redis
pool=redis.ConnectionPool(host="192.168.49.128")
r=redis.Redis(connection_pool=pool)
#r.delete("stu")#根据name删除redis中的任意数据类型
print(r.exists("stu"))#检测redis的name是否存在
print(r.keys(pattern="*"))#根据* ?等通配符匹配获取redis的name
r.expire("stu",1)# 为某个name设置超时时间
r.rename("set1","集合")# 重命名
#r.move("stu","db")#将redis的某个值移动到指定的db下
r.randomkey()#随机获取一个redis的name(不删除)
print(r.type("number"))redis的广播

redis的模块框架
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='192.168.49.128')
self.chan_sub = 'fm104.5'#订阅频道
self.chan_pub = 'fm88.7'#发布频道
def public(self, msg):
self.__conn.publish(self.chan_pub, msg)
return True
def subscribe(self):
pub = self.__conn.pubsub()#打开收音机
pub.subscribe(self.chan_sub)#调到那个台
pub.parse_response()#准备听
return pubredis的发布方(在安装有redis的虚拟机上)
import redis
r=redis.Redis()
r.publish("fm104.5","what the fuck")redis的订阅方
from redis_helper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response()#听
print(msg)RabbitMQ
发送端
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="192.168.49.128"))#阻塞式连接
channel = connection.channel()#生成一个管道
#声明queue
channel.queue_declare(queue='hello')#在管道里面创建一个队列
#n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')#在管道里面发送数据,exchange是路由转发,为空就是默认路由,routing_key是创建的队列
print(" [x] Sent 'Hello World!'")
connection.close()接收端
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="192.168.49.128"))
channel = connection.channel()
#You may ask why we declare the queue again ‒ we have already declared it in our previous code.
# We could avoid that if we were sure that the queue already exists. For example if send.py program
#was run before. But we're not yet sure which program to run first. In such cases it's a good
# practice to repeat declaring the queue in both programs.
channel.queue_declare(queue='hello')#channel.queue_declare(queue='hello',durable=True)这就是消息持久化,即使rabbitMQ重启也不会丢失消息,接收端也要这样写
def callback(ch, method, properties, body):#固定写法
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)#准备接收,callback是回调函数,当接收任务的时候会自动调用回调函数
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()#接收任务发布订阅
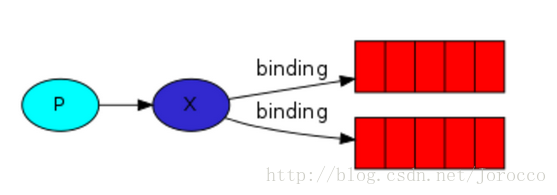
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
发布方
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="192.168.49.128"))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
exchange_type='fanout')#声明exchange,fanout是发给所有人
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()订阅方
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="192.168.49.128"))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
exchange_type="fanout")
result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)#绑定queue到exchange上
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()关键字发送
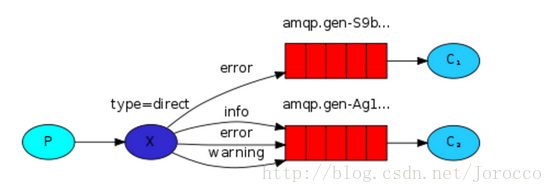
exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
发布方
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="192.168.49.128"))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()订阅方
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()模糊匹配
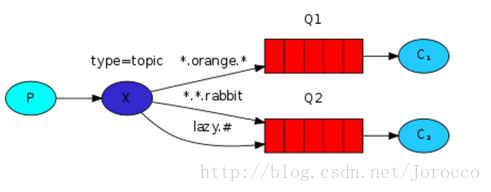
exchange type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
匹配规则

发布方
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="192.168.49.128"))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()订阅方
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host="192.168.49.128"))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()














 2691
2691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









