







一、hive方式映射数据
- 官方文档:mongo-hadoop官方文档
- 组件版本要求:
- Hadoop 1.X版本必须是1.2及以上版本
- Hadoop 2.X版本必须是2.4及以上版本
- Hive版本必须是1.1及以上版本
- 依赖的mongodb java dirver 版本必须是3.0.0及以上版本
- 依赖的jar包下载地址,根据需求选择不同版本:
- hive引入依赖jar包,以我的版本为例,在hiveCli窗口运行以下命令:
ADD JAR /path-to/mongo-hadoop-core-2.0.2.jar; ADD JAR /path-to/mongo-hadoop-hive-2.0.2.jar; ADD JAR /path-to/mongo-java-driver-3.9.1.jar;
- 使用list jars命令查看jar包是否加载成功,如下。
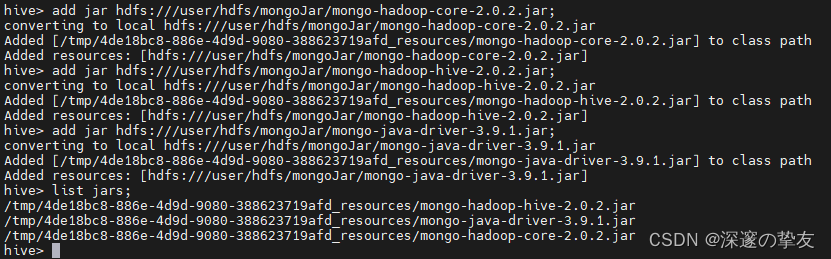
- 创建hive与mongodb表映射关系,模板如下:
CREATE [EXTERNAL] TABLE <tablename> (<schema>) STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler' [WITH SERDEPROPERTIES('mongo.columns.mapping'='<JSON mapping>')] TBLPROPERTIES('mongo.uri'='<MongoURI>'); 或 CREATE [EXTERNAL] TABLE <tablename> (<schema>) STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler' [WITH SERDEPROPERTIES('mongo.columns.mapping'='<JSON mapping>')] TBLPROPERTIES('mongo.properties.path'='HiveTable.properties');
-
使用mongo.columns.mapping选项指定对应关系,将 Hive列和Hive字段类型映射到MongoDB相应的表字段和类型。例如
mongo.columns.mapping'='{"id":"_id","work.title":"job.position","class":"class"},mapping左边对于hive的字段名,右边对应mongodb字段名,如hive字段和mongodb字段相同且符合hive命名规则,则可以不写。 -
建议创建表时使用EXTERNAL外部表的形式,因为hive表被删除时,只删除元数据,而底层的mongodb原数据保持不变;如果创建的是内部表,则删除hive表的同时会删除与hive表关联的元数据和底层的mongodb原数据。为防止误删等危险操作导致数据丢失,建议使用外部表。
-
参数mongo.uri为MongoDB的连接字符串,会将uri连接串存储在表中。如果你的连接串中包含凭据(例如用户名:密码)作为连接字符串的一部分进行传递时,建议使用参数mongo.properties.path指定定连接字符串在属性文件路径。
-
标准的mongo.uri为:
mongodb://[username:password@]host1[:port1][,...hostN[:portN]][/[defaultauthdb][?options]],详细了解可查看官网mongodb官网 -
对于mongodb的如果用户名或密码包含以下字符:
: / ? # [ ] @时,这些字符必须使用转换
百分比编码 ,提供转换工具 ,其实官网 也有对这种情况作出说明。
- 实例演示:
- mongodb数据库数据和字段
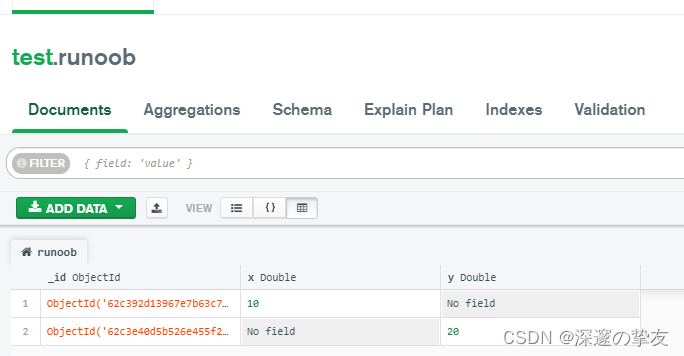
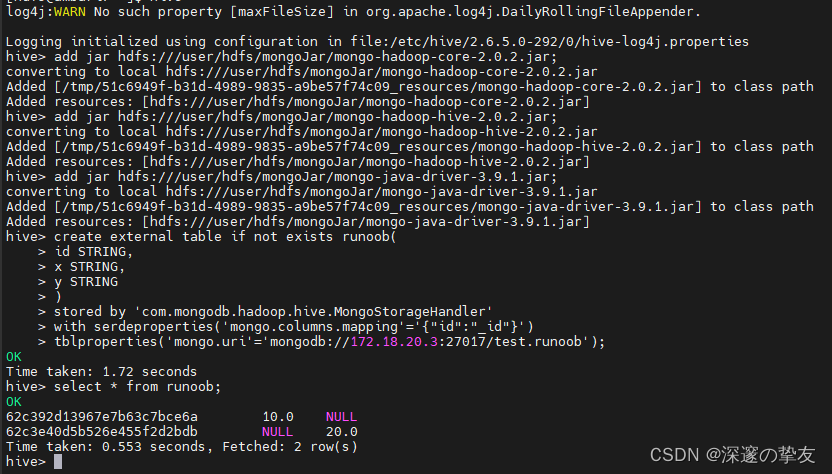
- 进入hiveCli窗口,执行以下命令:
add jar hdfs:///user/hdfs/mongoJar/mongo-hadoop-core-2.0.2.jar; add jar hdfs:///user/hdfs/mongoJar/mongo-hadoop-hive-2.0.2.jar; add jar hdfs:///user/hdfs/mongoJar/mongo-java-driver-3.9.1.jar; create external table if not exists runoob( id STRING, x STRING, y STRING ) stored by 'com.mongodb.hadoop.hive.MongoStorageHandler' with serdeproperties('mongo.columns.mapping'='{"id":"_id"}') tblproperties('mongo.uri'='mongodb://172.18.20.3:27017/test.runoob'); select * from runoob; - 执行结果如下,和mongodb数据库中的数据保持一致:
二、spark方式映射数据
官方文档:MongoDB Connector for Spark
一. 读取mongodb数据
spark读取mongodb数据的方式有java、scala和python等多种方式,可通过官网 自行学习,本文仅介绍python方式。
python方式需要使用pyspark 或者 spark-submit的方式进行提交。
- pyspark启动的方式,使用pyspark启动命令行:
# 根据自己的spark版本和scala版本选择,本地安装的spark版本为2.3.0,如果是其他版本需要修改版本号和scala的版本号 pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.0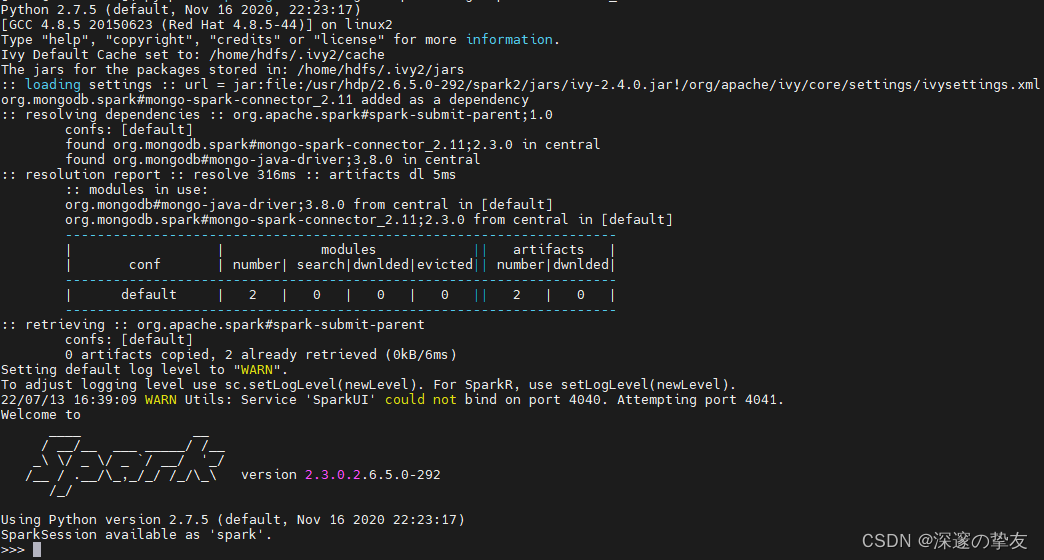
-
在pyspark shell脚本输入如下代码:
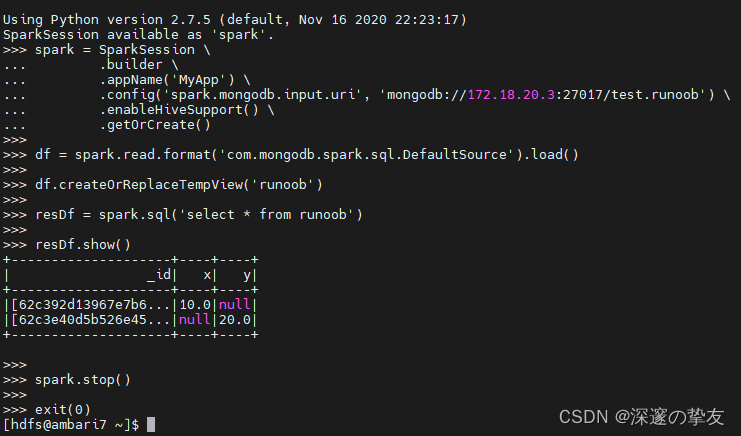
spark = SparkSession \ .builder \ .appName('mongodb') \ .config('spark.mongodb.input.uri', 'mongodb://172.18.20.3:27017/test.runoob') \ .enableHiveSupport() \ .getOrCreate() df = spark.read.format('com.mongodb.spark.sql.DefaultSource').load() df.createOrReplaceTempView('runoob') resDf = spark.sql('select * from runoob') resDf.show() spark.stop() exit(0) -
输出的结果和mongodb数据保持一致:
- spark-submit的方式启动
- 编写read_mongo.py脚本,脚本内容如下:
#!/usr/bin/python # -*- coding: utf-8 -*- from pyspark.sql import SparkSession if __name__ == '__main__': spark = SparkSession \ .builder \ .appName('mongodb') \ .config('spark.mongodb.input.uri', 'mongodb://172.18.20.3:27017/test.runoob') \ .enableHiveSupport() \ .getOrCreate() df = spark.read.format('com.mongodb.spark.sql.DefaultSource').load() df.createOrReplaceTempView('runoob') resDf = spark.sql('select * from runoob') resDf.show() spark.stop() exit(0) - spark-submit的方式提交命令,这里采用nohup提交方式,结果输出在log文件中
spark-submit \ --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.0 \ --num-executors 1 \ --executor-memory 512M \ --executor-cores 1 \ --master yarn \ --name read_mongo \ --conf spark.port.maxRetries=1000 \ read_mongo.py >> ./read_mongo.log &
二. 使用Schema约束读取mongo数据
- 采用pyspark的方式,在命令行中编写如下代码:
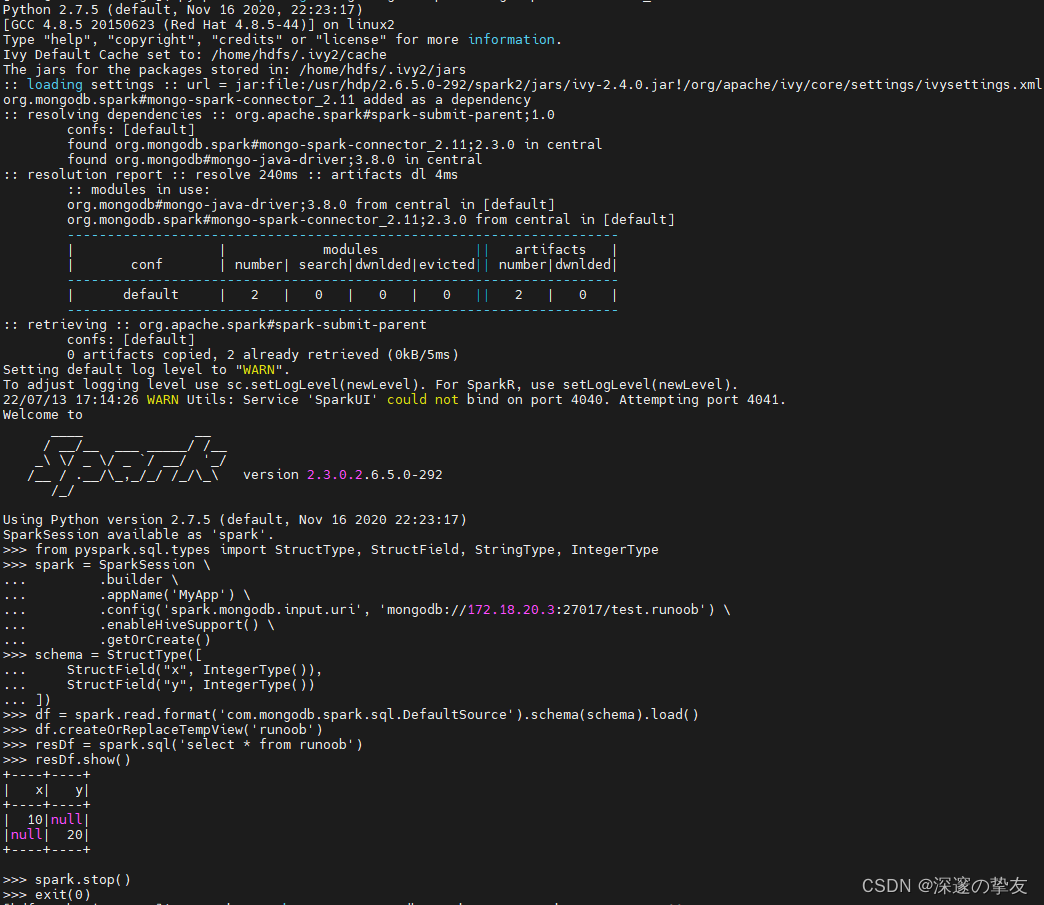
# 导入包 from pyspark.sql.types import StructType, StructField, StringType, IntegerType spark = SparkSession \ .builder \ .appName('mongodb') \ .config('spark.mongodb.input.uri', 'mongodb://172.18.20.3:27017/test.runoob') \ .enableHiveSupport() \ .getOrCreate() # 如果mongodb中的json字段太多,我们也可以通过schema限制,过滤掉不要的数据 # name 设置为StringType # age 设置为IntegerType schema = StructType([ StructField("x", IntegerType()), StructField("y", IntegerType()) ]) df = spark.read.format('com.mongodb.spark.sql.DefaultSource').schema(schema).load() df.createOrReplaceTempView('runoob') resDf = spark.sql('select * from runoob') resDf.show() spark.stop() exit(0)
- 输出的结果和mongodb数据保持一致:
三. 写入mongodb数据
-
采用pyspark的方式,在pyspark shell中编写如下代码:
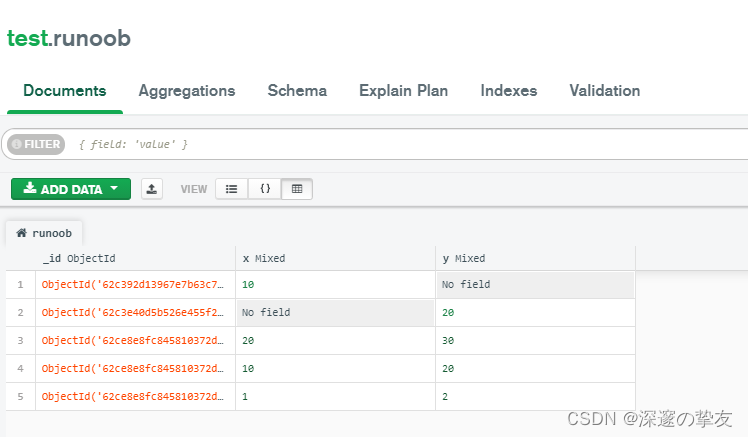
# 导入包 from pyspark.sql.types import StructType, StructField, StringType, IntegerType spark = SparkSession \ .builder \ .appName('mongodb') \ .config('spark.mongodb.output.uri', 'mongodb://172.18.20.3:27017/test.runoob') \ .enableHiveSupport() \ .getOrCreate() schema = StructType([ StructField("x", IntegerType()), StructField("y", IntegerType()) ]) df = spark.createDataFrame([(10, 20), (20, 30), (1, 2)], schema) df.show() df.write.format('com.mongodb.spark.sql.DefaultSource').mode("append").save() spark.stop() exit(0)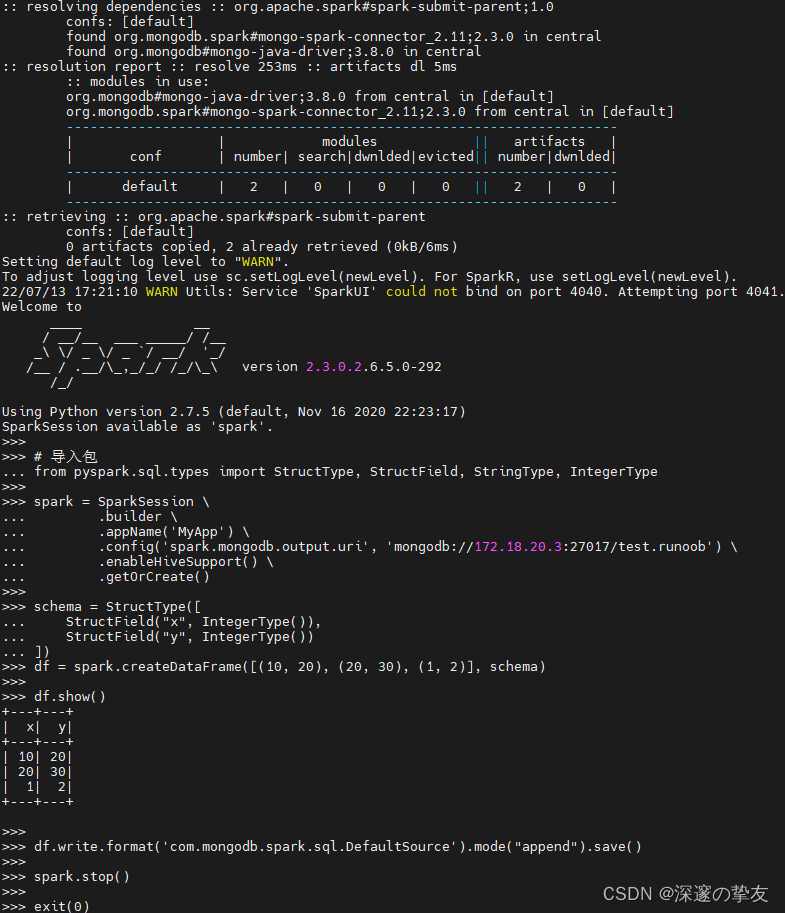
- 插入后的mongodb数据:
- spark-submit的方式启动
-
编写write_mongo.py脚本,脚本内容如下:
#!/usr/bin/python # -*- coding: utf-8 -*- from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StructField, StringType, IntegerType if __name__ == '__main__': spark = SparkSession \ .builder \ .appName('mongodb') \ .config('spark.mongodb.output.uri', 'mongodb://172.18.20.3:27017/test.runoob') \ .enableHiveSupport() \ .getOrCreate() schema = StructType([ StructField("x", IntegerType()), StructField("y", IntegerType()) ]) df = spark.createDataFrame([(10, 20), (20, 30), (1, 2)], schema) df.show() df.write.format('com.mongodb.spark.sql.DefaultSource').mode("append").save() spark.stop() exit(0) -
spark-submit的方式提交命令,这里采用nohup提交方式,结果输出在log文件中
spark-submit \ --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.0 \ --num-executors 1 \ --executor-memory 512M \ --executor-cores 1 \ --master yarn \ --name read_mongo \ --conf spark.port.maxRetries=1000 \ write_mongo.py >> ./write_mongo.log &
##四. 这里补充一个知识点
-
使用pyspark启动命令行:
pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.0 -
上面使用 —package的方式可以直接在代码中通过配置写入,另外,读取和写入可以在一个SparkSession 中进行操作,如下:
spark = SparkSession \ .builder \ .appName('mongodb') \ .config('spark.mongodb.input.uri', 'mongodb://172.18.20.3:27017/test.runoob') \ .config('spark.mongodb.output.uri', 'mongodb://172.18.20.3:27017/test.runoob') \ .config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.11:2.3.0') \ .enableHiveSupport() \ .getOrCreate() -
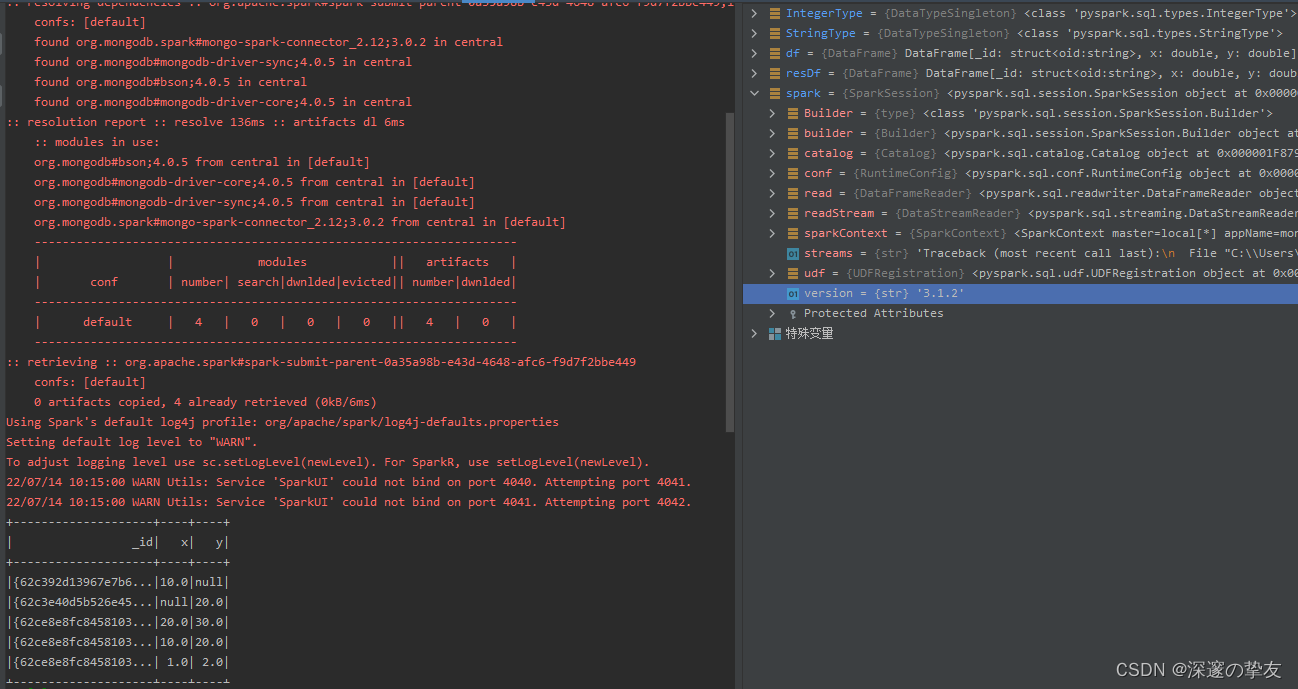
这样就可以直接在idea中进行脚本运行和断点测试了,但注意本地pyspark的版本,因我本地idea安装的pyspark版本为3.1.2,所以配置的jar包为
org.mongodb.spark#mongo-spark-connector_2.12;3.0.2,运行结果如下:














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









