







目标检测经典论文翻译汇总:[翻译汇总]
翻译pdf文件下载:[下载地址]
此版为纯中文版,中英文对照版请稳步:[Fast R-CNN中英文对照版]
Fast R-CNNRoss Girshick微软研究院rbg@microsoft.com |
摘要
本文提出了一种快速的基于区域的卷积网络方法(fast R-CNN)用于目标检测。Fast R-CNN建立在以前使用的深卷积网络有效地分类目标的成果上。相比于之前的研究工作,Fast R-CNN采用了多项创新提高了训练和测试速度,同时也提高了检测准确度。Fast R-CNN训练非常深的VGG16网络比R-CNN快9倍,测试时快213倍,并在PASCAL VOC上得到了更高的准确度。与SPPnet相比,Fast R-CNN训练VGG16网络比他快3倍,测试速度快10倍,并且更准确。Fast R-CNN的Python和C ++(使用Caffe)实现以MIT开源许可证发布在:https://github.com/rbgirshick/fast-rcnn。
1. 引言
最近,深度卷积网络[14, 16]已经显著提高了图像分类[14]和目标检测[9, 19]的准确性。与图像分类相比,目标检测是一个更具挑战性的任务,需要更复杂的方法来解决。由于这种复杂性,当前的方法(例如,[9, 11, 19, 25])采用多级pipelines的方式训练模型,既慢且精度不高。
复杂性的产生是因为检测需要目标的精确定位,这就导致两个主要的难点。首先,必须处理大量候选目标位置(通常称为“proposals”)。 第二,这些候选框仅提供粗略定位,其必须被精细化以实现精确定位。 这些问题的解决方案经常会影响速度、准确性或简洁性。
在本文中,我们简化了最先进的基于卷积网络的目标检测器的训练过程[9, 11]。我们提出一个单阶段训练算法,联合学习候选框分类和修正他们的空间位置。
结果方法能够训练非常深的检测网络(例如VGG16),其网络比R-CNN快9倍,比SPPnet快3倍。在运行时,检测网络在PASCAL VOC 2012数据集上实现最高准确度,其中mAP为66%(R-CNN为62%),每张图像处理时间为0.3秒,不包括候选框的生成(注:所有的时间都是使用一个超频875MHz的Nvidia K40 GPU测试的)。
1.1. R-CNN与SPPnet
基于区域的卷积网络方法(RCNN)[9]通过使用深度卷积网络来分类目标候选框,获得了很高的目标检测精度。然而,R-CNN具有明显的缺点:
1. 训练过程是多级pipeline。R-CNN首先使用目标候选框对卷积神经网络使用log损失进行fine-tunes。然后,它将卷积神经网络得到的特征送入SVM。这些SVM作为目标检测器,替代通过fine-tunes学习的softmax分类器。在第三个训练阶段,学习bounding-box回归器。
2. 训练在时间和空间上是的开销很大。对于SVM和bounding-box回归训练,从每个图像中的每个目标候选框提取特征,并写入磁盘。对于VOC07 trainval上的5k个图像,使用如VGG16非常深的网络时,这个过程在单个GPU上需要2.5天。这些特征需要数百GB的存储空间。
3. 目标检测速度很慢。在测试时,从每个测试图像中的每个目标候选框提取特征。用VGG16网络检测目标时,每个图像需要47秒(在GPU上)。
R-CNN很慢是因为它为每个目标候选框进行卷积神经网络前向传递,而没有共享计算。SPPnet网络[11]提出通过共享计算加速R-CNN。SPPnet计算整个输入图像的卷积特征图,然后使用从共享特征图提取的特征向量来对每个候选框进行分类。通过最大池化将候选框内的特征图转化为固定大小的输出(例如6×6)来提取针对候选框的特征。多输出尺寸被池化,然后连接成空间金字塔池[15]。SPPnet在测试时将R-CNN加速10到100倍。由于更快的候选框特征提取,训练时间也减少了3倍。
SPP网络也有显著的缺点。像R-CNN一样,训练过程是一个多级pipeline,涉及提取特征、使用log损失对网络进行fine-tuning、训练SVM分类器以及最后拟合检测框回归。特征也要写入磁盘。但与R-CNN不同,在[11]中提出的fine-tuning算法不能更新在空间金字塔池之前的卷积层。不出所料,这种局限性(固定的卷积层)限制了深层网络的精度。
1.2. 贡献
我们提出一种新的训练算法,修正了R-CNN和SPPnet的缺点,同时提高了速度和准确性。因为它能比较快地进行训练和测试,我们称之为Fast R-CNN。Fast RCNN方法有以下几个优点:
1. 比R-CNN和SPPnet具有更高的目标检测精度(mAP)。
2. 训练是使用多任务损失的单阶段训练。
3. 训练可以更新所有网络层参数。
4. 不需要磁盘空间缓存特征。
Fast R-CNN使用Python和C++(Caffe[13])编写,以MIT开源许可证发布在:https://github.com/rbgirshick/fast-rcnn。
2. Fast R-CNN架构与训练
Fast R-CNN的架构如图1所示。Fast R-CNN网络将整个图像和一组候选框作为输入。网络首先使用几个卷积层(conv)和最大池化层来处理整个图像,以产生卷积特征图。然后,对于每个候选框,RoI池化层从特征图中提取固定长度的特征向量。每个特征向量被送入一系列全连接(fc)层中,其最终分支成两个同级输出层 :一个输出K个类别加上1个包含所有背景类别的Softmax概率估计,另一个层输出K个类别的每一个类别输出四个实数值。每组4个值表示K个类别中一个类别的修正后检测框位置。
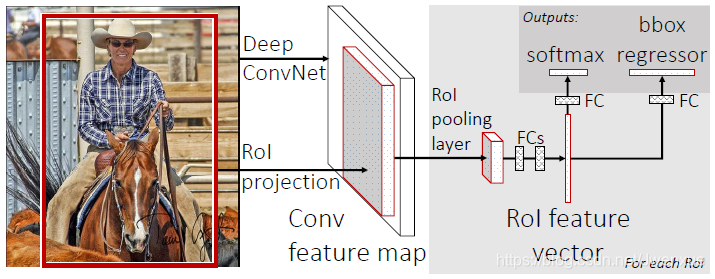
图1. Fast R-CNN架构。输入图像和多个感兴趣区域(RoI)被输入到全卷积网络中。每个RoI被池化到固定大小的特征图中,然后通过全连接层(FC)映射到特征向量。网络对于每个RoI具有两个输出向量:Softmax概率和每类bounding-box回归偏移量。该架构是使用多任务损失进行端到端训练的。
2.1. RoI池化层
RoI池化层使用最大池化将任何有效的RoI内的特征转换成具有H×W(例如,7×7)的固定空间范围的小特征图,其中H和W是层的超参数,独立于任何特定的RoI。在本文中,RoI是卷积特征图中的一个矩形窗口。每个RoI由指定其左上角(r,c)及其高度和宽度(h,w)的四元组(r,c,h,w)定义。
RoI最大池化通过将大小为h×w的RoI窗口分割成H×W个网格,子窗口大小约为h/H×w/W,然后对每个子窗口执行最大池化,并将输出合并到相应的输出网格单元中。同标准的最大池化一样,池化操作独立应用于每个特征图通道。RoI层只是SPPnets[11]中使用的空间金字塔池层的特例,其只有一个金字塔层。我们使用[11]中给出的池化子窗口计算方法。
2.2 从预训练网络初始化
我们实验了三个预训练的ImageNet [4]网络,每个网络有五个最大池化层和5至13个卷积层(网络详细信息见4.1节)。当预训练网络初始化fast R-CNN网络时,其经历三个变换。
首先,最后的最大池化层由RoI池层代替,其将H和W设置为与网络的第一个全连接层兼容的配置(例如,对于VGG16,H=W=7)。
然后,网络的最后一格全连接层和Softmax(其被训练用于1000类ImageNet分类)被替换为前面描述的两个同级层(全连接层和K+1个类别的Softmax以及特定类别的bounding-box回归)。
最后,网络被修改为采用两个数据输入:图像的列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









