







 本文详细介绍了深度优先搜索(DFS)和广度优先搜索(BFS)的基本概念,包括它们在括号生成、单词搜索、树的前序遍历和单词接龙等经典问题的应用。深度优先搜索是一种不断回溯的过程,适用于递归解决如括号生成、单词搜索等。而广度优先搜索则适用于寻找最短路径,如单词接龙问题。两种搜索方法在二叉树的层序遍历问题中也有重要应用。
本文详细介绍了深度优先搜索(DFS)和广度优先搜索(BFS)的基本概念,包括它们在括号生成、单词搜索、树的前序遍历和单词接龙等经典问题的应用。深度优先搜索是一种不断回溯的过程,适用于递归解决如括号生成、单词搜索等。而广度优先搜索则适用于寻找最短路径,如单词接龙问题。两种搜索方法在二叉树的层序遍历问题中也有重要应用。
所有文章放置于:https://github.com/zgkaii/CS-Notes-Kz,欢迎指正!
深度优先搜索
基本概念
深度优先搜索(Depth-First-Search,简称DFS)与是一种用于遍历或搜索树或图的算法,其执行过程类似于树的前序遍历。
其思想是,从图中某个顶点v出发尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
深度优先搜索是一个不断回溯的过程。
以下面有向图为例,假设根节点为0,则其深度优先遍历过程:
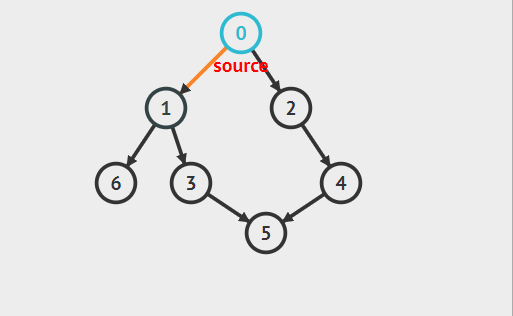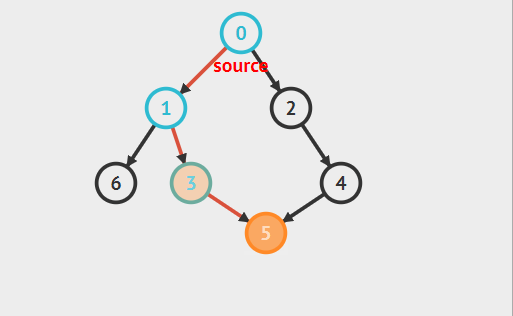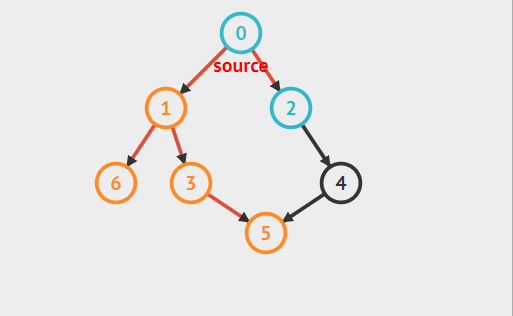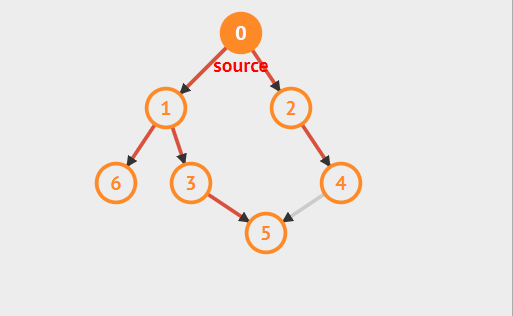
深度优先搜索实现方法
(1)首先将根节点放入stack中。
(2)从stack中取出第一个节点,并检验它是否为目标。如果找到目标,则结束搜寻并回传结果;否则将它某一个尚未检验过的直接子节点加入stack中。
(3)重复步骤2。
(4)如果不存在未检测过的直接子节点。将上一级节点加入stack中并重复步骤2。
(5)重复步骤4。
(6)若stack为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
经典举例
括号生成
以LeetCode. 括号生成为例,数字 n 代表生成括号的对数,需要设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
分析发现,括号生成求解过程正是一个满二叉树:
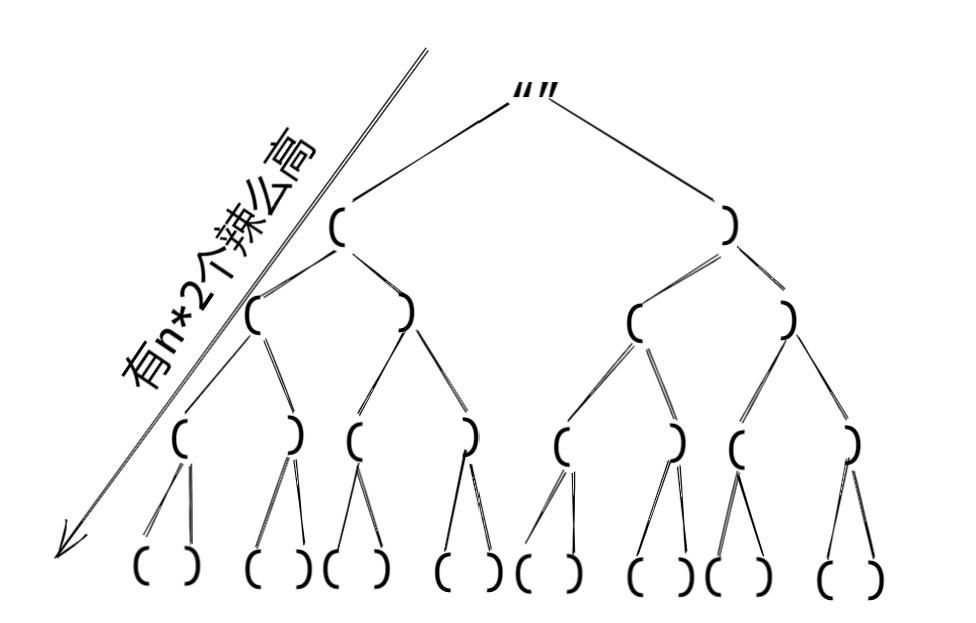
那么我们可以深度优先搜索出满足条件的值即可。
如果以left 代表左括号数量,right代表右括号数量,起始值left == right == 0。分析可知:
(1)当括号总数量n都大于0时,才能产生分支;
(2)只要left < n,就可以产生左分支;
(3)产生右分支的时候,受到左分支的限制。剩余右括号数量大于左括号剩余的数量的时,才能产生右分支(即right < left);
(4)当left/right数量都等于n时,说明搜索到一个满足条件的值。
将以上分析翻译为代码:
List<String> res = new ArrayList<>();
public List<String> generateParenthesis(int n) {
// (1)
if (n == 0) return res;
// 执行深度优先遍历
dfs(0, 0, n, "");
return res;
}
private void dfs(int left, int right, int n, String str) {
// (4)
if (left == n && right == n) {
res.add(str);
return;
}
// (2)
if (left < n) dfs(left + 1, right, n, str + "(");
// (3)
if (right < left) dfs(left, right + 1, n, str + ")");
}
单词搜索
以LeetCode. 单词搜索为例,给定一个二维网格和一个单词,找出该单词是否存在于网格中。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
这个问题使用回溯算法解决,涉及的知识便是深度优先遍历和状态重置。
以word = "ABCCED"为例,从board[0][0]开始,遍历匹配word[0]。匹配一个字符后,在borad上下左右4个方向搜索匹配word的下一个字符(注意board的边界条件,不要越界)。如果其中某一个方向不匹配,则回溯到上一步寻找新的方向,如果4个方向都不匹配,则返回false。
A --> B --> C (x) E
(x) (x) |
S F (x) C (x) S
|
A D <-- E (x) E (ture)
上例的搜索过程如下,这正是深度优先遍历:
A
/ \
S B
/ \
F C
/ \
E C
/ | \
F S E
/ \
E D(yes)
将之上分析翻译成代码:
public boolean exist(char[][] board, String word) {
char[] words = word.toCharArray();
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[0].length; j++) {
// 从下标(i, j)深度优先搜索
if (dfs(board, words, i, j, 0))
return true;
}
}
return false;
}
private boolean dfs(char[][] board, char[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4757
4757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









