







✨ 写在前面
🎃 哈喽大家好👋👋👋
🌱 作为一个初入编程的大学生,知识浅薄
🌱 写文章的同时也是在巩固自己,同时希望我的文章对你有所帮助!
🌱 我的其他文章
1.【数据结构】时间复杂度&&空间复杂度
2.【数据结构】顺序表接口实现及详解
2.【数据结构】带你手撕单链表!🌱 初入编程的世界 前方"路漫漫"🛣️ 每天我们都要进步一点点💧
🌱 希望分享知识的同时可以和你们一起进步🍻

![]()
🚀顺序表
缺点
- 头部或者中间插入数据需要挪动数据,时间复杂度高,效率低
- 扩容带来的问题:
1. 性能的消耗:
如果在需要扩容的空间的后面找不到足够大的空间,那么就会重新找一块空间(异地扩),
这种情况需要数据的拷贝,带来性能的消耗
2. 空间浪费:
如果扩容扩的太大会造成空间的浪费
优点
- 由下标可以进行随机访问
🚀链表
优点
- 任意位置插入位置都是O(1)
- 按需申请和释放,不存在扩容
缺点
- 不支持随机访问
🚀二者关系
可以看到 链表的优点对应的是顺序表的缺点
顺序表的优点也弥补了链表的缺点
二者是相辅相成的
🚀补充知识
- 顺序表的另一个优点
CPU高速缓存利用率高 - 链表的另一个缺点
CPU高速缓存利用率低
这是什么意思呢?
这设计到一些硬件的知识
我们首先来看一个图:
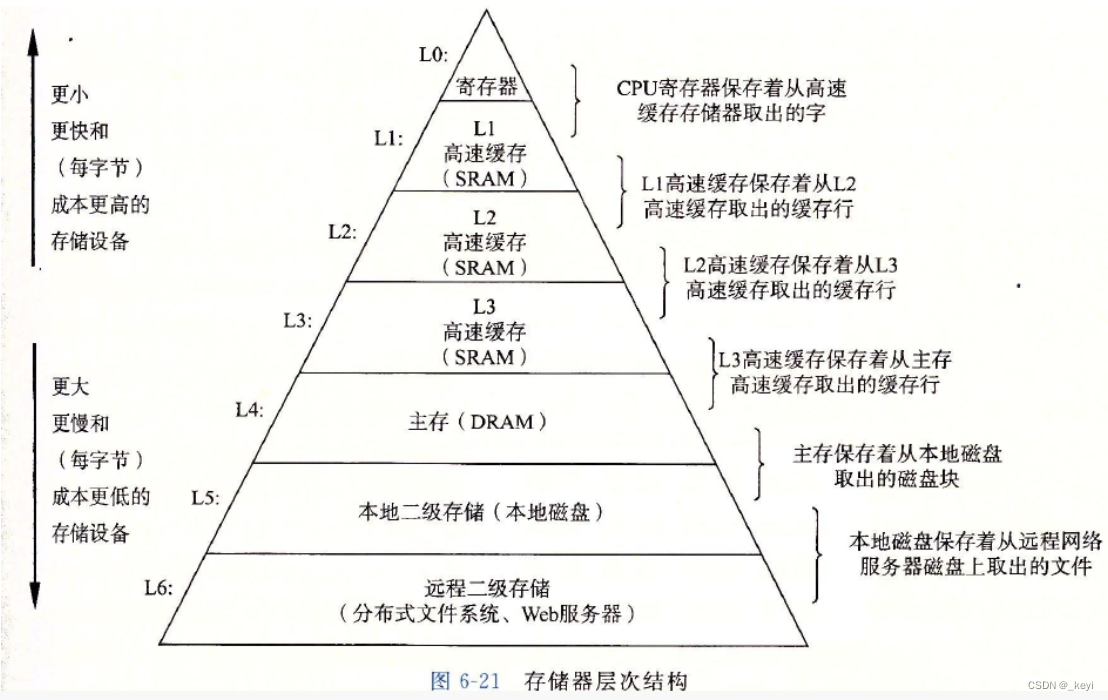
首先我们要知道,顺序表和链表中存放的数据都是在内存当中的
具体的可以看我的这篇文章➡️C语言深度剖析(一)
我们使用顺序表和链表的时候,需要到内存中读取数据,但是CPU的运算速度太快了,而内存的速度相对而言太慢了,所以硬件体系结构中存在着三级高速缓存,就是为了解决CPU和内存的速度不匹配的问题的。
CPU读取数据的时候不会直接访问,他会先看缓存中有没有,如果缓存中没有,他会先从内存加载到缓存(一级一级地加载)
举个例子:如果有一个顺序表:1 2 3 4
还有一个链表:10->20->30->40
如果对这两个表进行打印
首先 看 缓存里有没有顺序表的 1 ,没有就去内存中加载
而缓存的机制存在一个局部性原则,因为内存都是连续的,所以他会加载后面的一段内存
一般是加载几十个字节(具体看CPU)
所以 缓存顺便把顺序表后面的2 3 4加载到了缓存中
然后再去找后面的2 3 4 的时候发现缓存中已经存在 所以就不用再去内存中加载了
所以缓存命中率高!
而链表就不是这样了
链表是不连续的空间,10->20->30->40 每一个节点都是随机开辟的空间
大概率每两个节点之间距离很远
所以 每一次都需要缓存去内存中加载
所以缓存的命中率很低!
并且还有可能带来一个问题:缓存污染
也就是 把不用的数据加载到了缓存中 可能就把其他有用的数据给挤出去了!
而造成以上问题的原因归结于:二者的物理空间连续还是不连续

感谢阅读哦 给个赞把~~😛
















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











