






[目录]
0.问题重述
1.Summary and Assumption
2.Athlete-Centric-BNN
3.PLSR-Driven Evaluation
4.Elastic-BRR
5.Our Original Insight
6.总结
0. 问题重述
原题目:
第一大问:
为每个国家开发一个奖牌数模型(至少包括金牌和总奖牌数)。包括对模型预测的不确定性/精确度的估计以及模型性能的衡量标准。
显然,关键在于预测精度和不确定度。
1.1 根据您的模型,您对2028年美国洛杉矶夏季奥运会的奖牌榜有何预测?包括所有结果的预测区间。您认为哪些国家最有可能进步?哪些国家会比2024年表现更差?
1.2 您的模型应包括尚未获得奖牌的国家;您对有多少国家将在下一届奥运会上首次获得奖牌的预测是什么?您对这个估计的几率是多少?
同样提到了估计的几率。
1.3 您的模型还应考虑每届奥运会的比赛项目(数量和类型)。探索比赛项目与各国获得的奖牌数之间的关系。哪些运动项目对各个国家最重要?为什么?主办国选择的比赛项目如何影响结果?
第二问:
2.1可能存在“伟大教练”效应。两个可能的例子包括郎平[2],她曾执教美国和中国的排球队获得冠军,以及有时备受争议的体操教练贝拉·卡罗利[3],他曾执教罗马尼亚和美国的女子体操队并取得了巨大成功。检查数据以寻找可能由“伟大教练”效应引起的变化。您估计这种效应对奖牌数的贡献有多大?
2.2 选择三个国家并确定他们应考虑投资于“伟大”教练的运动项目,并估计其影响。
第三问:
您的模型还揭示了哪些关于奥运奖牌数的原创见解?解释这些见解如何为国家奥委会提供信息。
值得提醒的点:
-
您的模型和数据分析必须仅使用提供的数据集。您可以使用其他资源提供背景和上下文或帮助解释结果(请务必记录来源)
-
通常会对最终的奖牌数进行预测,但这些预测通常不是基于历史奖牌数,而是更接近即将举行的奥运会开始时,当已知当前参赛运动员时
Summary and Assumption
Summary
(和背景相关的套话)
为了对各国所获得的奖牌数进行分析与预测以及对不确定度进行量化,我们建立了Athlete-Centric Bayesian Neural Network。以CHN为例,该模型到达了$\text{RMSE} =1.768 $的高精度。针对问题一的第一小问,我们将AC-BNN应用于2024年的参赛国,最终得到了新西兰 、挪威等国的名次存在较大的上升可能,而如澳大利亚、荷兰等国的名次则存在较大的下降可能,并给出了金牌数目的 95 % 95\% 95%置信概率的预测区间。
同时,针对问题一的第二小问,我们同样应用了AC-BNN,并以 37 % 37\% 37%的概率认为阿尔巴尼亚, 51.9 % 51.9\% 51.9%的概率认为Armenia会获得大于等于1的金牌数,也就是夺得历史首金。
针对问题一的第三小问,考虑到自变量多重共线性的背景下,为了更好地分析比赛项目与各国获得的奖牌数之间的关系,我们建立了偏最小二乘回归模型。通过比较数据标准化后的回归系数,我们得以定量地研究运动项目对各个国家的重要性程度。
为了量化伟大教练效应以及分析应各国考虑投资于“伟大”教练的运动项目情况,我们开发了Elastic Bayesian Ridge Regression。我们首先采用弹性网络回归对于伟大教练效应带来的奖牌数变化进行总体的初步评估,得到了一名伟大教练约能在一次奥运会上带来 1.0426 1.0426 1.0426枚奖牌的增益;并同时进行特征选取,利用选取后的特征建立贝叶斯岭回归模型,最终建议中日两国投资Gymnastics的教练项目,建议美国投资Volleyball的教练项目,以 49.7 % , 99.9 % 49.7\%,99.9\% 49.7%,99.9%和 93.0 % 93.0 \% 93.0%的置信概率认为会回报2枚以上的奖牌。
Assumption
- 对于贝叶斯神经网络模型,数据为独立同分布
- 对于偏最小二乘回归模型和弹性网络回归模型,误差项的条件均值为0以及误差项同方差且不相关
- 对于弹性网络回归模型和贝叶斯岭回归模型,输入与目标变量之间存在线性关系
- 对于用于预测2028年奖牌数的数据,假定是在2024年的输入 A C A ACA ACA上产生了较小的随机扰动。对于2028年新增的项目,则增大原有相关项目的扰动:如新增Mountain Bike,则增大Cycling的扰动。
2.Athlete-Centric-BNN
2.1 BNN原理及特点
对于贝叶斯神经网络不了解的读者可以参考本人文章:小白换视角轻松理解BNN+代码论文复现
简而言之,贝叶斯神经网络处理该问题有两个得天独厚的优点:
- 善于处理高维度的输入数据
- 输出为一个分布,天生自带误差棒和置信区间。
2.2 Athlete-Centric
我们对于奥运会奖牌数的预测通常不是基于历史奖牌数,而是和各国各项目的参赛运动员相关。因此,这也启发了我们Athlete-Centric的思想:对于贝叶斯神经网络的回归分析模型,我们的输入中的重要组成部分为Average Performance Level of Competing Athletes( A C A ACA ACA)。
具体而言,对于一个特定国家,我们的BNN输入如下:
M
o
d
e
l
_
I
n
p
u
t
=
[
L
G
o
l
d
,
L
T
o
t
a
l
,
H
o
s
t
,
A
C
A
]
Model\_Input = [L_{Gold},L_{Total},Host,ACA]
Model_Input=[LGold,LTotal,Host,ACA]
其中
L
G
o
l
d
,
L
T
o
t
a
l
,
H
o
s
t
L_{Gold},L_{Total},Host
LGold,LTotal,Host分别为该国在上一届取得的金牌数和总奖牌数,以及是否为主办国。
A
C
A
=
A
P
A
⊙
E
n
ACA = APA \odot E_n
ACA=APA⊙En
其中,
A
P
A
APA
APA为Average Performance Level of Athletes,
E
n
E_n
En各项目的比赛场次。
⊙
\odot
⊙为哈达玛积,表示向量的逐元素相乘。
A
P
A
=
[
A
P
A
1
,
A
P
A
2
,
…
,
A
P
A
i
,
…
,
A
P
A
n
]
APA = [APA_1,APA_2,\ldots,APA_i,\ldots,APA_n]
APA=[APA1,APA2,…,APAi,…,APAn]
其中,n为总项目个数,
A
P
A
i
APA_i
APAi表示各个项目的参赛运动员平均水平。
A
P
A
i
=
∑
k
=
1
m
A
t
h
k
m
,
i
=
1
,
…
,
n
;
A
t
h
k
=
10
∗
G
+
8
∗
S
+
6
∗
B
+
1
∗
T
i
m
e
s
,
k
=
1
,
…
,
n
APA_i = \frac{\sum_{k = 1}^m Ath_k}{m},i = 1,\ldots,n;Ath_k = 10*G + 8*S + 6*B + 1*Times,k = 1,\dots,n
APAi=m∑k=1mAthk,i=1,…,n;Athk=10∗G+8∗S+6∗B+1∗Times,k=1,…,n
A
t
h
k
Ath_k
Athk为每一位运动员的个人水平,
G
,
S
,
B
,
T
i
m
e
s
G,S,B,Times
G,S,B,Times分别表示该运动员累计获得的金银铜牌次数以及累计参赛次数。此处的评分标准参考
在实际进行数据处理的过程中,为了保持 A P A APA APA与 E n E_n En两向量长度一致,我们对项目进行了一些合并。因为最终的 A P A APA APA包含项目太多,故不一一列出,仅展示选取项目构成的词云图:

2.3 模型建立与训练
经过对于数据的分析后,我们选择了以下的AC-BNN模型的参数设置:
- 双隐藏层,每层设置20个神经元
- 激活函数采用tanh
- 先验分布设置为正态分布
- 采用MCMC算法,具体实现为基于 pyro.infer \texttt{pyro.infer} pyro.infer的 NUTS \texttt{NUTS} NUTS算法。
- MCMC算法的超参数 num_samples \texttt{num\_samples} num_samples和 warmup_steps \texttt{warmup\_steps} warmup_steps分别设置为200和100
我们以 RMSE \text{RMSE} RMSE为评价准则,为2024年的所有参赛国都建立并训练了自己的AC-BNN模型。以USA为例,其模型在Gold和Total这两种输出上的RMSE分别达到了 3.68 3.68 3.68和 5.19 5.19 5.19的精度,下面给出训练过程可视化:
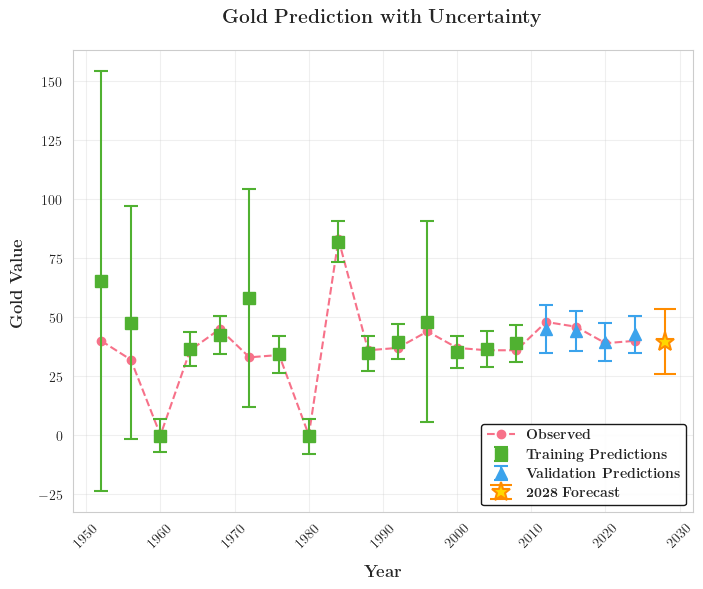
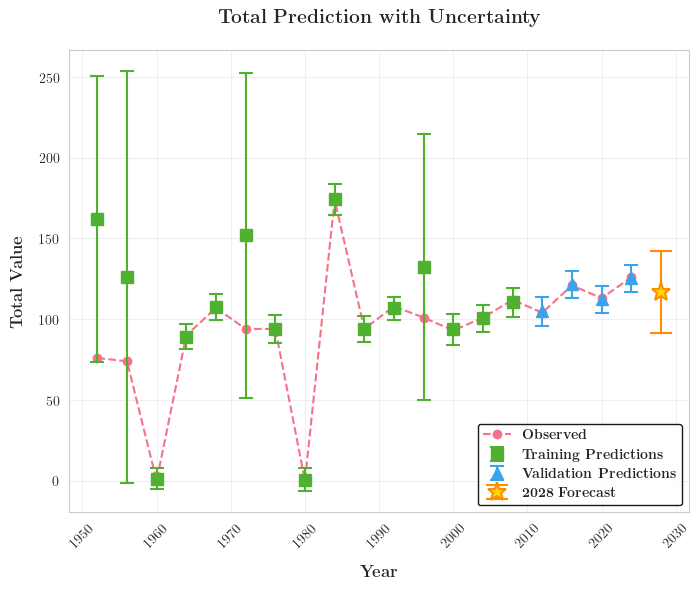
从图中我们也能发现,无论是训练集还是测试集,真实值总是落在预测值 95.44 % 95.44\% 95.44%置信概率的置信区间中,足以模型的可靠性。
2.4 Task One
2.4.1 第一小问
根据模型预测结果,大部分国家的排名都会存在一定幅度的波动。因此,我们选择了排名波动大于4并且以 μ σ > 2 \displaystyle \frac{\mu}{\sigma}>2 σμ>2为基准,分别筛选出了排名波动幅度较大并且预测结果稳定可靠的三个排名上升和三个排名下降的国家。
三个排名上升的国家分别为:新西兰、巴西和挪威。三个排名下降的国家分别为:瑞典、荷兰与澳大利亚。下图给出了其排名波动的具体情况以及预测金牌数以及 95.44 % 95.44\% 95.44%置信概率的预测区间:
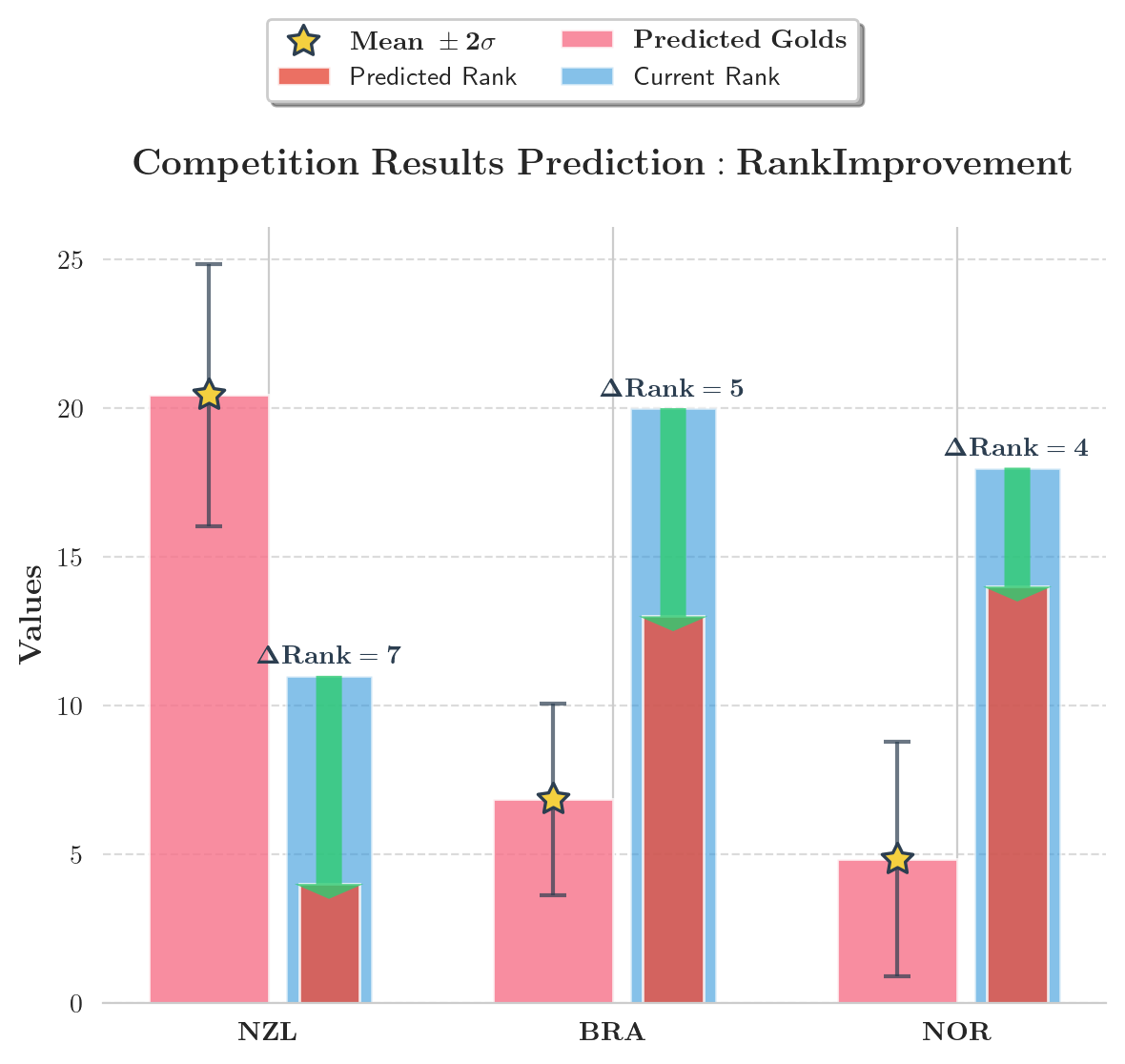
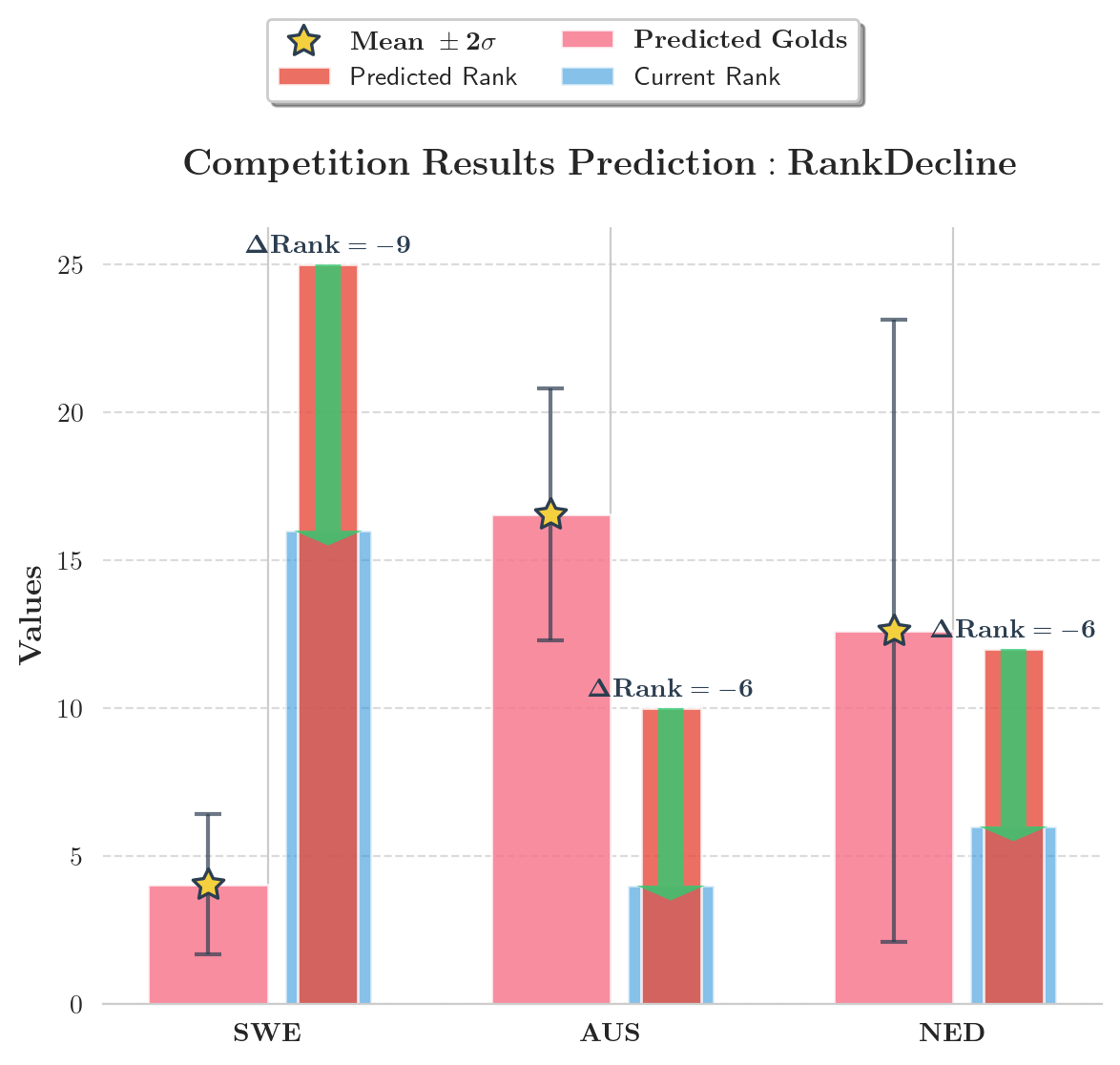
我们认为,出现该结果的主要原因为:2028年新增比赛项目为上述国家的优势项或者弱势项。
2.4.2 第二小问
在2024年的参赛国家中,仍然存在许多尚未获得过奖牌的。考虑数据集中关于尚未获得过奖牌的国家的数据较为系数,对模型的准确度影响较大,故在本问中我们聚焦于2028年尚未获得过金牌的国家获得第一枚金牌的概率。
与上一问相同,我们还是以以 μ σ > 2 \displaystyle \frac{\mu}{\sigma}>2 σμ>2为基准,最终得到了下列结果
| Country | P(Gold>0) | P(Gold>1) |
|---|---|---|
| Armenia | 0.981 | 0.519 |
| Albania | 0.997 | 0.370 |
考虑到贝叶斯神经网络的输出服从正态分布,我们不妨对结果进行概率密度的可视化:
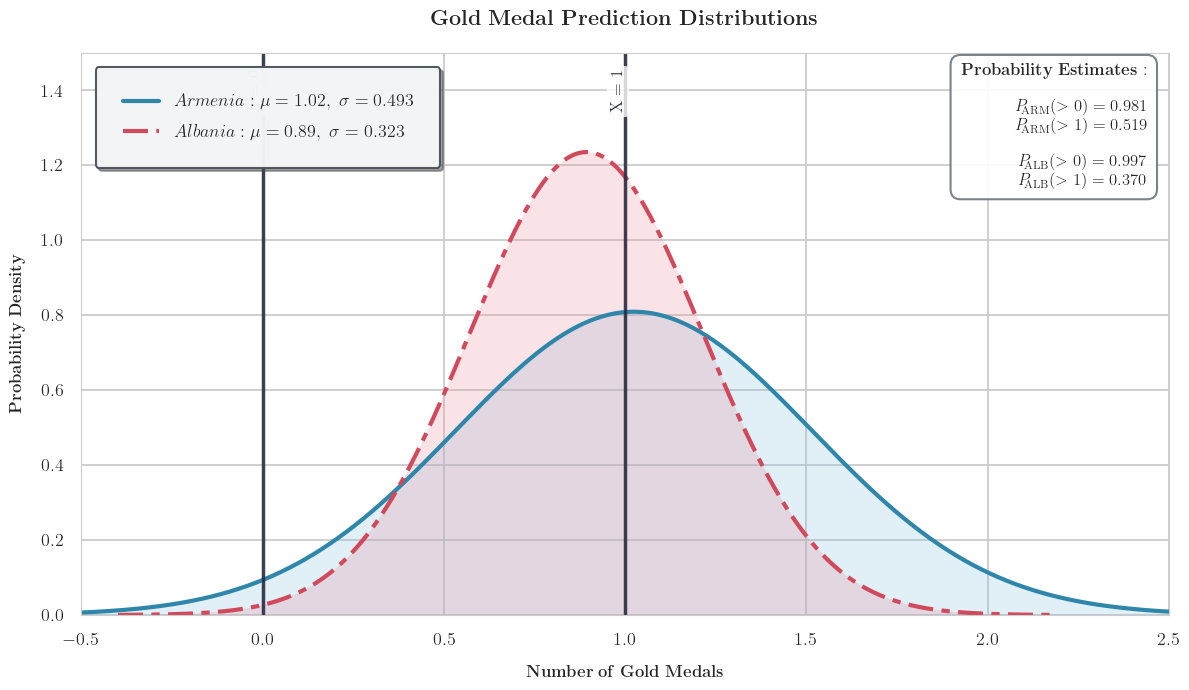
总而言之,并以 37 % 37\% 37%的概率认为阿尔巴尼亚, 51.9 % 51.9\% 51.9%的概率认为Armenia会获得大于等于1的金牌数,也就是夺得历史首金。
3.PLSR-Driven Evaluation
3,1 Why PLSR
为了分析竞赛项目与各国获得奖牌数量之间的关系,我们希望建立一个基于竞赛项目数量与运动员平均水平(APA)的组合数据集与总奖牌数Y之间的回归关系。回归系数反映了每个竞赛项目对一个国家获得总奖牌数的贡献:回归系数越大,该项目对该国家的重要性越高。可以发现,作为自变量的APA数据维度非常高,数据维度已经超过了样本数量。在这种情况下,选择一个合适的回归模型对于结果的可信度尤为重要。
选择回归模型的另一个重要因素是自变量数据集是否存在多重共线性。在这里,我们使用皮尔逊相关系数检验来检测自变量是否存在多重共线性:
皮尔逊相关系数是一种基于协方差和标准差测量线性相关的方法,适用于数据呈正态分布的连续变量。皮尔逊相关系数r的公式如下:
r = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 n ( x i − x ˉ ) 2 ⋅ ∑ i = 1 n ( y i − y ˉ ) 2 r = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^n (x_i - \bar{x})^2} \cdot \sqrt{\sum_{i=1}^n (y_i - \bar{y})^2}} r=∑i=1n(xi−xˉ)2⋅∑i=1n(yi−yˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
由于篇幅限制,我们展示了中国和美国的皮尔逊相关系数热图。每个方格的颜色深度将直观地显示两个体育项目数据之间的相关性强度:
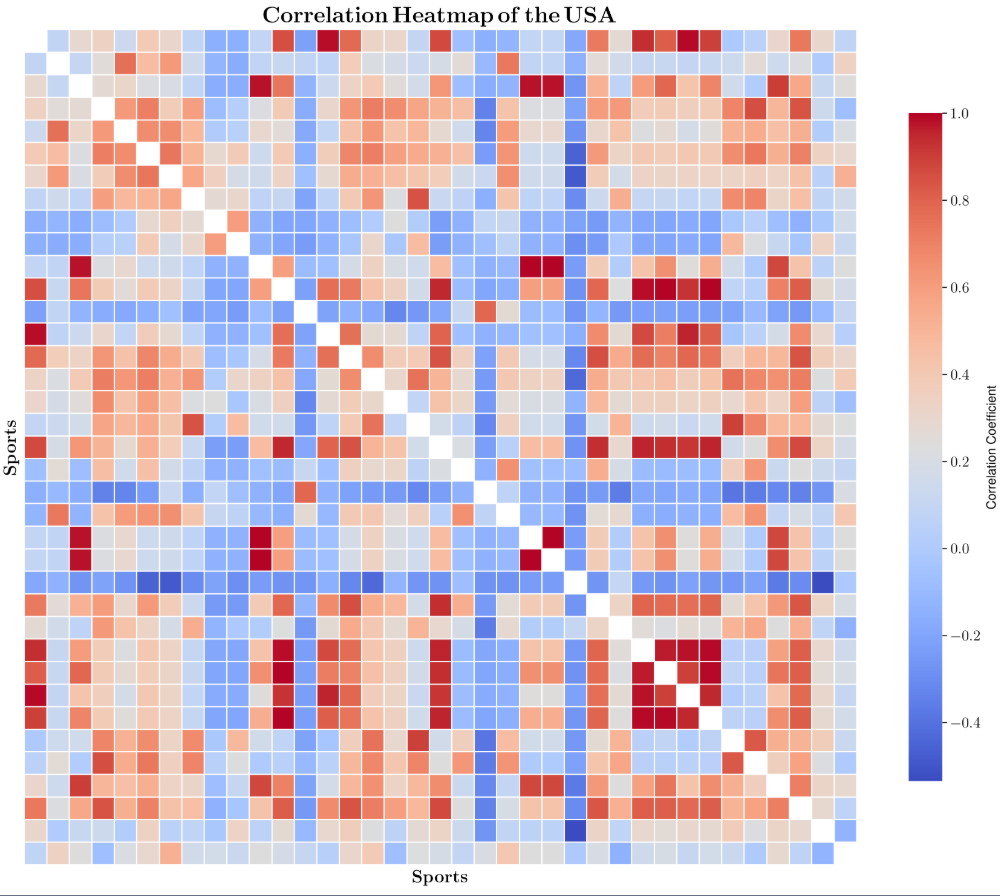
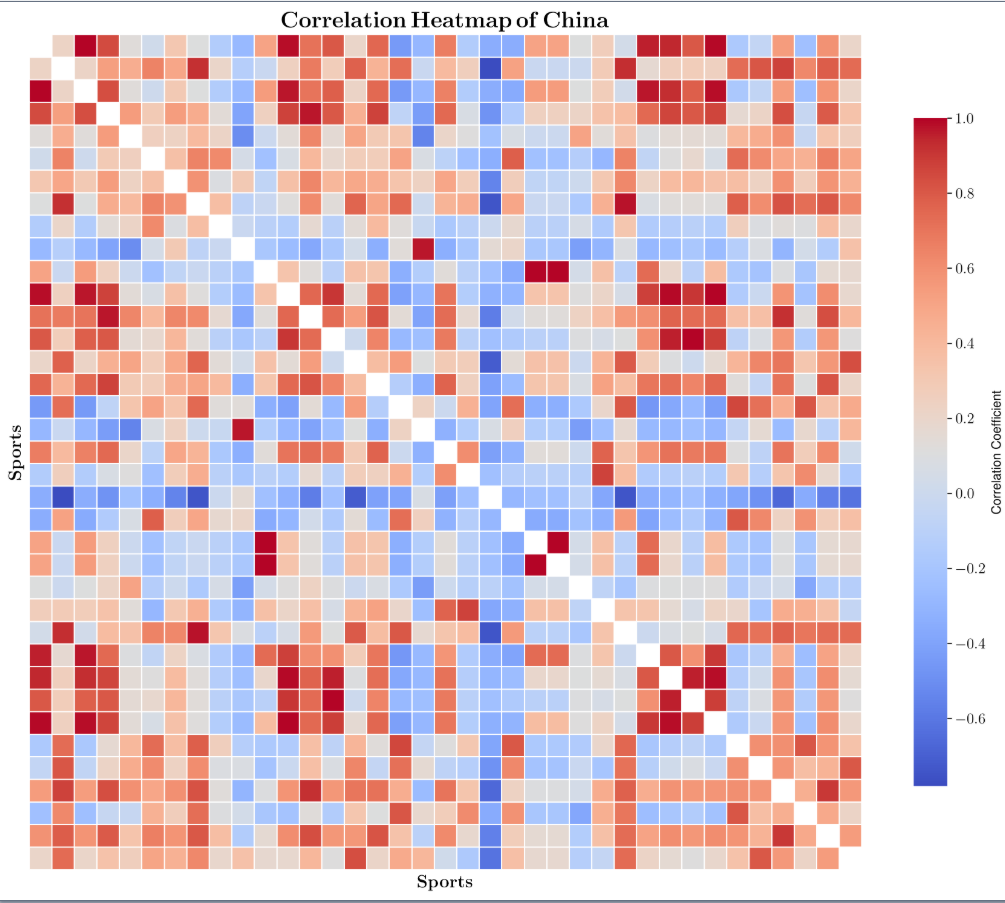
如图所示,可以看出自变量数据集APA存在高度的多重共线性。为了解决回归中高维多重共线性的问题,我们采用了偏最小二乘回归(PLSR)算法。
3.2 PLSR原理
偏最小二乘回归(PLSR)的核心是通过从标准化或中心化的数据集APA中提取主成分,捕捉自变量数据集APA与因变量Y之间的协方差信息。这个过程同时实现了降维和建模。主成分可以解释APA的最大方差,而主成分与Y之间的协方差最大化确保了这些主成分对Y具有最强的预测能力。
计算5折的平均均方误差(MSE)。
选择最优的
K
K
K:选择平均MSE最小的
K
K
K值。
数据标准化
- 目的:通过将变量中心化为均值0并缩放为方差1,消除尺度差异。
- 方法:标准化预测矩阵 X \mathbf{X} X和响应矩阵 Y \mathbf{Y} Y。
迭代提取潜在成分
通过最大化
X
\mathbf{X}
X和
Y
\mathbf{Y}
Y之间的协方差来提取成分:
-
初始化权重向量:
w = X T Y ∥ X T Y ∥ (对于单响应) \mathbf{w} = \frac{\mathbf{X}^T \mathbf{Y}}{\|\mathbf{X}^T \mathbf{Y}\|} \quad \text{(对于单响应)} w=∥XTY∥XTY(对于单响应) -
计算得分向量(成分):
t = X w \mathbf{t} = \mathbf{X} \mathbf{w} t=Xw -
计算载荷向量并更新 X \mathbf{X} X:
p = X T t ∥ t ∥ 2 , X 残差 = X − t p T \mathbf{p} = \frac{\mathbf{X}^T \mathbf{t}}{\|\mathbf{t}\|^2}, \quad \mathbf{X}_{\text{残差}} = \mathbf{X} - \mathbf{t} \mathbf{p}^T p=∥t∥2XTt,X残差=X−tpT -
更新 Y \mathbf{Y} Y:
q = Y T t ∥ t ∥ 2 , Y 残差 = Y − t q T \mathbf{q} = \frac{\mathbf{Y}^T \mathbf{t}}{\|\mathbf{t}\|^2}, \quad \mathbf{Y}_{\text{残差}} = \mathbf{Y} - \mathbf{t} \mathbf{q}^T q=∥t∥2YTt,Y残差=Y−tqT -
重复:用残差替换 X \mathbf{X} X和 Y \mathbf{Y} Y以提取下一个成分。
构建回归模型
使用提取的成分
T
=
[
t
1
,
t
2
,
…
,
t
k
]
\mathbf{T} = [\mathbf{t}_1, \mathbf{t}_2, \dots, \mathbf{t}_k]
T=[t1,t2,…,tk]回归
Y
\mathbf{Y}
Y:
Y
=
T
Q
T
+
E
\mathbf{Y} = \mathbf{T} \mathbf{Q}^T + \mathbf{E}
Y=TQT+E
其中
Q
\mathbf{Q}
Q是载荷矩阵,
E
\mathbf{E}
E是残差。
转换回原始变量
将系数转换回原始变量空间:
B
PLS
=
W
(
P
T
W
)
−
1
Q
T
\mathbf{B}_{\text{PLS}} = \mathbf{W} (\mathbf{P}^T \mathbf{W})^{-1} \mathbf{Q}^T
BPLS=W(PTW)−1QT
其中
W
\mathbf{W}
W是权重矩阵,
P
\mathbf{P}
P是
X
\mathbf{X}
X的载荷矩阵。
模型验证和优化
- 成分选择:通过交叉验证(例如,K折)选择最优的成分数量。
- 评估指标:使用 R 2 R^2 R2、RMSE等评估性能。
使用最优主成分数量进行回归
- 重新训练模型:基于完整的训练集,使用最优的 K K K提取主成分以构建最终的回归模型。
- 预测和评估:将模型应用于测试集并计算预测性能指标(如 R 2 R^2 R2、RMSE)。
- 模型解释:通过回归系数 B B B分析变量的重要性
3.3 实际应用
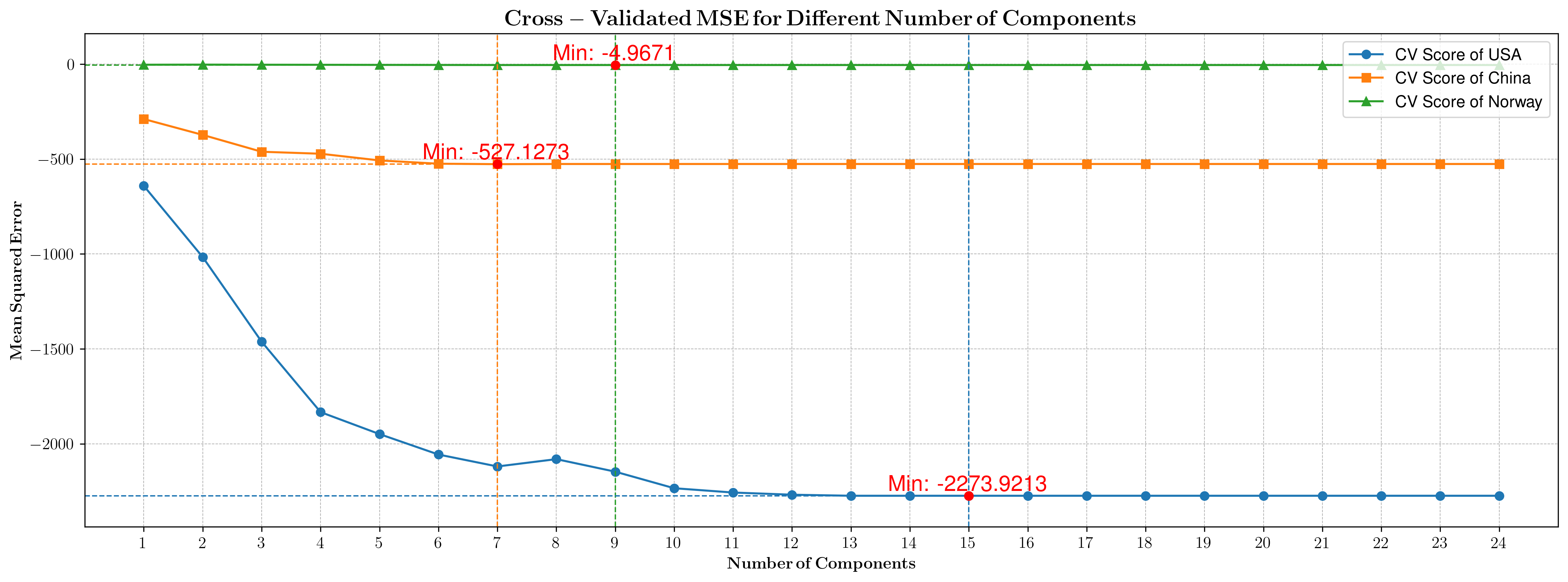
- 主成分数的确定
首先,我们通过5-fold交叉验证,确定了各国的最佳主成分数:
- 结果可视化
使用最优主成分数量进行回归,得到的回归系数可以反映每个项目对该国家总奖牌数的重要性。不同颜色表示不同竞赛项目回归系数的大小。中国、美国和挪威各个项目的回归系数如下图所示:
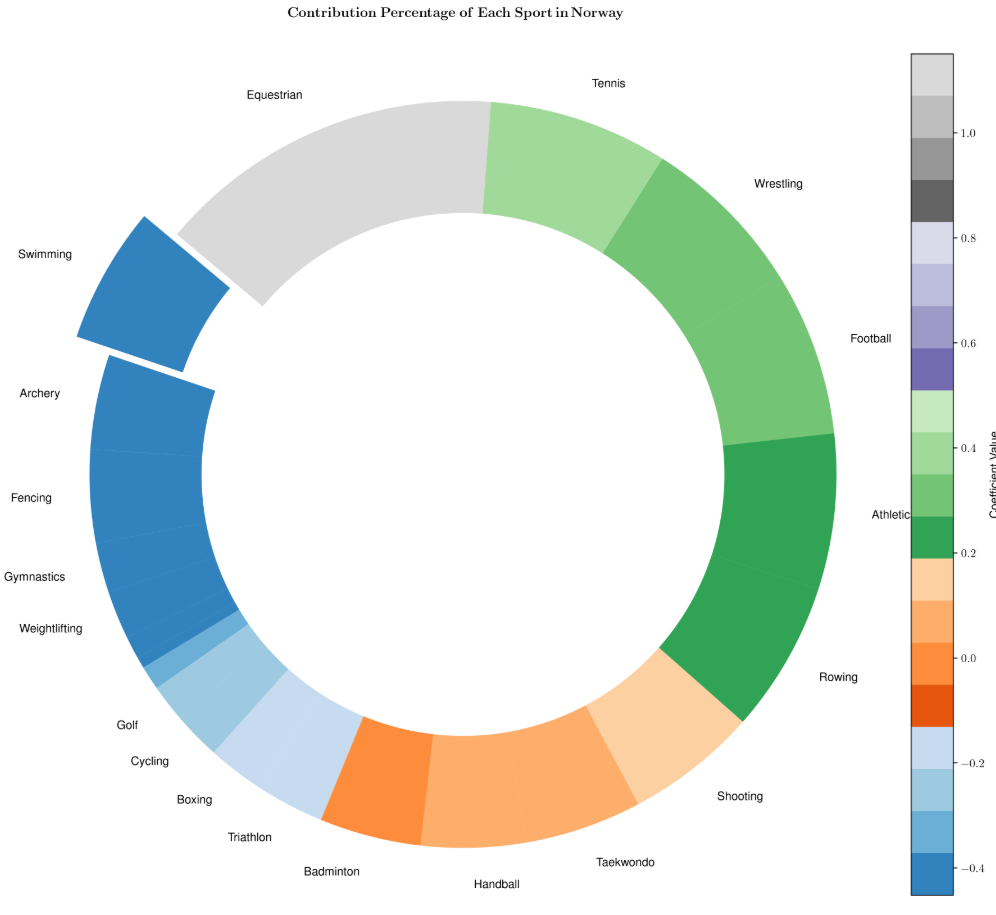
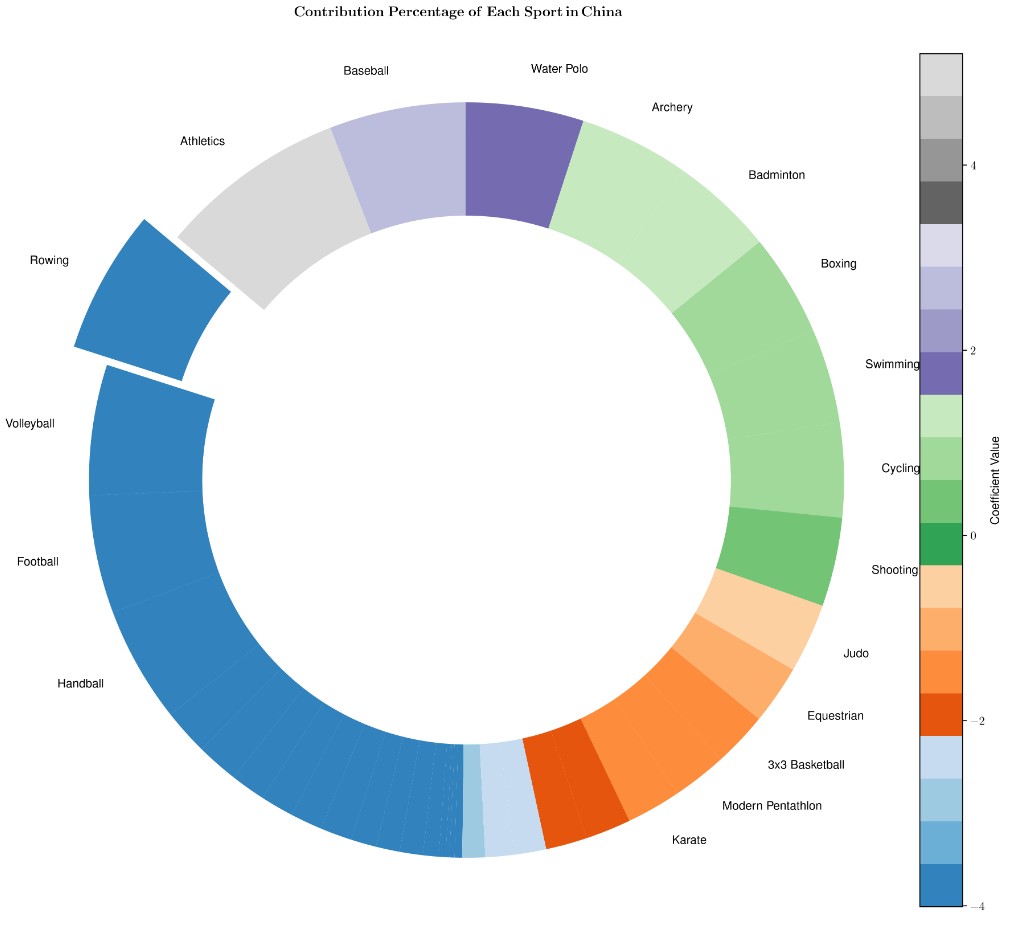
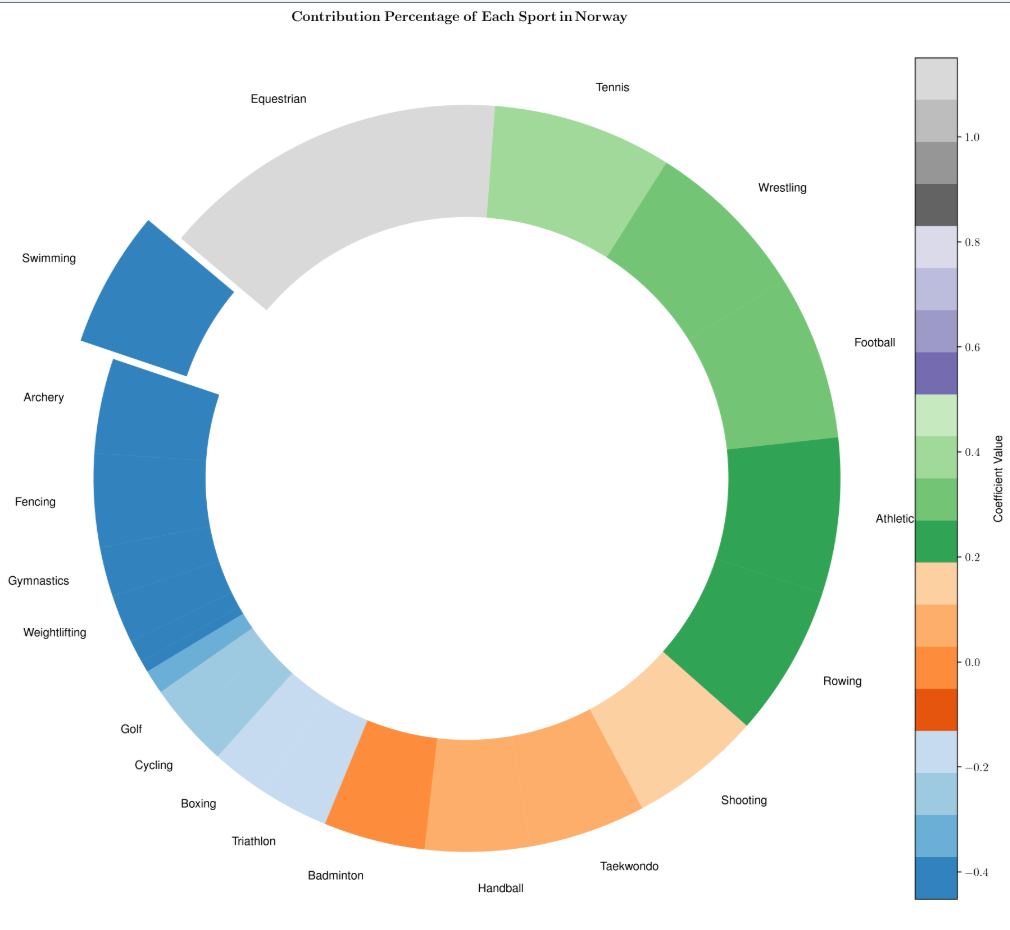
下表列出了对三国最重要的五个项目:

4.Elastic-BRR
Elastic Bayesian Ridge Regression是我们将弹性网络回归与贝叶斯岭回归结合的成果:弹性网络回归通过L1和L2正则化项结合了Lasso和岭回归的优点,而贝叶斯岭回归通过贝叶斯框架自动估计正则化参数并且能够提供不确定性估计。将两者结合后,就能够同时利用弹性网络的特征选择能力和贝叶斯岭回归的自动正则化和不确定性评估能力。
4.1 EBRR原理简述
4.1.1 弹性网络回归
-
原理
弹性网络回归是一种结合了Lasso回归(L1正则化)和岭回归(L2正则化)的线性回归模型。通过在损失函数中引入L1和L2正则化项,它在进行特征选择的同时,避免了Lasso回归在处理高度相关特征时的不稳定性。
-
公式
弹性网络回归的目标函数表示为:
minimize { 1 2 n ∥ y − X w ∥ 2 2 + α ρ ∥ w ∥ 1 + α ( 1 − ρ ) 2 ∥ w ∥ 2 2 } \text{minimize}\left\{ \frac{1}{2n} \|y - Xw\|_2^2 + \alpha \rho \|w\|_1 + \frac{\alpha (1 - \rho)}{2} \|w\|_2^2 \right\} minimize{2n1∥y−Xw∥22+αρ∥w∥1+2α(1−ρ)∥w∥22}
其中:- 1 2 n ∥ y − X w ∥ 2 2 \frac{1}{2n} \|y - Xw\|_2^2 2n1∥y−Xw∥22 表示均方误差项,用于衡量模型拟合度
- α ρ ∥ w ∥ 1 \alpha \rho \|w\|_1 αρ∥w∥1 表示用于特征选择的L1正则化项,使系数变得稀疏
- α ( 1 − ρ ) 2 ∥ w ∥ 2 2 \frac{\alpha (1 - \rho)}{2} \|w\|_2^2 2α(1−ρ)∥w∥22 表示通过收缩系数来防止过拟合的L2正则化项
- α \alpha α:正则化强度,控制整体惩罚的大小
- ρ \rho ρ:L1/L2惩罚之间的混合比例。当 ρ = 0 \rho = 0 ρ=0时,模型退化为岭回归;当 ρ = 1 \rho = 1 ρ=1时,模型退化为Lasso回归
-
算法步骤
通常使用坐标下降算法进行优化:
- 初始化权重系数 w w w(例如,零向量)
- 依次更新每个权重系数,同时保持其他系数固定:
- 依次遍历所有系数
- 为每个系数求解一元优化子问题
- 当系数变化低于容差阈值 ϵ \epsilon ϵ或达到最大迭代次数时,终止迭代
4.1.2 BRR
-
基础模型和先验设定
-
线性回归模型
观测数据遵循以下模型:
y = X w + ϵ y = Xw + \epsilon y=Xw+ϵ
其中: -
y ∈ R n y \in \mathbb{R}^n y∈Rn:目标变量, X ∈ R n × d X \in \mathbb{R}^{n \times d} X∈Rn×d:特征矩阵
-
w ∈ R d w \in \mathbb{R}^d w∈Rd:权重参数, ϵ ∼ N ( 0 , β − 1 I ) \epsilon \sim \mathcal{N}(0, \beta^{-1}I) ϵ∼N(0,β−1I):具有精度 β \beta β 的高斯噪声
-
参数的先验分布
权重 w w w 的高斯先验:
p ( w ∣ α ) = N ( 0 , α − 1 I ) p(w | \alpha) = \mathcal{N}(0, \alpha^{-1}I) p(w∣α)=N(0,α−1I)
其中 $ \alpha $ 控制先验精度。 -
超参数的先验
α \alpha α 和 β \beta β 的共轭伽马先验:
p ( α ) = Gamma ( α ∣ a 0 , b 0 ) , p ( β ) = Gamma ( β ∣ c 0 , d 0 ) p(\alpha) = \text{Gamma}(\alpha | a_0, b_0), \quad p(\beta) = \text{Gamma}(\beta | c_0, d_0) p(α)=Gamma(α∣a0,b0),p(β)=Gamma(β∣c0,d0)
具有弱超先验(小 $ a_0, b_0, c_0, d_0 $)。
-
-
后验推断
-
后验分布推导
根据贝叶斯定理,$ w $ 的后验是高斯分布:
p ( w ∣ y , X , α , β ) = N ( w ∣ μ , Σ ) p(w | y, X, \alpha, \beta) = \mathcal{N}(w | \mu, \Sigma) p(w∣y,X,α,β)=N(w∣μ,Σ)
其中均值和协方差为:
μ = β Σ X T y , Σ − 1 = α I + β X T X \mu = \beta \Sigma X^T y, \quad \Sigma^{-1} = \alpha I + \beta X^T X μ=βΣXTy,Σ−1=αI+βXTX -
超参数估计(证据近似)
最大化边际似然:
ln p ( y ∣ X , α , β ) = 1 2 ( d ln α + n ln β − β ∥ y − X μ ∥ 2 − α μ T μ − ln ∣ Σ ∣ ) + const. \ln p(y | X, \alpha, \beta) = \frac{1}{2} \left( d \ln \alpha + n \ln \beta - \beta \|y - X\mu\|^2 - \alpha \mu^T \mu - \ln |\Sigma| \right) + \text{const.} lnp(y∣X,α,β)=21(dlnα+nlnβ−β∥y−Xμ∥2−αμTμ−ln∣Σ∣)+const.
$ \alpha $ 和 $ \beta $ 的更新规则:
α new = d μ T μ + Trace ( Σ ) , β new = n ∥ y − X μ ∥ 2 + Trace ( X T X Σ ) \alpha^{\text{new}} = \frac{d}{\mu^T \mu + \text{Trace}(\Sigma)}, \quad \beta^{\text{new}} = \frac{n}{\|y - X\mu\|^2 + \text{Trace}(X^T X \Sigma)} αnew=μTμ+Trace(Σ)d,βnew=∥y−Xμ∥2+Trace(XTXΣ)n
-
-
与传统岭回归的联系
传统岭回归解决以下问题:
min w ( ∥ y − X w ∥ 2 + λ ∥ w ∥ 2 ) \min_w \left( \|y - Xw\|^2 + \lambda \|w\|^2 \right) wmin(∥y−Xw∥2+λ∥w∥2)
其解为:
w ridge = ( X T X + λ I ) − 1 X T y w_{\text{ridge}} = (X^T X + \lambda I)^{-1} X^T y wridge=(XTX+λI)−1XTy
贝叶斯岭回归的后验均值 $ \mu $ 在 $ \lambda = \alpha / \beta $ 时与此解匹配,但自动调整超参数。 -
优势和特点
- 通过学习 α \alpha α 和 β \beta β 实现自适应正则化
- 通过后验协方差 Σ \Sigma Σ 量化不确定性
- 通过参数先验减轻过拟合
4.2 Great Coach分析与特征选择
为了对“Great Coach”效应进行总体分析与量化,以及选取真正有高贡献度的特征,我们以总奖牌数作为回归因变量,构建了由国家、运动项目、 A P A APA APA、比赛年份和“Coach Effect”构成的回归自变量数据集。在此基础上,还构建了“Coach Effect”与国家和 A P A APA APA的交互项。经过查阅与可能存在“Coach Effect”的人物资料后,我们的数据集中选择了十五个国家和十个项目。
“Coach Effect”被编码为0或1,用以表征某年的比赛是否有“Great Coach的影响”。
我们首先建立了弹性网络回归用于初步量化“Coach Effect”的总体效应(即不区分国家、项目)并进行特征筛选。在下表中给出弹性网络回归的重要指标:
| 模型评价指标 | 模型 |
|---|---|
| R² Score | 0.900 |
| MSE | 8.644 |
| 最佳正则化参数 : α \alpha α | 0.0425 |
| 最佳L1比例: l1_ratio | 0.10 |
从模型评价指标中我们不难发现,模型拟合效果较好,并且由 α = 0.0425 \alpha = 0.0425 α=0.0425可以发现模型不存在过拟合的问题,而最佳L1比例也表明模型对于一些不重要的特征进行了惩罚。
评判“Coach Effect”对于奖牌数直接影响的是其回归系数,我们在此给出全部系数的结果:
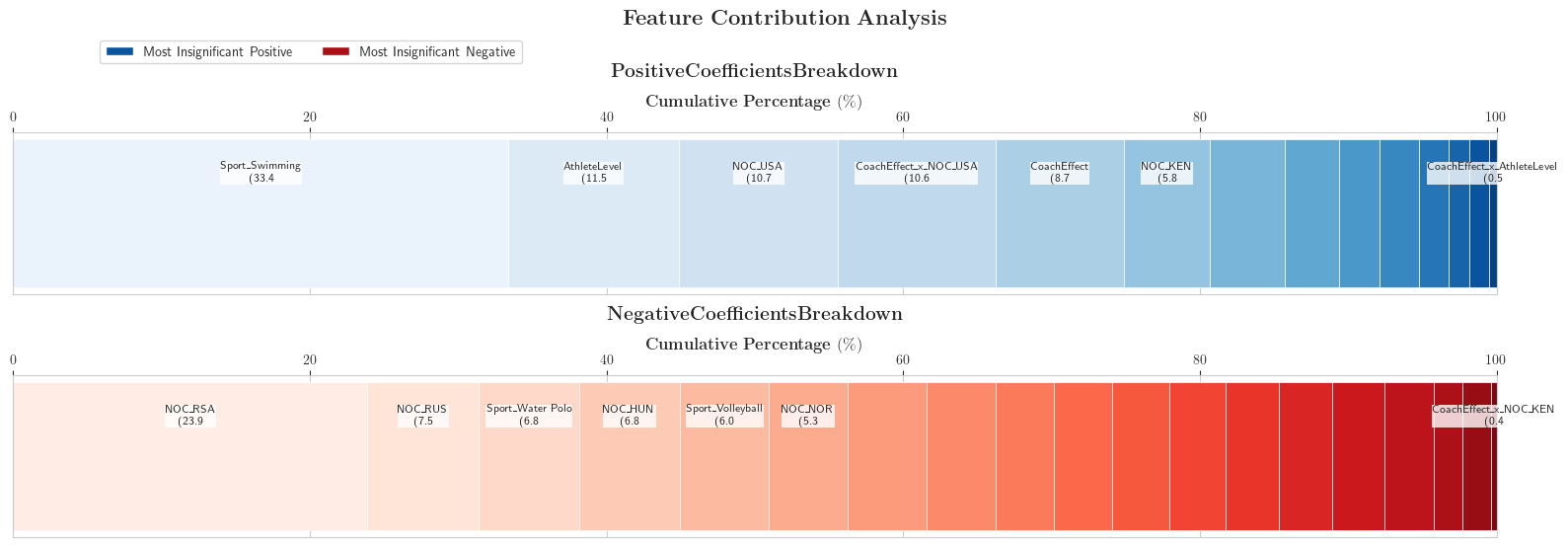
“Coach Effect”的回归系数为1.0264,即:总体而言,每增加一位“Great Coach”,就可以在某项目多获得一块奖牌。图中的结果还展示了“Coach Effect”与国家和 A P A APA APA的交互项的回归系数绝对值较小,即并不显著。这也就意味着,我们已经通过弹性网络回归模型去除了不重要的特征,而这些特征将不会进入贝叶斯岭回归模型。
4.3 投资Great Coach的战略分析
与弹性网络回归类似,我们以总奖牌数作为回归因变量,构建了由国家、运动项目、 A P A APA APA、比赛年份和“Coach Effect”构成的回归自变量数据集。在此基础上,还构建了“Coach Effect”与各比赛项目的交互项。“Coach Effect”与 A P A APA APA的交互项已经在特征提取时被去除。我们选择了三个国家和三个项目,分别为中、美、日以及跳水、跳水体操和排球,所涉及教练见表
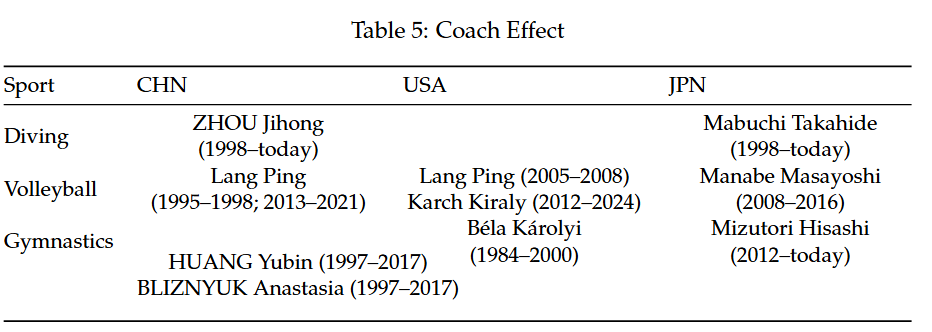
不同于使用弹性网络回归时的总体评判“Coach Effect”效应,在解决此问题时,我们采用的是每个国家分别建立贝叶斯岭回归模型,并重点关注“Coach Effect”与各项目的交互项,用以决定三国应该分别投资哪些项目。
我们完成基于KaTeX parse error: Expected 'EOF', got '_' at position 23: …{sklearn.linear_̲model} 的 BayesianRidge \texttt{BayesianRidge} BayesianRidge的代码实现后,得到如下结果:
| NOC | feature | coef_mean | coef_std |
|---|---|---|---|
| CHN | Diving_x_CoachEffect | 1.460868 | 0.794982 |
| CHN | Gymnastics_x_CoachEffect | 1.994045 | 0.849506 |
| CHN | Volleyball_x_CoachEffect | 0.806885 | 0.863156 |
| USA | Diving_x_CoachEffect | 3.050470 | 1.566817 |
| USA | Gymnastics_x_CoachEffect | 1.645152 | 1.818799 |
| USA | Volleyball_x_CoachEffect | 7.506258 | 3.724029 |
| JPN | Diving_x_CoachEffect | 2.688518 | 0.666871 |
| JPN | Gymnastics_x_CoachEffect | 4.257082 | 0.711219 |
| JPN | Volleyball_x_CoachEffect | 3.808470 | 0.719240 |
考虑到贝叶斯模型的输出服从正态分布,我们不妨对结果进行概率密度的可视化:
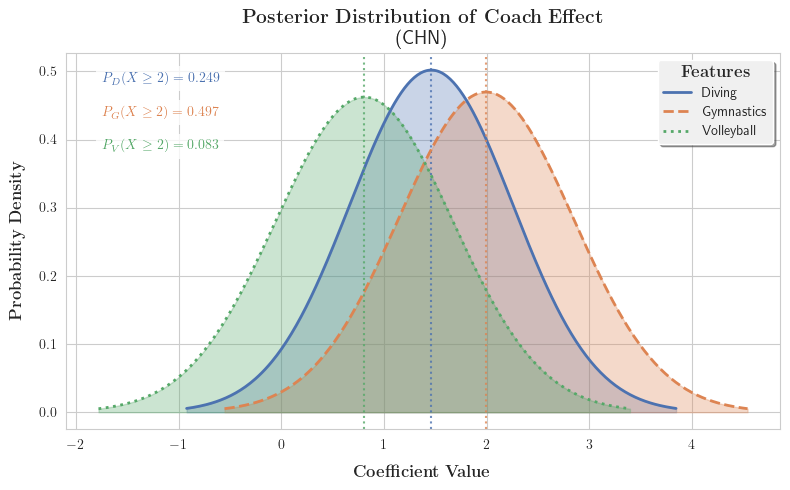
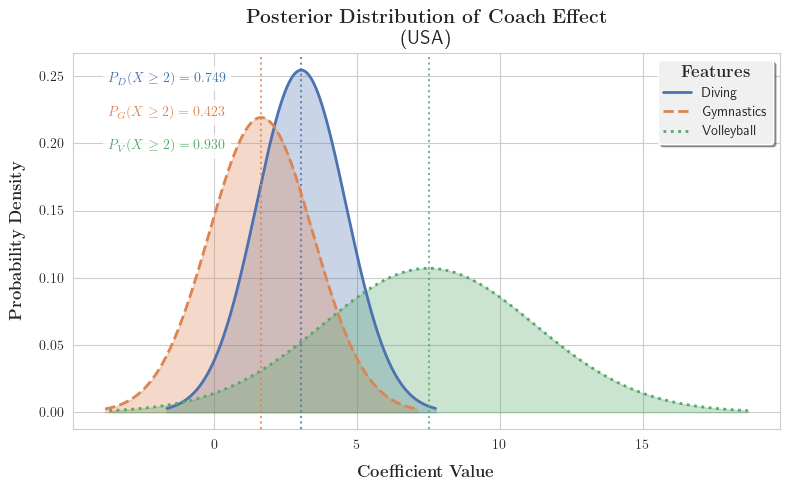
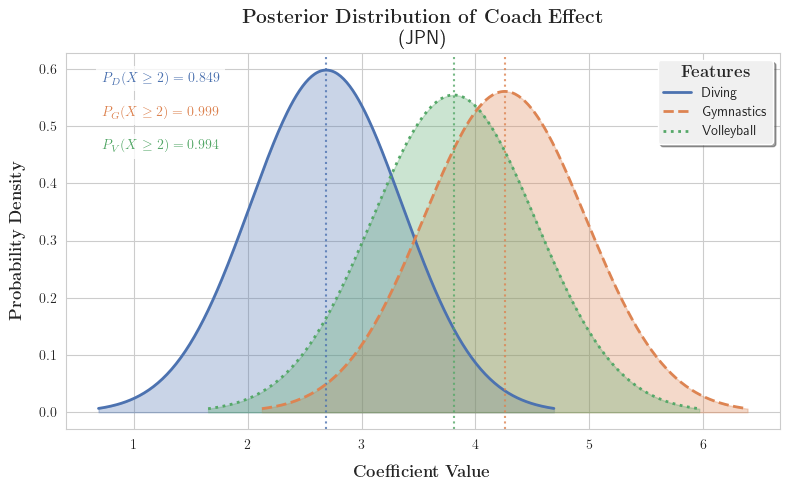
对结果进行分析,我们可以得出如下结论:
-
建议中日两国投资Gymnastics的教练项目,以 49.7 % , 99.9 % 49.7\%,99.9\% 49.7%,99.9%的置信概率认为会回报2枚以上的奖牌。
-
建议美国投资Volleyball的教练项目,以 93.0 % 93.0 \% 93.0%的置信概率认为会回报2枚以上的奖牌。
5.Our Original Insight
5.1 对PLSR结果的分析
可以观察到,竞赛项目与各国获得奖牌数量之间的关系也与这些国家的地理位置密切相关,这在中小型国家中尤为明显。例如,对于挪威和希腊等高纬度的北欧国家,游泳项目的回归系数通常低于低纬度国家。这表明游泳项目对竞赛奖牌总数的影响较小。推测这可能是由于它们高纬度、寒冷的环境,游泳的机会显著少于低纬度国家。

5.2 对EBRR其它结果的分析
首先给出Elastic Bayesian Ridge Regression模型的部分结果:
| NOC | feature | coef |
|---|---|---|
| CHN | Gymnastics | 1.341872 |
| CHN | Volleyball | -0.873367 |
| CHN | Year | -1.141747 |
| CHN | AthleteLevel | 2.180375 |
| CHN | CoachEffect | 1.460868 |
| USA | Gymnastics | 4.542182 |
| USA | Volleyball | 4.695676 |
| USA | Year | -1.864277 |
| USA | AthleteLevel | 1.967871 |
| USA | CoachEffect | 3.050470 |
| JPN | Gymnastics | 3.727176 |
| JPN | Volleyball | -0.261920 |
| JPN | Year | -0.019995 |
| JPN | AthleteLevel | -0.212211 |
| JPN | CoachEffect | 2.688518 |
对于模型结果进行一步分析,我们能发现下列特点:
-
Year项的负系数:
我们可以发现,对于中美两个大国,其Year的影响都相对显著,尤其是经常排名第一的美国,其Year项达到了-1.864的水平。然而该项对于日本却并不显著,仅为-0.019。经过分析,我们推测可能是因为随着时间的增长,其它国家的体育势力也逐渐发展,像中美这样包揽奖牌的体育大国的地位正在动摇。
-
CoachEffect并不一定直接提升运动员水平:
我们可以发现,三个国家中,CoachEffect最低的中国,反而最显著的特征是AthleteLevel,即反映运动员水平的 A P A APA APA。而日本则正相反。经过分析,我们推测,CoachEffect固然重要,但更重要的是,Coach对运动员的培养方法是否与本国对运动员的培养方案一致。
总结
本次美赛打得还是相当快乐的,前三天甚至每天下午依然会雷打不动地抽一个办小时健身
这道美赛题相对中规中矩,显然是不如2024美赛C题那般抽象的。
本次本人承担了除PLSR以外的全部的代码实现以及对应论文写作工作,最大的感觉就是其实对于一个队伍而言,不必三个人能力相当,而是重点在于分工合理。
本次数模小组是在线上协作,一天固定两次会议汇报进度,论文写作期间一直挂着微信语音。关于具体计划安排,写在 Run Code \texttt{Run Code} Run Code的 Jupyter Notebook \texttt{Jupyter Notebook} Jupyter Notebook之中,或许有可参考的价值。
关于具体的代码、数据和完整英文论文,若能够拿到一个不错的奖项,本人便会在本人公众号HORSE RU开源(所以本文就没有关键字的环节了)。BUT,无论是否取得令自己满意的成绩,想来也都不会懊悔,因为整个过程是相当有趣的。
此外,也希望读者们能够取得满意的成绩,以及,除夕快乐!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









