







得统一整理一下这个问题了。
其实String和Integer都是一样的。有两种实现的方式,一种就是
String a = "1";另一种就是
String aa = new String("1");两种写法的区别:
第一种写法过程:在栈区创建a引用(句柄),然后在常量池中寻找常量”1”,如果找到了直接将a引用指向常量池中,如果没找到,则在常量池中创建常量”1”,再指向它。
第二种写法过程:在栈区创建aa引用(句柄),然后再堆中创建对象new String,之后检查常量池中是否有”1”,如果有,直接取出来用以创建对象,如果没有,则需要创建一个”1”。
这两种写法就涉及到了一下问题:
String a = "5";
String c = "5";
System.out.println(c.hashCode());
System.out.println(a.hashCode());
System.out.println(a.equals(c));
System.out.println(a == c);String aa = new String("2");
String cc = new String("2");
System.out.println(aa.hashCode());
System.out.println(cc.hashCode());
System.out.println(aa.equals(cc));
System.out.println(aa == cc);首先看第一个,应该很简单了,答案为
53
53
true
true第二个答案
50
50
true
false这个时候可能有同学就要不理解了。首先给大家看一下hashcode的源码,这里有两部分,一个是string类型重写的hashcode,如下:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}下面是普通的hashcode源码:
public native int hashCode();看到区别没,其实hashcode就是为了表示一个对象的内存地址,但是对于string来说,就比较特殊,给重写了,所以string的hashcode只是根据你所赋予的值机型计算的,那只要值相同,hashcode当然就相等了。那可能就会问,为什么string要重写这个方法,不能使用以前的hashcode么。这个就要牵扯到以下知识点。
现在有一个map,里面的key可能是string可能是Integer,可能是int。如果是string和Integer,这种重写就有用了。对于同一个值,好比之前的aa和cc,string的值都一样,但是你不重写,比较的是地址,那么这样的hashcode的值,就会是new出来的对象的地址。对象是存在堆里面的,我不同的对象的堆地址自然不同,所以aa和cc就会被称为不同的key。这个跟我map的要求就不符合了,我map只要求key的值一样就可以。
有的同学会说,那我map为什么不能用equal来比较内部有没有相同的key呢?首先我们再看一下string的equal的源码:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}看到没?可以说是很弱智了。这里equal的重写竟然就是把string变成了一个char数组,一个个比较。想问,我要是map的key好长,那这个花费的时间很不值啊!所以采用的hashcode来比较,重写了以后就很方便~
再者,想说一下string常量池的一些问题。对于
String aa = new String("1");这一种,如我所说,1是在常量池中的。那现在有以下几种计算,大家可以计算以下:
1、
String s1 = new String("sss111");
String s2 = "sss111";
System.out.println(s1 == s2); //false2、
String s1 = new String("sss111");
s1 = s1.intern();
String s2 = "sss111";
System.out.println(s1 == s2); //true3、
String s1 = new String("111");
String s2 = "sss111";
String s3 = "sss" + "111";
String s4 = "sss" + s1;
System.out.println(s2 == s3); //true
System.out.println(s2 == s4); //false
System.out.println(s2 == s4.intern());//true4、
final String f = "a";
String c = f + "b" +"1";
String d = "ab1";
System.out.println(c == d);//true就不一个个分析了。首先先说一个方法,如果想分析,还是javac编译相应的java文件以后,再javap -c class文件,就会看到编译后的字节码,就知道运行过程了。
这里的intern是指向常量池内的的常量的一个函数。因此在2中,s1 = s1.intern(),s1指向的已经不是堆中的对象了,而是常量池中的常量。
对于3中,s3这种拼接的,但是明显都给出不变的,编译时会拼接起来的,所以运行时就是相同的,指向常量池中的sss111,但是编译过程中也会将sss和111加入常量池,这里要注意。
还有一个特殊情况,就是4,可以看到,f被final关键字修饰过,当修饰成常量后,只能被赋值一次,所以在编译期间就可以做编译优化。这里需要注意的。
下面说一下Integer的问题吧。
有下面的代码:
Integer a = 128;
Integer b = 128;
Integer c = new Integer(127);
Integer d = new Integer(127);
System.out.println(a.hashCode());
System.out.println(b.hashCode());
System.out.println(a == b);
System.out.println(c.hashCode());
System.out.println(d.hashCode());
System.out.println(c == d);答案:
128
128
false
127
127
false解释一下这个现象,其实源码里面写的也很清楚
@Override
public int hashCode() {
return Integer.hashCode(value);
}
public static int hashCode(int value) {
return value;
}上面的函数调用下面的函数,显而易见,Integer也重写了Object的hashcode,而且只返回对应的值。而为什么都是false,下面的很好理解,是因为创建了两个对象。上面的只是因为,对Integer对象,JVM会自动缓存-128~127范围内的值,所以所有在这个范围内的值相等的Integer对象都会共用一块内存,而不会开辟多个;超出这个范围内的值对应的Integer对象有多少个就开辟多少个内存。
说的通俗点!Integer已经默认创建了数值[-128~127]的Integer缓存数据,JVM会直接在该在对象池找到该值的引用。如果没有在范围内,Integer就会在堆内创建一个对象,指向这个对象,所以!
Integer a = 128;
Integer b = 128;a和b分别指向的对象的地址,当然不同。
题外话:每个整形的包装类,包括Long、Integer、Short、Byte、Character,都提供了缓存机制(一种优化手段),但是Float、Double没有,也就没有==比较的有趣现象了。
最后上一张图:
String s1 = "china";
String s2 = "china";
String ss1= new String("china");
String ss2 = new String("china");
int i =1;
int j =1;
public static final int i1 = 1;
public static final int j1 = 1;
Integer it1= 127;
Integer it2= 127;
Integer it11= 128;
Integer it12= 128;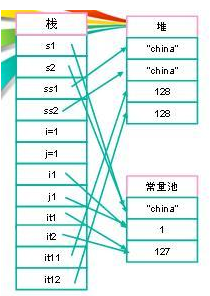















 1830
1830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









