







并行与分布式计算:OpenMP详解(五)
Section 5 OpenMP
OpenMP有三个API组件
- Compiler directives(编译指导语句)
- Runtime library routines(库函数)
- Environment variables
编译指导语句
句法:#pragma omp 指导名 子句
指导句紧邻其相关的程序语句(出现在其前一句)
指导句:#pragma omp parallel for
#pragma omp parallel for
该语句告知编译器,紧接着的for循环可以被并行执行
- 循环中迭代次数必须在执行循环前就可以算出
- 循环中不能包含break,return或exit
- 循环中不能包含前往循环外的goto语句
举例:
int a[1000], b[1000], s[1000];
...
#pragma omp parallel for
for (i= 0; i< 1000; i++)
s[i] = a[i] + b[i];
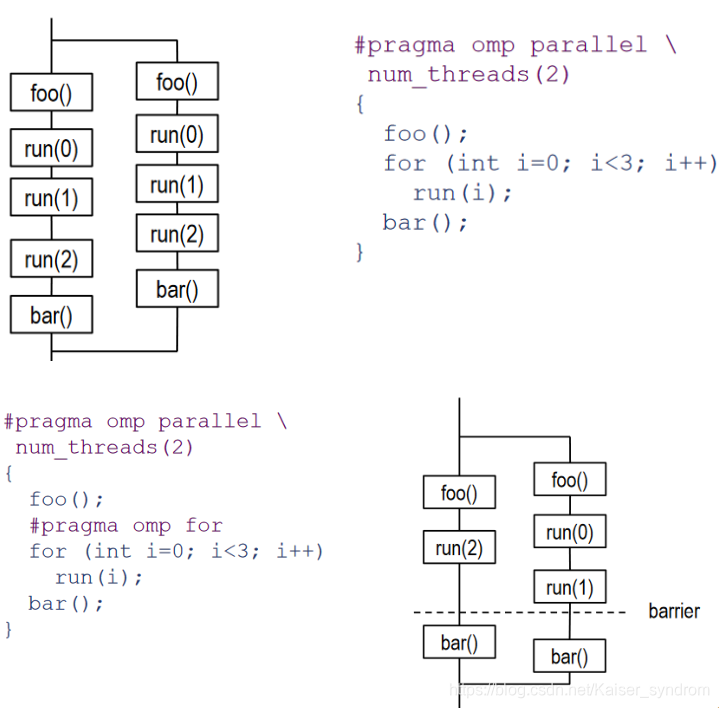
指导句:#pragma omp parallel
- 表示下面的一个结构应该并行执行
- 这一般适用于单程序多数据集的情况(SPMD)
- 也就是说,如果对于多个数据集都采用同一个方式处理,就可以考虑这个子句
指导句:#pragma omp for
- 仅在已被pragma parallel标记的结构中使用
- 表示下面的for循环的内容应该被分配给之前由parallel开启的多个线程执行
- for循环的工作内容总共仅执行一次,for循环外的内容被每个线程执行一次
- 将每一个线程执行的跟for相关的内容合并起来,不重不漏恰好是完整的单个for循环
- 在for循环的结尾,有一个barrier使得所有进程同步,从而大家同时结束for循环,同时进入下一步
看下例,被pragma for标记的部分被分配给多个线程并仅执行了一遍
指导句:#pragma omp single
使用条件:仅在一个并行代码块中使用
使用效果
- 告诉编译器只用一个线程来执行下面紧邻的代码结构
- 与该线程同组的其他线程将等待其完成该代码结构
- 除非使用
n
o
w
a
i
t
nowait
nowait子句告知其他线程不必等待
- 与single nowait效果类似的有指导句master
- 除非使用
n
o
w
a
i
t
nowait
nowait子句告知其他线程不必等待
实际情景
- 可以用于处理I/O这样的同时使用多线程可能出错的工作
指导句:#pragma omp section(s)
section:表示sections中的一个独立的代码部分
sections:表示闭合的要被划分给一组(a team)线程的一个或数个section代码块
- section和线程之间是肉和僧的关系,每个线程僧都试图抢肉吃,吃完一块就抓紧再拿一块
- 肉一旦端上来,所有的线程僧都会立刻试图抓块肉开吃
- 每块肉只能被一个僧拿走吃
- 如果有的线程僧吃的够快,肉的数目又很多的话,那么可能存在线程僧吃到了多块肉
指导句:#pragma omp task
开启一个子线程执行下述子任务
参考下述斐波那契数列的并行求法

指导句:#progma omp barrier 与 #progma omp taskwait
Tasks的完成与同步
以下情况可以保证任务已经完成
- 在线程与任务的结束后,所有子线程和子任务都必定已经完成
- 在指导语barrier处
- 线程组中的所有线程在此同步
- 在指导语taskwait处
- 某个线程的所有子线程在此同步
子句 reduction
reduction子句是常见的,parallel,for,sections都支持reduction子句
- #pragma omp … reduction(operator : listVariable)
- 列表变量即一连串的被reduction标记的变量,用","隔开即可
reduction子句用于规约变量,在使用时,reduction将把list中的所有变量进行一个private备份(使用一个恰当的初始值),并用此备份进行并行计算,在for循环结束后将把变量做规约(例如+:sum将给每一个线程创建一个名为sum的变量进行加运算,并在最后将所有sum与sum的初值进行合并,完成求和运算)
常见操作符对应的初始值如下

代码举例:
#include<stdio.h>
#include<omp.h>
int main()
{
omp_set_num_threads(2);
int sum = 3;
int prod = 5;
#pragma omp parallel for reduction(+:sum,q) reduction(*:prod) num_threads(2)
for (int i = 1; i <= 3; ++i)
{
int tid = omp_get_thread_num();
sum += i;
prod *= i;
printf("thread(%d) ""sum = % d prod = % d\n", tid, sum, prod);
}printf("results: ""sum = % d prod = % d\n", sum, prod);
}
输出值为
thread(0) sum = 1 prod = 1
thread(1) sum = 3 prod = 3
thread(0) sum = 3 prod = 2
results: sum = 9 prod = 30
//sum在0和1线程的初始值都是0,prod的初始值都是1
//0线程处理i=1和i=2的任务,1线程处理i=3的任务
子句 schedule
仅仅将for循环的任务均分还是不够精细
举个栗子(不同颜色表示分配给不同处理器的任务,一行对应一个i迭代器的任务)
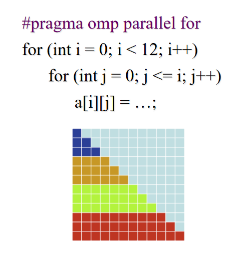
由于任务量与迭代器的关系可能不同,如何才把一个for循环内的12个任务按照任务量更均匀地分配给不同线程使得执行时间更短?
考虑静态规划
在执行前,每一个迭代器要分配给哪个线程都已经确定了。
需要根据现实情况思考的问题:如何确定静态规划的方式使得任务负载更加均衡?
考虑动态规划
迭代器在循环执行中动态地分配给各个线程。
需要根据现实情况思考的问题:在动态的分配的分配中如何平衡分配开销和负载均衡?
schedule子句
使用方法:schedule(kind,chunkSize)
- 静态调度 static
- 0 - chunkSize-1分配给第一个线程chunkSize - 2chunkSize-1分配给第二个线程,以此类推
- 开销较低,但可能产生负载不均衡
- 静态的分配方式适用于任务量在执行前已知的情形,这样一开始合适的分配任务不会导致太大的负载不均衡
- 不填size默认为平均分配(size=迭代数/线程数上取整)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qwnIhNcL-1585721404096)(C:\Users\56875\AppData\Roaming\Typora\typora-user-images\image-20200401103201129.png)]](https://img-blog.csdnimg.cn/20200401141343965.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0thaXNlcl9zeW5kcm9t,size_16,color_FFFFFF,t_70)
- 动态调度 dynamic
- 每次都将chunkSize个迭代器分配给一个可用线程
- 也就是线程空闲时会自动取领取一个chunkSize大小的任务
- 由于线程的启动时机和执行完的时间不确定,所以迭代器被分配到哪个线程时无法事先知道的
- 不填size默认为1(逐个分配)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wfsdmnVR-1585721404097)(C:\Users\56875\AppData\Roaming\Typora\typora-user-images\image-20200401103136547.png)]](https://img-blog.csdnimg.cn/20200401141401309.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0thaXNlcl9zeW5kcm9t,size_16,color_FFFFFF,t_70)
- 每次都将chunkSize个迭代器分配给一个可用线程
- 启发式调度 guided
- chunkSize表示每次分配的迭代次数的最小值
- 每次分配给线程的迭代次数是不同的,开始可能比较大,以后逐渐减小
- 是一种更灵活的动态分配,当有大量任务时就会一次性分配较多任务,从而使得分配消耗更少,执行效率更高;当任务量较少时一次性分配较少线程,从而使得负载更加均衡
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RIs0G1NF-1585721404097)(C:\Users\56875\AppData\Roaming\Typora\typora-user-images\image-20200401103121264.png)]](https://img-blog.csdnimg.cn/20200401141416640.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0thaXNlcl9zeW5kcm9t,size_16,color_FFFFFF,t_70)
库函数
int omp_get_num_procs(void);//获取当前可用的物理处理器数目
void omp_set_num_threads(int t);//设置程序中激活的线程数
OpenMP的优点与缺点
优点
- 适合域分解(数据并行)
- 在*nix和windows上都可运行
缺点
- 不是非常适合功能分解
在Visual Studio 2019上编写和调试OpenMp
使用VS2019,必须打开OpenMP支持,在源文件右键,属性,C/C++/,语言,OpenMp















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









