






今天和大家分享一篇快手发表在CIKM2023的文章,介绍搜索场景下如何建模用户的长期兴趣,权衡相关性和用户偏好。

Motivation
推荐场景的兴趣建模典型工作如DIN,SIM等,这类工作也能直接应用于个性化搜索精排中,但会带来较大的噪声:对于即时搜索而言,和当下用户搜索需求相关的历史行为才可能带来信息增益,和搜索无关的行为强行引入反而只会给模型带来噪声。
尽管DIN本身的注意力机制、引入零向量的DIN变体ZAM[2]、带检索功能的SIM等都一定程度上具备计算历史行为item和目标item的相关性,但都不是直接和彻底的,只是通过注意力分数等弱化噪声,都没有显式建模和搜索词的相关性。
整体来看,搜索场景下行为序列建模主要挑战有两点:
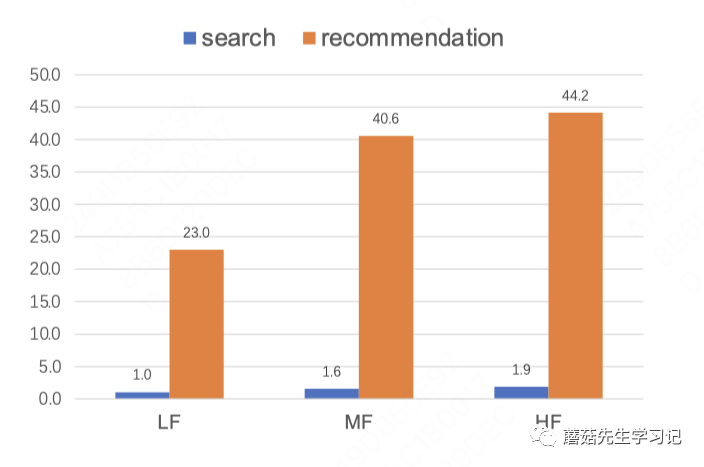
稀疏性和噪声:搜索场景本身的行为序列是非常稀疏的,因为用户在搜索场景下需求相对较为明确,通过少量的item可能就能满足需求。下图是快手推荐、搜索场景的行为序列对比,按照用户频次分层,比如:快手推荐场景下“中频用户周行为序列平均长度为40.6”,但快手搜索场景下只有“1.6”,推荐场景是搜索场景的25倍。显然,仅引入搜索场景的行为序列是远远不够的,信息增益太小。那么就需要考虑将用户全渠道的行为(包括推荐场景、搜索场景等)都用于构造用户长期行为序列,作为个性化搜索的输入信息,但面临的挑战就是噪声过多,和当前搜索词不相关的item占绝大多数。
行为稀疏导致仅用ID捕捉item关系能力不足:正是由于和目标item有关系的历史行为可能很少,如果仅依靠ID来建模item之间的关系,可能会造成性能的下降。需要考虑item的辅助信息、用户历史行为中对item的交互深度(如播放时长等),来刻画用户的偏好。
为了解决这样的挑战,作者提出了一种新的搜索场景下的长期兴趣建模结构:Query-dominant user Interest Network (QIN),通过两阶段检索,从长期历史行为序列中依次选出和搜索词和目标item相关的子序列,然后通过一种新的注意力机制提取用户序列表征,该注意机制中除了建模历史item ID和 target item ID的关系,还会引入item的属性、历史item交互行为深度(如观看时长)等信息。在快手搜索场景下取得了相对7.6%的显著CTR提升。
Solution
QIN一言以蔽之,整体分为两个步骤:
相关行为检索:类似SIM,只不过分为2个阶段。设计相关性搜索单元(Relevance Search Unit, RSU),从历史长期行为序列中检索出和搜索词相关的行为;再对每个target item,从子序列中检索出相关的个行为。
用户序列表征:类似DIN,对上述个行为设计注意力机制,融入ID、属性、交互深度等信息,得到Target-item感知的用户序列表征。
整体工作是很简洁的。步骤1听起来很简单,主要还是取决于“基建”,有“基建”这个事情就容易实现:多模态语义向量、Embedding搜索、缓存等机制。
步骤2体现了QIN的结构设计,如何融入ID、属性、交互深度等信息到注意力机制设计结构中。当然步骤2,个人理解属于锦上添花的工作。
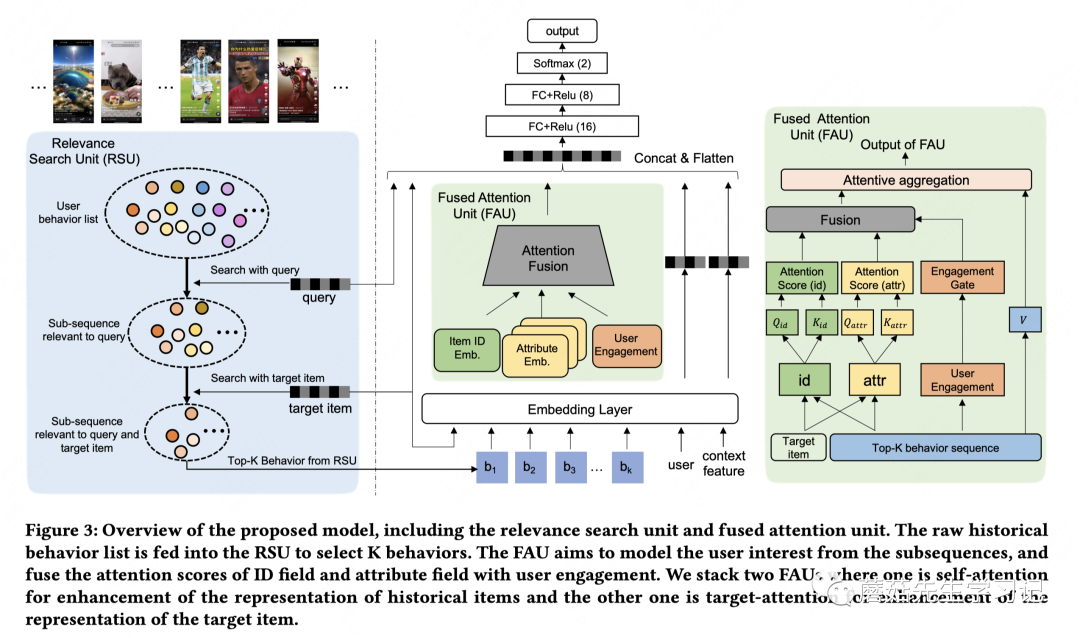
具体而言,整体模型结构如下:
左侧是相关性搜索单元:输入query、target item向量,得到top-K行为序列;
最右侧是融合注意力单元:用于序列表征;
中间是模型结构:对top-K行为序列用FAU单元进行self-attention计算用于提升每个item的表征,再用另一个FAU单元进行target-attention计算,得到汇聚后的用户表征,输入到模型中进行建模。
相关行为检索(Relevance Search Unit)
长期行为中存在非常大的噪声,RSU负责从中选出和搜索词最相关的topK个行为。
我们先看个示例如下。最上面是用户的长期历史行为序列,有体育(偏好梅西)、娱乐、宠物、健身等行为。当用户搜索world cup的时候,先从历史行为序列中检索出和world cup可能相关的,如:"梅西"、"阿根廷"、"C罗"等。再对每个待预测的target item,选出和target item联系紧密的。

这里面相关性计算用到了多模态预训练向量。至于为什么会设计2个阶段的检索,而不是略去第二个阶段,作者提到:
第一阶段负责从全局角度拓展出和搜索词相关的用户兴趣:初筛,基于多模态预训练向量计算搜索词和item的相关分,把很不相关的结果过滤掉,保留的item有多种相关性粒度,即:有很相关的、也有弱相关的,有些弱相关的item对于推测用户偏好还是有帮助的。
第二个阶段负责从局部角度拓展出和目标item相关的用户兴趣:细筛,基于多模态预训练向量计算item和item的相关分,加强item粒度的相关性,还能够提升不同item之间的差异性。比如上图“梅西吻奖杯的画面”的视频和历史行为中“梅西”本人的照片更相关;“世界杯难忘时刻”的视频和历史行为中“梅西”、“C罗”等都有关系。
融合注意力单元(Fused Attention Unit)
上述筛选出来的相关item需要进行模型建模,此处相当于对DIN/Transformers等方法做了改进,进行self-attention和target attention的序列表征。
作者强调,在长尾场景中,计算item与item的注意力分数时,仅考虑ID是不够的,需要同时考虑attribute,再将二者融合起来。除此之外,本部分还会考虑如何把用户历史交互深度信号引入建模,比如观看时长等。
item与item计算attention score的公式如下,包括通过ID计算、通过attribute计算的。
其中,是item ID的embedding;是item attribute的embedding,比如item的作者。, 是Q,K矩阵。
上述两个注意力做线性插值:
进一步,考虑将行为序列中的item的交互深度信息引入,比如时长、点赞、收藏等。交互行为对应的embedding输入2层非线性层作为gate作用在上述att上,用于区分用户的偏好强度。
是engagement类型的表征,最后得到的注意力分数计算公式为:
通过上述注意力单元,可以得到item和item之间的关系。
上述FAU单元用于两处,1处是序列中的self-attention,做每个item的表征增强;另一处是target attention,用于汇聚用户行为序列表征。
比如:得到 target item和每个历史行为item的计算分数后,就能够对用户序列做汇聚得到用户行为表征:
其中。上述过程是1个head的输出表征,可以叠加多个head拼接输出。
训练过程和常规CTR模型一样,不做赘述。
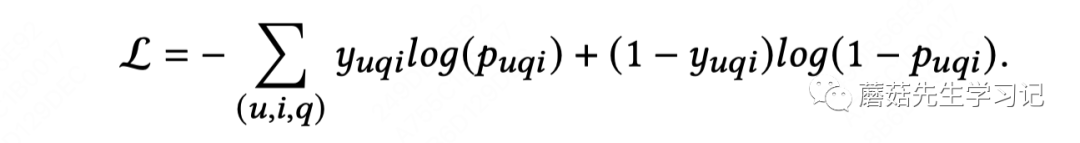
Online Serving
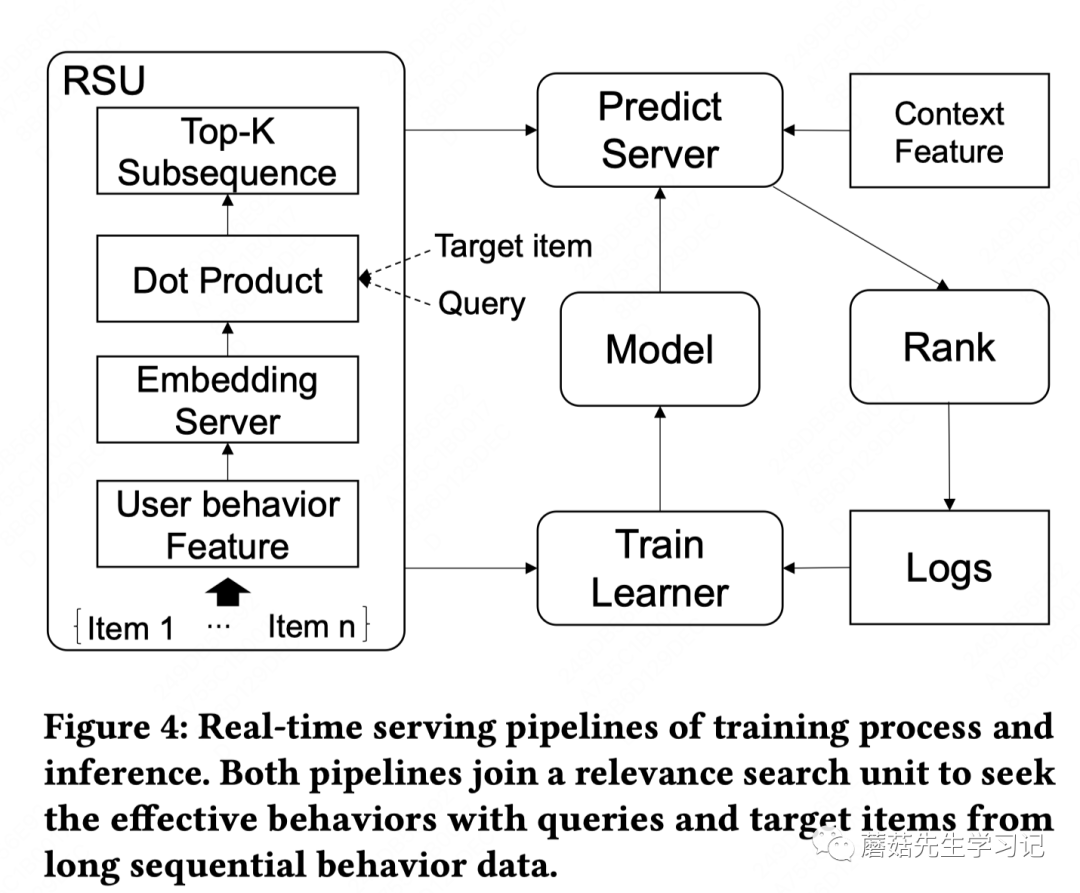
抛开RSU不看,整个过程就是典型的ctr在线预估服务。QIN引入了RSU单元。
历史行为存储:会对历史重复行为做去重,即重复item的只保留最新一次行为,差不多可以减少10%行为。行为特征通过feature center获取,以KV行为存储,包括engagement, timestamp, authorid等,embedding server中存储多模态向量,也是KV存储格式,不仅有videos,query的向量也存了。
Dot Product检索:对每个item,每个query都会做检索,最耗时的地方,文中提到会做并行优化。我个人理解1次请求过来,每个query对应的user topK行为可以分离处理提前异步计算,检索的时候去KV中拿query侧的多模态向量,然后dot product计算和item的相似性,并取出最相关的topK行为,这里可能会用到量化技术做ANN检索,但难点是用户维度的存储,每个用户都有个自己的小型数据库,工程上如何实现?拿到query相关的topK item后,每个target item打分的时候,就可以并行的去做第二阶段检索,如果K比较小,对每个item直接遍历一遍算可能就可以了,如果K比较大,可能仍然需要个小型ANN。总之,是需要一定工程基建能力支持的。
拿到每个target item的top-K行为后,剩下流程就和ctr在线预估服务一样了。
Evaluation
数据集:Amazon dataset,包括Beauty、CDs&Vinyl、Electronics、Kindle Stores等细分品类。指标采用搜索场景更广泛使用的NDCG等。
对比实验
对比实验如下:对比的baseline主要是个性化搜索领域的一些工作如HEM(层次化embedding)、TEM(transformers)、ZAM(zero-attention)等,可以看出NDCG等排序指标提升不少。
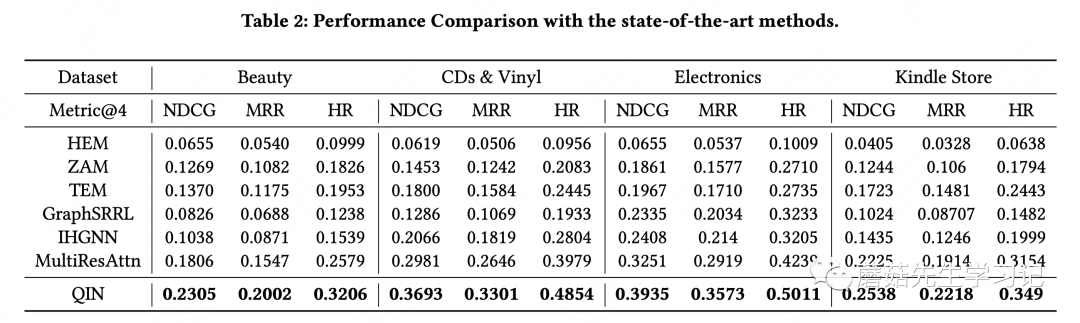
消融实验
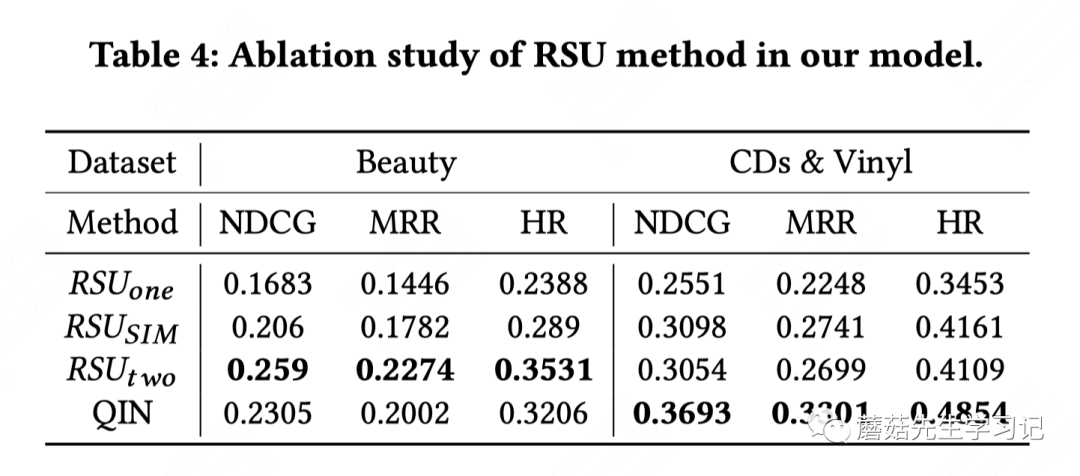
RSU消融实验包括两类:
1)两阶段RSU的有效性,对比RSUone、RSUTwo、SIM等方法。
2)FAU融合注意力机制有效性,对比DIN等方法。
RSU的消融实验如下:
只进行搜索词相关性筛选,效果一般,但作者提到比大多数baseline都好,说明相关性筛选单元还是很重要的;
只进行和target item的相关性搜索(忽略搜索词),效果比好,说明SIM方法直接迁移到搜索场景,不考虑搜索词本身,效果也不错,但在搜索场景这种大部分item都不相关的场景下(意味着序列要用非常长可能才能提取到有效行为),这种方法线上性能压力非常大;
先进行搜索词相关筛选,再进行target item相关搜索,比起效果还更好,说明不仅仅是算力问题,两阶段筛选对于噪声过滤还是非常有用的。理想情况下,算力无限、相似性计算能力没有折损,理论上SIM效果不会输给,但实际情况是检索不完美,容易有信息折损,也会引入一些噪声。
QIN和没太理解差异在哪,包含关系?文中也没说清楚。暂时不展开。
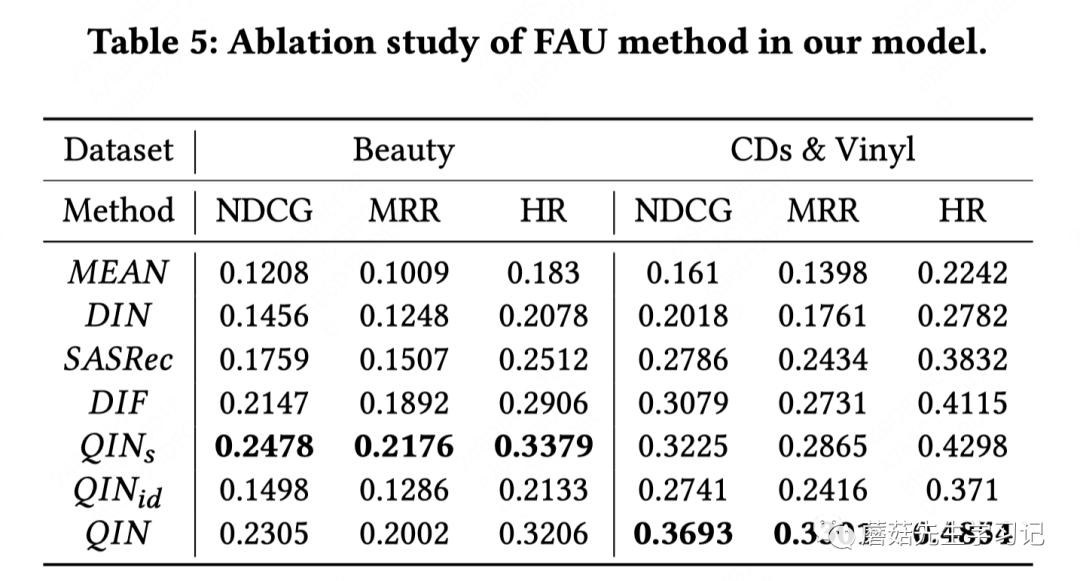
FAU的消融实验包括两个部分:
user engagement引入作为gate的有效性;
属性信息引入对于attention的有用性。
消融实验结论如下:
DIF和QIN中的FAU的差异在于是否使用user engagement,FAU用了user engagement,可以看出效果提升不少,说明user engagement的有效性;
不考虑属性信息,纯用id做attention,效果退化为和DIN差不多,说明属性信息非常重要;
和差不多,只不过前者的user engagement是标量,不可学习,也进一步说明user engagement的有效性。
参数实验
id和属性attention之间的参数可以调参:
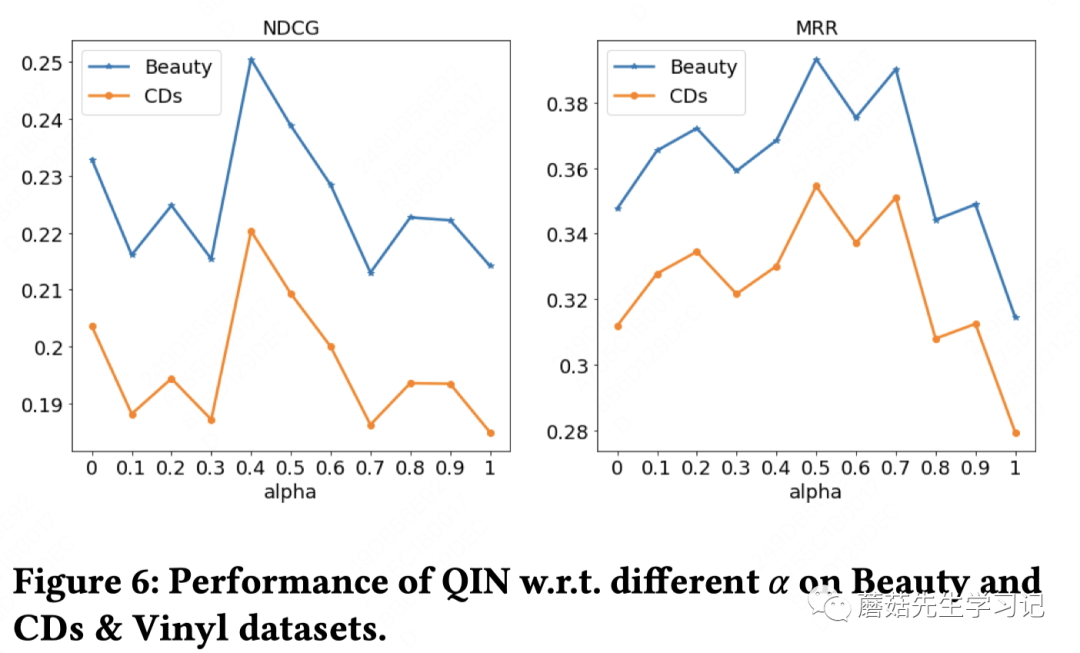
差不多55开的时候效果最好。等于0时完全不依赖ID特征,等于1时完全不依赖属性信息,也都有一定效果。但都说明了属性信息在搜索场景注意力机制设计上很重要。
线上AB实验
FAU中的user engagement采用的是:有效观看(>4s)、换词率。线上核心指标是ctr。
线上实验了1个月,超过100M次搜索。
非常显著的提升,ctr+7.6%;有效观看+24.1%和换词率-7.2%。非常夸张的提升。

Conclusion
本文提出的方法QIN,整体上insight是比较直接、清晰和符合直觉的。核心是“两阶段相关性检索”、“引入属性信息和engagement指标来设计attention结构”,方法比较简洁,有一定适用性。但具体落地,还是比较依赖“类SIM架构”的落地,工程实现上有一定壁垒。
我们回过头来看QIN和两类主流的序列建模方法DIN和SIM的差异。
DIN:DIN本身的注意力机制、引入零向量的DIN变体ZAM[2],从一定程度上看也具备一些和目标item的相关性计算能力。但是都不够直接和彻底,只是通过注意力分数弱化噪声或通过零向量来软干预。没有显式地建模和搜索词的相关性。
SIM:SIM的设计出发点个人认为是性能的考量,通过一阶段的检索来优化DIN对于长序列的计算复杂度问题。不考虑性能因素,理想情况下,能力天花板是DIN。当然,如果DIN结构不能适配场景特点,即:DIN本身不一定能捕捉精准偏好,反而因为长序列造成噪声问题,此时SIM才有可能突破DIN天花板的。但这一点在搜索场景下是不一样的。搜索场景下做检索是为了过滤历史行为中和目标query不相关的item,是为了降噪。尽管形式上都是检索,但是设计出发点不一样,也意味着QIN的天花板不是DIN,直接套用DIN用于搜索场景长期行为序列建模实践中收益是比较小的。从序列中提炼出和目标query和目标item有关的用户偏好信息,对于充分利用用户长期兴趣来精准预估本次用户搜索需求是很关键的。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

References
[1] CIKM2023: Query-dominant User Interest Network for Large-Scale Search Ranking
[2] Qingyao Ai, Daniel N Hill, SVN Vishwanathan, and W Bruce Croft. A zero attention model for personalized product search. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, pages 379–388, 2019.


















 2531
2531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









