







全文1.2W字,PC阅读戳:https://f0jb1v8xcai.feishu.cn/wiki/LPlAwm6vSiesFBkysh8csZYfn1g

1. 重排Overview
搜索推荐广告的基础架构和知识我们在 电商搜索全链路(PART I)Overview 以及 阿里淘宝:重新审视搜索粗排 中已经有相关介绍,这里直接进入主题。
重排一般是离用户最近的一个环节(有些场景还有混排),因此往往重/混排就能决定这次推荐的结果,所以它称作『生死判官』也不为过。
其定位是对精排模型打分后的top-N候选进行重新排序,从上下文listwise的角度系统建模最优收益,然后重新生成TOP-K个物品的序列展现给用户。
为什么需要重排。精排的思路是通过对商品打分,按照这个打分从高到低进行排序,打分越高的物品价值越高 -> 展示位置更靠前 -> 产生的实际收益更大。但这套逻辑有一个严重的缺陷,就是物品的上下文信息会极大影响用户决策。
举一个快手短视频的例子,比如第一条视频是将军对于台海危机的言论,但如果下一条视频推荐了小姐姐视频那就相当不合时宜,因为这两个视频没有连贯性,推荐效果较差。那如果下一个推荐视频是比较燃的音乐,再在后面推荐小姐姐跳舞的视频,那么这时候内容的连贯性就较好,用户不会觉得突兀。
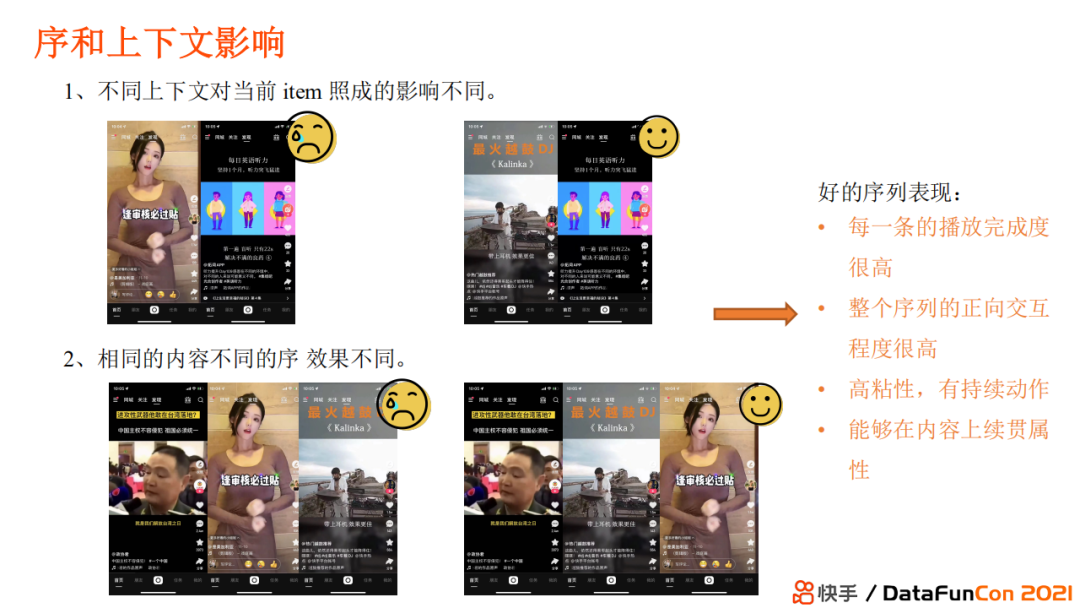
具体而言,重排模块需要处理的问题:
不再同召回、粗精排一样仅仅考虑 的pair关系,而是 的相互影响,如何使得整个展现序列价值最大化;
在不同的场景中,如何合理定义『价值』,什么是好的价值,业务意志如何体现;
越来越多业务参与其中,如何恰当地分配流量。除了各自业务主目标(GMV、时长等),还需要考虑更多的多样性、发现性、用户体验等,也许还需要背负一些业务策略(如加权、降权、bad case过滤等)
如何更加及时感知用户的行为喜好,迅速响应调整模型策略。
既然目标明确了,那么效果如何评估,能与我们最终的目标对应上?
精准度:NDCG。这个衡量指标与精排的一致,目标是将用户可能点击/购买的商品尽可能排到更前面,效率更高,公式如下
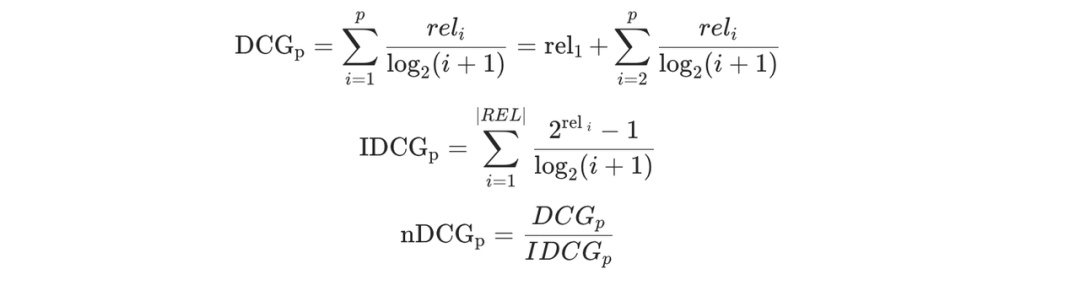
多样性:α-NDCG。来源于2008年在SIGIR发表的《Novelty and Diversity in Information Retrieval Evaluation》,本质还是DCG的逻辑,优化了对于增益的定义。
2. 重排模型发展
重排的模型发展主要有
pointwise模型。和经典CTR模型基本类似,如DNN、WDL、DeepFM。与精排模型相比主要优势在于实时更新的模型、特征和调控权重。随着工程能力的升级,ODL和实时特征的引入带来了较大提升;
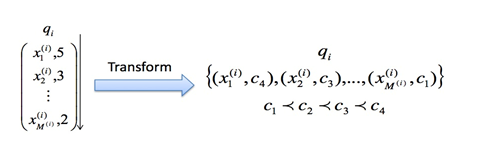
pairwise模型。通过pairwise来对比物品对之间的顺序关系,如GBRank、RankSVM、RankNet等,但pirwise的模型没有考虑列表的全局信息,而且极大地增加了模型训练和预估的复杂度。

listwise模型。建模输入物品列表的整体信息和对比信息,并通过 list-wise 损失函数来比较序列物品之间的关系。LambdaMart、MIDNN 、DLCM、PRM 和 SetRank分别通过 GBT、DNN、RNN、Self-attention 和 Induced self-attention 来提取这些信息。随着工程能力的升级,输入序列的信息和对比关系也上提到排序阶段中提取。
generative模型。主要分为两种,一种考虑了前序信息的,如 MIRNN 和 Seq2Slate 都通过 RNN 来提取前序信息,再通过 DNN 或者 Pointer-network 来从输入商品列表中一步步地生成最终推荐列表。
diversity模型。有很多工作考虑最终推荐列表里的相关性和多样性达到平衡,如Hulu,youtube的DPP模型。
2.1 基于Greedy Search
Greedy Search策略,每一步选当前状态下目标效用函数最大的内容加入候选列表中,直到候选列表长度满足要求。贪心策略的每一步都采取的是局部最优策略,并不能保证产生是全局最优解。
2.1.1 MMR
[CMU SIGIR 1998] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries
https://www.cs.cmu.edu/~jgc/publication/The_Use_MMR_Diversity_Based_LTMIR_1998.pdf
在论文中定义了经典的MMR标准:
其中Q是搜索query,D是候选物品(如精排预估后的结果),S是MMR算法已经选取过的物品。Sim1用来衡量物品和query之间的相关性,Sim2用来衡量当前候选物品Di和已经选取的物品的最大相似度。
从公式可以看出,MMR的核心思想是Greedy Search,贪心生成top集合。最开始先选取和query相关性最高的item,然后之后的每次选取,都是与query相关性最高且与已经选取物品的最大相似度最低的。前者保证了相关性,后者保证了多样性,用参数 用来调控对相关性和多样性的偏向权重。
MMR在Microsoft、Amazon 、JD的搜索推荐系统都成功落地
2009 (Microsoft) (WSDM) Diversifying Search Results
2018 (Amazon) (RecSys) Adaptive, Personalized Diversity for Visual Discovery
2.1.2 DPP
[Google CIKM'18] Practical Diversified Recommendations on YouTube with Determinantal Point Processes
[Hulu NIPS'18] Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity
DPP(Determinantal Point Processes)模型输入是物品的精排分数,以及两个物品之间的pairwise距离(可以用jaccard、emd等计算得到),然后生成topk结果,优化目标是多样性和效率。
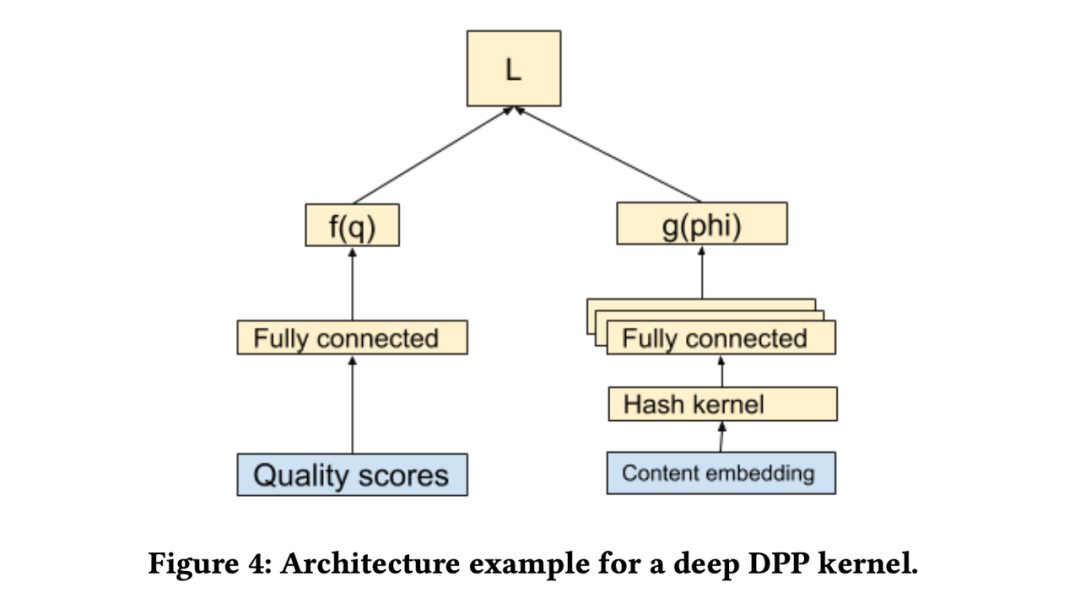
DPP的数学推导逻辑比较复杂,包括基于Kernel Parameterization和基于深度学习的版本,这里只看DL版本的。
其中,f函数的输入为精排模型最后一层隐藏向量,g函数的输入为物品的向量表示。
2.2 基于上下文Listwise
Context-aware List-wise Model,通过建模精排模型生成的Top-N个物品间的互相影响关系,来生成Top-K结果。包括miRNN, DLCM, PRM, EdgeRec, PRS, AirbnbDiversity等,成功应用到淘宝搜索、推荐、Airbnb搜索的重排序中。
2.2.1 miRNN
[阿里IJCAI'18] Globally Optimized Mutual Influence Aware Ranking in E-Commerce Search
https://arxiv.org/abs/1805.08524
淘宝搜索重排序场景,需要实现GMV最大化。作者使用RNN来建模context信息,基于商品价格、商品在展示列表中成交概率,生成topk列表结果达到最优GMV。
这个问题可以拆解成两个小问题( 是商品价格):
估计每个商品在topk列表中成交的概率,
如何找到最优topk的序列
对于问题1,作者采用RNN来建模,即考虑前面已经选取的物品对后面商品购买的影响。
如何考虑context信息?引入全局特征(global feature),作者将传统item自身的特征称为local feature。以price为例,global feature的price定义为,当前item的price在候选集合下的归一化
price归一化后如何使用?price由于是连续值,会将其离散化后做embedding
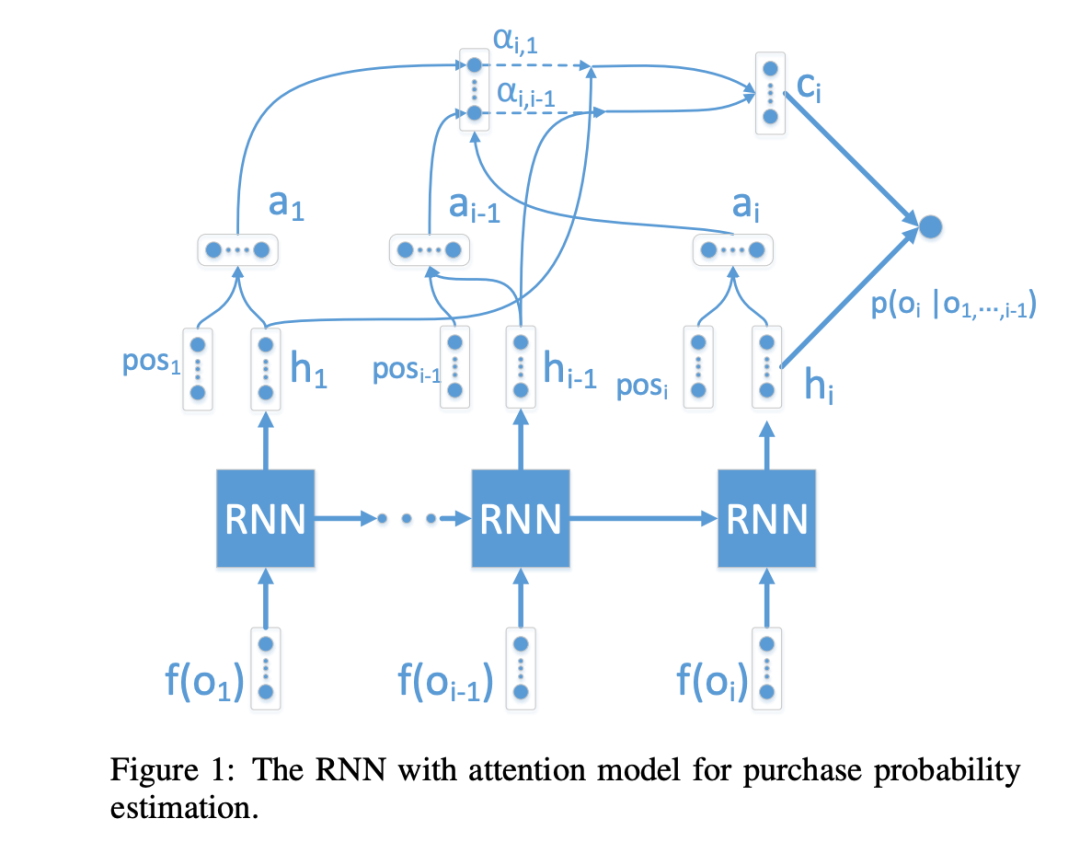
对于问题2,基于学习得到的RNN模型,可以通过Beam Search来解决。
2.2.2 DLCM
[SIGIR'18] Learning a Deep Listwise Context Model for Ranking Refinement
https://arxiv.org/pdf/1804.05936
搜索场景下,传统LTR模型对每个query而言不是最优的(即使整体平均效果不错),造成这种现象的原因是,不同的query对应的相关文档的特征空间可能具有不同的分布。
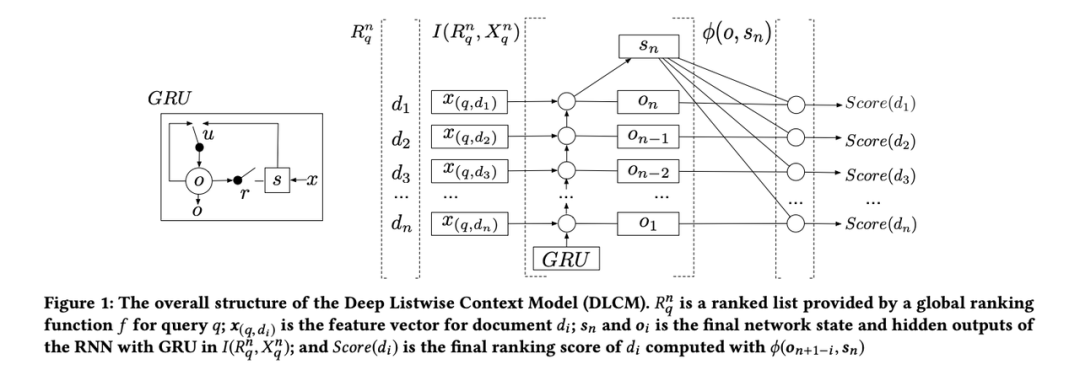
所以作者提出的DLCM主要做法是,通过使用GRU模型来学习精排之后topk商品的context信息,用于rerank。DLCM主要包括三步:
通过传统LTR模型,得到精排的topk item;
使用GRU从后往前的顺序学习topk个item的关系(从后往前可以最大程度地保留精排分高的物品信息到RNN传递的最后阶段);
根据GRU模型输出进行rerank学习;
就是GRU网络最后的编码向量,然后利用类似attention的方式,得到最后每个文档的输出分。
2.2.3 Seq2Slate
[谷歌 ICML'19] Seq2Slate: Re-ranking and Slate Optimization with RNNs
https://arxiv.org/abs/1810.02019
谷歌 视频推荐场景,之前的模型都是 encoding 的方式,还没有尝试 decoding 的工作。
提出使用 seq2seq 的架构来解决重排推荐问题,称为 seq2Slate。利用 point network,根据用户前面看过的视频,来预测下一个观看的视频。
Pointer Network:是对 seq2seq+attention 机制的简化,可以解决 seq2seq 的框架无法解决输出序列的词汇表会随着输入序列长度的改变而改变的问题。一句话解释:传统带有注意力机制的seq2seq模型输出的是针对输出词汇表的一个概率分布,而Pointer Networks输出的则是针对输入文本序列的概率分布。
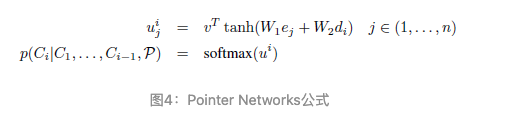
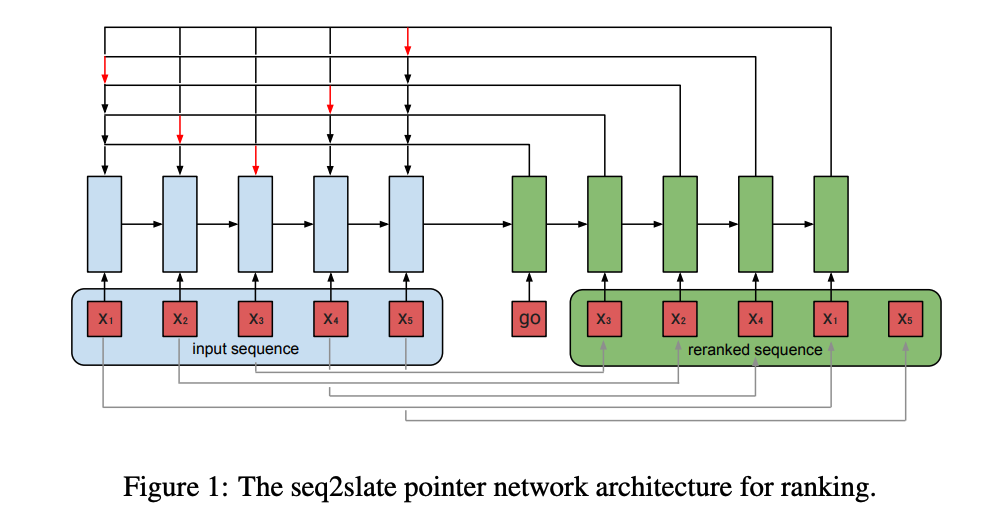
输入层:输入是候选集合列表
Encoder:RNN模型,从前往后编码
Decoder:go 表示开始预测,每次从未预测的样本中找出最相关的一个(箭头表示当前需要预测的样本,红色箭头表示当前被预测为最好的一个样本。如果一个样本已经被预测,下一次则不考虑了)
样本的输入顺序可能影响最终预测结果
2.2.4 PRM
[阿里 RecSys'19] Personalized Re-ranking for Recommendation
https://arxiv.org/abs/1904.06813
通常的排序pointwise地对item进行打分,这样仅仅考虑了用户和单个物品之间的关系,而没有考虑排序列表物品之间的相互影响。也有工作使用RNN对序列进行建模,但缺点是如果两个物品相隔较远,则不能很好的学习。使用Transformer对精排后结果进行个性化重排序。
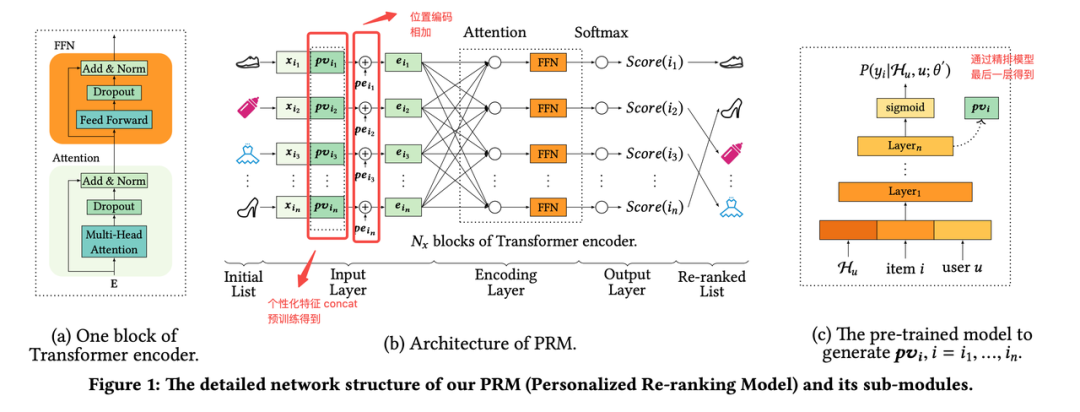
对精排输出的向量分,拼接上位置编码得到各个item的输入,然后利用Transformer进行编码,最后通过一层全连接层和softmax得到每个物品的重排序得分。
输入层:输入是由精排模型打分排序好的列表 ,特征包括
item特征矩阵
个性化矩阵:user x item 维度的特征,由预训练模型得到(可以通过精排模型产出向量)
位置特征:可训练的矩阵
编码层:Transformer
输出层:
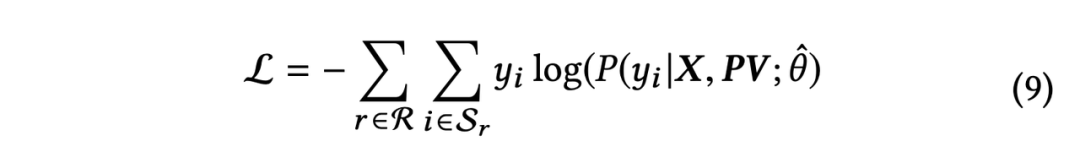
2.2.5 EdgeRec
[阿里 CIKM'20] EdgeRec - Recommender System on Edge in Mobile Taobao
https://arxiv.org/abs/2005.08416
阿里淘宝首猜推荐场景,这里和之前的模型有些不一样,EdgeRec是部署在client 端上的模型,之前的模型计算我们一般都是部署在 server 端(这种模式下,client 端搜集用户在端上产生的行为特征,再交给 server 端上的模型进行计算,最后由 server 将计算排序好的结果返还给 client)。
正如上述所说,传统模式下的计算存储资源和时效性是非常严重的问题,特别是在大促节日。
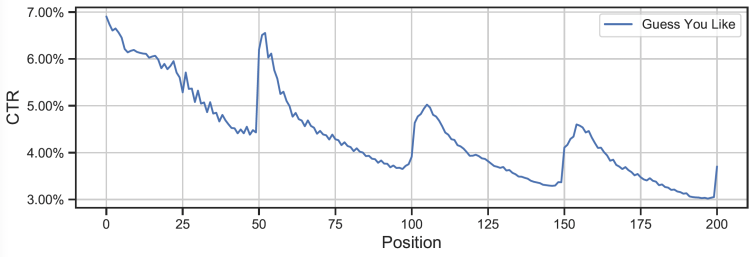
另外,目前的搜索推荐一般是分页请求的形式,即只有在翻页之后才会有调整商品列表的机会,无法及时响应用户的兴趣变化(可以看下图,翻页之后 ctr 会突涨)。比如用户在第4个商品的交互表明不喜欢“摩托车”,但是由于分页请求只能在50个商品后,那么当页后面其他“摩托车”商品无法被及时调整。
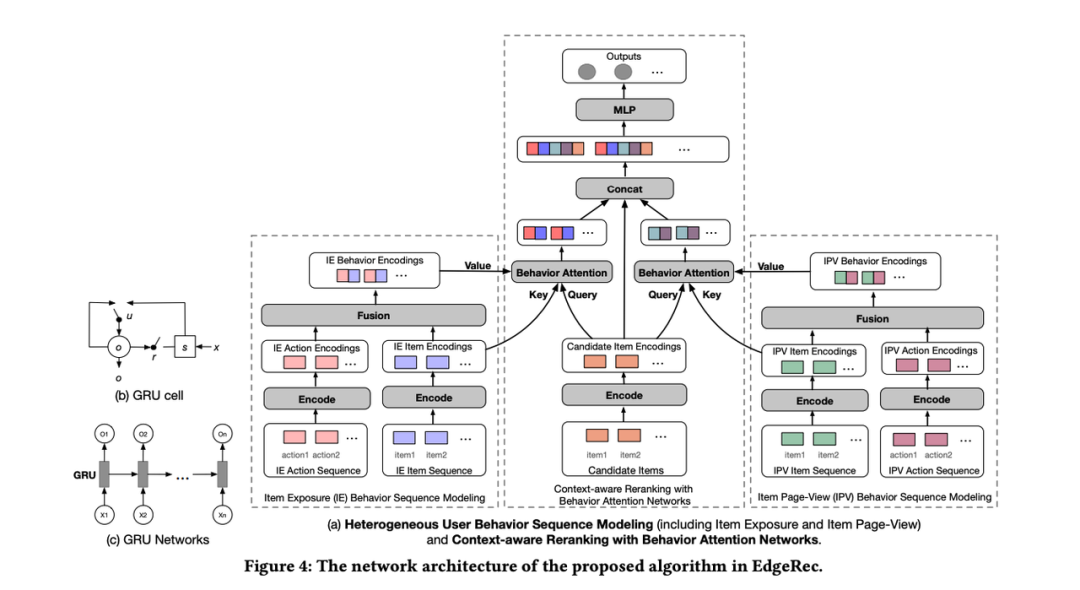
关于架构和系统的设计不在本文的讨论范围之内,具体参考论文原文,这里重点介绍重排模型,看是如何实时改变商品展示顺序的。
首先第一个模块是Heterogeneous User Behavior Sequence Modeling,用于建模端上实时用户行为,包含了商品曝光行为序列建模和商品详情页行为序列建模两部分。
接下来就是利用这些实时特征的端上重排建模,中间为待排序的候选商品集合,过 GRU 得到embedding;左侧为实时曝光序列的建模;右侧为用户点击进去商品详情页的建模;
然后通过 target attention去融合,也就是让待排序的商品看看之前用户都喜欢/不喜欢什么样的商品,调整后面出的顺序。
2.2.6 PRS
[阿里 2021] Revisit Recommender System in the Permutation Prospective
https://arxiv.org/abs/2102.12057
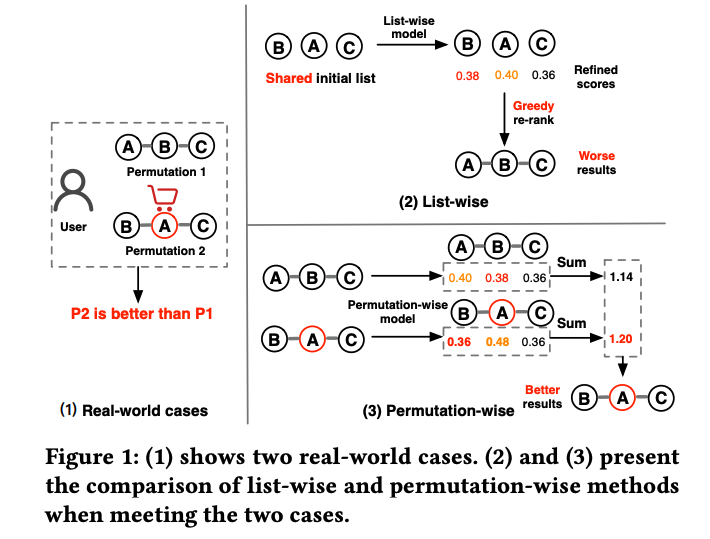
阿里推荐场景。来源于一个现实观察:在给同一个用户展示推荐列表时,不同的商品展示顺序会严重影响用户反馈。
如下图所示,两个列表A-B-C和B-A-C包含相同的三个物品,但其排列并不相同,用户对B-A-C排列有交互,而对A-B-C这样的排列没有交互,一个可能的原因是,将较贵的B物品放在较为便宜的物品A前面,可以增加用户对于购买物品A的欲望,那么这种由于排列不同导致用户反馈不同的影响因素
因此对于重排而言,一种更好的方式是考虑所有可能的排列方式,对每一种排列的结果进行打分,并选择评分最高的排序列表结果展示给用户。但这样很明显会存在两个问题
计算爆炸问题:从长度为 n 的集合中选取 m 个推荐商品,List-wise 重排模型的搜索空间是 ,而本文提出的 Permutation-Wise 的空间是
列表评估问题:针对Permutation-Wise产出的结果,如何准确评估?
论文作者提出一个两阶段的重排框架 PRS,分为 PMatch 和 PRank 两阶段。
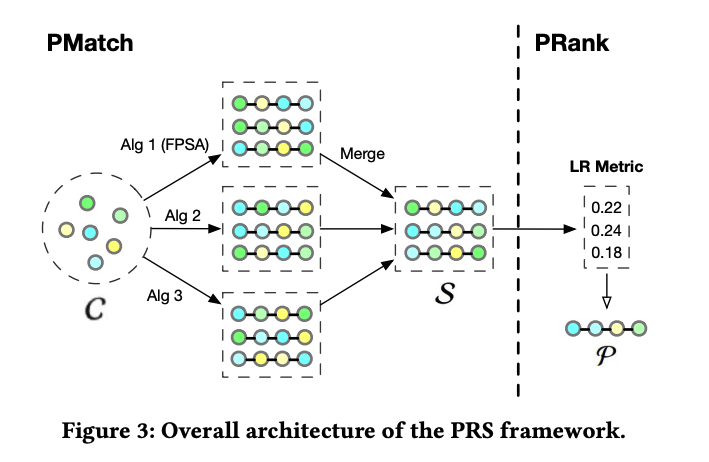
PMatch:使用 FPSA (Fast Permutation Searching Algorithm) 算法生成候选商品排列组合。具体而言,
离线训练一个模型,预测物品的点击概率pctr 和 继续浏览的概率
在线serving 时,使用 beam-search 方法生成 k 个长度为 n 的候选队列,计算 累加曝光率,期望增加浏览深度, 累加每个 item 的 曝光率*点击率,曝光率会受前边序列影响,两者都是越大越好。
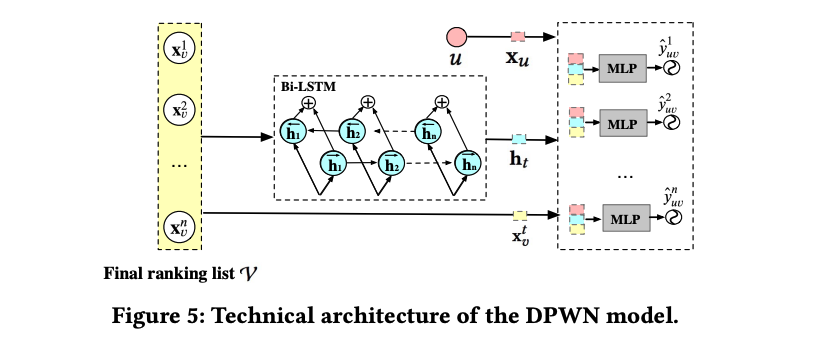
PRank:排序阶段使用带 bi-lstm 结构的 DPWN 模型,计算队列中每个商品的点击率 pCTR,然后将排列中所有的 pCTR相加作为这个排队的打分,选择 pctr 和最高的作为胜出结果。
2.3 基于强化学习
留坑
3. 重排在业界落地实践
虽然以上基本都是在业务线上实践后发的顶会,但论文毕竟还是论文,涉及实操经验、踩坑分享的内容相对较少。下面借助几个公开的分享,整理下大厂中重排模块的实践。
3.1 快手短视频推荐多目标排序
多目标排序在快手短视频推荐中的实践[1]
场景是快手短视频推荐,包括发现页、关注页、同城页。
短视频推荐的主要优化目标是提高用户的整体的 DAU,提升用户留存。具体手段就是提升使用时长/正向反馈(如收藏、点赞、评论、完播率等),减少负向反馈(如dislike、skip等)。
精排多目标排序
经历了手工调参融合 -> 简单ML模型 -> LTR模型 ->
手动融合公式:score = a*pEvtr + b*\pLtr + ... + g*f(pWatchTime),缺点在于过于依赖人工规则设计和调参,缺乏个性化;
树模型Ensemble融合:引入 pXtr、画像和统计类特征,利用GBDT模型拟合label。缺点是树模型表达能力有限,且无法 online learning。
NN模型:双塔DNN,使用 a*pEvtr + b*pLtr + ... 拟合组合收益label,w = a*effectiveView + b*like + ...
损失为加权logloss:
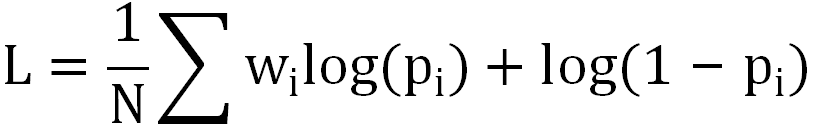
端到端LTR:把上述双塔模型替换为交叉精排模型,尝试了pointwise和pairwise的loss学习
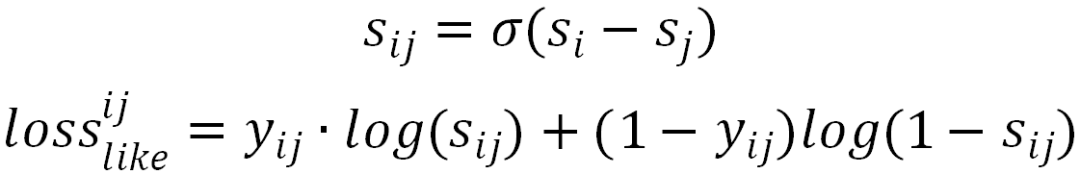

重排序
重排需要考虑视频之间的彼此影响
listwise rerank:对top6的候选使用transformer进行建模,weighted logloss学习
强化学习:
端上rerank:
3.2 【2021】快手短视频重排序
快手短视频推荐的重排分享,整体框架如下
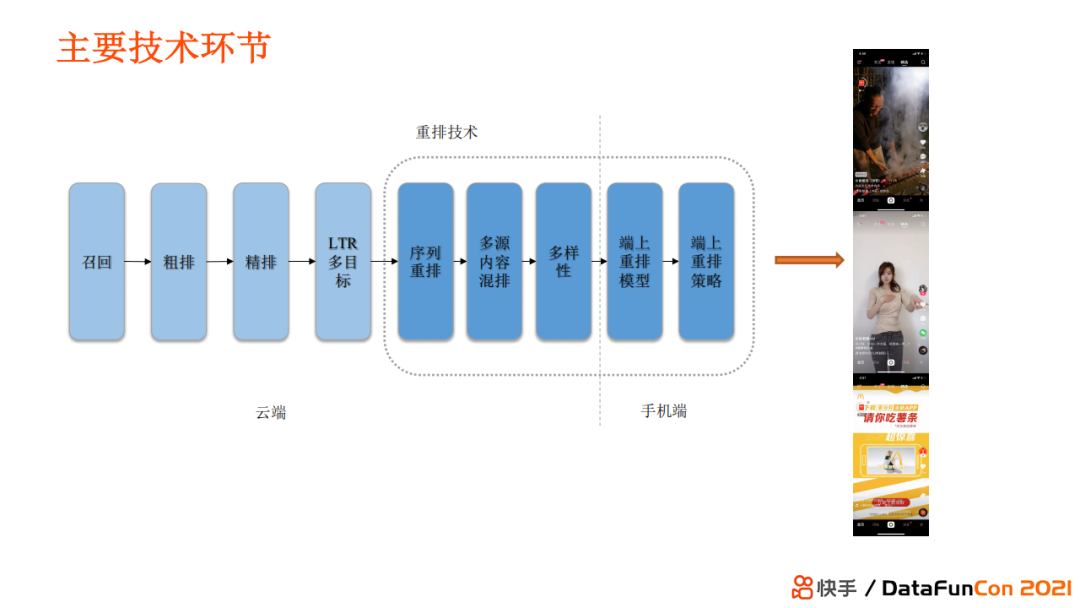
可以看到,重排整体包括服务端(序列重排、多源内容混排、多样性)和手机端(端上重排模型&策略)两部分。
3.2.1 序列重排
首先如开篇所说,如何定义一个好的序列极为重要,决定了优化方向。快手短视频的标准是:认为好的序列完成度很高,整个序列的正向交互程度很高,用户具有高粘性,有看完视频后下刷的意愿,且序列在内容上具有序贯属性。
序列重排整体采用 GE(Generator-Evaluator) 范式,generator 从 top50中生成多种候选序列,然后使用 evaluator 对候选序列依据整体价值进行打分。
3.2.1.1 Generaotr
常用的生成方式是 beam search,顺序地生成每个位置的视频,具体策略是通过前序已生成的视频来选择模型预估的最优 topk 视频。其他的一些生成方式如前面介绍过的 MRR 多样性召回、Seq2slate 召回等等。
快手这里使用的是多队列权重。线上之前的基线是对各队列权重手工调参(这时候参数是固定的),但更优的应该是参数是自适应调节的(比如某段时间我需要推荐沉浸时间较长的视频,而另外一段时间需要低成本高获得感的视频内容,那么前者需要更多关注观看时长的目标,互动可以进行折算,而后者需要互动、点赞率较高)。于是可以对参数进行协同采样得到不同的序列。
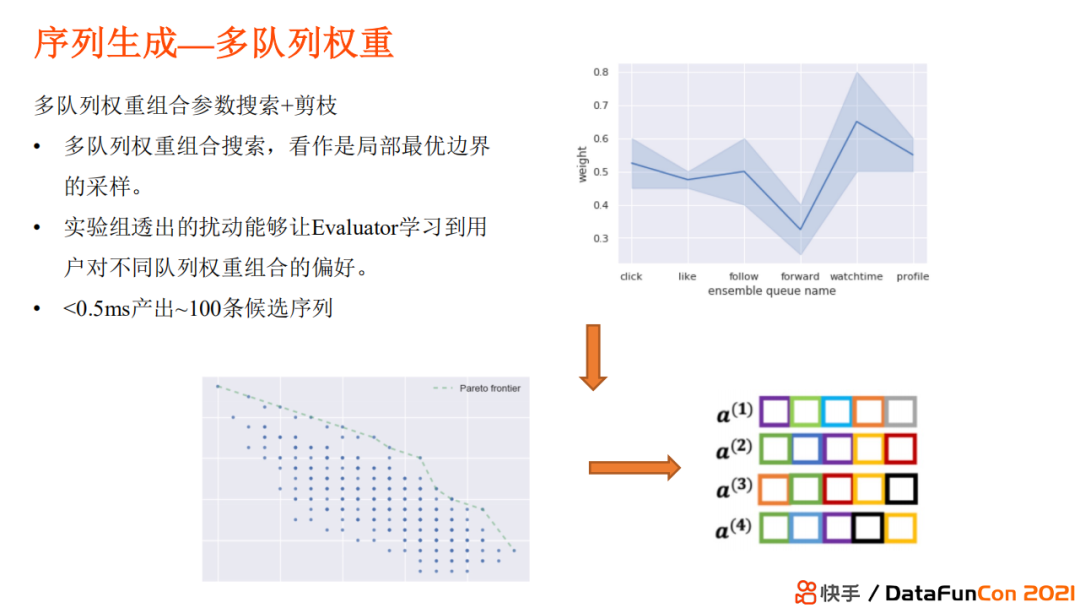
3.2.1.2 Evaluator
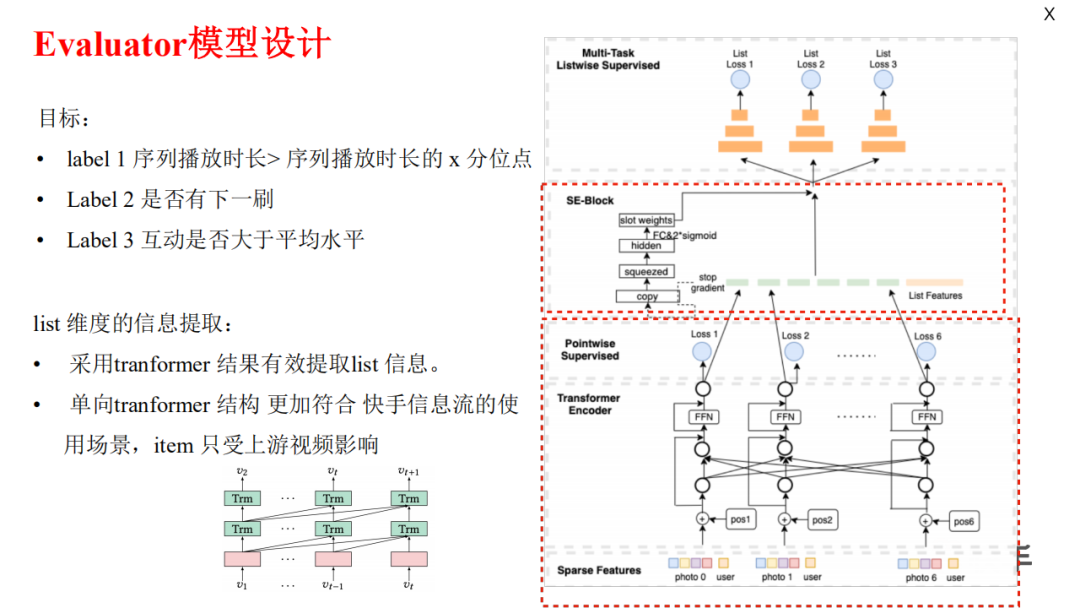
Evaluator 使用单向 transformer,因为用户刷视频动作是单向的,下游视频信息对上游视频没有增益。
整体模型分为两层,
第一层使用单向 transformer 建模item,并对每个 item 做一个 loss(类似精排pointwise的 ctr 预估?文中没具体说);
第二层是对上一层得到item embedding,加上 list feature建模整体序列,share-bottom 形式做多目标多任务
3.2.2 多元混排
混排要解决的问题是,如何将各个业务返回结果恰当的组合,得到综合价值最大的返回序列。
最基础的方案,各业务通过固定位置的形式获取流量。但这样缺乏个性化,对用户和平台而言都有损效率。进一步的,LinkedIn 一篇论文中(KDD 2020 | Ads Allocation in Feed via Constrained Optimization)将其转化成在用户价值体验大于C的前提下最优化营收价值,具体参见原论文。
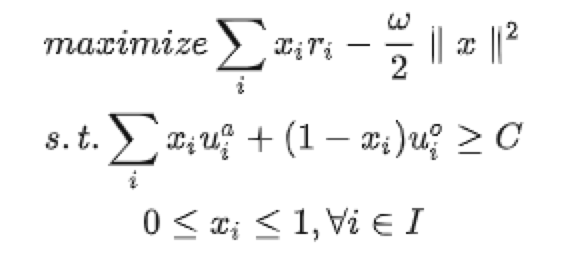
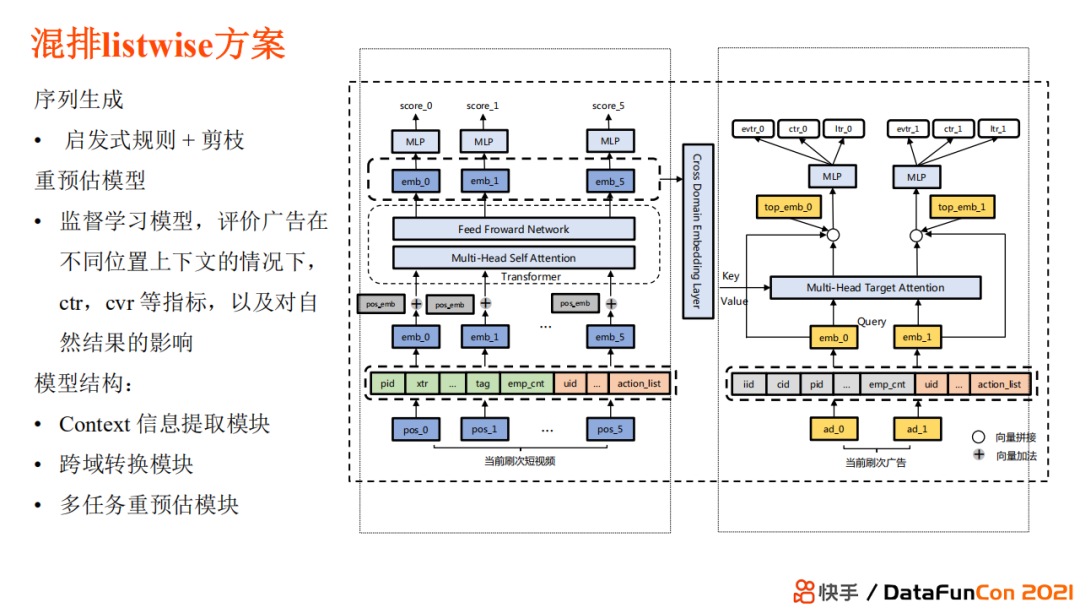
混排 listwise 方案采用generator-evaluator 的范式,模型包括三块:
contetx信息提取模块:对自然视频内容重预估 (精排模型对商品已经有精准预估,为什么还需要重预估?商品打分会受到它所处的上下文环境的影响,将上下文信息整合才能预估得更加准确)
跨域转换模块:考虑到自然和广告内容属于两个不容域
多任务重预估模块:结合自然内容,对广告进行重预估,衡量它的曝光率、ctr、cvr 等指标,得到一个最佳价值序列
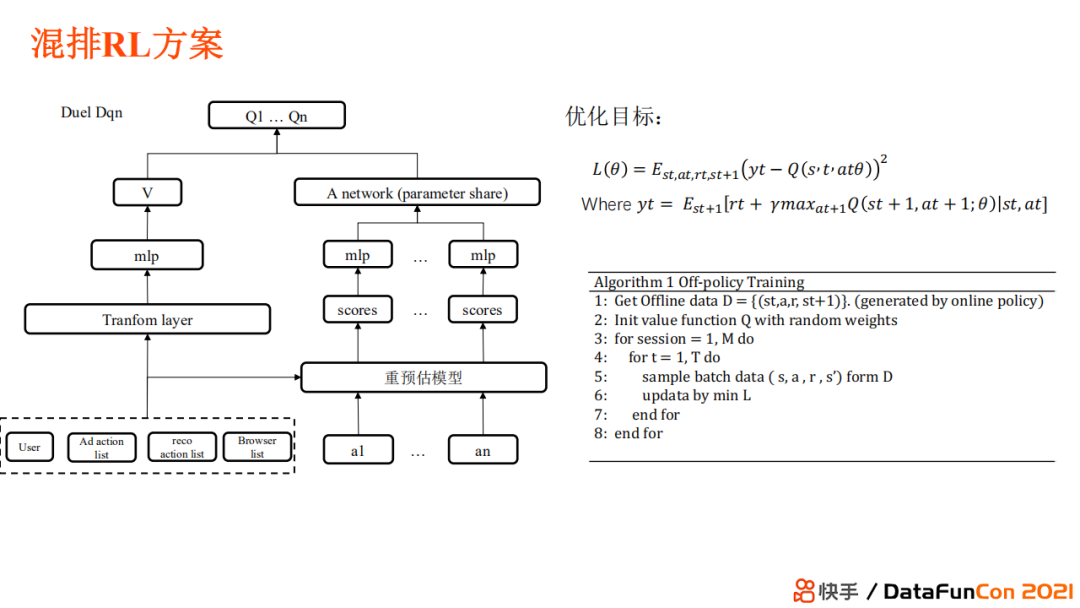
混排 RL 方案首先定义
状态:用户在一个 session 内下刷深度、曝光内容、广告交互历史、内容交互历史、上下文信息以及本刷的内容
动作空间:如第一条、第二条广告放置在哪一位置等(需要满足业务约束) 采用 Duel DQN 方案,优化目标是每一步选择能够达到最终的总和价值最大,reward 是长期价值和近期价值的组合。
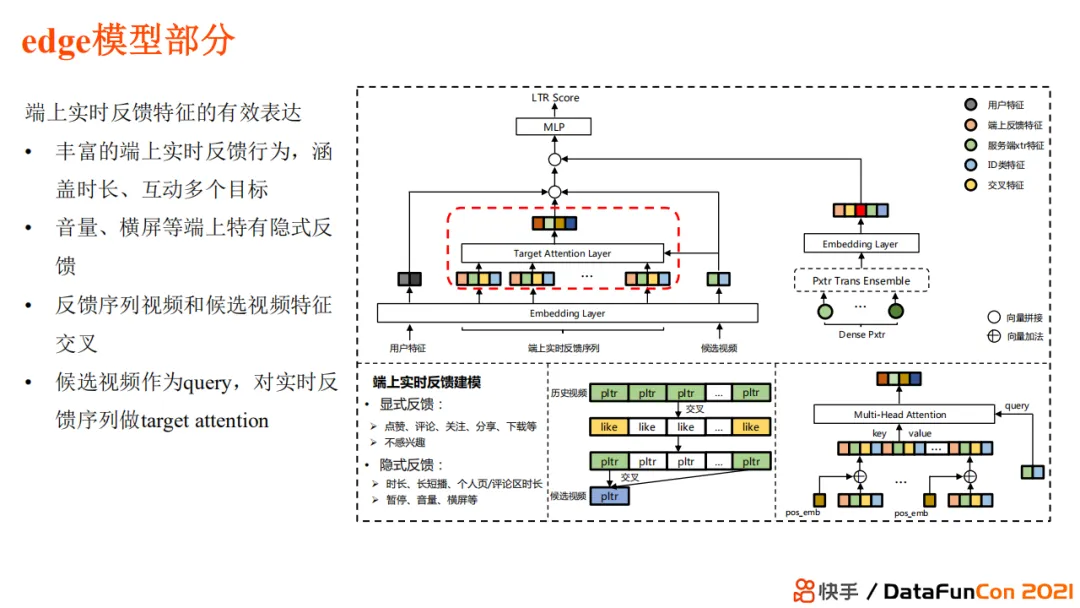
3.2.3 端上重排
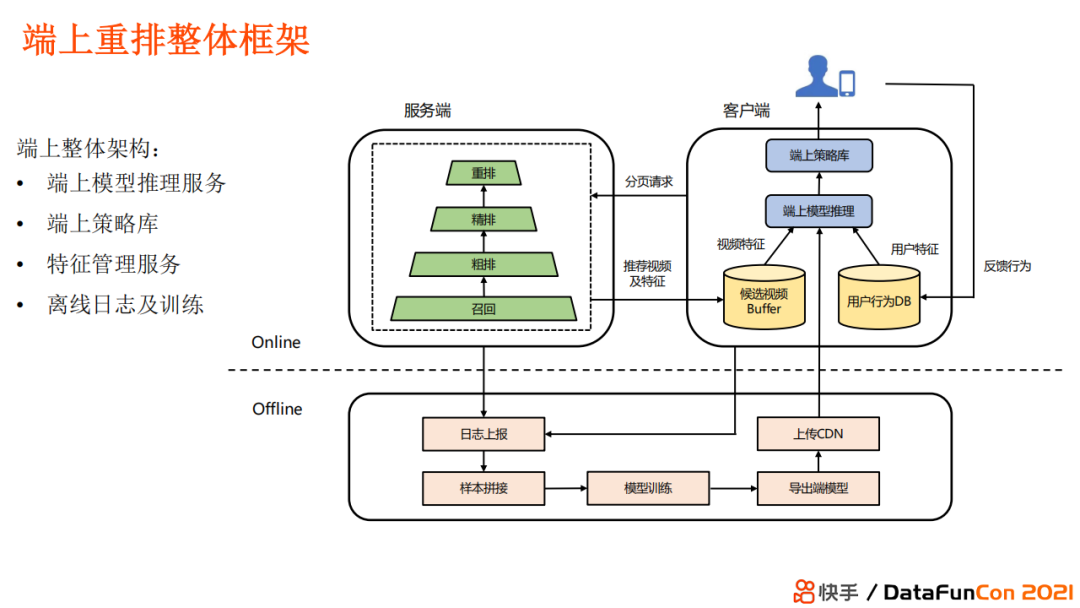
端上重排整体架构如上,
服务端收到手机端发出的分页请求后进行召回、粗排。精排、重排,返回推荐的视频及特征;
端上的推理模型使用候选视频以及特征,加上用户特征和反馈进行预估,最后结合端上策略得到最终混排结果 端上模型可以利用更实时和更充分的反馈特征进行预估
3.3 微信看一看推荐混排
用强化学习做混排建模
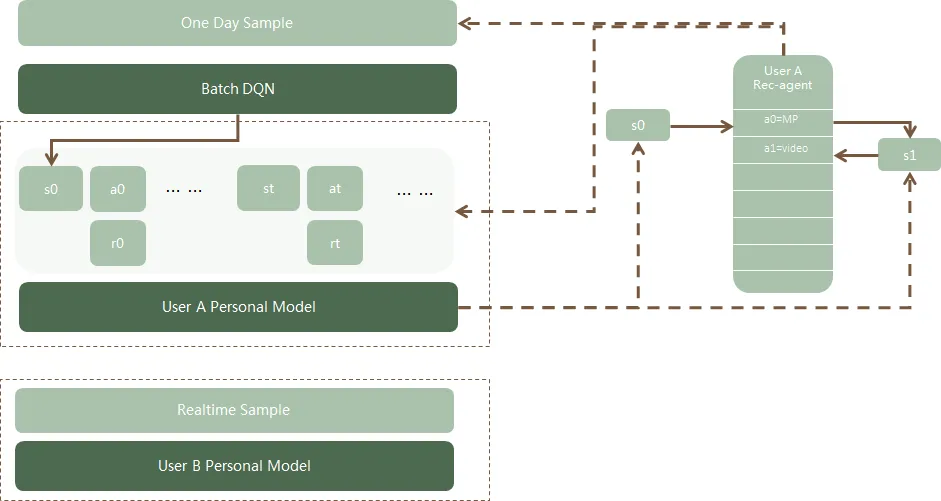
当用户的请求到来时会根据他之前的行为计算隐状态作为此次输入state的一部分,每次选择某个业务作为action,反馈点击作为reward。
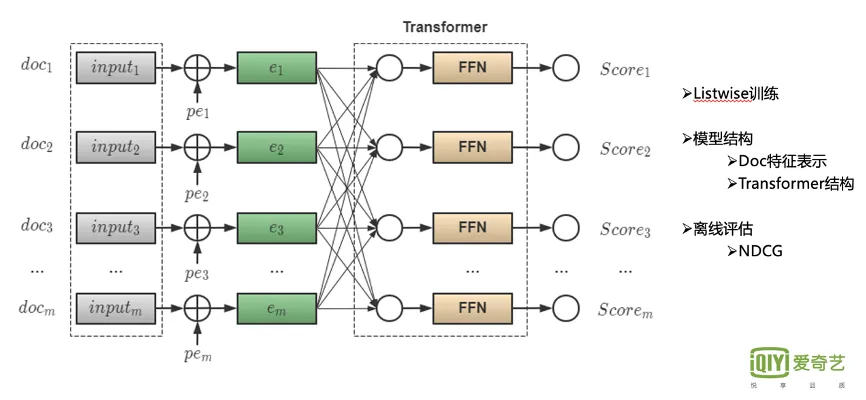
3.4 爱奇艺搜索排序
这篇分享介绍的是爱奇艺搜索整体业务,包括query处理、召回、粗排、精排、重排等。这里只截取重排部分。
之所以要进行重排,是因为精排部分是分片的,没法加入上下文感知。具体模型和PRM类似,离线评估指标是NDCG
3.5 美团搜索重排
Transformer 在美团搜索排序中的实践[2]
模型结构参考PRM
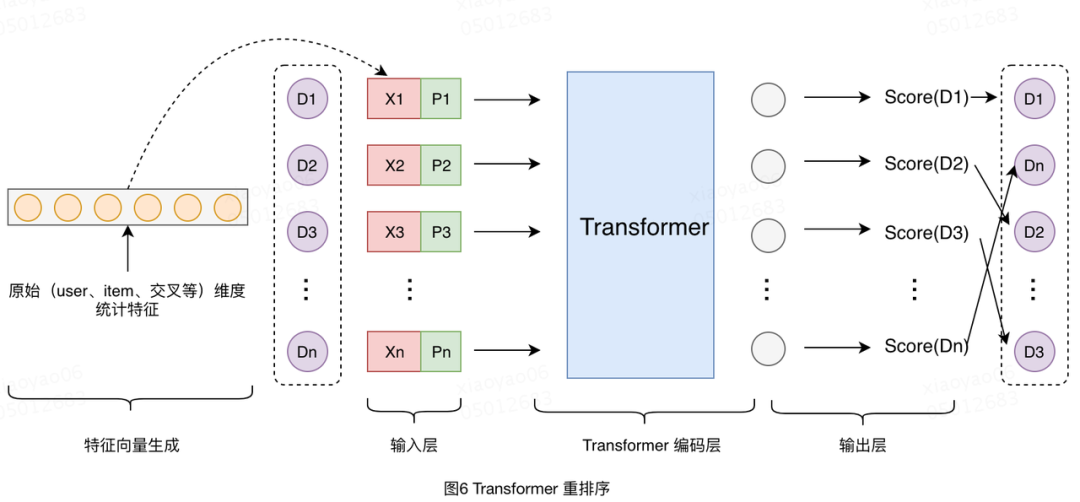

3.6 美团搜索多业务混排
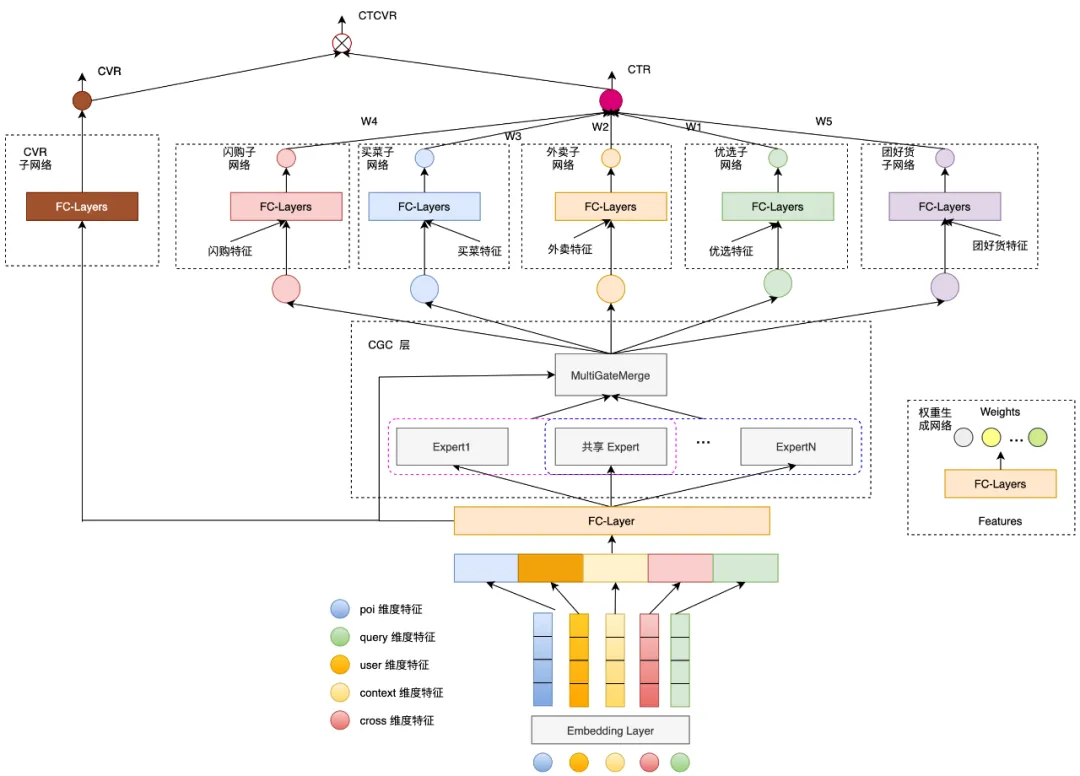
场景是美团首页搜索,当用户搜索一个query时,需要对不同业务商品进行统一混合排序,包括闪购、买菜、优选、团好货等等。
由于多业务的目标其实都是一样的(for gmv),所以这里更多的是多目标多业务建模,如何在模型中利用不同业务之间的共性和特性。
整体模型是ESMM+多子塔结构。
3.7 美团搜索端上重排
端智能在大众点评搜索重排序的应用实践[3]
业务场景是大众点评搜索。相比与云端服务器处理模式,端上模型架构具有以下优势:
支持页内重排,对用户反馈作出实时决策
无延时感知用户实时偏好
更好保护用户隐私 具体到端上重排的任务是,根据用户对前面排序结果的反馈,动态调整下文候选的序列,使得列表页整体搜索点击率达到最优。
3.7.1 模型算法
特征工程和云端模型相差不大
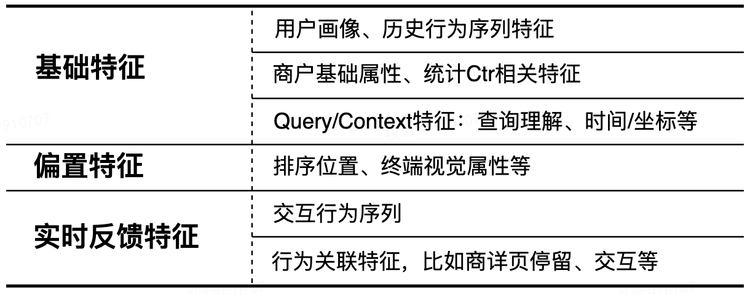
整体采用基于 context-aware listwise的方式进行建模,通过建模精排模型生成的 Top-N 个物品上下文之间的互相影响关系,来生成 Top-K 结果。
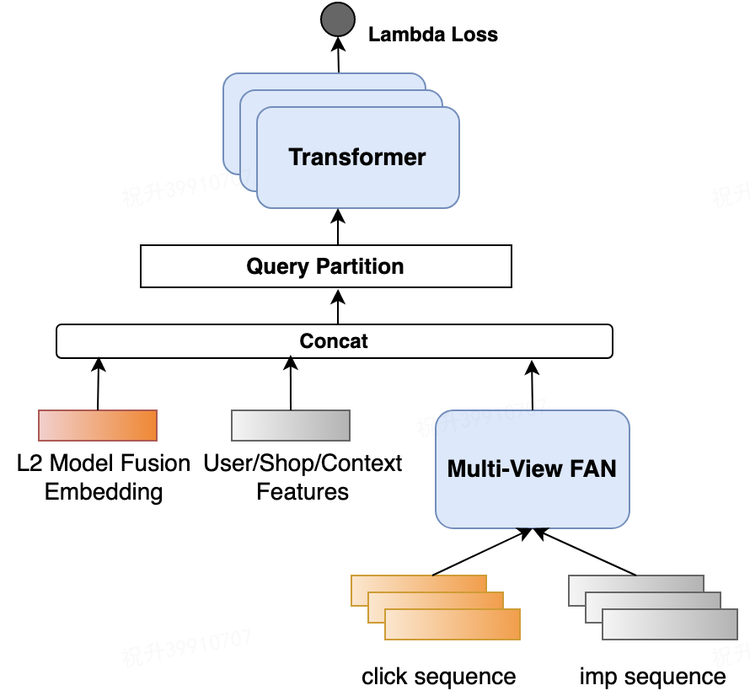
这里面 Multi-View FAN 是对用户反馈行为建模的网络
引入深度反馈网络。拆分正负反馈序列,首先做一次target attention,生成向量表征后作为 Query 和另一个序列做 attention。同时考虑到反馈信号的稀疏性,引入 zero-attention,避免噪声。
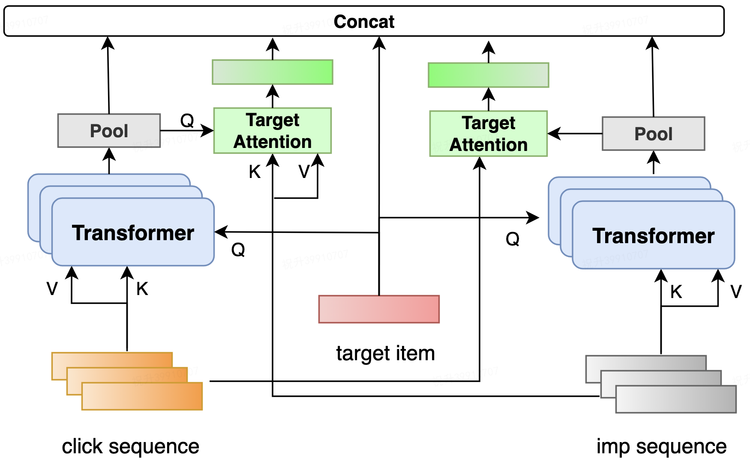
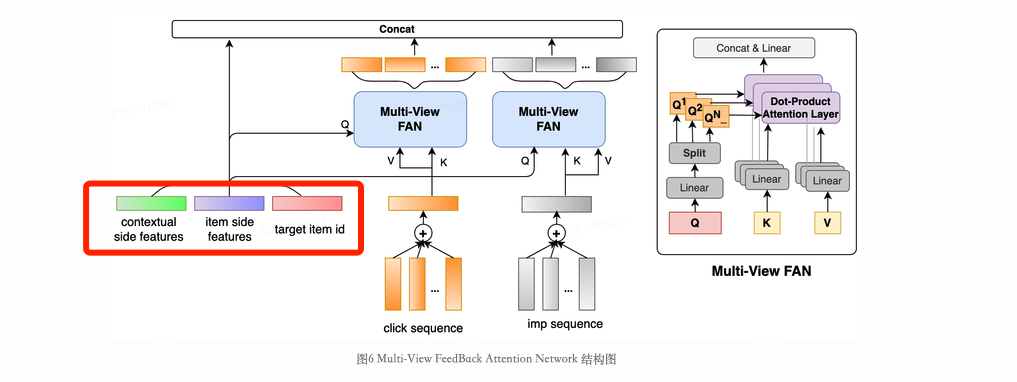
多视角的正负反馈序列交叉建模。多视角指的其实就是候选 item 的价格、距离、环境、口味等细粒度表征,通过对多重维度的建模来更好捕捉用户兴趣。
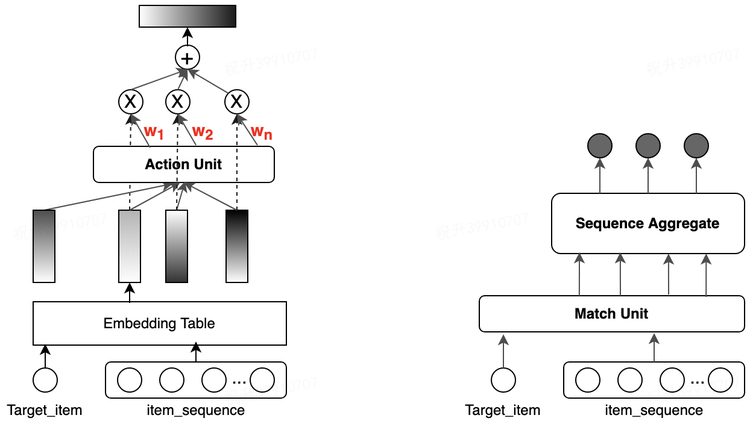
Match&Aggregate 序列特征。可以理解为一种“Hard”的 Attention 方式,提取的形式包括:Hit(是否命中)、Frequency(命中多少次)、Step(间隔多久)等等,除了单变量序列的交叉,还可以组合多个变量进行交叉,来提升行为描述的粒度和区分度。
端云联合训练。服务端精排和云端重排联合训练,可以充分复用大量复杂有效的信息,同时避免计算资源的开销。
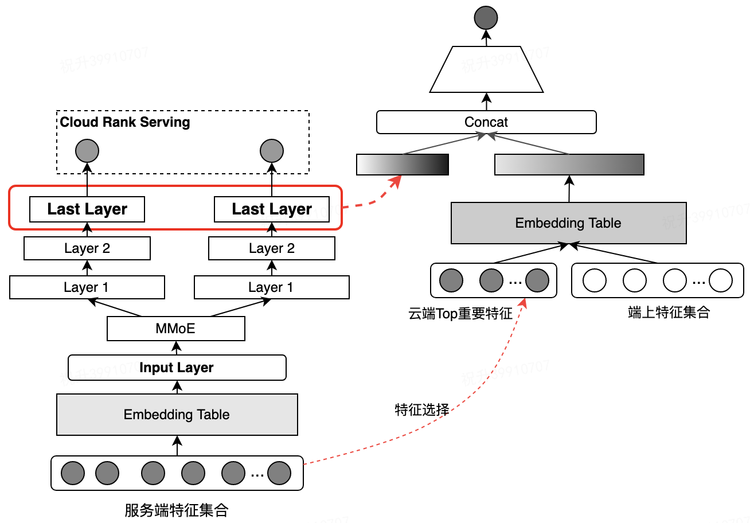
优化目标:CTR。点评搜索关注的是排在页面头部结果的好坏,因此采用 listwise 的 lambda loss,引入 deltaNDCG值来强化头部位置的影响。
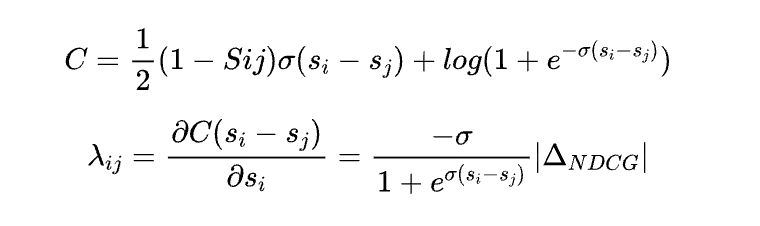
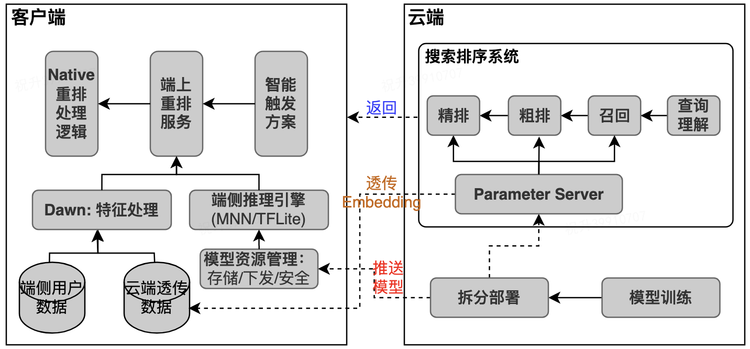
3.7.2 架构部署
APP 的整体大小不超过几百 MB,因此部署在终端的模型必须考虑计算和存储的限制。
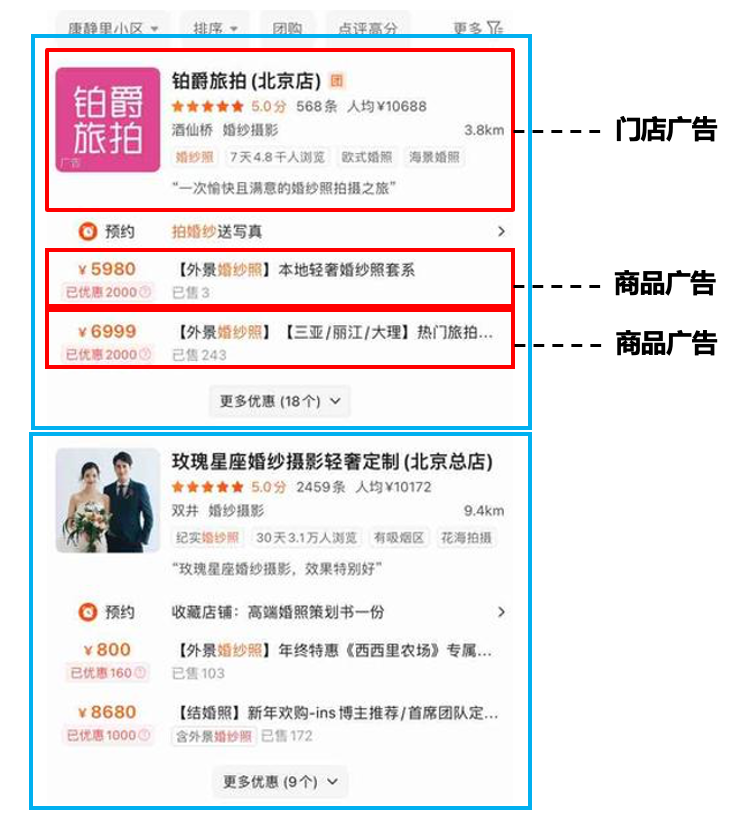
3.8 美团搜索广告混排
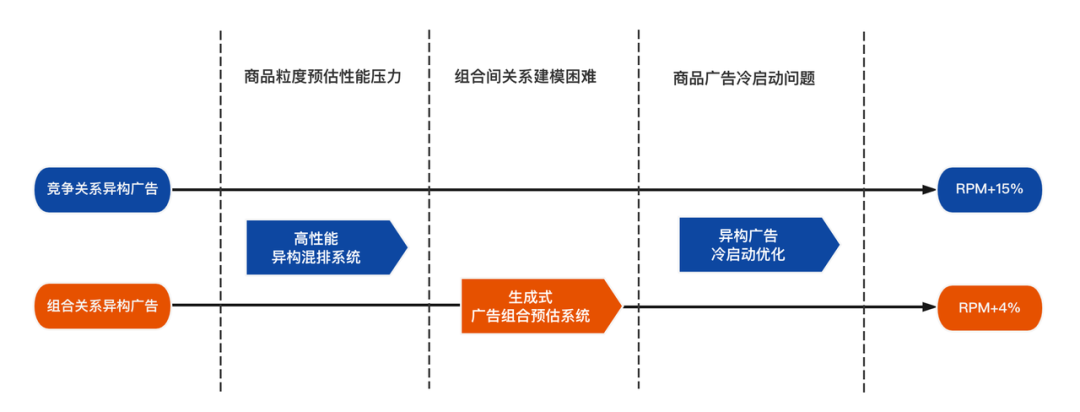
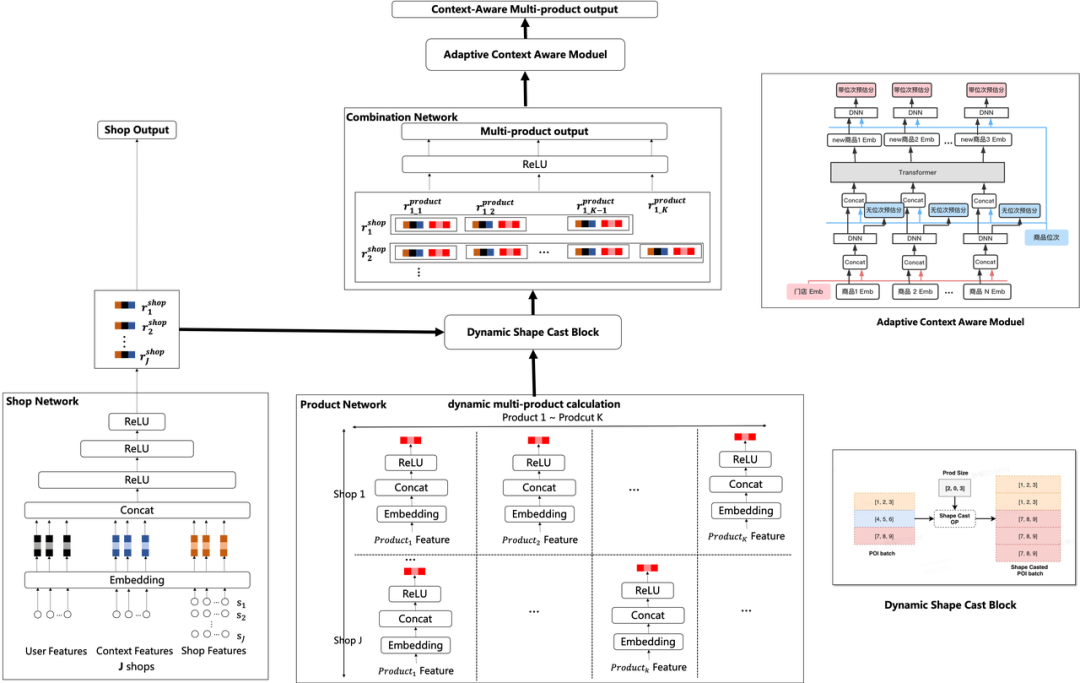
美团搜索广告因LBS(Location Based Services, 基于位置的服务)的限制,所以在某些类目上门店候选较少,而候选较少又严重制约了整个排序系统的潜力空间。可以考虑将商品广告作为门店广告的补充候选,对两者混排后进行展示。商品广告和门店广告的形态、混排方式如下

引入商品广告后,候选量从150+扩到1500+。存在几个挑战
商品粒度预估性能压力:下沉到商品粒度后增加至少10倍的候选量,造成线上预估服务无法承受的耗时增加。
组合间关系建模困难:门店同组合商品的上下文关系使用Pointwise-Loss建模难以刻画。
商品广告冷启动问题:仅使用经过模型选择后曝光的候选,容易形成马太效应。
3.9 【聚合】阿里推荐重排
淘宝公开分享的重排技术文章比较多,
【2020.10-AE搜索】阿里强化学习重排实践
【2020.12-淘宝首页推荐】序列检索系统在淘宝首页信息流重排中的实践
【2021.02-阿里推荐】EdgeRec:边缘计算在推荐系统中的应用(端上重排)
【2021.09-淘宝直播推荐】淘宝直播全屏页重排算法实践(直播推荐每次请求只展现一个结果,每次滑动会重新发起请求,因此是重排是用的pointwise模型)
【2022.04-淘宝每平每屋】生成式重排在内容推荐中的应用实践
【2023.06-淘宝首页推荐】Generator-Evaluator重排模型在淘宝流式场景的实践
Generator-Evaluator 架构其实和强化学习里的比较像。generator模型通过探索/采样的方式生成一些(不一定那么好的)序列,然后evaluator进行评估,打分的结果就作为generaotr的reward。如果reward是正的,generator就调大生成这个序列的联合概率,相反,如果收到的reward是负的,generator就降低生成这个序列的联合概率。
3.9.1 Generator
具体的,generator 是一个 encoder-decoder 结构的模型,
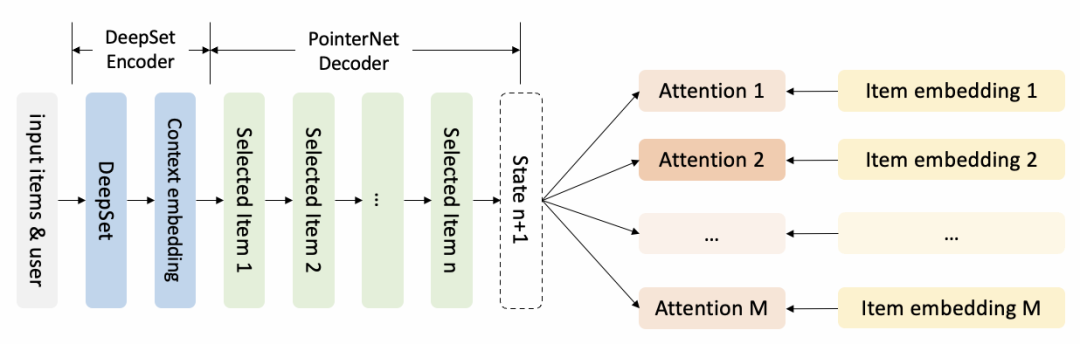
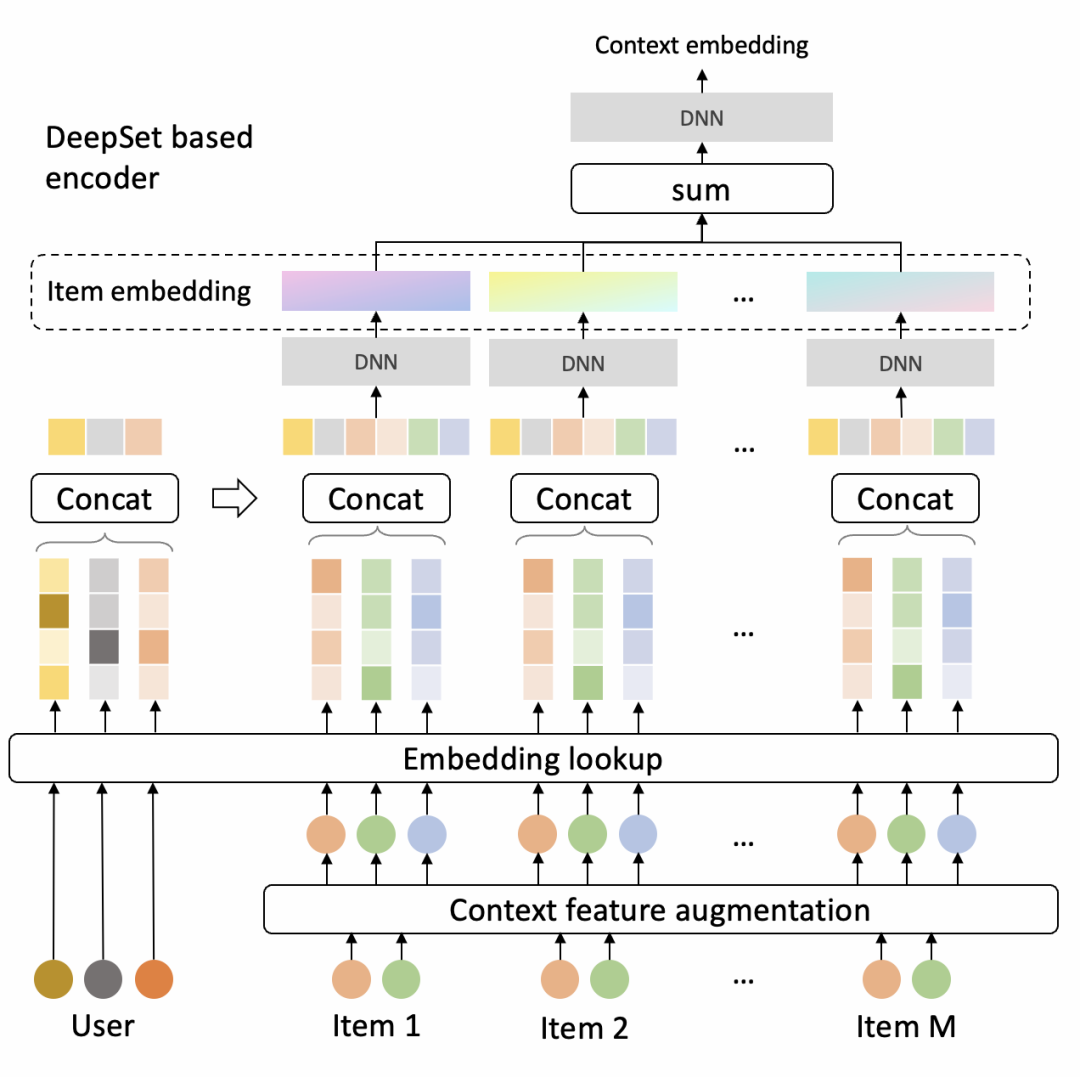
Encoder是DeepSet的结构,因为它对输入商品的顺序不敏感,模型结构如下
Decoder是基于Pointer Network的结构,每次从候选集合中选择一个商品,然后立即更新上下文,继续选择下一个商品,模型结构如下。
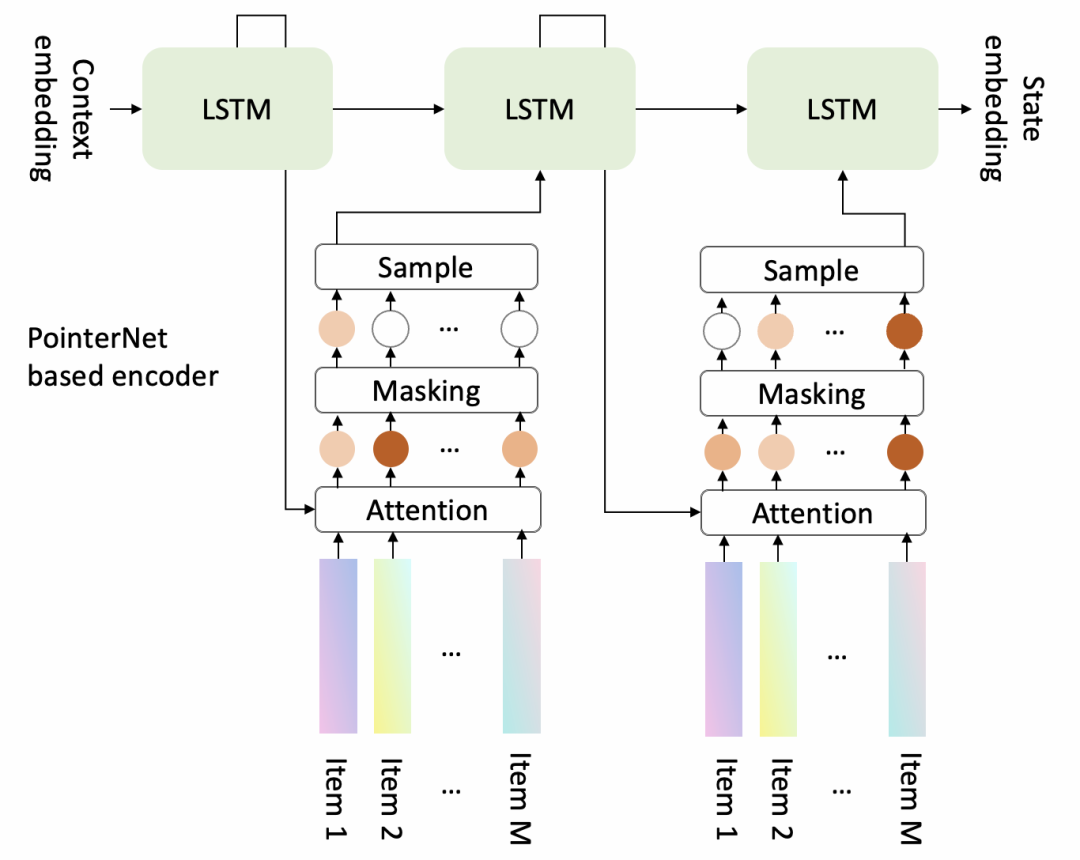
Attention之后Making的作用:
在前序步骤中已被选择的商品不能再出现,因此将attention值mask为0;
通过mask调控业务规则,譬如强插商品的分数必须最高,因此可以将其余商品的值mask为0;Sample的作用,可以进行更多探索尝试不同action,帮助generator找到更优序列生成策略。最简单的选择是Thompson Sampling,会依据每个商品mask后的attention值成比例地选择商品。一个更好的选择可能是Random Network Distillation,倾向于选择一个在之前相似的state下很少被选择的商品。
3.9.2 Evaluator
特征处理模块之后,过5个不同的子网络(目的是聚焦商品序列不同的维度信息),最后concat起来过MLP得到预测分。
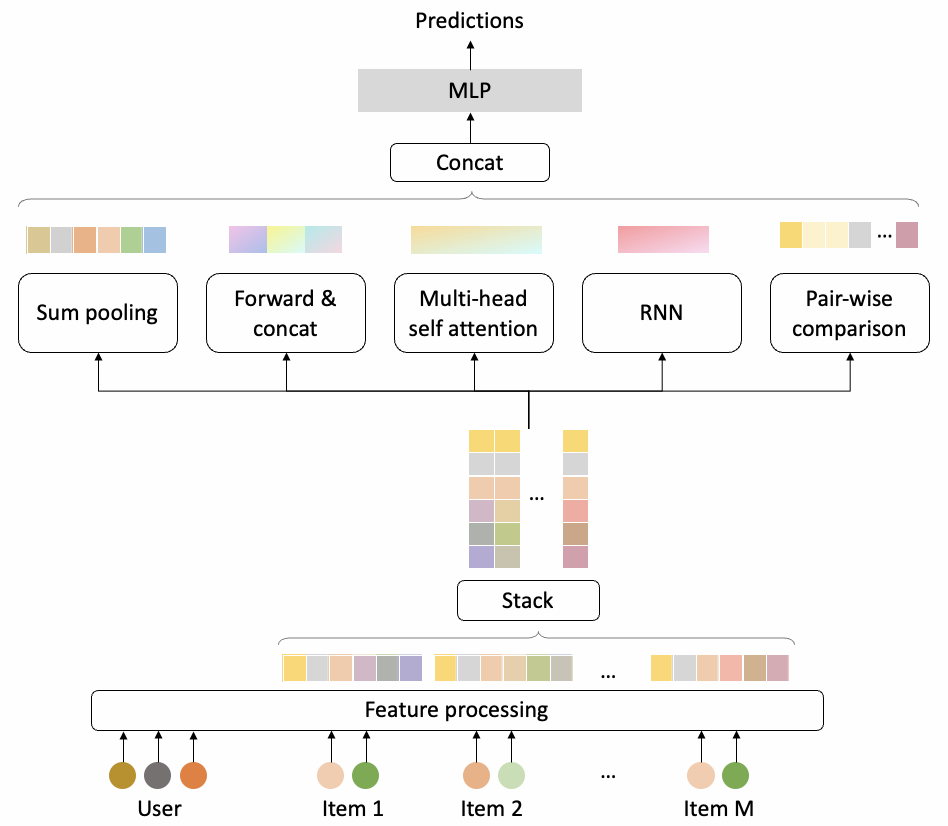
具体训练的时候,会首先使用监督学习的方式充分训练evaluator。
3.9.3 业务规则
GE架构可以很好的结合业务策略目标,包括流量调控、多样性、组间排序以及定坑插入。
流量调控:确保来自特定群组的内容能够得到更多的曝光机会(通常是某些特定场景,需要无法通过正常的推荐系统得到曝光的内容)
多样性:确保推荐结果应该包含不同群组的内容(群组的概念可以是:商家、类目、货源等);
组间排序:特定群组的商品应该以一个很大的概率被排在属于其他群组的商品的前面;
定坑插入:确保指定商品被放在结果列表中某个特定位置,但这一操作有可能会打破多样性的要求(插入商品和前后两个商品的品牌一样),因此可以采用在generator中的masking机制实现。
3.9.4 模型训练
有监督训练evaluator,交叉熵损失函数,分类模型
类似强化学习的方式训练generator,最大化reward。reward的定义包括evaluator对生成序列的预估分以及上述业务规则是否满足的评分,融合加权求和得到最终的reward;最终线上使用的是训练好的generator,evaluator不上线。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

本文参考资料
[1]
多目标排序在快手短视频推荐中的实践: https://www.infoq.cn/article/nozs4xy7bvbcf34vzhhu
[2]Transformer 在美团搜索排序中的实践: https://tech.meituan.com/2020/04/16/transformer-in-meituan.html
[3]端智能在大众点评搜索重排序的应用实践: https://tech.meituan.com/2022/06/16/edge-search-rerank.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









