







源 | 李rumor
预训练中,除了模型尺寸、数据、计算量之外,比较重要的就是batch size和learning rate这两个超参数了。从DeepSeek的scaling law工作[1]中可以看到,不同的学习率可以让loss有一定的波动,影响模型收敛。
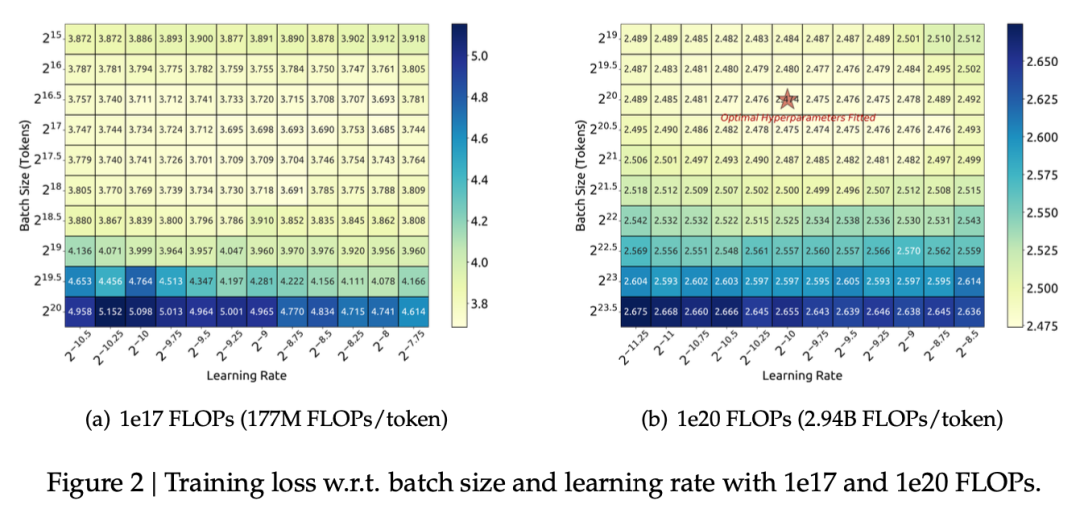
虽然近两年主流LLM都采用cosine decay的学习率策略,但它有个关键问题,就是对续训很不友好。早在Chinchilla的工作中就提到,cosine策略的衰减周期需要与训练步数一致,过短或过长都不会收敛到当前的局部最优。如下图中,14k步最优值是cosine正好衰减到14k步,而其他设置都有一定差距:
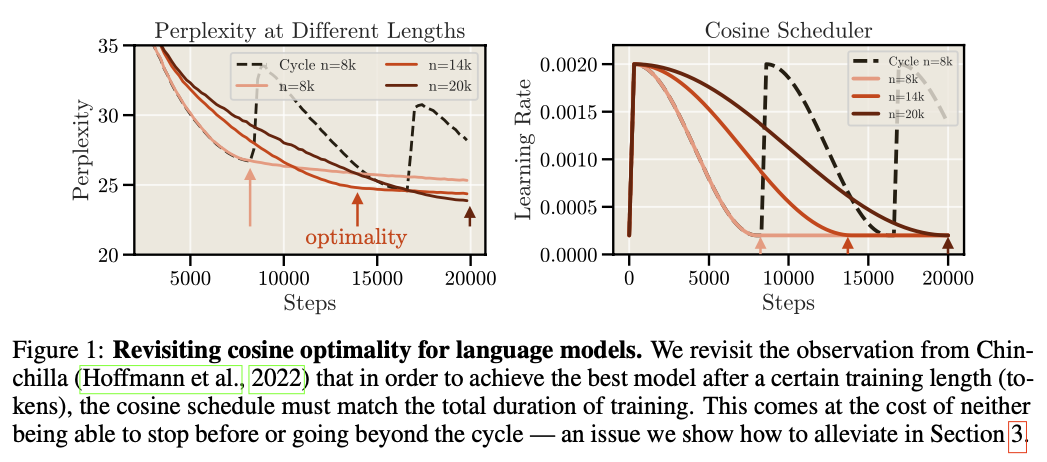
这个硬性的设置就让续训变得比较难,因为预训练结束时模型的LR已经降到了比较低,收敛到局部最优,续训如果LR设置过大可能会让效果变差,过低的话收敛效率也低。
告别Cosine
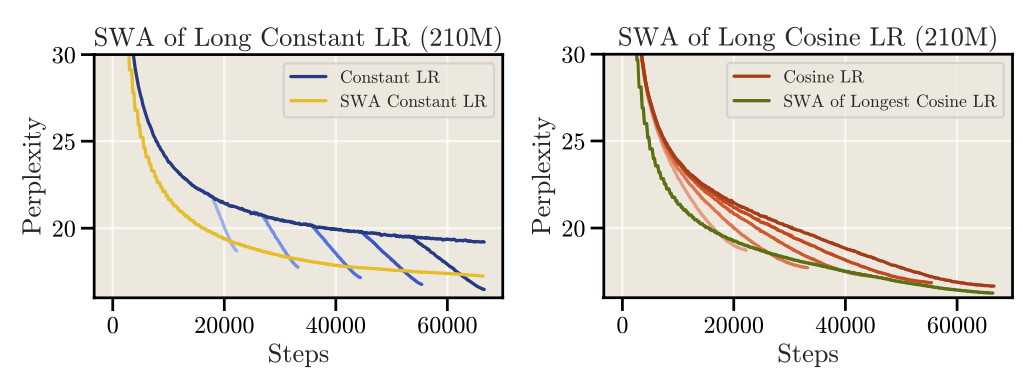
在近期清华的MiniCPM[2]工作中,作者提出了一个WSD策略(Warmup-Stable-Decay),即快速warmup后,一大段时间内使用固定学习率,在最后快速衰减到小的学习率。如下图:
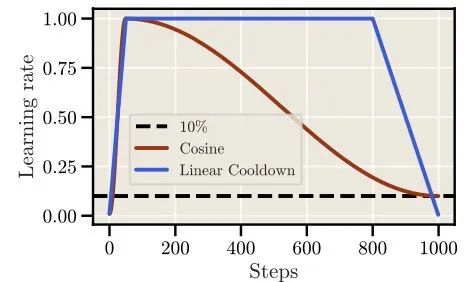
这个策略在小尺寸模型上的收敛效果很好,甚至快速衰减后还可以超过cosine的表现。如下图中WSD(80N,8N)是指一共训80N,其中最后10%(8N)快速衰减,跟Cosine(80N)对比:
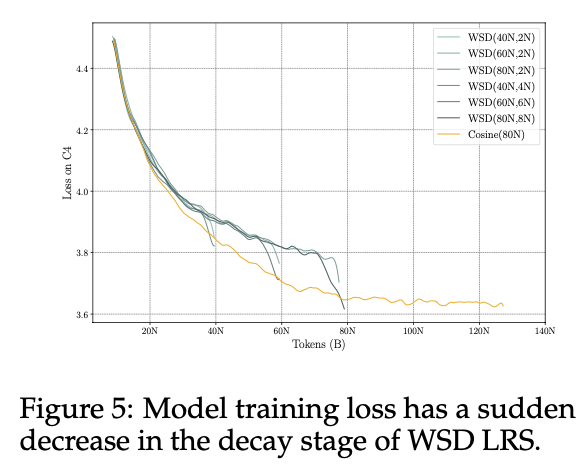
WSD策略对续训就更加友好,只要拿到之前固定学习率的ckpt就可以继续训练,节省了很多计算资源。
近期一篇工作[3]对WSD这种固定学习率的策略(称为Cooldown)进行了进一步研究和Scaling Law分析。以下是作者得出的结论(210M模型训练5B左右):
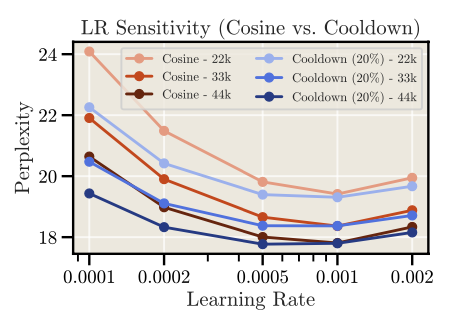
Cooldown策略的最优学习率是Cosine最优的一半,不过从图中数值来看采用Cosine相同的LR差距也不大
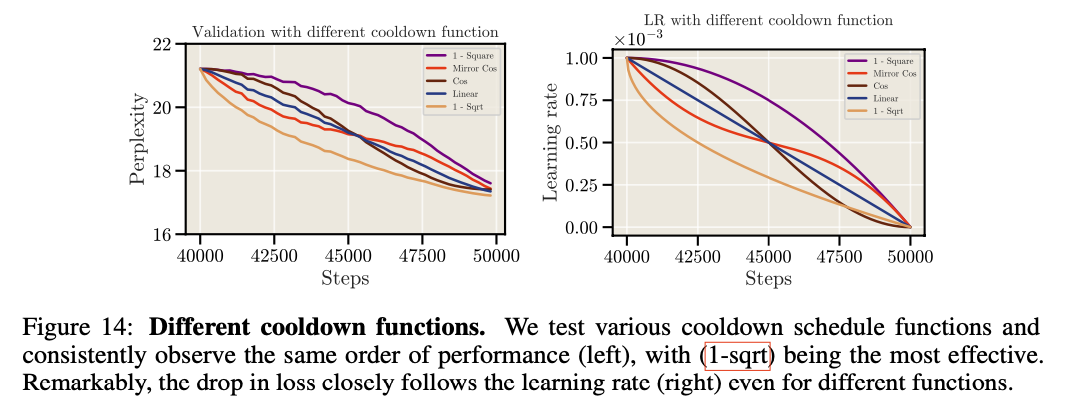
相比线性衰减,1-sqrt可以达到更好的收敛效果
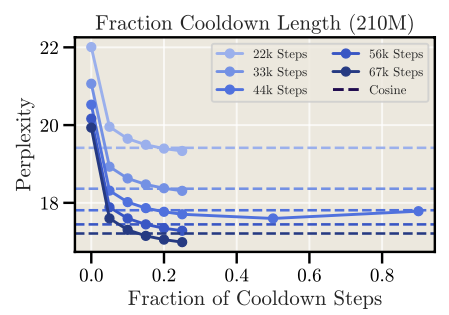
衰减长度在10%-20%之间较好,Cooldown的效果可以超过Cosine
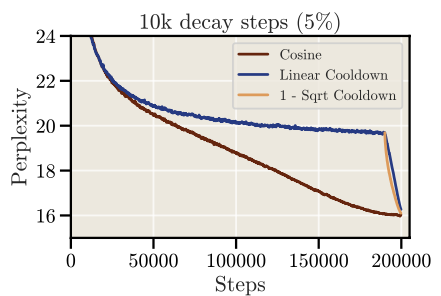
当训练的token数较多时(5B->20B),衰减5%也可以追上Cosine的效果
通过33M-360M尺寸上拟合后的Scaling Law显示,Cooldown和Cosine的效果基本一致。下图横轴纵轴分别是Cooldown和Cosine的PPL,拟合的曲线斜率为0.99
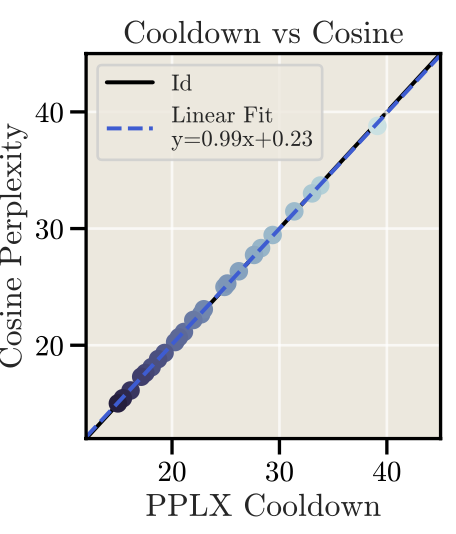
通过上述实验,作者在一系列小尺寸模型上证明了固定学习率+快速衰减的策略和Cosine基本等价,同时也给出了LR大小、衰减周期、衰减函数的指导,非常给力。
狠人选择不调LR
虽然上述策略对Cosine decay进行了很大简化,但仍旧有更狠的方法,既然最终目标就是得到一个好的ckpt,那可以直接对多个权重进行平均、或者在梯度更新时对优化器做文章。
Stochastic Weight Averaging
SWA时2018年[4]就被提出的工作,它的思想很好理解,就是对多个ckpt权重做平均:
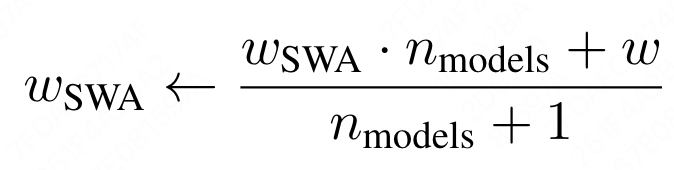
虽然使用SWA之后可以完全固定LR,但另一个代价是需要调节权重平均的窗口大小,作者实验后发现不如Cooldown或Cosine的效果好:
Schedule-Free Optimizer
SFO是最近Meta刚出炉的一篇工作[5],主要是对优化器进行了改造,配合固定学习率即可训练。该工作的核心思想源自于Polyak-Ruppert平均:
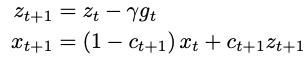
当 时, 。类似SWA做一个ckpt的平均。但该方法的实际表现一直不好,于是作者结合Primal平均做了一个改进,提出了SFO:
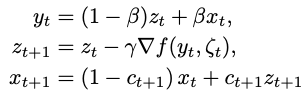
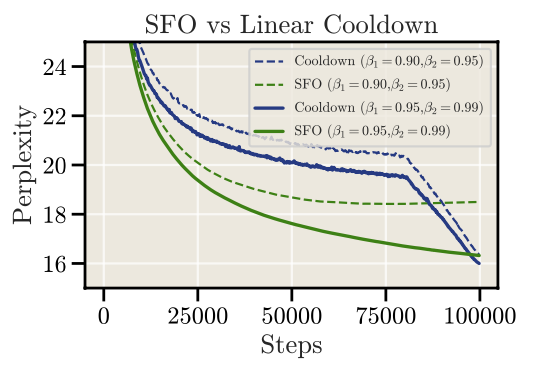
因为在ckpt层面上做了平均,原paper实验结果显示该方法评估指标更加稳定,同时也能追上Cosine的效果。不过该方法结合AdamW后,对超参数beta会比较敏感,在实际对比中略弱于Cooldown:
总结
从上述工作可以看到,想要替换掉cosine decay,又想追上cosine的效果,还是伴随着不少代价:
换成WSD/Cooldown,需要调节衰减长度
换成SWA,需要调节平均窗口
换成SFO,需要调节beta
同时,上述WSD、SFO策略都是近期被提出的,这些策略只在小尺寸模型上进行过验证,能否保证大模型的稳定收敛、Scaling Law生效还有待更多的实验验证。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

参考资料
[1]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism: https://arxiv.org/abs/2401.02954
[2]MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies: https://arxiv.org/abs/2404.06395
[3]Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations: https://arxiv.org/abs/2405.18392
[4]Averaging Weights Leads to Wider Optima and Better Generalization: https://arxiv.org/abs/1803.05407v3
[5]The Road Less Scheduled: https://arxiv.org/abs/2405.15682



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









