








抽象的
基于检索的临床决策支持 (ReCDS) 可通过为特定患者提供相关文献和类似患者来帮助临床工作流程。然而,由于缺乏多样化的患者集合和公开可用的大规模患者级注释数据集,ReCDS 系统的发展受到了严重阻碍。在本文中,我们收集了一个名为 PMC-Patients 的患者摘要和关系的新数据集,以对两个 ReCDS 任务进行基准测试:患者到文章检索 (ReCDS-PAR) 和患者到患者检索 (ReCDS-PPR)。具体来说,我们使用简单的启发式方法从 PubMed Central 文章中提取患者摘要,并利用 PubMed 引文图来定义患者-文章相关性和患者-患者相似性。 PMC-Patients 包含 167k 条患者摘要,310 万条患者与文章相关性注释和 293k 条患者与患者相似性注释,这是 ReCDS 规模最大的资源,也是最大的患者集合之一。人工评估和分析表明,PMC-Patients 是一个具有高质量注释的多样化数据集。我们还在 PMC-Patients 基准上实施和评估了几个 ReCDS 系统,以展示其挑战,并进行了几个案例研究,以展示 PMC-Patients 的临床实用性。
-
数据:
背景与摘要
临床医生通常依靠循证医学 (EBM) 将临床经验与高质量的科学研究相结合来为患者做出决策1。然而,找到相关研究可能会很困难2。为了解决这个问题,人们越来越有兴趣利用自然语言处理 (NLP) 和信息检索 (IR) 技术来检索相关文章或类似患者,以协助患者管理3、4、5、6、7。在本文中,我们引入术语“基于检索的临床决策支持” (ReCDS) 来描述这些任务。ReCDS 可以通过检索和分析相关文章或类似患者来确定最可能的诊断和最有效的治疗方案,从而为特定患者提供临床帮助。
带有相关文章的 ReCDS 以 EBM 为基础。因此,大多数 ReCDS 研究都集中在检索相关研究文章8、9、10上,这主要得益于 2014 年至 2016 年每年在文本检索会议 (TREC) 上举行的临床决策支持 (CDS) 轨道3、11、12 。每年, TREC CDS Track 都会发布30个“医疗病例叙述”,并要求参与者为每位患者返回相关的 PubMed Central (PMC) 文章。虽然在 TREC 池化评估设置 13 下可以注释足够的患者-文章相关性,但 TREC CDS 中测试患者集的大小和多样性有限。因此,系统性能对未发现的医疗状况的普遍性可能会受到限制。
另一方面,具有相似患者的 ReCDS 仍未得到充分探索。检索相似患者的医疗记录可以提供有价值的指导,特别是对于患有罕见疾病等缺乏临床共识的罕见疾病的患者。尽管如此,开展这类研究仍面临各种挑战。与科学文章不同,目前没有可供公开检索的“参考患者”集合。此外,定义“患者相似性”并非易事14 ,大规模注释成本高昂。因此,关于相似患者检索的研究很少 15、16,所有这些研究都使用私有数据集和注释。
上述问题清楚地表明,评估 ReCDS 系统的一个标准化基准是十分必要的。理想情况下,这样的基准应该包含:(1)一组多样化的患者摘要,既可作为查询患者集,又可作为参考患者集;(2)丰富的相关文章和类似患者的注释。出于隐私考虑,只有少数来自电子健康记录 (EHR) 的临床笔记数据集是公开的。一个值得注意的大型公共 EHR 数据集是 MIMIC 17、18、19、20 。然而,它只包含ICU 患者,没有任何关系注释,因此不适合评估 ReCDS 系统。
在本文中,我们旨在使用 PMC-Patients 对 ReCDS 任务进行基准测试,PMC-Patients 是从 PMC 中的病例报告和 PubMed 的引文图中收集的新型数据集。病例报告表示一类医学出版物,通常包括:(1)描述患者整个入院过程的病例摘要;(2)讨论类似病例和相关文章的文献综述,这些都记录在引文图中。为了构建 PMC-Patients,我们首先使用简单的启发式方法从 PMC 中发布的病例报告中提取患者摘要。对于这些患者摘要,我们然后使用 PubMed 引文图注释相关文章和类似患者。图 1通过示例演示了数据集集合。PMC-Patients 是最大的患者摘要集合之一,具有最大的关系注释规模。此外,我们数据集中的患者在患者特征方面表现出比现有患者集合更高的多样性。我们的人工评估表明,PMC-Patients 中的患者摘要和关系注释都是高质量的。
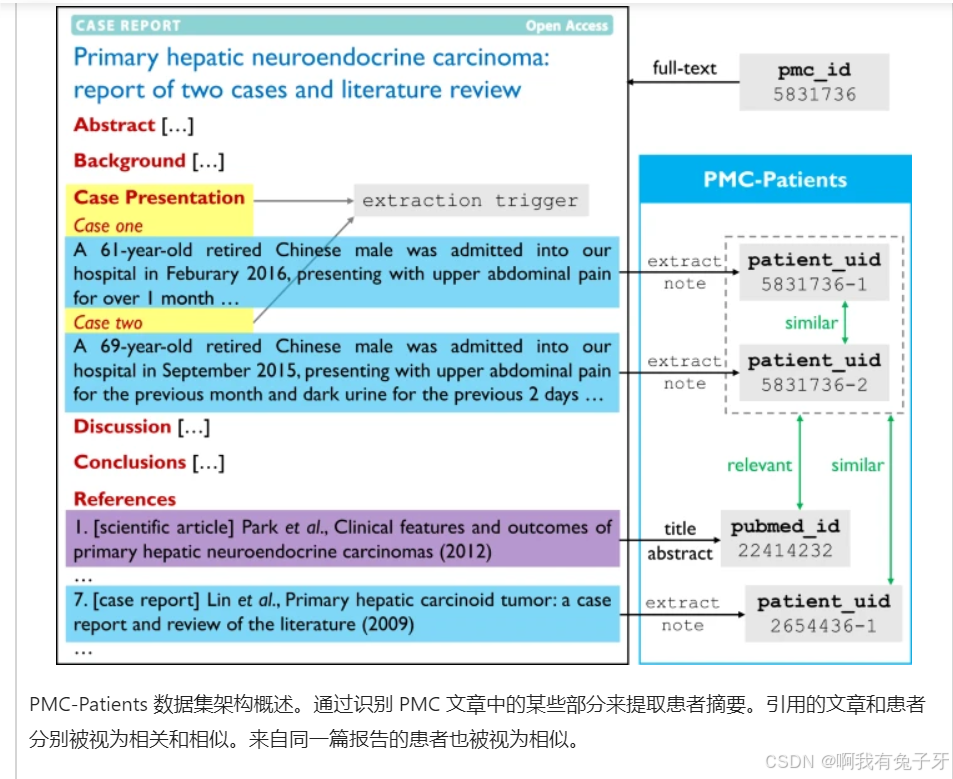
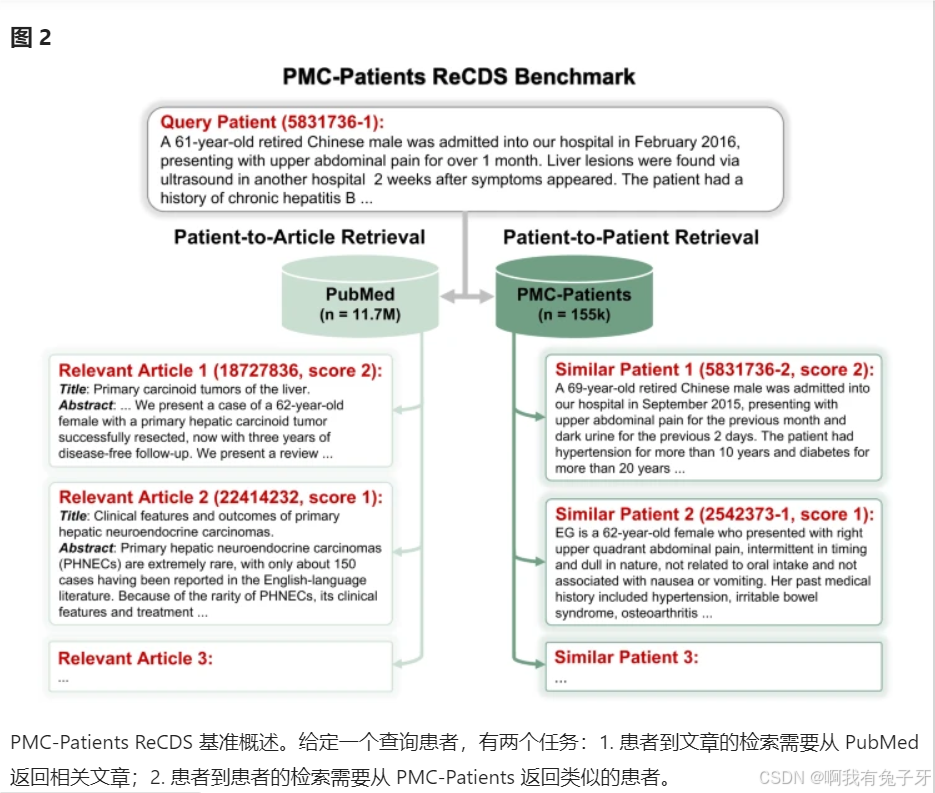
基于 PMC-Patients,我们正式定义了两个 ReCDS 任务:患者到文章检索 (ReCDS-PAR) 和患者到患者检索 (ReCDS-PPR),如图 2中的示例所示。我们系统地评估了各种基线 ReCDS 系统的性能,实验结果表明 ReCDS-PAR 和 ReCDS-PPR 都是具有挑战性的任务。我们还提供了相关案例研究,以展示我们的检索任务在三种典型临床场景中的潜在应用和意义。
总而言之,我们推出了 PMC-Patients,这是首个包含 167k 条患者摘要的数据集,其中注释了 310 万个相关患者-文章对和 293k 个相似患者-患者对,它既是一个大规模、高质量、多样化的患者集合,也是对 ReCDS 系统进行基准测试的最大规模资源。
PMC-Patients ReCDS 基准
基于 PMC-Patients 中的患者摘要和关系注释,我们为 ReCDS 定义了两个基准测试任务:患者到文章检索 (ReCDS-PAR) 和患者到患者检索 (ReCDS-PPR)。两者都被建模为信息检索任务,其中输入是患者摘要p ∈ ℙ,其中ℙ表示 PMC-Patients 数据集。对于 ReCDS-PAR,目标是使用语料库𝔸中的标题和摘要检索与输入患者相关的 PubMed 文章。我们没有使用 PubMed 中的整个文章集合,而是缩小了检索语料库的范围,仅包含满足以下标准的文章:1) 具有机器可读的标题和摘要;2) 英文;3) 标有“人类”MeSH 术语。此限制允许更有效地进行密集检索,因为对整个 PubMed 集合进行编码将非常耗时。同时,它反映了一种实际的搜索场景,研究人员经常使用类似的过滤器来优化他们的搜索。最终的语料库𝔸包含 11.7 M 篇文章,在效率和保真度之间取得了令人满意的平衡。对于 ReCDS-PPR,目标是从 PMC-Patients 中检索与输入患者相似的患者。
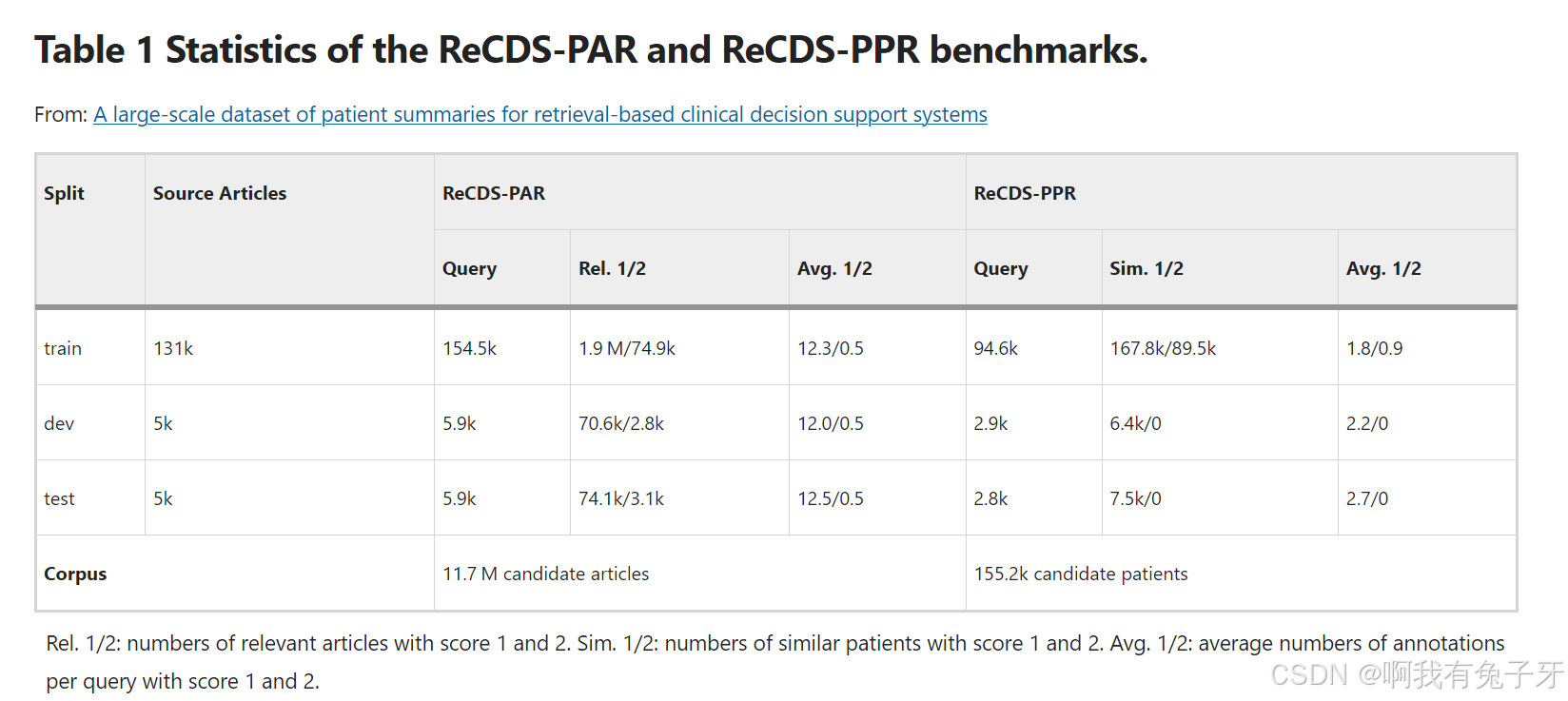
我们在文章层面分割训练/开发/测试集。具体来说,我们从所有包含患者的文章中随机选择两个文章子集(每篇 5000 篇),并将相应的患者作为查询患者包含在开发和测试集中。从其他文章中提取的患者摘要被用作训练查询患者,也用作 ReCDS-PPR 的检索语料库ℙ 。基准统计数据如表1所示。值得注意的是,ReCDS-PPR 开发和测试集不包含高度相似的患者注释。这是因为对于开发/测试集中的每个查询患者,从同一篇文章中提取的患者(如果有)也将分配到开发/测试分割中,因此不会出现在 ReCDS-PPR 语料库中。
我们使用上面部分定义的 3 等级在两个基准上评估检索模型,其中平均倒数等级 (MRR)、准确率为 10 (P@10)、标准化折扣累积增益为 10 (nDCG@10),召回率为 1k (R@1k)。
基线模型
我们为 ReCDS-PAR 和 ReCDS-PPR 实现了三种类型的基线检索模型:稀疏检索器、密集检索器和最近邻检索器。此外,为了利用词汇和语义匹配(这已被证明可以进一步提高检索性能21、22),我们使用互易秩融合23算法来结合稀疏和密集检索器。
稀疏检索器
我们使用 Elasticsearch ( Elasticsearch: The Official Distributed Search & Analytics Engine | Elastic )实现了一个 BM25 检索器24。BM25算法的参数在 Elasticsearch 中设置为默认值(b = 0.75,k 1 = 1.2)。对于 ReCDS-PAR,我们将 PubMed 文章的标题和摘要作为单独的字段进行索引,并在检索时将这两个字段的权重经验性地设置为 3:1。
我们训练了几种不同的编码器,它们都是由领域特定的 BERT 30初始化的 Transformer 编码器29,包括 PubMedBERT 31、BioLinkBERT 32和 SPECTER 33。对于 ReCDS-PPR 任务,只使用一个编码器,而对于 ReCDS-PAR 任务,我们训练两个独立的编码器,分别对患者和文章进行编码,因为它们的结构不同。如果输入文本超出 BERT 模型允许的最大序列长度,我们只需截断它即可。
我们使用 PyTorch ( PyTorch ) 和 Hugging Face Transformers 库 ( https://huggingface.co/docs/transformers/index ) 实现所有密集检索器。我们在两个 NVIDIA GeForce RTX 3090 GPU 上对所有密集检索器进行 50k 步训练,每个设备的批次大小为 12,以便充分利用 GPU 的全部容量。我们的学习率设置为 2e-5,预热率为 0.1,使用线性学习率调度程序。我们使用 AdamW 34优化器,权重衰减为 0.05。此外,我们应用了 4 步梯度累积。
最近邻 (NN) 检索器
我们假设如果两个病人相似,那么他们各自的相关文章和相似病人集应该有较高的重叠度,在此基础上我们实现了如下类似于35的NN检索器。对于训练查询p∈ℙ中的每个病人, 我们将其相关文章集定义为\({\mathbb{R}}(p)= \ 。对于每个查询病人q,我们首先使用BM25检索前K个相似的训练病人作为其最近邻居。我们还尝试使用经过微调的密集检索器,但性能并不理想。我们以它们的相关文章的并集作为候选集:R(p)={a|a∈A,Rel(p,a)>0}{p}_{1},{p}_{2},\ldots ,{p}_{K}\in {\mathbb{P}}p1,p2,…,pK∈P
然后,候选文章根据相关性得分其定义为:ci∈CPAR(q)sNN,PAR(q,ci)
对于 ReCDS-PPR,我们将每个训练患者的相似患者集定义为。用于排序的候选集和相似度得分定义为:p∈PS(p)={p′|p′∈P,Sim(p,p′)>0}
在实践中,我们动态地设置K中包含至少 10k 个候选,以确保每个查询的候选集具有适中的大小。C(q)
倒数秩融合(RRF)
RRF 是一种将多个检索器的结果组合起来的算法,并已证明具有提高检索性能的潜力36。具体来说,给定一组需要排序的文档D和一组来自不同检索器的排序结果R,每个结果都是上的排列,某个文档d的 RRF 得分计算如下:1…|D|
其中r ( d ) 是文档d在排名结果r中的排名,k是超参数。在实践中,我们尝试了稀疏检索器和性能最佳的密集检索器的不同组合(我们不使用 NN 检索器,因为它们的性能较差),并在我们的开发集上调整超参数k 。当 ReCDS-PAR 的k = 100 和 ReCDS -PPR 的k = 5时,稀疏检索器、基于 PubMedBERT 的密集检索器和基于 BioLinkBERT 的密集检索器的组合可实现最佳性能 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









