








目的与初心:之前的帖子成功在windows本地部署了LightRAG,完成了测试文档的抽取。在初见效果以后,迅速投入大量文档进行抽取。直接使用LightRAG抽取的效果非常差,完全无法正常使用抽取完成的知识图谱。故这一篇文档目的在于深入分析LightRAG的原理。深入内部修改提示词,保证:
1.不会抽取重复的关系与节点,例如:
<elementId>: 5:6cab5d42-4d85-48d7-be0d-9c5b8f464282:36420305
<id>: 36420305
下列内容重复出现,在代码里要控制
description:
keywords: 32.0
source: 《医宗必读》
source_id: 《医宗必读》 categorizes abdominal pain into three regions based on the organs involved, providing a foundational framework for understanding this symptom.
target: 腹痛
weight: 0.0
2.节点中的命名、属性等内容固定且规范,便于后续使用。(在插入neo4j签可以再进行一次格式检查)
3.预计解决时间:2:34-11:34 出去休息和吃饭仨小时,约6小时。预计达成目标:
a.在10、50个文档的测试下获得规范的neo4j数据(指标:没有重复节点和关系,格式和命名规范,基本抽取到文章的核心内容)。
b.在今晚回去前顺利执行全部文档的知识图谱抽取
c.时间安排:
1个小时对总体框架有了解,对于改代码有思路;2:49-3:49
2个小时一边实操摸索一边改
剩下的时间进行测试和调整。
还没有部署的同学可以看这篇:
【2025最新】windows本地部署LightRAG,完成neo4j知识图谱保存_lightrag neo4j-CSDN博客
2.知识源快速筛选与感觉建立(2:39-3:50 11min)
原则:按照更新时间、阅读量、标题快速打开全部网页。网页的优先级大于视频。在网页无法弄清的前提下才看视频。
【核心资料】4:33-5:00 27min
这一篇是核心思想和抽象框架,没提到代码细节,但可以用来建立整体理解:
LightRAG基础原理解析_lightrag原理-CSDN博客
LLM大模型下的高效检索方案:LightRAG技术论文与代码结合解读-CSDN博客(第二篇稍微加入一些代码)
这篇文章对讲解和代码给的非常清晰,可以作为主要的研究对象:(这篇主要是代码)————主要讲查询,对抽取用处不大
这一篇优点混乱,但是很详细,可以看完第一篇以后再看一遍,换一个角度增加理解:
LightRAG核心原理和数据流_light rag从切片中抽取的什么-CSDN博客
这一篇用于优化索引性能,我看的时候只关注能不能学到规范抽取的东西,没有就快速结束:
让lightrag索引速度更快的工程实现优化设计_lightrag 查询响应慢-CSDN博客
【辅助资料】
下面这篇文章能看到一些核心代码,但是没有给出具体位置,对于我们上手改没太大用,这里先保存,作为工具书查用
LightRAG中的知识图谱构建与优化_lightrag 实体消歧-CSDN博客
下面是我之前做的一些笔记,有个博主视频演示了代码,但当时我自己并没有提前做好准备也没有明确目的,所以看视频花了时间,收益却不大,这里用来在我初步了解后,没有想法的情况下进行补充。
视频:基于知识图谱做rag Lightrag中实体关系的提取及图谱的生成_哔哩哔哩_bilibili 笔记:【2025最新】windows本地部署LightRAG,完成neo4j知识图谱保存_lightrag neo4j-CSDN博客
- LightGraph论文地址: https://arxiv.org/pdf/2410.05779v1
- LightGraph源码地址:https://github.com/HKUDS/LightRAG
3.学习积累
1.相关研究项
研究问题:如何增强大型语言模型(LLMs)的信息检索和生成能力,特别是通过集成外部知识源来提供更准确和上下文相关的响应。
研究内容:LightRAG的框架,通过在文本索引和检索过程中引入图结构,增强从低级和高级知识发现中获取的综合信息检索能力。此外,通过增量更新算法确保新数据的及时集成,使系统能够在快速变化的数据环境中保持有效性和响应性。
研究难点:现有RAG系统依赖于平面数据表示,缺乏对实体间复杂关系的理解;这些系统通常缺乏上下文感知能力,导致响应可能无法完全解决用户查询。
简介
LightRAG 是一种轻量级、高效的检索增强生成(Retrieval-Augmented Generation, RAG)框架,旨在通过结合外部知识库和生成式模型(如大语言模型)来提升文本生成任务的质量和准确性。
LightRAG的主要优势包括:
高效的知识图谱构建:LightRAG通过图结构差异分析实现增量更新算法,显著降低了计算开销,使知识库维护更加高效。
双层检索机制:该系统结合了低层次(具体实体和属性)和高层次(广泛主题和概念)的检索策略,满足了不同类型的查询需求,提高了检索的全面性和多样性。
快速适应动态数据:LightRAG能够在新数据到来时快速整合,无需重建整个知识库,确保系统在动态环境中保持高效和准确。
2.LightRag调用流程分析
Rag技术分为两个部分:Input Document 和 Query
2.1Input Document
2.1.1图增强实体和关系提取
先将文档分割成小块以便快速识别和获取信息,接着利用大语言模型(LLM)提取各类实体(如名称、日期等)及其关系,这些信息用于构建知识图。其具体过程涉及三个函数:R(.)用于提取实体和关系,通过将原始文本分割成块提高效率;P(.)借助 LLM 为实体节点和关系边缘生成文本键值对,便于检索和文本生成;D(.)对原始文本不同片段中的相同实体和关系进行去重,减少图操作开销。
2.1.2 快速适应增量知识库
面对数据变化,LightRag 采用增量更新算法。对于新文档,依循原有图索引步骤处理后与原知识图合并,实现新数据无缝集成,同时避免重建整个索引图,降低计算开销,确保系统能提供最新信息且保持准确性和高效性。
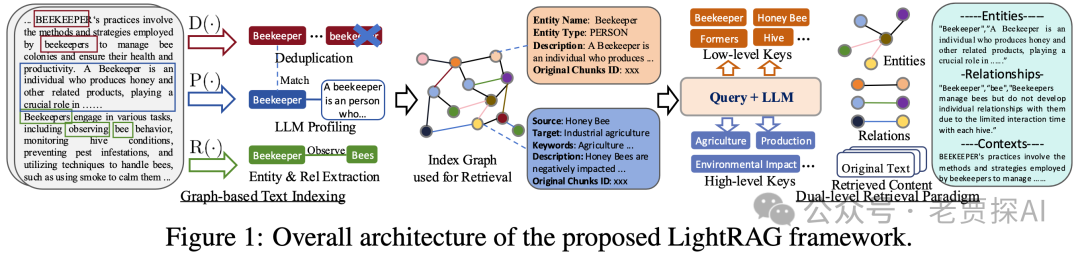
2.1.3 Input Document 全流程介绍【看来这部分是我们要重点处理的】
1.将文件切割成块并去重,方便传递给LLM。
chunking_func: Callable[
[
str,
str | None,
bool,
int,
int,
str,
],
list[dict[str, Any]],
] = field(default_factory=lambda: chunking_by_token_size)
# 逻辑:chunk tokens大小为1200,重叠部分为100,先获取每个chunk的start后切分
for chunk in raw_chunks:
_tokens = encode_string_by_tiktoken(chunk, model_name=tiktoken_model)
if len(_tokens) > max_token_size:
for start in range(
0, len(_tokens), max_token_size - overlap_token_size
):
chunk_content = decode_tokens_by_tiktoken(
_tokens[start : start + max_token_size],
model_name=tiktoken_model,
)
new_chunks.append(
(min(max_token_size, len(_tokens) - start), chunk_content)
)
else:
new_chunks.append((len(_tokens), chunk))

2.提取块中的实体与实体关系。
循环遍历每次对单个chunk提取实体以及关系,提取后合并
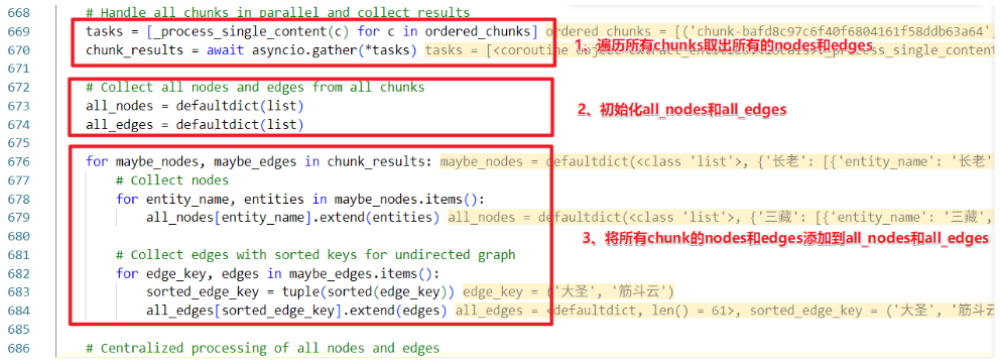
合并数据来源
nodes_data:当前处理批次中提取的实体数据(例如单篇文档分块后提取的实体列表)。
全局节点数据:通过查询知识图谱(knowledge_graph_inst.get_node)获取已存在的节点信息。
合并过程(all_nodes)
实体类型(entity_type)合并:
逻辑:统计当前批次实体类型(nodes_data)和已有节点类型的出现频率,选择频率最高的类型。
entity_type = sorted(
Counter([dp["entity_type"] for dp in nodes_data] + already_entity_types).items(),
key=lambda x: x[1],
reverse=True,
)[0][0]
3.利用算法去重实体、实体关系。
4.获取实体或者关系之前的数据,和提取到新描述的数据合并。如果超出系统设置最大长度,则提交到LLM进行一次总结。
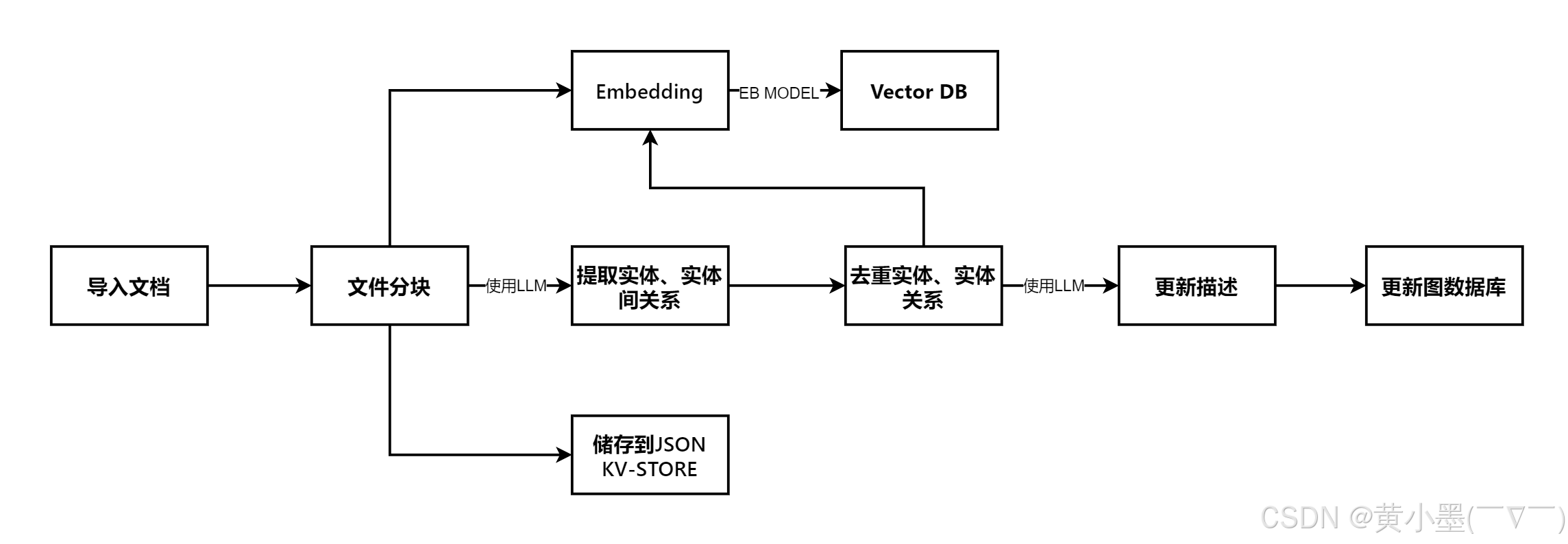
2.2 QUERY
2.2.1 双层检索机制
低级检索以细节为导向检索特定实体及其属性或关系信息,旨在检索图谱中指定节点或边的精确信息;高级检索处理更加概念化涵盖更广泛的主题、摘要,其并非与特定实体关联,聚合多个相关实体和关系的信息,为高级的概念及摘要提供洞察力。同时使用了图结构和向量表示使得检索算法有效地利用,有效地利用局部和全局关键词,简化搜索过程并提高结果的关联性。
下面是关键词提取示例:

相比graphrag、nano, lightrag支持自定义实体抽取的类型,这篇文档是最有用的,但也只有第二部分【LightRAG核心原理和数据流_light rag从切片中抽取的什么-CSDN博客】
还是要一边对着这篇笔记最后的视频截图,一遍直接进入pycharm,使用ctrl一层层跳转源码
笔记:【2025最新】windows本地部署LightRAG,完成neo4j知识图谱保存_lightrag neo4j-CSDN博客
基础知识也有了,直接上手一边研究一边改吧
4.开始修改
在我的启动文件,example/lightrag_openai_compatible_demo.py的insert函数下一路跳转,找到了我要的模块
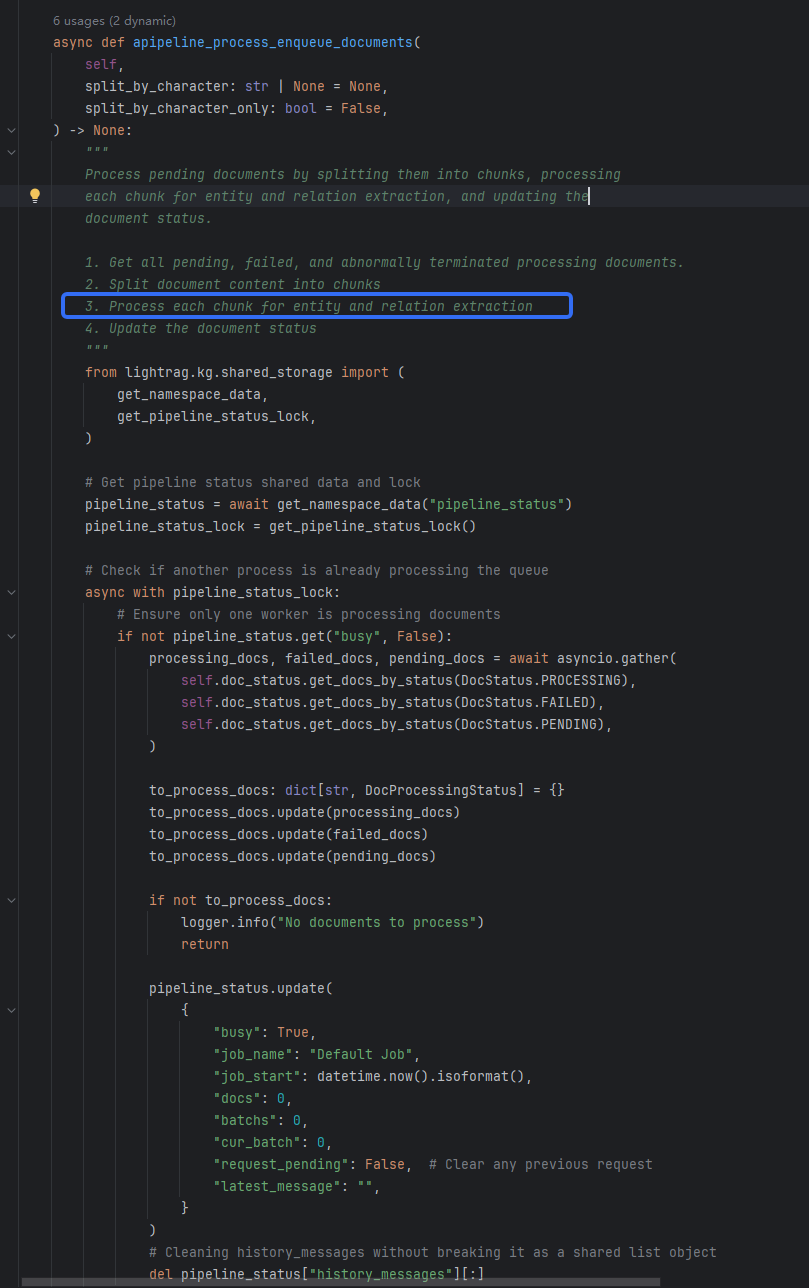
找到实体处理模块了,下面就是提示词:
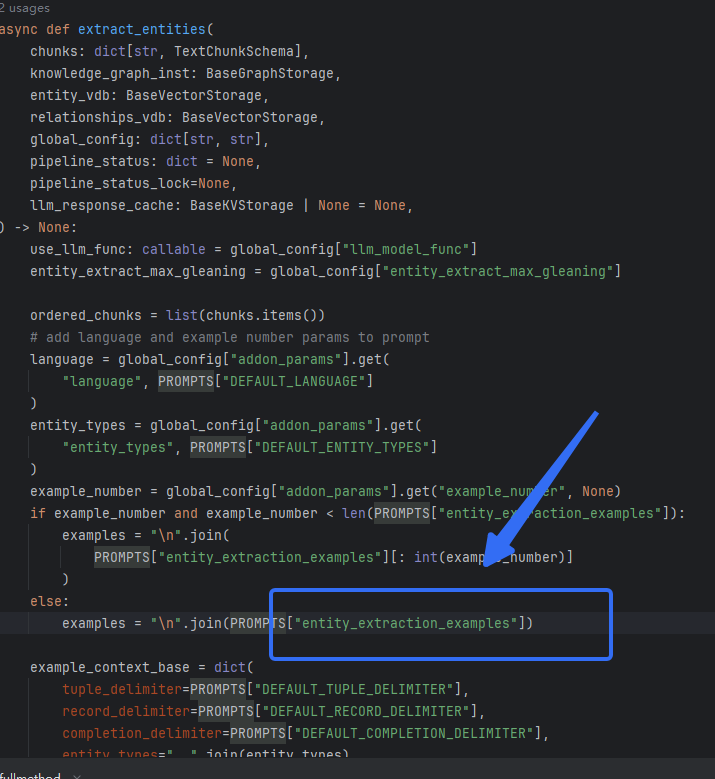
这也和之前文档提到的部分一样:

破案了,只要找到下面的prompt文件,直接修改prompt,就可以定制化了:
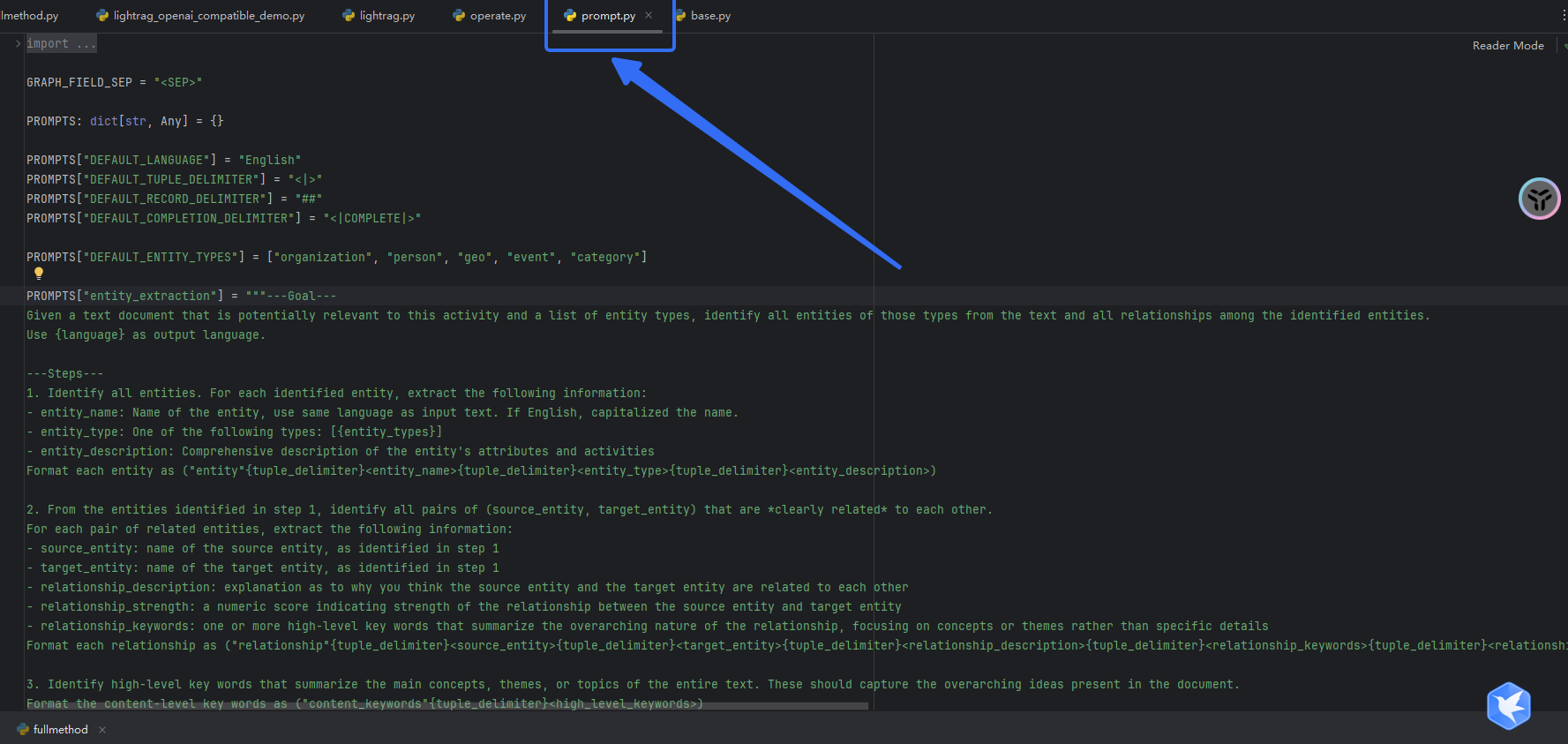
来都来了,好好分析一下我们需要的prompt吧
实体与关系抽取
可以看到,会抽取出如下属性:这些属性对我的应用来说够用了
Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>)
提示信息["实体提取"] = """---目标---
给定一个可能与此活动相关的文本文档以及一个实体类型列表,从文本中识别出属于这些类型的所有实体,以及所识别出的实体之间的所有关系。
使用 {语言} 作为输出语言。
---步骤---
1. 识别所有实体。对于每个识别出的实体,提取以下信息:
- 实体名称:实体的名称,使用与输入文本相同的语言。如果是英文,将名称首字母大写。
- 实体类型:以下类型之一:[{实体类型}]
- 实体描述:对该实体的属性和活动的全面描述 将每个实体格式化为 ("实体"{元组分隔符}<实体名称>{元组分隔符}<实体类型>{元组分隔符}<实体描述>)
2. 从步骤1中识别出的实体里,确定所有“源实体”与“目标实体”之间 *明确相关* 的成对实体。 对于每一对相关实体,提取以下信息:
- 源实体:源实体的名称,即步骤1中识别出的名称
- 目标实体:目标实体的名称,即步骤1中识别出的名称
- 关系描述:解释你认为源实体和目标实体相关的原因
- 关系强度:一个表示源实体和目标实体之间关系强度的数值分数
- 关系关键词:一个或多个概括关系总体性质的高级关键词,关注概念或主题而非具体细节
将每个关系格式化为 ("关系"{元组分隔符}<源实体>{元组分隔符}<目标实体>{元组分隔符}<关系描述>{元组分隔符}<关系关键词>{元组分隔符}<关系强度>)
3. 识别能够概括整个文本的主要概念、主题或话题的高级关键词。这些关键词应涵盖文档中呈现的总体思想。 将内容层面的关键词格式化为 ("内容关键词"{元组分隔符}<高级关键词>)
4. 使用 **{记录分隔符}** 作为列表分隔符,以单列表的形式用 {语言} 输出步骤1和步骤2中识别出的所有实体和关系。
5. 完成后,输出 {完成分隔符} ###################### ---示例--- ###################### {示例} ############################# ---真实数据--- ###################### 实体类型: [{实体类型}] 文本: {输入文本} ###################### 输出:"""
PROMPTS["entity_extraction"] = """---Goal--- Given a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities. Use {language} as output language. ---Steps--- 1. Identify all entities. For each identified entity, extract the following information: - entity_name: Name of the entity, use same language as input text. If English, capitalized the name. - entity_type: One of the following types: [{entity_types}] - entity_description: Comprehensive description of the entity's attributes and activities Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>) 2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other. For each pair of related entities, extract the following information: - source_entity: name of the source entity, as identified in step 1 - target_entity: name of the target entity, as identified in step 1 - relationship_description: explanation as to why you think the source entity and the target entity are related to each other - relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity - relationship_keywords: one or more high-level key words that summarize the overarching nature of the relationship, focusing on concepts or themes rather than specific details Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_keywords>{tuple_delimiter}<relationship_strength>) 3. Identify high-level key words that summarize the main concepts, themes, or topics of the entire text. These should capture the overarching ideas present in the document. Format the content-level key words as ("content_keywords"{tuple_delimiter}<high_level_keywords>) 4. Return output in {language} as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter. 5. When finished, output {completion_delimiter} ###################### ---Examples--- ###################### {examples} ############################# ---Real Data--- ###################### Entity_types: [{entity_types}] Text: {input_text} ###################### Output:"""
给出一个示例
PROMPTS["entity_extraction_examples"] = [
"""Example 1:
Entity_types: [person, technology, mission, organization, location]
Text:
```
while Alex clenched his jaw, the buzz of frustration dull against the backdrop of Taylor's authoritarian certainty. It was this competitive undercurrent that kept him alert, the sense that his and Jordan's shared commitment to discovery was an unspoken rebellion against Cruz's narrowing vision of control and order.
Then Taylor did something unexpected. They paused beside Jordan and, for a moment, observed the device with something akin to reverence. "If this tech can be understood..." Taylor said, their voice quieter, "It could change the game for us. For all of us."
The underlying dismissal earlier seemed to falter, replaced by a glimpse of reluctant respect for the gravity of what lay in their hands. Jordan looked up, and for a fleeting heartbeat, their eyes locked with Taylor's, a wordless clash of wills softening into an uneasy truce.
It was a small transformation, barely perceptible, but one that Alex noted with an inward nod. They had all been brought here by different paths
```
Output:
("entity"{tuple_delimiter}"Alex"{tuple_delimiter}"person"{tuple_delimiter}"Alex is a character who experiences frustration and is observant of the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"Taylor"{tuple_delimiter}"person"{tuple_delimiter}"Taylor is portrayed with authoritarian certainty and shows a moment of reverence towards a device, indicating a change in perspective."){record_delimiter}
("entity"{tuple_delimiter}"Jordan"{tuple_delimiter}"person"{tuple_delimiter}"Jordan shares a commitment to discovery and has a significant interaction with Taylor regarding a device."){record_delimiter}
("entity"{tuple_delimiter}"Cruz"{tuple_delimiter}"person"{tuple_delimiter}"Cruz is associated with a vision of control and order, influencing the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"The Device"{tuple_delimiter}"technology"{tuple_delimiter}"The Device is central to the story, with potential game-changing implications, and is revered by Taylor."){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Taylor"{tuple_delimiter}"Alex is affected by Taylor's authoritarian certainty and observes changes in Taylor's attitude towards the device."{tuple_delimiter}"power dynamics, perspective shift"{tuple_delimiter}7){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Jordan"{tuple_delimiter}"Alex and Jordan share a commitment to discovery, which contrasts with Cruz's vision."{tuple_delimiter}"shared goals, rebellion"{tuple_delimiter}6){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"Jordan"{tuple_delimiter}"Taylor and Jordan interact directly regarding the device, leading to a moment of mutual respect and an uneasy truce."{tuple_delimiter}"conflict resolution, mutual respect"{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Jordan"{tuple_delimiter}"Cruz"{tuple_delimiter}"Jordan's commitment to discovery is in rebellion against Cruz's vision of control and order."{tuple_delimiter}"ideological conflict, rebellion"{tuple_delimiter}5){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"The Device"{tuple_delimiter}"Taylor shows reverence towards the device, indicating its importance and potential impact."{tuple_delimiter}"reverence, technological significance"{tuple_delimiter}9){record_delimiter}
("content_keywords"{tuple_delimiter}"power dynamics, ideological conflict, discovery, rebellion"){completion_delimiter}
#############################""",
"""Example 2:
Entity_types: [company, index, commodity, market_trend, economic_policy, biological]
Text:
```
Stock markets faced a sharp downturn today as tech giants saw significant declines, with the Global Tech Index dropping by 3.4% in midday trading. Analysts attribute the selloff to investor concerns over rising interest rates and regulatory uncertainty.
Among the hardest hit, Nexon Technologies saw its stock plummet by 7.8% after reporting lower-than-expected quarterly earnings. In contrast, Omega Energy posted a modest 2.1% gain, driven by rising oil prices.
Meanwhile, commodity markets reflected a mixed sentiment. Gold futures rose by 1.5%, reaching $2,080 per ounce, as investors sought safe-haven assets. Crude oil prices continued their rally, climbing to $87.60 per barrel, supported by supply constraints and strong demand.
Financial experts are closely watching the Federal Reserve's next move, as speculation grows over potential rate hikes. The upcoming policy announcement is expected to influence investor confidence and overall market stability.
```
Output:
("entity"{tuple_delimiter}"Global Tech Index"{tuple_delimiter}"index"{tuple_delimiter}"The Global Tech Index tracks the performance of major technology stocks and experienced a 3.4% decline today."){record_delimiter}
("entity"{tuple_delimiter}"Nexon Technologies"{tuple_delimiter}"company"{tuple_delimiter}"Nexon Technologies is a tech company that saw its stock decline by 7.8% after disappointing earnings."){record_delimiter}
("entity"{tuple_delimiter}"Omega Energy"{tuple_delimiter}"company"{tuple_delimiter}"Omega Energy is an energy company that gained 2.1% in stock value due to rising oil prices."){record_delimiter}
("entity"{tuple_delimiter}"Gold Futures"{tuple_delimiter}"commodity"{tuple_delimiter}"Gold futures rose by 1.5%, indicating increased investor interest in safe-haven assets."){record_delimiter}
("entity"{tuple_delimiter}"Crude Oil"{tuple_delimiter}"commodity"{tuple_delimiter}"Crude oil prices rose to $87.60 per barrel due to supply constraints and strong demand."){record_delimiter}
("entity"{tuple_delimiter}"Market Selloff"{tuple_delimiter}"market_trend"{tuple_delimiter}"Market selloff refers to the significant decline in stock values due to investor concerns over interest rates and regulations."){record_delimiter}
("entity"{tuple_delimiter}"Federal Reserve Policy Announcement"{tuple_delimiter}"economic_policy"{tuple_delimiter}"The Federal Reserve's upcoming policy announcement is expected to impact investor confidence and market stability."){record_delimiter}
("relationship"{tuple_delimiter}"Global Tech Index"{tuple_delimiter}"Market Selloff"{tuple_delimiter}"The decline in the Global Tech Index is part of the broader market selloff driven by investor concerns."{tuple_delimiter}"market performance, investor sentiment"{tuple_delimiter}9){record_delimiter}
("relationship"{tuple_delimiter}"Nexon Technologies"{tuple_delimiter}"Global Tech Index"{tuple_delimiter}"Nexon Technologies' stock decline contributed to the overall drop in the Global Tech Index."{tuple_delimiter}"company impact, index movement"{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Gold Futures"{tuple_delimiter}"Market Selloff"{tuple_delimiter}"Gold prices rose as investors sought safe-haven assets during the market selloff."{tuple_delimiter}"market reaction, safe-haven investment"{tuple_delimiter}10){record_delimiter}
("relationship"{tuple_delimiter}"Federal Reserve Policy Announcement"{tuple_delimiter}"Market Selloff"{tuple_delimiter}"Speculation over Federal Reserve policy changes contributed to market volatility and investor selloff."{tuple_delimiter}"interest rate impact, financial regulation"{tuple_delimiter}7){record_delimiter}
("content_keywords"{tuple_delimiter}"market downturn, investor sentiment, commodities, Federal Reserve, stock performance"){completion_delimiter}
#############################""",
"""Example 3:
Entity_types: [economic_policy, athlete, event, location, record, organization, equipment]
Text:
```
At the World Athletics Championship in Tokyo, Noah Carter broke the 100m sprint record using cutting-edge carbon-fiber spikes.
```
Output:
("entity"{tuple_delimiter}"World Athletics Championship"{tuple_delimiter}"event"{tuple_delimiter}"The World Athletics Championship is a global sports competition featuring top athletes in track and field."){record_delimiter}
("entity"{tuple_delimiter}"Tokyo"{tuple_delimiter}"location"{tuple_delimiter}"Tokyo is the host city of the World Athletics Championship."){record_delimiter}
("entity"{tuple_delimiter}"Noah Carter"{tuple_delimiter}"athlete"{tuple_delimiter}"Noah Carter is a sprinter who set a new record in the 100m sprint at the World Athletics Championship."){record_delimiter}
("entity"{tuple_delimiter}"100m Sprint Record"{tuple_delimiter}"record"{tuple_delimiter}"The 100m sprint record is a benchmark in athletics, recently broken by Noah Carter."){record_delimiter}
("entity"{tuple_delimiter}"Carbon-Fiber Spikes"{tuple_delimiter}"equipment"{tuple_delimiter}"Carbon-fiber spikes are advanced sprinting shoes that provide enhanced speed and traction."){record_delimiter}
("entity"{tuple_delimiter}"World Athletics Federation"{tuple_delimiter}"organization"{tuple_delimiter}"The World Athletics Federation is the governing body overseeing the World Athletics Championship and record validations."){record_delimiter}
("relationship"{tuple_delimiter}"World Athletics Championship"{tuple_delimiter}"Tokyo"{tuple_delimiter}"The World Athletics Championship is being hosted in Tokyo."{tuple_delimiter}"event location, international competition"{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Noah Carter"{tuple_delimiter}"100m Sprint Record"{tuple_delimiter}"Noah Carter set a new 100m sprint record at the championship."{tuple_delimiter}"athlete achievement, record-breaking"{tuple_delimiter}10){record_delimiter}
("relationship"{tuple_delimiter}"Noah Carter"{tuple_delimiter}"Carbon-Fiber Spikes"{tuple_delimiter}"Noah Carter used carbon-fiber spikes to enhance performance during the race."{tuple_delimiter}"athletic equipment, performance boost"{tuple_delimiter}7){record_delimiter}
("relationship"{tuple_delimiter}"World Athletics Federation"{tuple_delimiter}"100m Sprint Record"{tuple_delimiter}"The World Athletics Federation is responsible for validating and recognizing new sprint records."{tuple_delimiter}"sports regulation, record certification"{tuple_delimiter}9){record_delimiter}
("content_keywords"{tuple_delimiter}"athletics, sprinting, record-breaking, sports technology, competition"){completion_delimiter}
#############################""",
]
这里先回去研究下entity_types在哪里给,从示例可以看出,这决定了能抽取的实体类别,只要我们提前限定,就能定义它抽取出来的type(比如我可以把umls的类别给它,umls的类别是医学专家确定的,还是比较靠谱的)
从operate.py看到:
entity_types = global_config["addon_params"].get(
"entity_types", PROMPTS["DEFAULT_ENTITY_TYPES"]
)
从而可以找到定义的类别,这显然和咱们的医学不太符合,所以很鸡贼的把它注释掉,换成我自己的,直接注释了其他地方也不用改:
其它地方咱们的原则也是:改嘛,放心大胆的改,改的地方都记住,改错了再对照着改回来就行。改提示词反正也不会改到系统配置啥的。
PROMPTS["DEFAULT_ENTITY_TYPES"] = ["organization", "person", "geo", "event", "category"]“组织”,“个人”,“地理(信息 / 事物)”,“事件”,“类别”
我在这还看见了,这也解释了为啥之前我抽取的知识图谱是中英双语的。这里感觉没啥大影响,先不改。
PROMPTS["DEFAULT_LANGUAGE"] = "English"
这个提示词还有一个关键信息:关系也是在这里抽取的,我之前遇见的问题就是出现了很多内容重复但是id不重复的边,在这里我要解决这个问题,但阅读提示词之后,我发现添加id并不在这个步骤中。但经历上述分析,我了解到:想要修改提取的实体和关系类型,修改entity_extraction与entity_extraction_examples中的提示词内容是第一步。
但这种修改只能影响到大模型的回应结果,后续还有格式化和存储等过程,所以咱们继续分析。回到lightRAG.py,标注位置就是知识图谱创建的函数
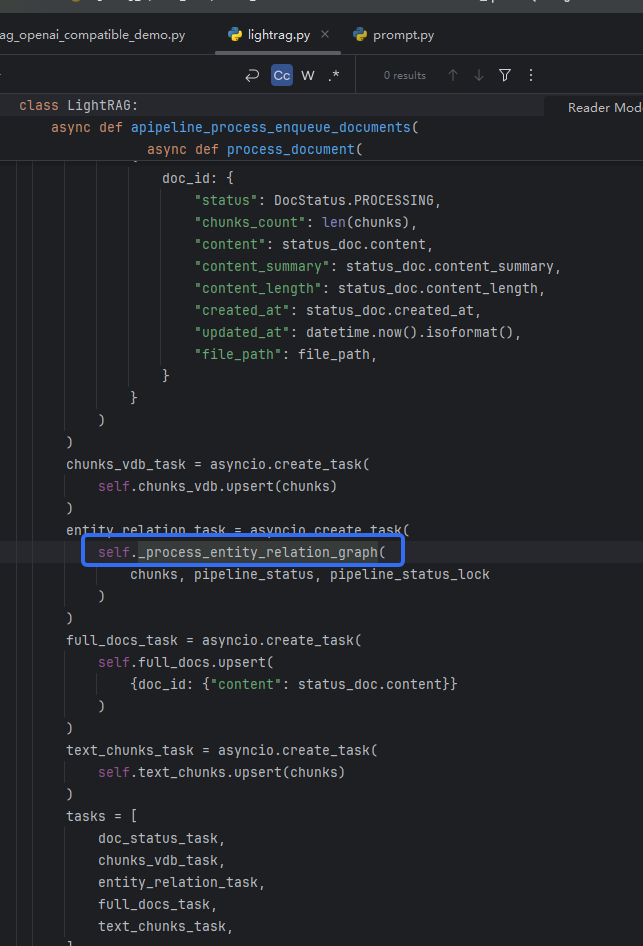 :
:
这个函数的核心函数为extract_entities
抽取结果要提取内容,以元组形式返回,包含提取的实体和关系。标记处的函数展示了提取返回的结果。如果我们之前修改了大模型的返回类型,就要在该函数那里修改返回的元组类型:
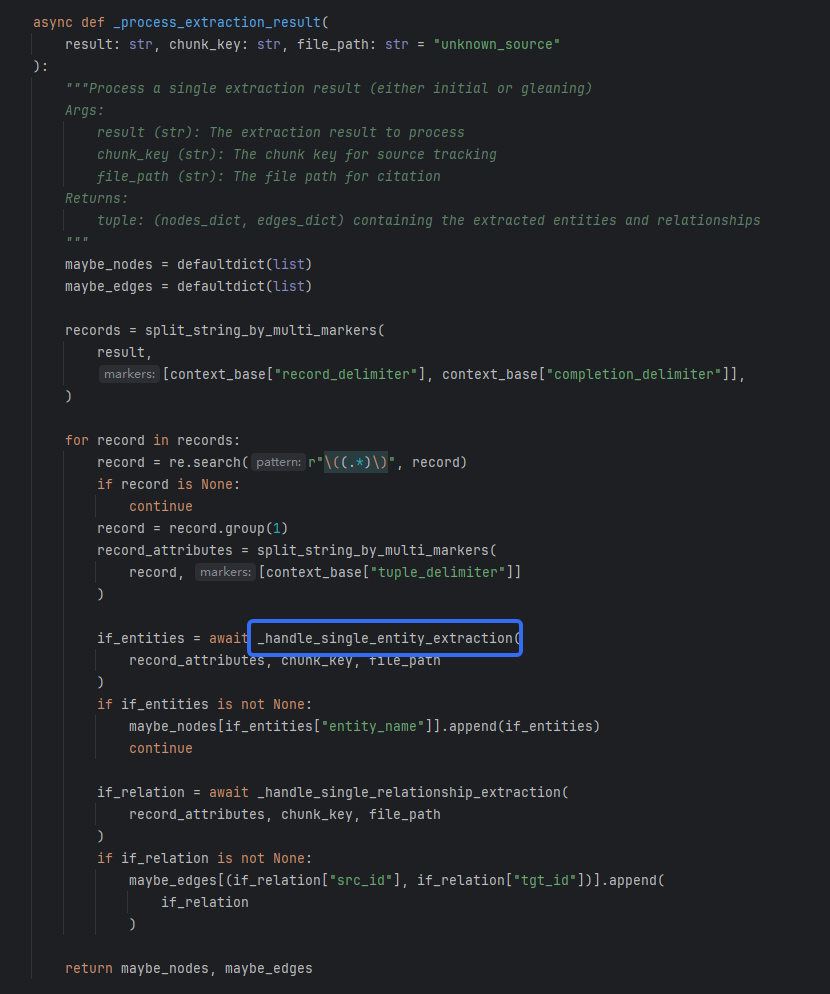
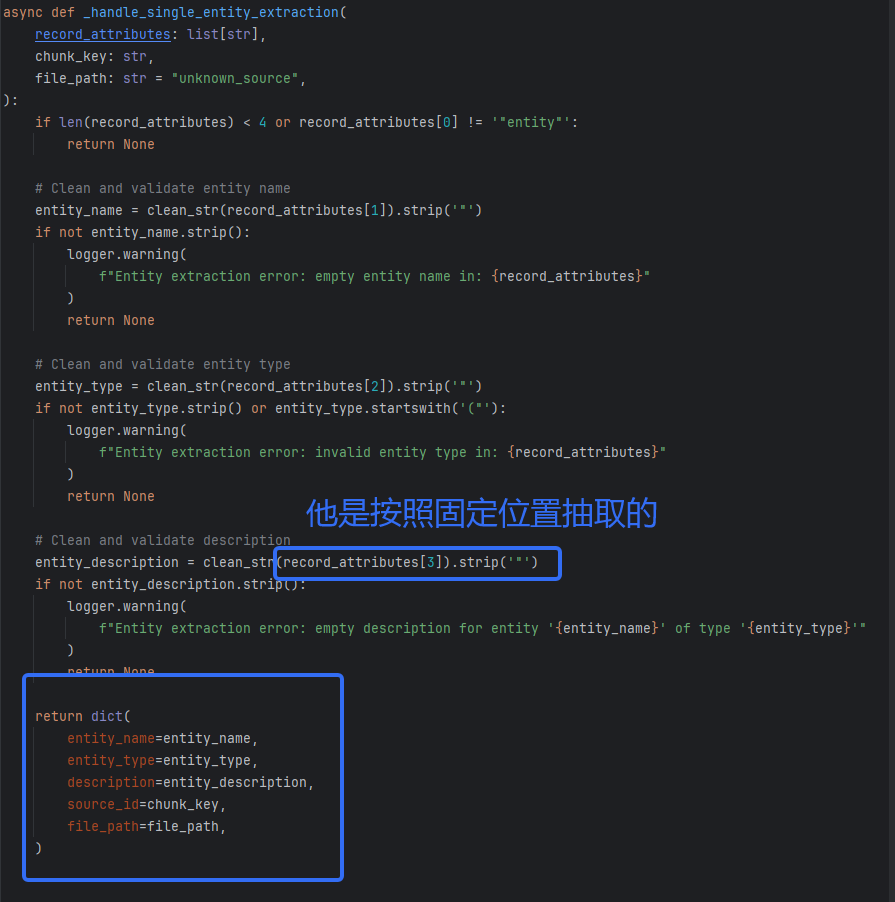
关系抽取给出了一些id,也是按位置提取的。这里复习一下关系的返回格式
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_keywords>{tuple_delimiter}<relationship_strength>)- source_entity: name of the source entity, as identified in step 1 - target_entity: name of the target entity, as identified in step 1 - relationship_description: explanation as to why you think the source entity and the target entity are related to each other - relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity - relationship_keywords: one or more high-level key words that summarize the overarching nature of the relationship, focusing on concepts or themes rather than specific details

下面这段代码主打合并之前提取的边和节点
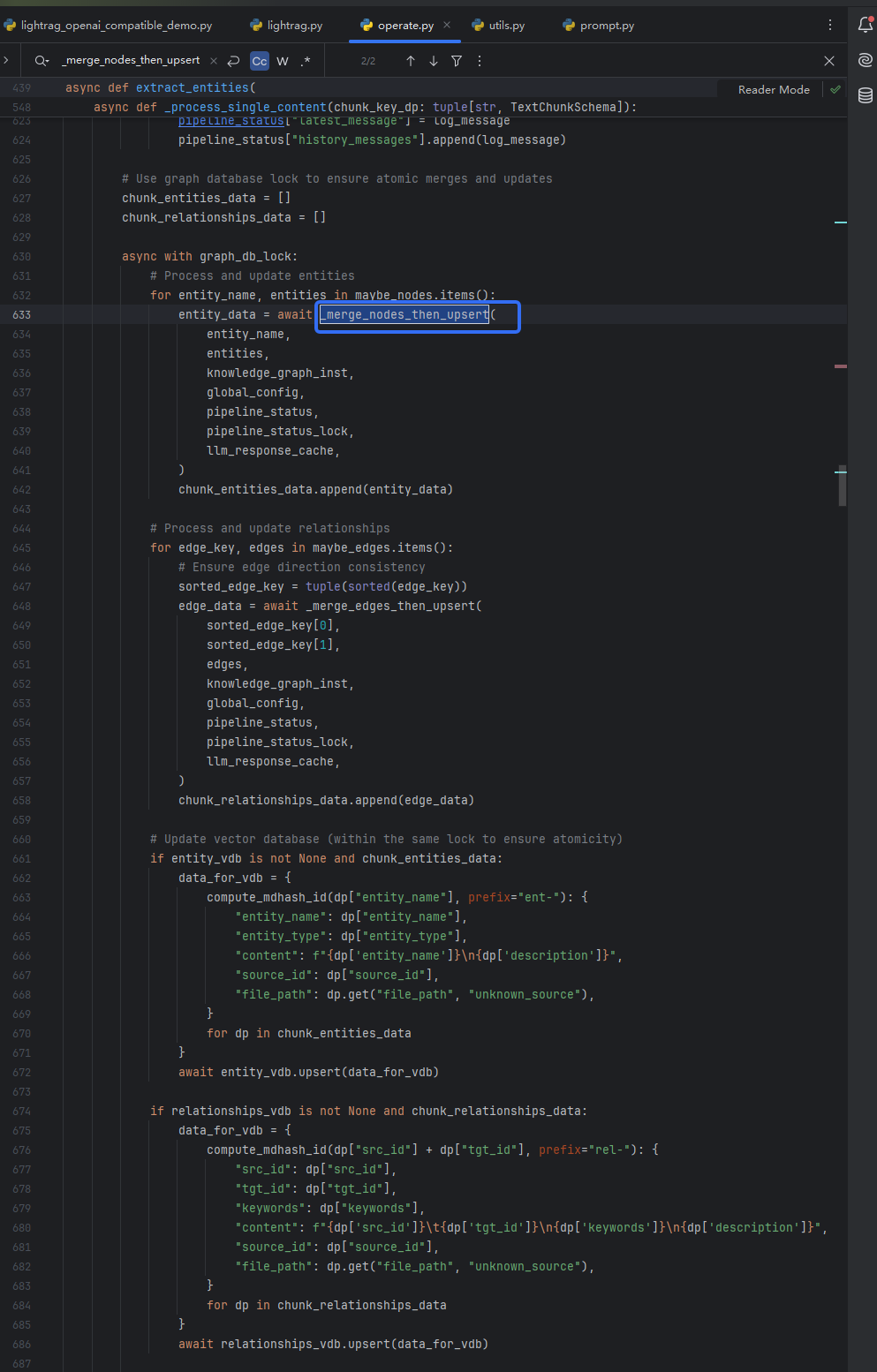
详细分析框出来的合并节点代码:
async def _merge_nodes_then_upsert(
entity_name: str,
nodes_data: list[dict],
knowledge_graph_inst: BaseGraphStorage,
global_config: dict,
pipeline_status: dict = None,
pipeline_status_lock=None,
llm_response_cache: BaseKVStorage | None = None,
):
"""Get existing nodes from knowledge graph use name,if exists, merge data, else create, then upsert."""
already_entity_types = []
already_source_ids = []
already_description = []
already_file_paths = []
检查实体是否已存在
already_node = await knowledge_graph_inst.get_node(entity_name)
若已存在节点,准备合并
if already_node is not None:
# Update pipeline status when a node that needs merging is found
status_message = f"Merging entity: {entity_name}"
logger.info(status_message)
if pipeline_status is not None and pipeline_status_lock is not None:
async with pipeline_status_lock:
pipeline_status["latest_message"] = status_message
pipeline_status["history_messages"].append(status_message)
already_entity_types.append(already_node["entity_type"])
already_source_ids.extend(
split_string_by_multi_markers(already_node["source_id"], [GRAPH_FIELD_SEP])
)
already_file_paths.extend(
split_string_by_multi_markers(already_node["file_path"], [GRAPH_FIELD_SEP])
)
already_description.append(already_node["description"])
entity_type = sorted(
Counter(
[dp["entity_type"] for dp in nodes_data] + already_entity_types
).items(),
key=lambda x: x[1],
reverse=True,
)[0][0]
description = GRAPH_FIELD_SEP.join(
sorted(set([dp["description"] for dp in nodes_data] + already_description))
)
source_id = GRAPH_FIELD_SEP.join(
set([dp["source_id"] for dp in nodes_data] + already_source_ids)
)
file_path = GRAPH_FIELD_SEP.join(
set([dp["file_path"] for dp in nodes_data] + already_file_paths)
)
logger.debug(f"file_path: {file_path}")
description = await _handle_entity_relation_summary(
entity_name,
description,
global_config,
pipeline_status,
pipeline_status_lock,
llm_response_cache,
)
node_data = dict(
entity_id=entity_name,
entity_type=entity_type,
description=description,
source_id=source_id,
file_path=file_path,
)
await knowledge_graph_inst.upsert_node(
entity_name,
node_data=node_data,
)
node_data["entity_name"] = entity_name
return node_datax
可以看到,上述代码的重点是,如何获取已经有的节点,结合下列线索,需要找到初始的图存储
@abstractmethod
async def get_node(self, node_id: str) -> dict[str, str] | None:
"""Get node by its label identifier, return only node properties"""
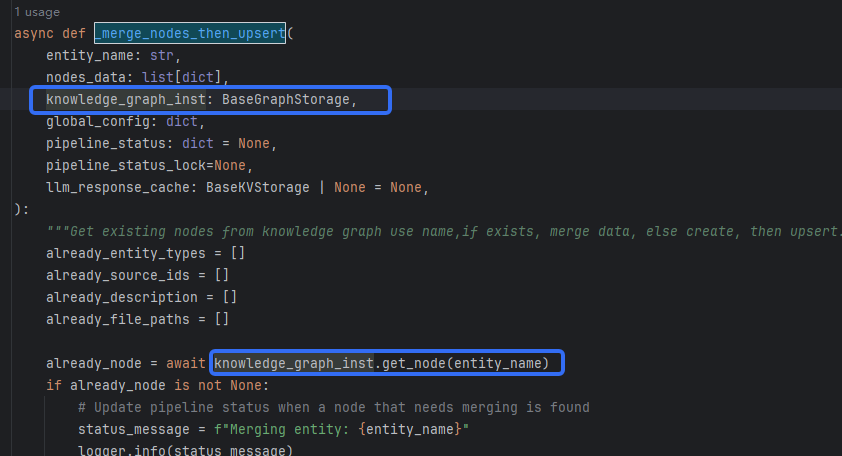
目前只找到抽象类
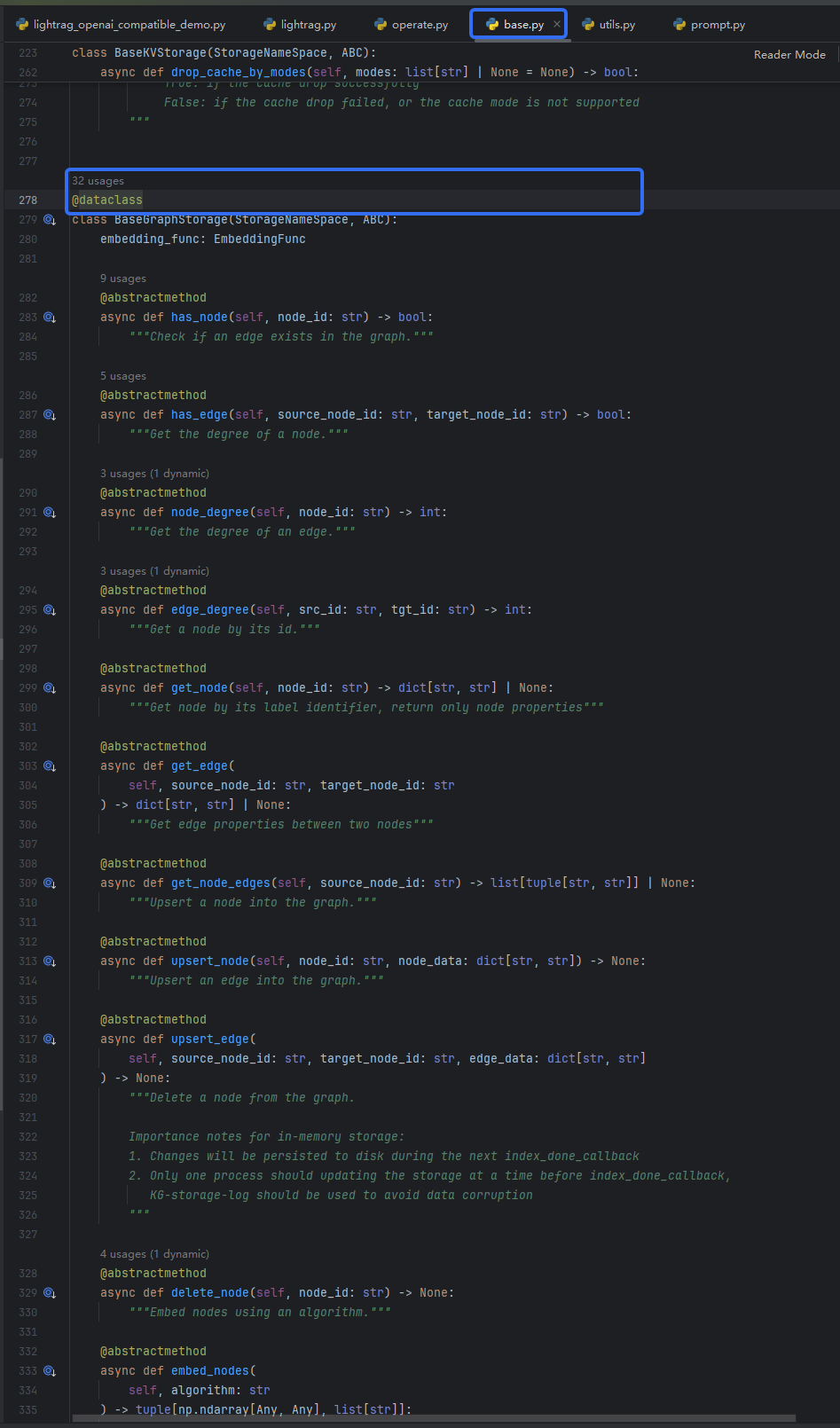
我们去看看是在哪里定义的数据库,这个数据库就是我们去重和更新的基础,应该是在init.py
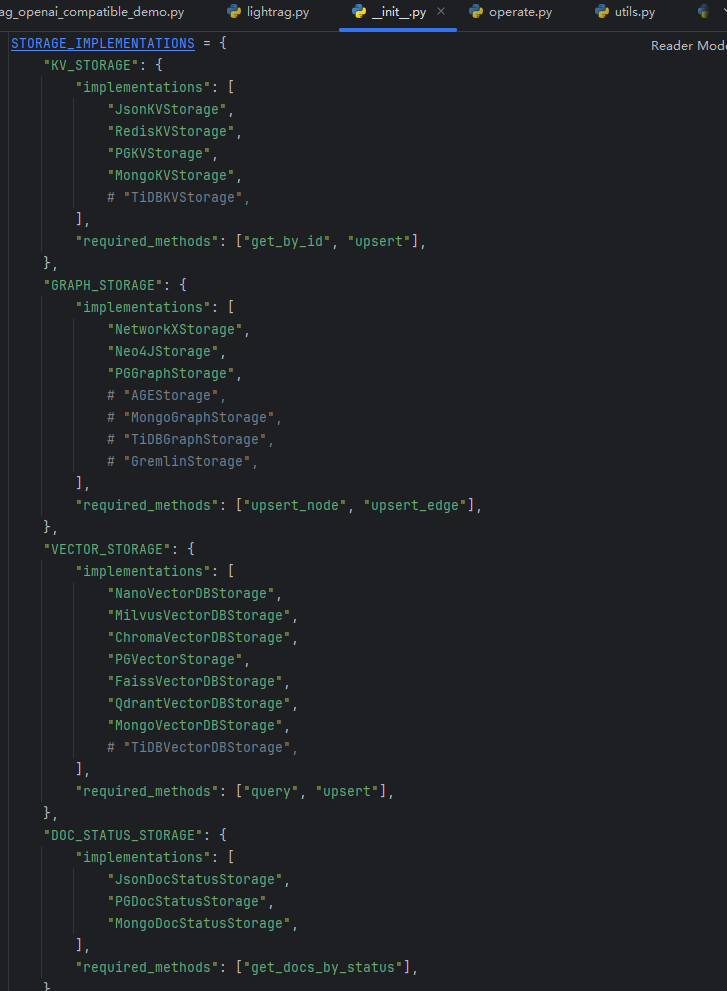
在lightRAG中会获取init.py的存储
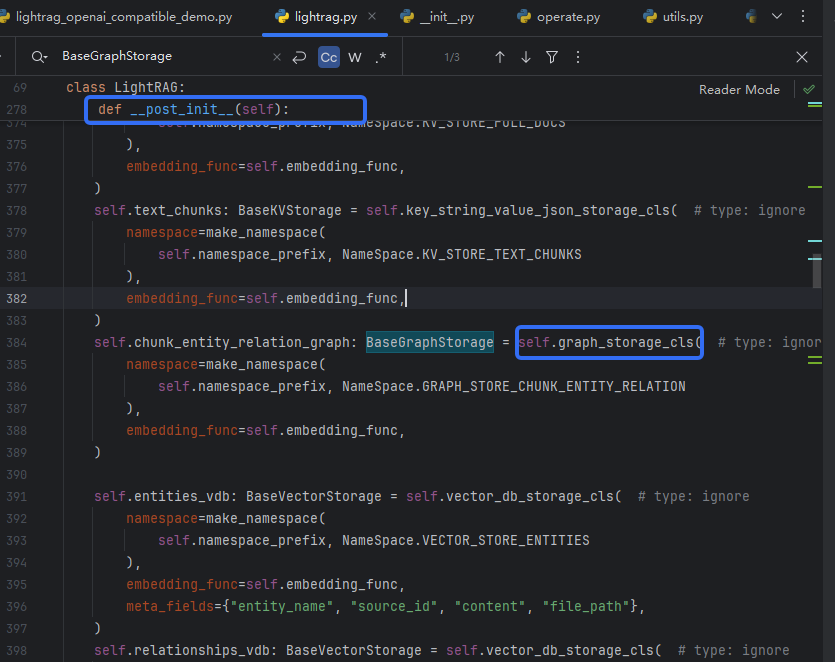
详细分析合并边的代码
async def _merge_edges_then_upsert(
src_id: str,
tgt_id: str,
edges_data: list[dict],
knowledge_graph_inst: BaseGraphStorage,
global_config: dict,
pipeline_status: dict = None,
pipeline_status_lock=None,
llm_response_cache: BaseKVStorage | None = None,
):
already_weights = []
already_source_ids = []
already_description = []
already_keywords = []
already_file_paths = []
if await knowledge_graph_inst.has_edge(src_id, tgt_id):
# Update pipeline status when an edge that needs merging is found
status_message = f"Merging edge::: {src_id} - {tgt_id}"
logger.info(status_message)
if pipeline_status is not None and pipeline_status_lock is not None:
async with pipeline_status_lock:
pipeline_status["latest_message"] = status_message
pipeline_status["history_messages"].append(status_message)
already_edge = await knowledge_graph_inst.get_edge(src_id, tgt_id)
# Handle the case where get_edge returns None or missing fields
if already_edge:
# Get weight with default 0.0 if missing
already_weights.append(already_edge.get("weight", 0.0))
# Get source_id with empty string default if missing or None
if already_edge.get("source_id") is not None:
already_source_ids.extend(
split_string_by_multi_markers(
already_edge["source_id"], [GRAPH_FIELD_SEP]
)
)
# Get file_path with empty string default if missing or None
if already_edge.get("file_path") is not None:
already_file_paths.extend(
split_string_by_multi_markers(
already_edge["file_path"], [GRAPH_FIELD_SEP]
)
)
# Get description with empty string default if missing or None
if already_edge.get("description") is not None:
already_description.append(already_edge["description"])
# Get keywords with empty string default if missing or None
if already_edge.get("keywords") is not None:
already_keywords.extend(
split_string_by_multi_markers(
already_edge["keywords"], [GRAPH_FIELD_SEP]
)
)
# Process edges_data with None checks
weight = sum([dp["weight"] for dp in edges_data] + already_weights)
description = GRAPH_FIELD_SEP.join(
sorted(
set(
[dp["description"] for dp in edges_data if dp.get("description")]
+ already_description
)
)
)
keywords = GRAPH_FIELD_SEP.join(
sorted(
set(
[dp["keywords"] for dp in edges_data if dp.get("keywords")]
+ already_keywords
)
)
)
source_id = GRAPH_FIELD_SEP.join(
set(
[dp["source_id"] for dp in edges_data if dp.get("source_id")]
+ already_source_ids
)
)
file_path = GRAPH_FIELD_SEP.join(
set(
[dp["file_path"] for dp in edges_data if dp.get("file_path")]
+ already_file_paths
)
)
for need_insert_id in [src_id, tgt_id]:
if not (await knowledge_graph_inst.has_node(need_insert_id)):
await knowledge_graph_inst.upsert_node(
need_insert_id,
node_data={
"entity_id": need_insert_id,
"source_id": source_id,
"description": description,
"entity_type": "UNKNOWN",
"file_path": file_path,
},
)
description = await _handle_entity_relation_summary(
f"({src_id}, {tgt_id})",
description,
global_config,
pipeline_status,
pipeline_status_lock,
llm_response_cache,
)
await knowledge_graph_inst.upsert_edge(
src_id,
tgt_id,
edge_data=dict(
weight=weight,
description=description,
keywords=keywords,
source_id=source_id,
file_path=file_path,
),
)
edge_data = dict(
src_id=src_id,
tgt_id=tgt_id,
description=description,
keywords=keywords,
source_id=source_id,
file_path=file_path,
)
return edge_data
这里的存储用的是vdb,
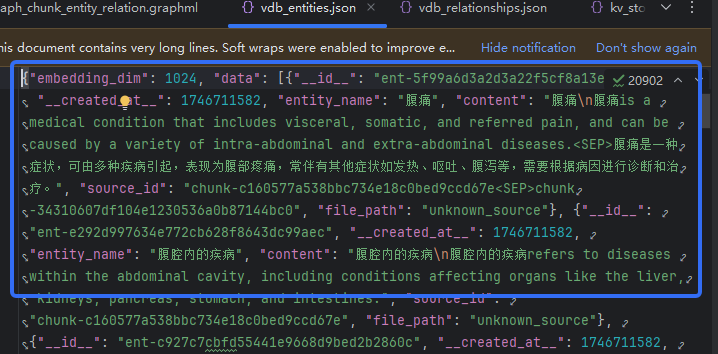
最后注入neo4j是这个文件:E:\UMLS\research\research1\LightRAG-main\LightRAG-main\examples\dickens\graph_chunk_entity_relation.graphml
这里要注意d0对应html的“entity_name”,
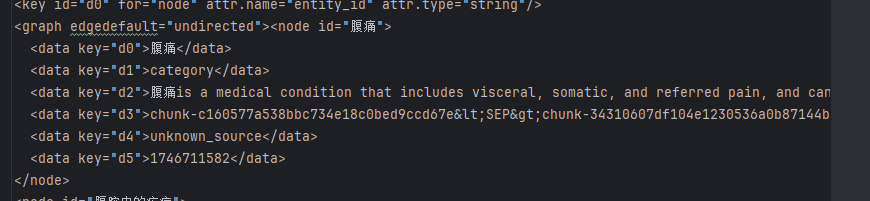
这次调优的关键任务就在加id和去重上面,所以其实在graphxl文件启动可视化导入neo4j之前,用代码进行去重和筛查,微调结果再插入,就可以控制neo4jj的规范和非重复了。我之前有问题就是在于该文件导入neo4j的语句不规范。
最后!./dicks文件夹是运行example中的导入文件才会生成的,如果换了模型要及时删除重新生成。在修改前一定要用github保存!否则很容易好像什么都没改,但是整个项目不能用了,导致要重新部署和写代码!
多轮抽取
为啥用框架而不是自己实现实体关系抽取,很大一个原因就是,框架作者会提前考虑很多细节,比如这里就会多次抽取,防止遗漏:
提示信息["实体持续提取"] = """
在上一次提取中遗漏了许多实体和关系。
---记住步骤---
1. 识别所有实体。对于每个识别出的实体,提取以下信息:
- 实体名称:实体的名称,使用与输入文本相同的语言。如果是英文,将名称首字母大写。
- 实体类型:以下类型之一:[{实体类型}]
- 实体描述:对该实体的属性和活动的全面描述 将每个实体格式化为 ("实体"{元组分隔符}<实体名称>{元组分隔符}<实体类型>{元组分隔符}<实体描述>
2. 从步骤1中识别出的实体里,确定所有“源实体”与“目标实体”之间 *明确相关* 的成对实体。 对于每一对相关实体,提取以下信息:
- 源实体:源实体的名称,即步骤1中识别出的名称
- 目标实体:目标实体的名称,即步骤1中识别出的名称
- 关系描述:解释你认为源实体和目标实体相关的原因
- 关系强度:一个表示源实体和目标实体之间关系强度的数值分数
- 关系关键词:一个或多个概括关系总体性质的高级关键词,关注概念或主题而非具体细节 将每个关系格式化为 ("关系"{元组分隔符}<源实体>{元组分隔符}<目标实体>{元组分隔符}<关系描述>{元组分隔符}<关系关键词>{元组分隔符}<关系强度>)
3. 识别能够概括整个文本的主要概念、主题或话题的高级关键词。这些关键词应涵盖文档中呈现的总体思想。 将内容层面的关键词格式化为 ("内容关键词"{元组分隔符}<高级关键词>)
4. 用 {语言} 以单列表的形式输出步骤1和步骤2中识别出的所有实体和关系,使用 **{记录分隔符}** 作为列表分隔符。 5. 完成后,输出 {完成分隔符} ---输出--- 使用相同格式将它们添加在下面:\n """ (已去除首尾多余空白字符)
PROMPTS["entity_continue_extraction"] = """
MANY entities and relationships were missed in the last extraction.
---Remember Steps---
1. Identify all entities. For each identified entity, extract the following information:
- entity_name: Name of the entity, use same language as input text. If English, capitalized the name.
- entity_type: One of the following types: [{entity_types}]
- entity_description: Comprehensive description of the entity's attributes and activities
Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>
2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other.
For each pair of related entities, extract the following information:
- source_entity: name of the source entity, as identified in step 1
- target_entity: name of the target entity, as identified in step 1
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity
- relationship_keywords: one or more high-level key words that summarize the overarching nature of the relationship, focusing on concepts or themes rather than specific details
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_keywords>{tuple_delimiter}<relationship_strength>)
3. Identify high-level key words that summarize the main concepts, themes, or topics of the entire text. These should capture the overarching ideas present in the document.
Format the content-level key words as ("content_keywords"{tuple_delimiter}<high_level_keywords>)
4. Return output in {language} as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
5. When finished, output {completion_delimiter}
---Output---
Add them below using the same format:\n
""".strip()


















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









