






分类与聚类
分类
分类其实是从特定的数据中挖掘模式,作出判断的过程。
聚类
从广义上说,聚类就是将数据集中在某些方面相似的数据成员放在一起。
一个聚类就是一些数据实例的集合,其中处于相同聚类中的数据元素彼此相似,但是处于不同聚类中的元素彼此不同。
由于在聚类中那些表示数据类别的分类或分组信息是没有的,即这些数据是没有标签的,所以聚类通常被归为无监督学习(Unsupervised Learning)。
聚类算法分为三大类:
- 原型聚类:
• K均值聚类算法 - 层次聚类
- 密度聚类
k-means聚类
k-means聚类算法的分析流程:
第一步,确定K值,即将数据集聚集成K个类簇或小组。
第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心。
第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组。
第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心。(对于每个簇,计算其均值,即得到新的k个质心点)
第五步,迭代执行第三步到第四步,直到迭代终止条件满足为止(聚类结果不再变化)
k-means聚类与图像处理
在图像处理中,通过K-Means聚类算法可以实现图像分割、图像聚类、图像识别等操作。
我们通过K-Means可以将这些像素点聚类成K个簇,然后使用每个簇内的质心点来替换簇内所有
的像素点,这样就能实现在不改变分辨率的情况下量化压缩图像颜色,实现图像颜色层级分割。
优点:
1.是解决聚类问题的一种经典算法,简单、快速
2.对处理大数据集,该算法保持高效率
3.当结果簇是密集的,它的效果较好
缺点:
1.必须事先给出k(要生成的簇的数目)。
2.对躁声和孤立点数据敏感
层次聚类
层次聚类是一种很直观的算法。顾名思义就是要一层一层地进行聚类。
层次聚类算法根据层次分解的顺序分为:自下底向上和自上向下,即凝聚的层次聚类算法和分裂的层次聚
类算法(agglomerative和divisive),也可以理解为自下而上法(bottom-up)和自上而下法(top- down)。
凝聚层次聚类agglomerative
参考https://blog.csdn.net/q923714892/article/details/117387574
凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对
象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间
相似度的定义上有所不同。 这里给出采用最小距离的凝聚层次聚类算法流程:
(1) 将每个对象看作一类,计算两两之间的最小距离;
(2) 将距离最小的两个类合并成一个新类;
(3) 重新计算新类与所有类之间的距离;
(4) 重复(2)、(3),直到所有类最后合并成一类。
特点:
• 凝聚的层次聚类并没有类似K均值的全局目标函数,没有局部极小问题或是很难选择初始点的问题。
• 合并的操作往往是最终的,一旦合并两个簇之后就不会撤销。
• 当然其计算存储的代价是昂贵的。
代码举例:
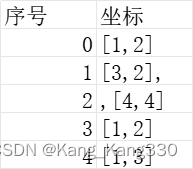
X = [[1,2],[3,2],[4,4],[1,2],[1,3]]
# -*- coding: utf-8 -*-
'''@Time: 2024/5/25 22:33
'''
###cluster.py
#导入相应的包
from scipy.cluster.hierarchy import dendrogram, linkage,fcluster
from matplotlib import pyplot as plt
'''
linkage(y, method=’single’, metric=’euclidean’) 共包含3个参数:
1. y是距离矩阵,可以是1维压缩向量(距离向量),也可以是2维观测向量(坐标矩阵)。
若y是1维压缩向量,则y必须是n个初始观测值的组合,n是坐标矩阵中成对的观测值。
2. method是指计算类间距离的方法。
'''
'''
fcluster(Z, t, criterion=’inconsistent’, depth=2, R=None, monocrit=None)
1.第一个参数Z是linkage得到的矩阵,记录了层次聚类的层次信息;
2.t是一个聚类的阈值-“The threshold to apply when forming flat clusters”。
'''
X = [[1,2],[3,2],[4,4],[1,2],[1,3]]
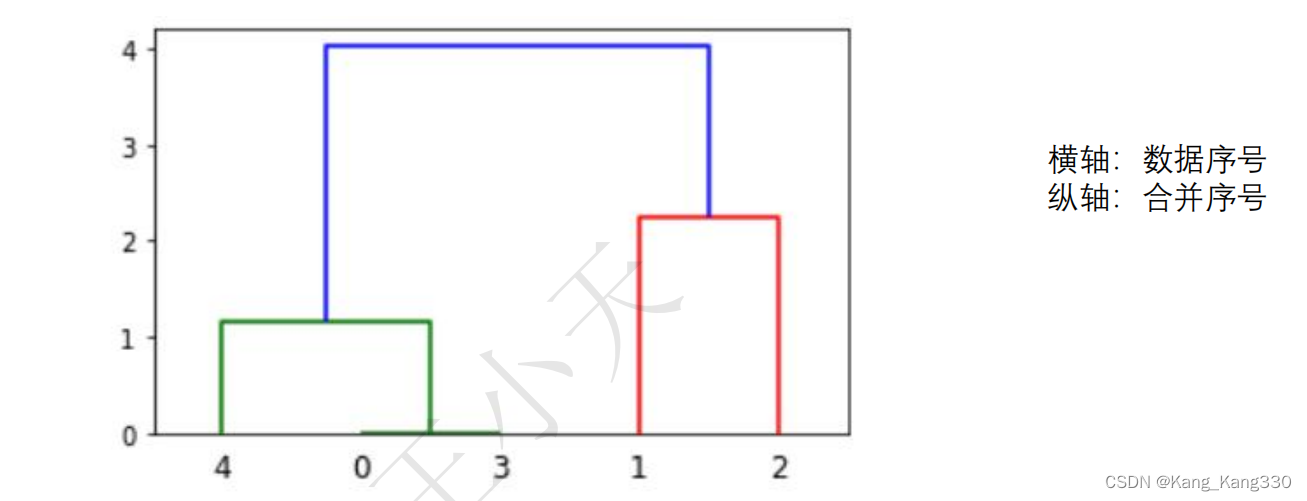
Z = linkage(X, 'ward')
f = fcluster(Z,4,'distance')
fig = plt.figure(figsize=(5, 3))
dn = dendrogram(Z)
print(Z)
plt.show()
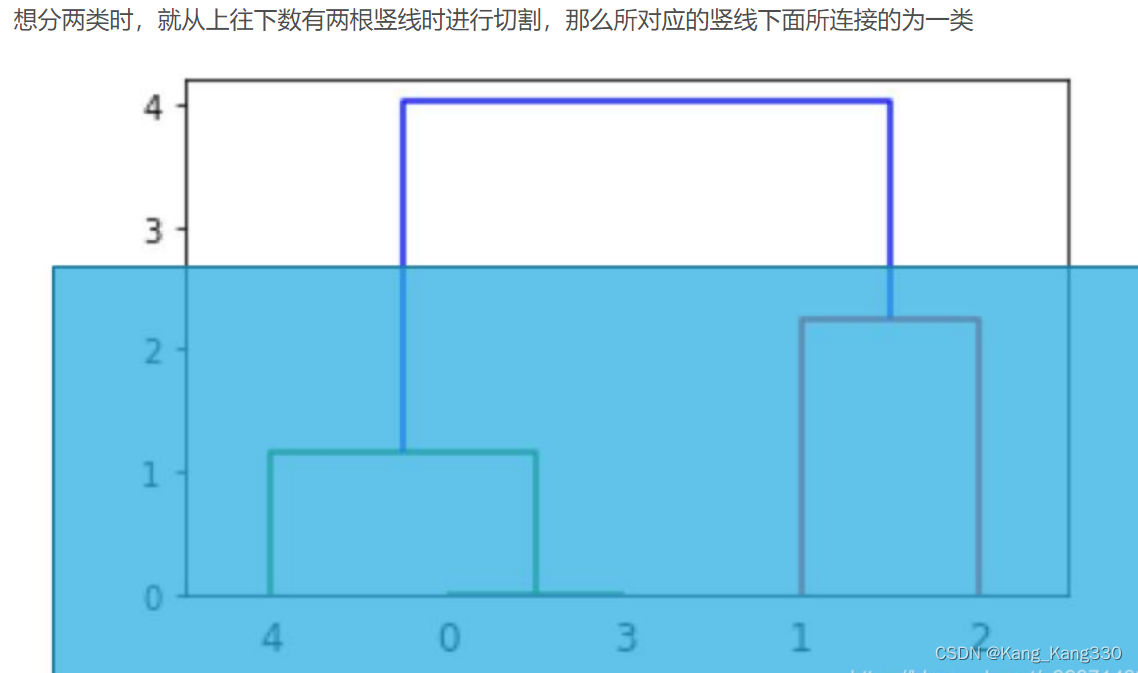
先穷举,再从上往下找,想分几类。
密度聚类
需要两个参数:ε (eps) 和形成高密度区域所需要的最少点数 (minPts)
• 它由一个任意未被访问的点开始,然后探索这个点的 ε-邻域,如果 ε-邻域里有足够的点,则建立一
个新的聚类,否则这个点被标签为杂音。
• 注意,这个杂音点之后可能被发现在其它点的 ε-邻域里,而该 ε-邻域可能有足够的点,届时这个点
会被加入该聚类中
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.cluster import DBSCAN
iris = datasets.load_iris()
X = iris.data[:, :4] # #表示我们只取特征空间中的4个维度
print(X.shape)
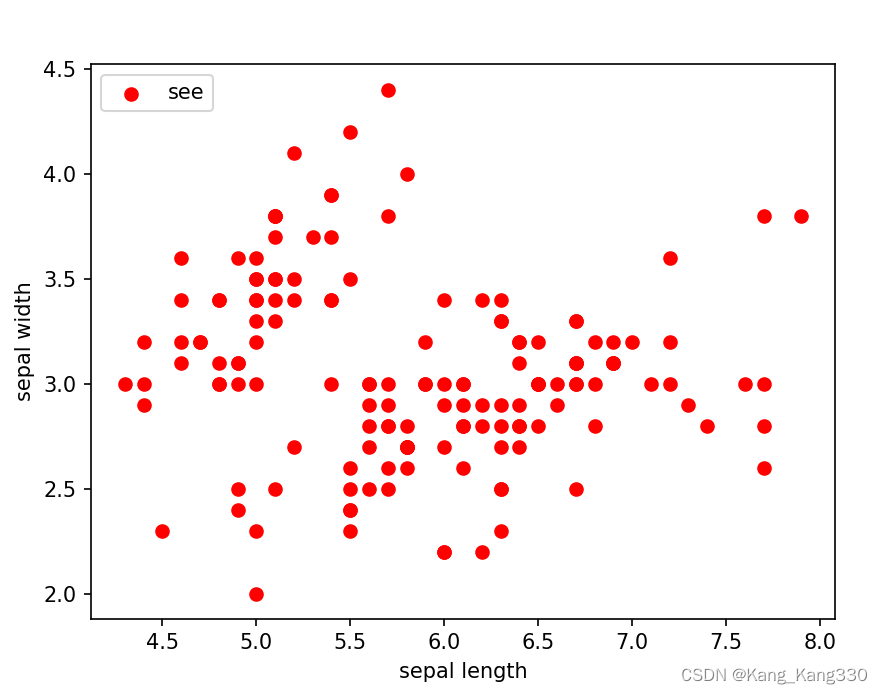
# 绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
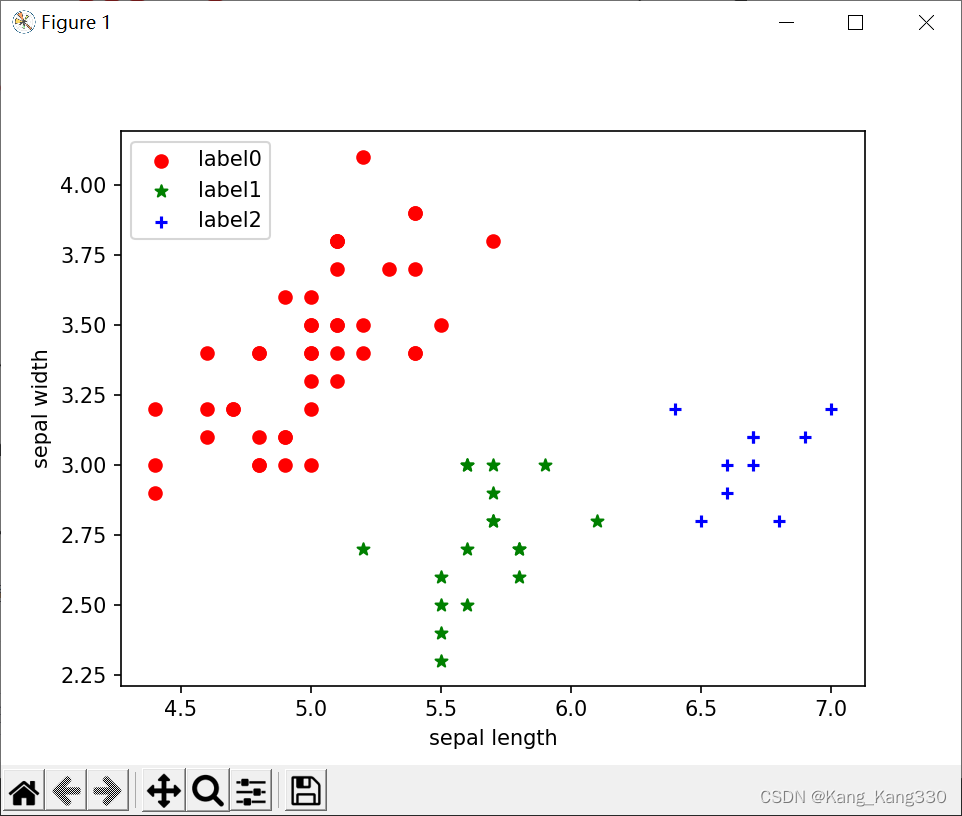
dbscan = DBSCAN(eps=0.4, min_samples=9)#一个点周围必须9个点
dbscan.fit(X)
label_pred = dbscan.labels_
# 绘制结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
取的数据
最终结果















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









