







目录
1>理解线性回归
线性回归的概念:
通过特征的线性组合来描述目标变量。
线性回归的例子:
为了简化问题,我们仅考虑两个特征。假设想要使用两个特征(今天的股票价格和昨天的股票价格)来预测明天的股票价格,那么我们可以把今天的股票价格作为第一个特征,昨天的股票价格作为特征
。而线性回归的目标就是学习两个权重:
和
,这样就可以使用接下来的公式来预测明天的股票价格:
如果有M个特征值,可以把上面的公式扩展为M个特征的和,这样每个特征都有一个权重系数:
从几何角度来考虑这个公式,在只有一个特征的情况下,的公式为
,也就是一条直线。在有两个特征的情况下,
的公式为
,所描述的是特征空间的一个平面。
2>使用线性回归预测波士顿房价
为了方便理解,我们先设定训练数据的背景:
我们要构建一个波士顿房价数据集的模型,目标是预测20世纪70年代一些波士顿街区的房屋价值,使用的信息包括犯罪率、房产税率、到就业中心的距离和高速公路的可用性。
打开一个新的IPython会话:
ipython引入所有需要的模块:
import numpy as np
import cv2
from sklearn import datasets
from sklearn import metrics
from sklearn import model_selection
from sklearn import linear_model
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.rcParams.update({'font.size':16})载入数据集:
boston=datasets.load_boston()查看boston对象的结构:
dir(boston)
#结果:['DESCR', 'data', 'feature_names', 'filename', 'target']- DESCR:获得更多关于数据集的信息。
- data:包含所有的数据。
- feature_names:包含所有的特征名字。
- filename:包含该数据集的文件路径。
- target:包含所有的目标值(类别标签)。
数据集一共包括了506个数据点,每个数据点包括13个特征:
boston.data.shape
#结果:(506, 13)我们仅有一个目标值,也就是房价:
boston.target.shape
#结果:(506,)创建线性回归对象:
linreg=linear_model.LinearRegression()在前面的命令中,我们想要把数据分为训练数据集和测试数据集,这里使用test_size参数保留10%的数据用于测试:
X_train, X_test, y_train, y_test=model_selection.train_test_split(
boston.data, boston.target, test_size=0.1, random_state=42
)- X_train:这些特征将用于训练模型,我们已经指定test_size=0.1,这意味着其中90%的数据将用于训练or拟合模型。
- y_train:这些类别标签将用于训练模型,我们需要在训练or拟合模型时指定标签。
- X_test:这些特征将用于预测阶段,占所有特征数据的10%,这些特征将不会在训练阶段使用,而是用于预测,以测试模型的准确性。
- y_test:这些类别标签将用于预测阶段,以测试实际类别与预测类别之间的准确性。
- random_state:即随机数的种子,当该值相同时,同一代码得到的训练集数据也相同。
在scikit-learn中,train函数叫作fit,其他的操作和OpenCV中完全一样:
linreg.fit(X_train, y_train)
#结果:LinearRegression()通过计算真实房价y_train和预测结果linreg.predict(X_train)的差值,可以得到预测值的均方误差:
metrics.mean_squared_error(y_train, linreg.predict(X_train))
#结果:22.7375901544866linreg对象的score方法返回的是R方值:
linreg.score(X_train, y_train)
#结果:0.7375152736886281为了测试模型的泛化性能,在测试数据上计算均方误差:
y_pred=linreg.predict(X_test)
metrics.mean_squared_error(y_test, y_pred)
#结果:14.995852876582495画出对应的图可以更好地了解模型的真实能力:
%matplotlib
plt.figure(figsize=(10, 6))
plt.plot(y_test, linewidth=3, label='ground truth')
plt.plot(y_pred, linewidth=3, label='predicted')
plt.legend(loc='best')
plt.xlabel('test data points')
plt.ylabel('target value')
其中,真实的房价是由蓝色折线表示,预测的房价是由红色折线表示。
需要注意的一个情况是:模型在那些真实房价非常高或非常低的情况下误差最大,比如在数据点12、18和42的峰值位置。
可以形式化数据方差的数量,这样就能通过计算R方值来解释上面这个现象:
plt.figure(figsize=(10, 6))
plt.plot(y_test, y_pred, 'o')
plt.plot([-10, 60], [-10, 60], 'k--')
plt.axis([-10, 60, -10, 60])
plt.xlabel('ground truth')
plt.ylabel('predicted')
scorestr=r'R$^2$ = %.3f'%linreg.score(X_test, y_test)
errstr='MSE = %.3f'%metrics.mean_squared_error(y_test, y_pred)
plt.text(-5, 50, scorestr, fontsize=12)
plt.text(-5, 45, errstr, fontsize=12)
如果模型比较好,那么所有的数据点都应该在虚线表示的对角线上,因为y_pred总是和y_true相等。与对角线存在偏差表明模型的预测出现了一些误差或者数据中有一些方差是模型无法解释的。
3>应用Lasso回归和ridge回归
机器学习中常见的一个问题:
一个算法可能在训练数据集上非常有效,但在应用到未知数据上时却错误百出。这个现象也叫作过拟合,是指为了得到一致假设而使假设变得过度严格。
降低过拟合的一个常见方法叫作正则化,它通过在成本函数中添加一个独立于所有特征值之外的额外限制来避免过拟合,两个最常用的正则化项如下:
- L1正则化:该方法在评分函数上添加一个与所有权重绝对值之和成比例的元素,对应的算法叫作Lasso回归。
- L2正则化:该方法在评分函数上添加一个与所有权重平方和成比例的元素,对应的算法叫作ridge回归。
使用时需要替换下面的命令:
linreg=linear_model.LinearRegression()- 对于Lasso回归算法,使用下面的命令来替换上面那行代码:
lassoreg=linear_model.Lasso()- 对于ridge回归算法,使用下面的命令来替换上面那行代码:
ridgereg=linear_model.RidgeRegression()4>使用逻辑回归对鸢尾花种类进行分类
为了方便理解,我们先设定训练数据的背景:
机器学习世界中有一个有名的数据集叫作Iris数据集,它包括了来自三种不同品种的鸢尾花:山鸢尾、变色鸢尾和弗吉尼亚鸢尾。该数据集中共有150朵鸢尾花的测量数据,这些测量数据包括花萼的长度和宽度、花瓣的长度和宽度,所有数据的计量单位为厘米。
我们的目标是构建一个机器学习模型,它可以从这些已知品种的鸢尾花的测量数据中得到训练,这样就能对新鸢尾花进行品种分类。
理解逻辑回归:
逻辑回归实际上是用于目标为分类的模型。它使用一个逻辑函数(或者sigmoid函数)把任意输入的实值x转换为区间在0到1之间的一个预测值。
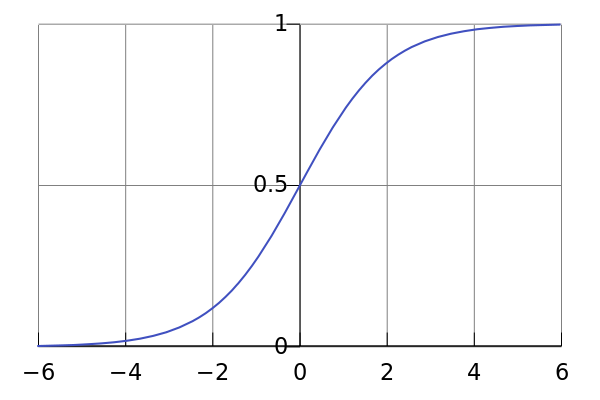
逻辑函数如上图所示,其中横轴为x,纵轴为,将
向最近的整数取整可以高效地把输入分类到属于0或者1的类别。
在大多数情况下,我们的问题拥有不止一个输入或者特征值。比如,Iris数据集一共提供了四个特征。为了简化这个问题,在此只关注前两个特征:花萼长度和花萼宽度
,于是我们可以把输入x作为两个特征
和
的线性组合来表示:
最后,这里需要逻辑函数来处理,把可能输出的数值压缩到范围[0, 1],即我们用来表示类别的数值(0或1):
载入所有必需的模块:
import numpy as np
import cv2
from sklearn import datasets
from sklearn import model_selection
from sklearn import metrics
import matplotlib.pyplot as plt
%matplotlib载入数据集:
iris=datasets.load_iris()查看iris对象的结构:
dir(iris)
'''
结果:
['DESCR',
'data',
'feature_names',
'filename',
'frame',
'target',
'target_names']
'''其中所有的数据都包含在data中,一共有150个数据点,每个数据点有4个特征值:
iris.data.shape
#结果:(150, 4)这四个特征对应前面所提到的花萼和花瓣的尺寸信息:
iris.feature_names
'''
结果:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
'''每个数据点都有一个类别标签存储在target中:
iris.target.shape
#结果:(150,)也可以看一下类别标签,发现一共有三个类别:
np.unique(iris.target)
#结果:array([0, 1, 2])为了简化的目的,我们现在只关注二分类问题,也就是只有两个类别。最简单的方式是忽略属于某个类别的所有数据点,比如通过选择不属于类别2的所有行来忽略类别标签2:
idx=iris.target!=2
data=iris.data[idx].astype(np.float32)
target=iris.target[idx].astype(np.float32)在开始设置一个模型前,最好先仔细观察一下数据,此处我们可以创建一个散点图,其中每个数据点的颜色对应其类别标签:
plt.figure(figsize=(10, 6))
plt.scatter(data[:, 0], data[:, 1], c=target, cmap=plt.cm.Paired, s=100)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1]);
由于之前说明过问题简化,所以此处仅使用Iris数据集的头两个特征:花萼长度(iris.feature_names[0])以及花萼宽度(iris.feature_names[1])。从上图来看,两个类别有着明显分离。
把数据分为训练集和测试集:
X_train, X_test, y_train, y_test=model_selection.train_test_split(
data, target, test_size=0.1, random_state=42
)查看返回的参数,确认获得90%的训练数据和10%的测试数据:
X_train.shape, y_train.shape
#结果:((90, 4), (90,))
X_test.shape, y_test.shape
#结果:((10, 4), (10,))创建一个逻辑回归分类器:
lr=cv2.ml.LogisticRegression_create()指定期望的训练方法,此处我们想要使用每个数据点后都更新一次模型:
lr.setTrainMethod(cv2.ml.LogisticRegression_MINI_BATCH)
lr.setMiniBatchSize(1)指定算法在结束之前的迭代次数:
lr.setIterations(100)调用对象的train方法:
lr.train(X_train, cv2.ml.ROW_SAMPLE, y_train)
#结果:True训练阶段的目标是找到一组可以最好地把特征值转换为输出标签的权重。一个单独的数据点由它的四个特征值组成,所以我们应该设置四个权重
,由此可以初步得到输入x的公式:
算法还需要添加一个额外的权重用于设置补偿或偏差,于是我们最终得到输入x的公式:
检索这些权重:
lr.get_learnt_thetas()
'''
结果:
array([[-0.04090133, -0.01910263, -0.16340333, 0.28743777, 0.11909772]],
dtype=float32)
'''计算分类器在训练数据集上的准确率:
et, y_pred=lr.predict(X_train)
metrics.accuracy_score(y_train, y_pred)
#结果:1.0完美的得分!然而,这个结果仅表明模型可以完美地记住训练数据集,并不意味着模型能够正确分类一个新的未知数据集。
计算分类器在测试数据集上的准确率:
ret, y_pred=lr.predict(X_test)
metrics.accuracy_score(y_test, y_pred)
#结果:1.0完美的得分!现在可以确定我们构建的模型确实非常完美。
















 1569
1569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











