







一、init命令介绍
在使用SwanLab记录模型实验时,我们首先需要通过swanlab.init()创建一个SwanLab实验,然后通过swanlab.log()将数据记录到当前的实验中,最后通过swanlab.finish()命令关闭当前的实验。
swanlab.init既是我们实验的创建命令,又决定了项目与实验的一系列初始设置,因此充分学习swanlab.init的用法是我们高效用好SwanLab的第一步。
二、init命令使用示例
在使用swanlab.init()时,我们通常会根据需求填入不同的参数信息,如项目名称,实验名称等。再向config参数传递一个包含超参数键值对的字典来存入超参数,
run = swanlab.init(
# 设置项目
project="my-project",
# 实验名称
experiment_name = "test"
# 实验描述
description = "MINIST手写体识别模型训练"
# 跟踪超参数与实验元数据
config={
"learning_rate": 0.01,
"epochs": 10,
},
)
三、init命令参数全解析
在以下内容中,我们将具体讲解init各个参数的具体作用:
project : str, 可选参数
当前实验的项目名称
默认为 None,表示当前项目名称与当前工作目录相同。
workspace : str, 可选参数
当前项目所在的位置
可以是组织或用户(目前仅支持自己)。默认为 None,表示当前项目归属于当前用户。
experiment_name : str, 可选参数
实验名称
如果没有提供此参数,SwanLab 将默认为您生成一个。
description : str, 可选参数
实验描述
用于对当前实验进行更详细的介绍或标注。如果不提供此参数,也可稍后在网页界面进行修改。
config : Union[dict, str],可选参数
实验的超参数信息,允许传入dict或者字符串
- 如果提供为
dict,将直接作为当前实验的配置。 - 如果提供为字符串,SwanLab将从文件中读取配置。并且配置文件必须是
json或yaml格式。无论如何,调用此函数后,可以稍后修改配置。
logdir : str,可选参数
实验日志信息的存放位置
SwanLab会生成一个文件夹存储实验执行过程中生成的所有日志信息,该参数主要用于管理日志信息的存放位置。
情况1:参数为None
如果参数为None,SwanLab将在代码执行的同一路径中生成一个名为“swanlog”的文件夹来存储数据
情况1可视化生成的日志文件,只需在代码执行的同一路径中运行命令swanlab watch即可(无需进入“swanlog”文件夹)。
情况2:参数为文件夹路径
该参数可以是自行指定的文件夹路径,但必须确保该文件夹存在,并且最好不包含除Swanlab生成的数据之外的任何内容。
这种情况下,如果要查看日志,必须使用命令 swanlab watch -l ./your_specified_folder
其中your_specified_folder 需要与你传入的参数一致。
suffix : str, 可选参数
实验名称的后缀,默认为 ‘default’。
如果此参数为 ‘default’,后缀将为 ‘%b%d-%h-%m-%s’(例如:‘Feb03_14-45-37’),代表当前时间。
例如:experiment_name = ‘example’, suffix = ‘default’ -> ‘example_Feb03_14-45-37’;
如果此参数为 None 或 False,则不会添加后缀。
如果此参数是字符串,后缀将是您提供的字符串。
注意:experiment_name + suffix 必须是唯一的,否则不会创建实验。
mode : str, 可选参数
实验数据的上传模式
允许的值为 ‘cloud’, ‘cloud-only’, ‘local’, ‘disabled’。
- 如果值为 ‘cloud’,则数据会上传到云端并保存本地日志。
- 如果值为 ‘cloud-only’,则数据只会上传到云端,不会保存本地日志。
- 如果值为 ‘local’,则数据只会保存本地,不会上传到云端。
- 如果值为 ‘disabled’,则不会保存或上传数据,只是解析数据。
load : str, 可选
实验配置文件的参数传递
如果传递此参数,SwanLab 会搜索您指定的配置文件(必须是 JSON 或 YAML 格式),并自动为您填充该函数的一些显式参数(不包括kwargs 中的参数和为 None 的参数)。
四、init命令效果展示
在接下来的部分,我们会提供一个可用的python脚本,并具体展示各个参数在可视化页面的效果。
import swanlab
import random
# 初始化一个新的swanlab run类来跟踪这个脚本
run = swanlab.init(
# 设置将记录此次运行的项目信息
project="init-tutorial-project",
# 实验名称
experiment_name = "init_test",
# 实验名称后缀
suffix = "20240621" ,
# 实验描述
description = "init功能解析与展示",
# 跟踪超参数和运行元数据
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10
}
)
# 模拟训练
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# 向swanlab上传训练指标
swanlab.log({"acc": acc, "loss": loss})
# [可选] 完成训练,这在notebook环境中是必要的
swanlab.finish()
-
项目名称效果展示
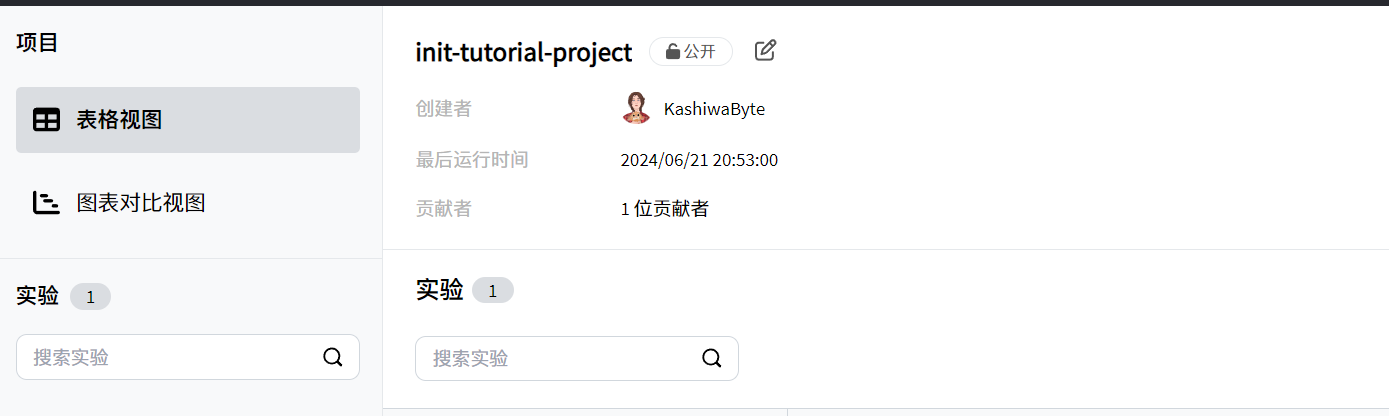
-
实验名称与实验后缀效果展示
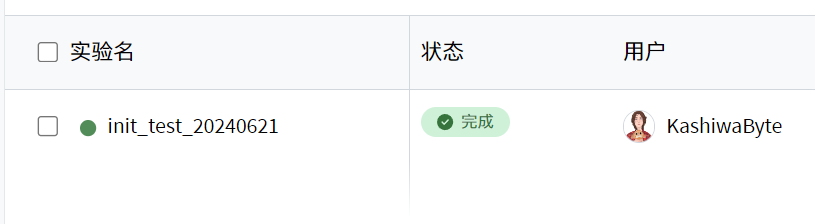
-
实验描述效果展示

-
实验超参数记录效果展示
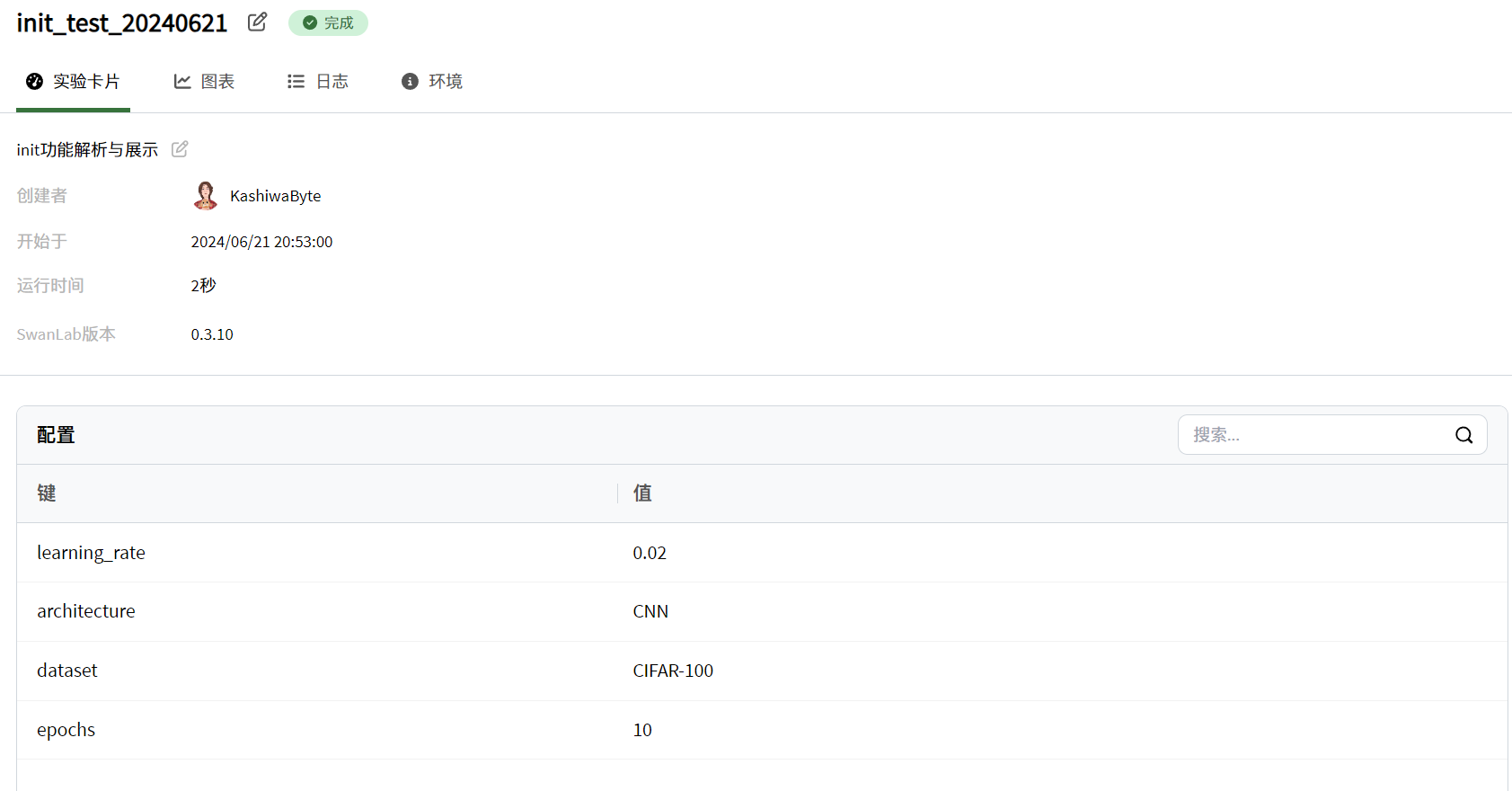
五、init命令小结
swanlab.init命令的用法其实非常简单,只需要仔细阅读以上教程,再多多实践,就可以轻松掌握。
如果有更多关于设置的需求与思考也欢迎在评论区留言,或者在我们的GitHub官方开源库提交issue,我们团队一定会全力满足用户的使用需求。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









