






Lab1 MapReduce
- 简介
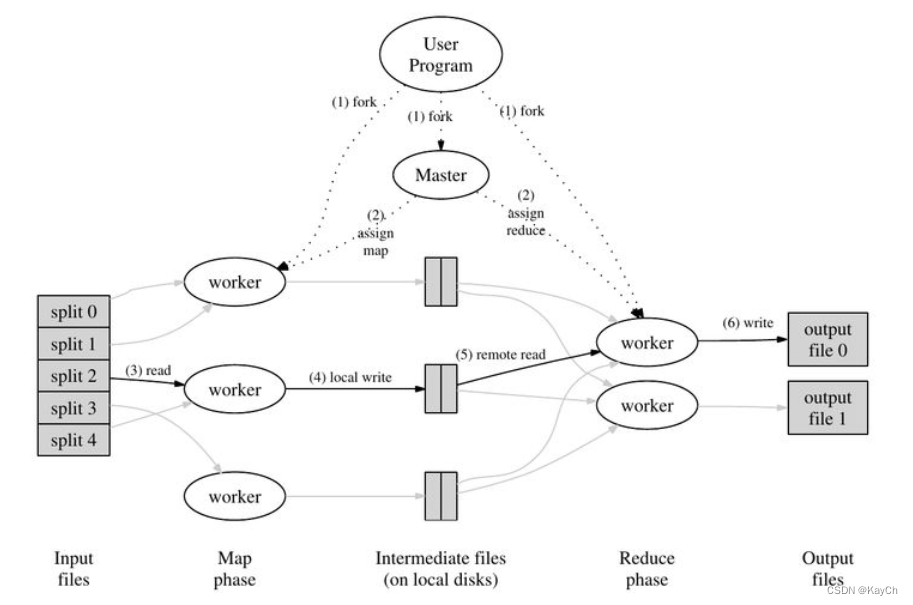
输入文件被分成M个数据片段,然后经过map阶段后得到许多的以键值对形式的中间文件,最后经过reduce阶段后得到最终结果。整个阶段由两类程序控制,其中一个是Master程序,其余是多个Worker程序,Master程序用于分配调度任务给各个Worker程序,Worker程序则执行map或reduce任务。
-
实验总览
实现一个基于MapReduce机制的单词计数,输入是在
src/main下的以pg-*.txt命名的文件,希望得到对这些文件所有出现的单词分别计数的结果的文件。执行过程要求先启动一个coordinator作为master导入输入文件,等待worker的请求。然后启动一个到多个的worker,这些worker需要载入对应的map函数和reduce函数,然后向coordinator请求任务,按照得到的任务类型分别执行map或者reduce -
实验流程
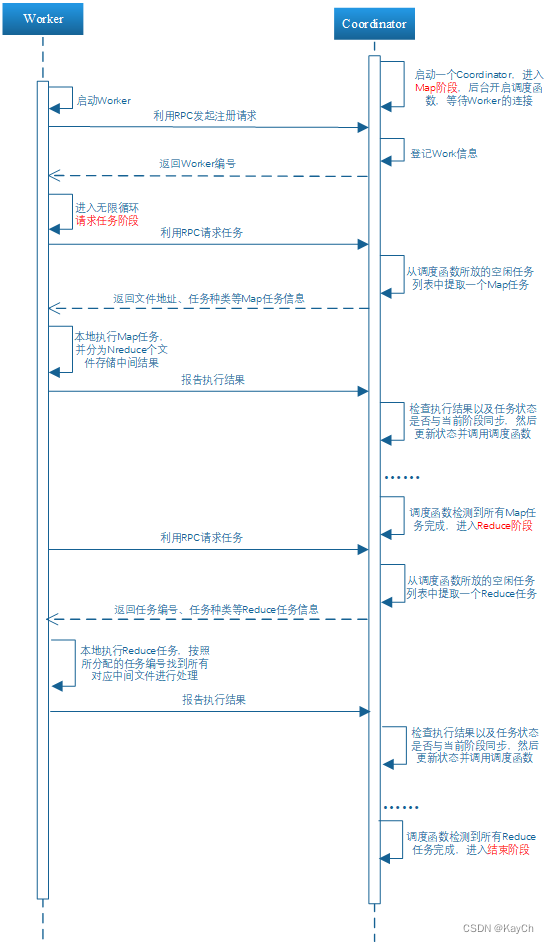
-
对象设计
本次实验主要的对象有Coordinator,Worker,Task。
- Coordinator作为调度程序,需要保存所有的任务和worker的信息,以及当前阶段。由于涉及到多进程相应多个worker,所以需要设置锁互斥改变当前Coordinator中的状态。
type TaskStat struct { Status int //任务状态 TaskReady|TaskWait|TaskRunning|TaskFinish|TaskErr WorkerId int //执行该任务的work标识 startTime time.Time //开始时间 } type Coordinator struct { // Your definitions here. files []string //文件名称 nReduce int //reduce任务数量 mu sync.Mutex //互斥锁(修改Coordinator的状态需要上锁) taskStats []TaskStat //标记所有任务的状态 taskPhase int //当前阶段 workerNum int //worker的数量 done bool //是否已经完成所有任务 taskCh chan Task //任务通道(用于发放待执行任务) }-
Worker
Worker作为执行任务的程序,需要保存自己的id和map以及reduce函数,便于编写代码传参时更加简洁。
type worker struct { id int //Coordinator分配的id mapf func(string, string) []KeyValue reducef func(string, []string) string }-
Task
Task代表了Coordinator分发给Worker的任务,用于Coordinator与worker交互。需要保存任务的编号,任务的类型,map和reduce的数量以及文件名。
const ( MapPhase = 0 reducePhase = 1 ) type Task struct { TaskSeq int //task的编号 FileName string //文件名 TaskPhase int //任务类型 mapPhase|reducePhase NMap int //map任务数量 NReduce int //reduce任务数量 } -
流程设计
- Coordinator启动
c := Coordinator{} c.files = files c.nReduce = nReduce c.mu = sync.Mutex{} //按照reduce任务和map任务数量最大值确定等待任务列表的长度 if len(files) > nReduce { c.taskCh = make(chan Task, len(files)) } else { c.taskCh = make(chan Task, nReduce) }- 进入Map阶段
func (c *Coordinator) initMap() { c.taskPhase = MapPhase c.taskStats = make([]TaskStat, len(c.files)) }- 周期性调用调度函数
func (c *Coordinator) timeSchedule() { for { if c.Done() { break } go c.schedule() time.Sleep(ScheduleInterval) } } func (c *Coordinator) schedule() { //执行调度函数会更新Coordinator的状态,所以需要加锁 c.mu.Lock() defer c.mu.Unlock() //调度前需要先检查整个任务是否完成 if c.done { return } //设置标记,表示当前所有任务是否全部完成 finish := true //遍历所有任务的状态,分类处理 for index, stat := range c.taskStats { switch stat.Status { case TaskReady: //准备阶段则放入任务通道 finish = false c.taskCh <- c.getTaskInfo(index) c.taskStats[index].Status = TaskWait case TaskWait: //等待阶段只需设计标记为否 finish = false case TaskRunning: //运行阶段需要检测是否超时,如果超时则重新设置为等待阶段 finish = false if time.Now().Sub(c.taskStats[index].startTime) > MaxWaitTime { c.taskCh <- c.getTaskInfo(index) c.taskStats[index].Status = TaskWait } case TaskFinish: //任务完成则无需操作 case TaskErr: //出错则重新设置为等待阶段 finish = false c.taskCh <- c.getTaskInfo(index) c.taskStats[index].Status = TaskWait default: panic("schedule err") } } //检测是否全部都完成 if finish { if c.taskPhase == MapPhase { //如果当前处于Map阶段则进入Reduce阶段 c.initReduce() } else { //如果当前处于Reduce阶段则进入结束阶段 c.done = true } } }- 建立Rpc服务器
func (c *Coordinator) server() { rpc.Register(c) rpc.HandleHTTP() //l, e := net.Listen("tcp", ":1234") sockname := coordinatorSock() os.Remove(sockname) l, e := net.Listen("unix", sockname) if e != nil { log.Fatal("listen error:", e) } go http.Serve(l, nil) }- Work启动
w := worker{} w.mapf = mapf w.reducef = reducef- 设置RPC请求的Call函数
func call(rpcname string, args interface{}, reply interface{}) bool { // c, err := rpc.DialHTTP("tcp", "127.0.0.1"+":1234") sockname := coordinatorSock() c, err := rpc.DialHTTP("unix", sockname) if err != nil { log.Fatal("dialing:", err) } defer c.Close() err = c.Call(rpcname, args, reply) if err == nil { return true } fmt.Println(err) return false }- Worker发起注册Rpc请求
func (w *worker) register() { args := RegisterArgs{} reply := RegisterReply{} ok := call("Coordinator.RegisterWorker", &args, &reply) if ok { w.id = reply.WorkerId } else { log.Fatal("register fail") } }- Coordinator注册worker的信息,并通过rpc返回
func (c *Coordinator) RegisterWorker(args *RegisterArgs, reply *RegisterReply) error { c.mu.Lock() defer c.mu.Unlock() c.workerNum += 1 reply.WorkerId = c.workerNum return nil }- Worker进入无限循环执行任务阶段
func (w *worker) run() { for { //通过RPC请求一个任务 task := w.getTask() //执行任务 w.workTask(task) } }- Worker请求任务
func (w *worker) getTask() Task { args := GetTaskArgs{} reply := GetTaskReply{} args.WorkerId = w.id ok := call("Coordinator.GetTask", &args, &reply) if !ok { //如果请求失败,直接退出 os.Exit(1) } return reply.Task }- Coordinator返回一个任务,并且更新Coordinator的状态
func (c *Coordinator) GetTask(args *GetTaskArgs, reply *GetTaskReply) error { task := <-c.taskCh //登记task c.RegisterTask(args, &task) reply.Task = task return nil } func (c *Coordinator) RegisterTask(args *GetTaskArgs, task *Task) { c.mu.Lock() defer c.mu.Unlock() if c.taskPhase != task.TaskPhase { panic("taskPhase err") } c.taskStats[task.TaskSeq].Status = TaskRunning c.taskStats[task.TaskSeq].WorkerId = args.WorkerId c.taskStats[task.TaskSeq].startTime = time.Now() }- Work根据任务类别选择不同方式处理
func (w *worker) workTask(task Task) { //根据任务类型进行分类处理 switch task.TaskPhase { case MapPhase: w.mapWork(task) case reducePhase: w.reduceWork(task) default: panic("taskPhase err") } }- 执行map任务
func (w *worker) mapWork(task Task) { //读取对应文件的内容 file, err := os.Open(task.FileName) if err != nil { w.repTask(task, false, err) } content, err := ioutil.ReadAll(file) if err != nil { w.repTask(task, false, err) } file.Close() //利用map函数对文件内容进行处理 kva := w.mapf(task.FileName, string(content)) //将map的结果分为nReduce份存储 reduceRes := make([][]KeyValue, task.NReduce) for _, kv := range kva { index := ihash(kv.Key) % task.NReduce reduceRes[index] = append(reduceRes[index], kv) } //将每份内容分别存储为一份中间文件 for index, content := range reduceRes { //建立中间文件的名称 filename := fmt.Sprintf("mr-%d%d", task.TaskSeq, index) f, err := os.Create(filename) if err != nil { w.repTask(task, false, err) } enc := json.NewEncoder(f) for _, kv := range content { err := enc.Encode(&kv) if err != nil { w.repTask(task, false, err) } } err = f.Close() if err != nil { w.repTask(task, false, err) } w.repTask(task, true, nil) } }- 执行reduce任务
func (w *worker) reduceWork(task Task) { //创建可以装入所有的键值对的maps maps := make(map[string][]string) //循环读取所有指定任务编号的中间文件 for i := 0; i < task.NMap; i++ { fileName := fmt.Sprintf("mr-%d%d", i, task.TaskSeq) file, err := os.Open(fileName) if err != nil { w.repTask(task, false, err) } dec := json.NewDecoder(file) for { //json反解码出文件 var kv KeyValue if err := dec.Decode(&kv); err != nil { break } if _, ok := maps[kv.Key]; !ok { maps[kv.Key] = make([]string, 0, 100) } //将解码结果放进对应key的数组中 maps[kv.Key] = append(maps[kv.Key], kv.Value) } } //将map的结果利用reduce函数进行处理 res := make([]string, 0, 100) //准备写入的结果 for k, v := range maps { res = append(res, fmt.Sprintf("%v %v\n", k, w.reducef(k, v))) } resName := fmt.Sprintf("mr-out-%d", task.TaskSeq) //将结果写入文件 if err := ioutil.WriteFile(resName, []byte(strings.Join(res, "")), 0600); err != nil { w.repTask(task, false, err) } w.repTask(task, true, nil) }














 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









