






文章目录
1.图的逻辑结构和具体实现
1.1.逻辑结构
什么叫「逻辑结构」?就是说为了方便研究,把图抽象成一个样子。一幅图是由节点和边构成的,逻辑结构如下:

1.2.实现
上面的这种实现是「逻辑上的」,实际上我们很少用这个 Vertex 类实现图,而是用常说的邻接表和邻接矩阵来实现。
邻接表的优点是占用的空间少,缺点是无法快速判断两个节点是否相邻。在常规的算法题中,邻接表的使用会更频繁一些,主要是因为操作起来较为简单,但这不意味着邻接矩阵应该被轻视。矩阵是一个强有力的数学工具,图的一些隐晦性质可以借助精妙的矩阵运算展现出来。
1.2.1.有向无权图
对于有向无权图,邻接表很直观,我把每个节点 x 的邻居都存到一个列表里,然后把 x 和这个列表关联起来,这样就可以通过一个节点 x 【下标x】找到它的所有相邻节点。
邻接矩阵则是一个二维布尔数组,我们权且称为 matrix,如果节点 x 和 y【】下标x,y 是相连的,那么就把 matrix[x][y] 设为 true(上图中绿色的方格代表 true)。如果想找节点 x 的邻居,去扫一圈 matrix[x][…] 就行了。如下图:

如果用代码的形式来表现,邻接表和邻接矩阵大概长这样:
# 邻接表
# graph[x] 存储 x 的所有邻居节点
graph: List[List[int]]
# 邻接矩阵 # matrix[x][y] 记录 x 是否有一条指向 y 的边
matrix: List[List[bool]]
1.2.2.有向加权图
如果是有向加权图,对于邻接表,不仅仅存储某个节点 x 的所有邻居节点,还存储 x 到每个邻居的权重。对于邻接矩阵,matrix[x][y] 不再是布尔值,而是一个 int 值,0 表示没有连接,其他值表示权重。如果用代码的形式来表现,大概长这样:
# 邻接表 # graph[x] 存储 x 的所有邻居节点以及对应的权重
graph: List[List[int, int]]
# 邻接矩阵 # matrix[x][y] 记录 x 指向 y 的边的权重,0 表示不相邻
matrix: List[List[int]]
1.2.3.无向图
无向 = 双向
如果连接无向图中的节点 x 和 y,把 matrix[x][y] 和 matrix[y][x] 都变成 true 就行了;邻接表也是类似的操作,在 x 的邻居列表里添加 y,同时在 y 的邻居列表里添加 x。 把上面的技巧合起来,就变成了无向加权图。
2.基本概念
2.1.度
- 在无向图中,「度」就是每个节点相连的边的条数。
- 在有向图中,由于边有方向,所以有向图中每个节点「度」被细分为入度(indegree)和出度(outdegree) 。对于节点node,有x条边指向它,它的入度为x;它有y条边指向别的节点,它的出度为y。
3.图的遍历
先看多叉树的遍历:
# 多叉树遍历框架 DFS(preOrder,postOrder)
def traverse(root):
if root is None:
return []
# 前序位置
for child in root.children:
traverse(child)
# 后序位置
# 多叉树的层序遍历BFS
from collections import deque
class Node:
def __init__(self, val=None, children=None):
self.val = val
self.children = children
def levelOrder(self, root):
if not root:
return []
res = []
queue = deque([root])
while queue:
level = []
for _ in range(len(queue)):
node = queue.popleft()
level.append(node.val)
queue.extend(node.children or [])
res.append(level)
return res
图和多叉树最大的区别是,图是可能包含环的,而树不可能有环。
如果图可能包含环,遍历框架就要一个 visited 数组进行辅助,防止递归重复遍历同一个节点进入死循环的。在图的遍历过程中,onPath 用于判断是否成环。类比贪吃蛇游戏,visited 记录蛇经过过的格子,而 onPath 仅仅记录蛇身。
图DFS:1.从图中任选一个顶点作为起点,访问这个起点。2.对于当前未访问过的相邻结点,依次递归访问。
图BFS:1.从图中任选一个顶点作为起点,将起点入队。2.从队头取出一个结点,访问它。3.遍历该结点的所有相邻结点,将未访问过的结点入队。4.重复执行步骤 2 和步骤 3,直到队列为空。
下面是 Python 中实现图的遍历框架的代码示例,其中 graph 是用字典表示的图,键是顶点,值是与该顶点相邻的结点列表。
# 图的遍历 DFS
visited = [] # 记录被遍历过的节点
onPath = [] # 记录从起点到当前节点的路径
""" 图遍历框架 """ DFS
def traverse(graph, s):
if visited[s]:
return []
# 经过节点 s,标记为已遍历,# 防止走回头路进入死循环
visited[s] = True
# 做选择:标记节点 s 在路径上
onPath[s] = True
for neighbor in graph.neighbors(s):
traverse(graph, neighbor)
# 撤销选择:节点 s 离开路径
onPath[s] = False
#BFS遍历图
from collections import deque
def bfs(graph, start):
visited, queue = set(), deque([start]) # visited记录被遍历过的节点,把start放进queue
visited.add(start)
while queue:
vertex = queue.popleft() # 取出queue第一个元素
for next in graph[vertex]:
if next not in visited:
visited.add(next)
queue.append(next)
return visited
onPath 数组的操作很像前文 回溯算法核心套路 中做「做选择」和「撤销选择」,区别在于位置:回溯算法的「做选择」和「撤销选择」在 for 循环里面,而对 onPath 数组的操作在 for 循环外面。
为什么有这个区别呢?这就是前文 回溯算法核心套路 中讲到的回溯算法和 DFS 算法的区别所在:回溯算法关注的不是节点,而是树枝。不信你看前文画的回溯树,我们需要在「树枝」上做选择和撤销选择:
对于这里「图」的遍历,我们应该用 DFS 算法,即把 onPath 的操作放到 for 循环外面,否则会漏掉记录起始点的遍历。
# DFS 算法,关注点在节点
def traverse(root: TreeNode):
if root is None:
return
print("进入节点", root)
for child in root.children:
traverse(child)
print("离开节点", root)
# 回溯算法,关注点在树枝
def backtrack(root: TreeNode):
if root is None:
return
for child in root.children:
# 做选择
print("从", root, "到", child)
backtrack(child)
# 撤销选择
print("从", child, "到", root)
4.有向图的环检测
4.1.DFS 算法利用 path 数组判断是否存在环
看到依赖问题,就把问题转化成「有向图」这种数据结构,只要图中存在环,那就说明存在循环依赖。因此我们要把题目的输入转化成一幅有向图,然后再判断图中是否存在环。
首先如何转换成图呢?我们前文 图论基础写过图的两种存储形式,邻接矩阵和邻接表 常见的存储方式是使用邻接表
其次如何判断这幅图中是否存在环,遍历一遍就可以知道啦。
#数据以课程表为例
class Solution:
def hasCycle(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# 建图函数:
def buildGraph(numCourses: int, prerequisites: List[List[int]]) -> List[List[int]]:
graph = [[] for _ in range(numCourses)] # 图中共有 numCourses 个节点
for edge in prerequisites:
from_, to_ = edge[1], edge[0]
graph[from_].append(to_) # 添加一条从 from 指向 to 的有向边,边的方向是「被依赖」关系,即修完课程 from 才能修课程 to
return graph
#遍历
def dfs(graph, node, visited, path):
path.add(node) # 将当前结点添加到 DFS 路径中
visited.add(node) # 标记当前结点为已访问
for neighbor in graph[node]: # 遍历当前结点的所有相邻结点
if neighbor in path: # 相邻结点已经在路径中,则产生了环,返回 True
return True
elif neighbor not in visited: # 相邻结点未被访问过,则递归访问相邻结点
if dfs(graph, neighbor, visited, path):
return True
path.remove(node) # 在完成 DFS 后,需要将当前结点从 DFS 路径中删除
return False # 不存在环,返回 False
visited = set() # 定义一个集合,用于保存被访问过的结点
graph = buildGraph(numCourses, prerequisites)
for node in graph: # 遍历图中的每个结点,进行 DFS
if node not in visited:
if dfs(graph, node, visited, set()): # 存在环
return True
return False # 不存在环
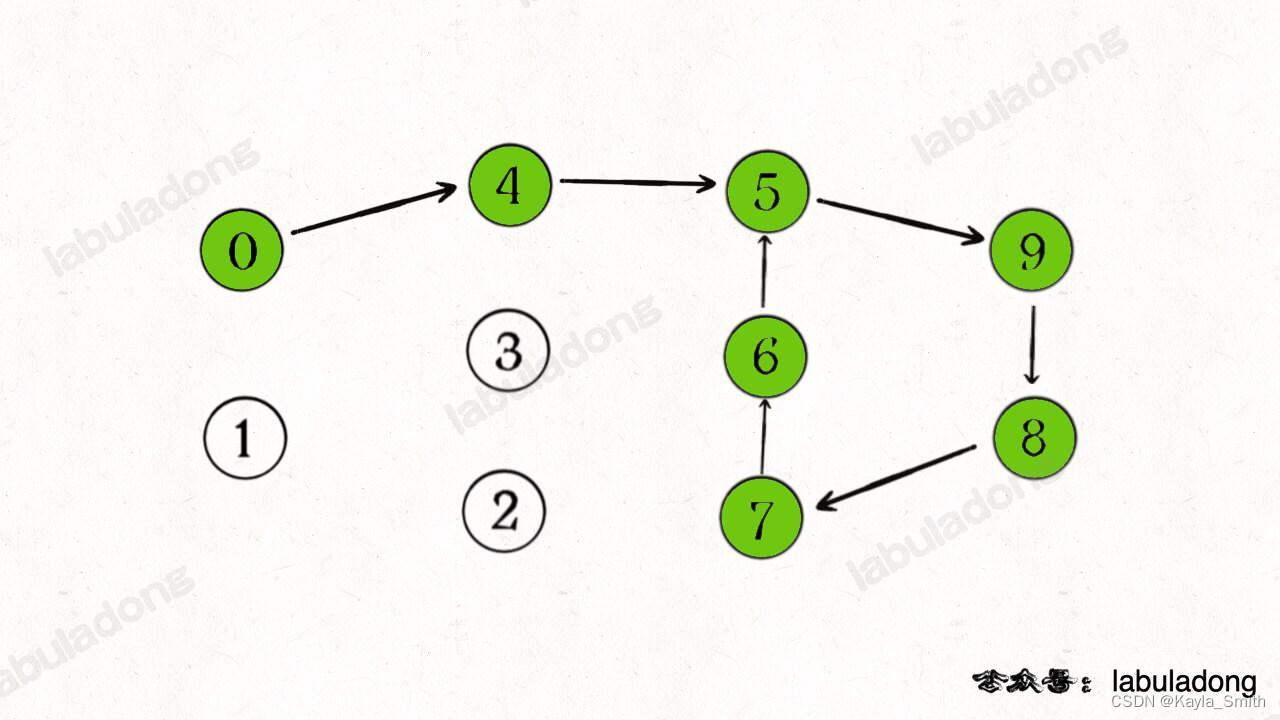
如果不仅要判断是否存在环,还要返回这个环具体有哪些节点,怎么办?
注意,假设下图中绿色的节点是递归的路径,它们在 path 中的值都是 true,但显然成环的节点只是其中的一部分:
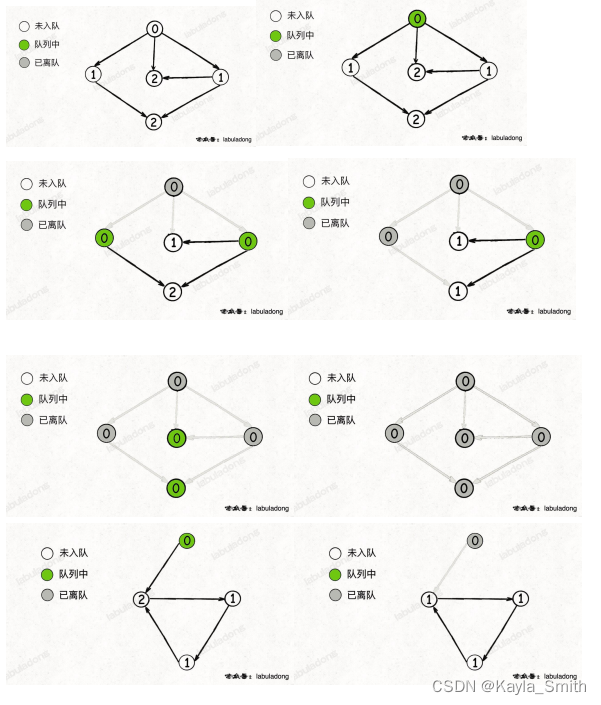
4.2.利用BFS 算法借助 indegree 数组记录每个节点的「入度」实现环检测算法
总结下这段 BFS 算法的思路:
1、构建邻接表,和之前一样,边的方向表示「被依赖」关系。
2、构建一个 indegree 数组记录每个节点的入度,即 indegree[i] 记录节点 i 的入度。
3、对 BFS 队列进行初始化,将入度为 0 的节点首先装入队列。
4、开始执行 BFS 循环,不断弹出队列中的节点,减少相邻节点的入度,并将入度变为 0 的节点加入队列。
5、如果最终所有节点都被遍历过(count 等于节点数),则说明不存在环,反之则说明存在环。
# BFS
def hasCycle(graph): # 建图如前
indegrees = {v: 0 for v in graph} # 统计各个顶点的入度
for node in graph:
for neighbor in graph[node]:
indegrees[neighbor] += 1
queue = [node for node in indegrees if indegrees[node] == 0] # 将入度为 0 的顶点放入队列中
visited = set(queue)
while queue:
node = queue.pop(0)
for neighbor in graph[node]:
if neighbor in visited:
# 出现环
return True
indegrees[neighbor] -= 1
5.拓扑排序算法
5.1.拓扑排序 Topological sorting
有向图的拓扑排序或拓扑测序是对其顶点的一种线性排序,使得对于从顶点u 到顶点v的每个有向边uv,u在排序中都在v之前。
例如,图形的顶点可以表示要执行的任务,并且边可以表示一个任务必须在另一个任务之前执行的约束;在这个应用中,拓扑排序只是一个有效的任务顺序。
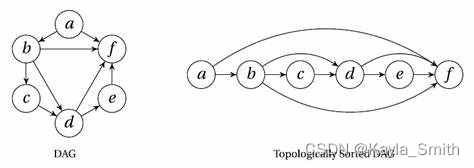
什么样的图才能拓扑排序:
- 当且仅当图中没有定向环时(即有向无环图),才有可能进行拓扑排序。
- 任何有向无环图至少有一个拓扑排序。已知有算法可以在线性时间内,构建任何有向无环图的拓扑排序。
在图论中,由一个有向无环图的顶点组成的序列,当且仅当满足下列条件时,才能称为该图的一个拓扑排序:
- 序列中包含每个顶点,且每个顶点只出现一次;
- 若A在序列中排在B的前面,则在图中不存在从B到A的路径。
5.2.如何进行拓扑排序
5.2.1.DFS 算法,后序遍历的结果(进行反转),就是拓扑排序的结果
建图的时候对边的定义决定反不反转。
如果箭头方向是「被依赖」关系,比如节点 1 指向 2,含义是节点 1 被节点 2 依赖,即做完 1 才能去做 2,就需要反转。反之则不用。
代码就是在环检测的代码基础上添加了记录后序遍历结果:
class Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
postorder = [] # 记录后序遍历结果
hasCycle = [False] # 记录是否存在环
visited = [False] * numCourses
onPath = [False] * numCourses
# 建图函数
def buildGraph(numCourses, prerequisites):
# 代码见前文
pass
# 图遍历函数
def traverse(graph, s):
if onPath[s]: # 发现环
hasCycle[0] = True
if visited[s] or hasCycle[0]:
return
# 前序遍历位置
onPath[s] = True
visited[s] = True
for t in graph[s]:
traverse(graph, t)
# 后序遍历位置
postorder.append(s)
onPath[s] = False
graph = buildGraph(numCourses, prerequisites)
# 遍历图
for i in range(numCourses):
traverse(graph, i)
# 有环图无法进行拓扑排序
if hasCycle[0]:
return []
# 逆后序遍历结果即为拓扑排序结果
# postorder.reverse()
# res = []
# for i in postorder:
# res.append(i)
# return res
return postorder[::-1]
5.2.2.BFS算法,节点的层序遍历顺序就是拓扑排序的结果。
统计每个顶点的入度。使用一个列表 indegree 统计图中每个顶点的入度,即有多少个顶点指向该顶点。
将所有入度为 0 的顶点入队。将所有入度为 0 的顶点加入队列 queue 中,作为拓扑排序的起点。
对队列中的每个顶点进行 BFS。从队列头开始取出每个顶点 u,并将其加入结果列表 res 中。接下来,遍历顶点 u 的相邻顶点 v,将它们的入度减 1。如果相邻顶点 v 的入度为 0,就将其加入队列中,表示它们的前驱都已经被访问完了。
如果最终访问的顶点数不足 n 个,说明图中存在环。如果最终访问的顶点数等于图中顶点的个数 n,说明图中没有环,返回结果列表 res。否则,说明图中存在环,返回空列表。
from collections import deque
def topo_sort_bfs(graph):
# 统计每个顶点的入度
indegree = [0] * len(graph)
for u in graph:
for v in graph[u]:
indegree[v] += 1
# 将所有入度为 0 的顶点入队
queue = deque([u for u in range(len(graph)) if indegree[u] == 0])
# 对队列中的每个顶点进行 BFS
res = []
while queue:
u = queue.popleft()
res.append(u)
# 遍历 u 的相邻顶点 v,将 v 的入度减 1
for v in graph[u]:
indegree[v] -= 1
# 如果 v 的入度为 0,则将其入队
if indegree[v] == 0:
queue.append(v)
# 如果最终访问的顶点数不足 n 个,说明图中存在环
return res if len(res) == len(graph) else []
6.二分图【一种特殊图】
6.1定义和用处
二分图的顶点可以分成两个互斥的独立集 U 和 V 的图,使得所有边都是连结一个 U 中的点和一个 V 中的点。
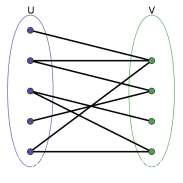
可以将 U 和 V 当做一个着色:U 中所有顶点为蓝色,V 中所有顶点着绿色,每条边的两个端点的颜色不同。将其中一个顶点着蓝色并且另外一个着绿色后,第三个顶点与上述具有两个颜色的顶点相连,无法再对它着蓝色或绿色,则不是二分图。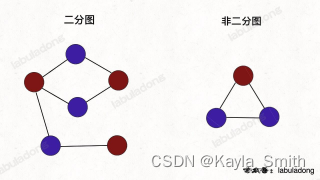
用处:二分图经常出用来研究两种不同类型的物件之间的关系。
比如说我们需要一种数据结构来储存电影和演员之间的关系: 既然是存储映射关系,可以使用哈希表来存储电影到演员列表的映射,如果给一部电影的名字,就能快速得到出演该电影的演员。但是如果给出一个演员的名字,我们想快速得到该演员演出的所有电影,怎么办呢?这就需要「反向索引」,对之前的哈希表进行一些操作,新建另一个哈希表,把演员作为键,把电影列表作为值。
显然,如果用哈希表存储,需要两个哈希表分别存储「每个演员到电影列表」的映射和「每部电影到演员列表」的映射。但如果用「图」结构存储,将电影和参演的演员连接,很自然地就成为了一幅二分图:
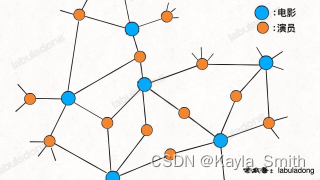
每个电影节点的相邻节点就是参演该电影的所有演员,每个演员的相邻节点就是该演员参演过的所有电影,非常方便直观。
6.2二分图判定
遍历一遍图,一边遍历一边染色,看看能不能用两种颜色给所有节点染色,且相邻节点的颜色都不相同。
既然说到遍历图,也不涉及最短路径之类的,当然是 DFS 算法和 BFS 皆可了,DFS 算法相对更常用些
# 判定二分图代码框架
def traverse(graph, visited, v):
visited[v] = True
# 遍历节点 v 的所有相邻节点 neighbor
for neighbor in graph.neighbors(v):
if not visited[neighbor]:
# 相邻节点 neighbor 没有被访问过
# 那么应该给节点 neighbor 涂上和节点 v 不同的颜色
traverse(graph, visited, neighbor)
else:
# 相邻节点 neighbor 已经被访问过
# 那么应该比较节点 neighbor 和节点 v 的颜色
7.并查集(UNION-FIND)
7.1.基本概念
并即合并union,查即查找find,集即集合。并查集(Union-Find)是一种数据结构,用于维护一个集合的划分,并支持两个操作:
- Find(x):查找元素 x 所在的集合的根节点。在查找根节点的同时,可以执行路径压缩,即将元素 x 到根节点路径上的所有结点的父节点直接指向根节点,从而减少下一次查找的深度。
- Union(a, b):将元素 a 所在的集合和元素 b所在的集合合并。
还可以增加isConnected(m,n)判断节点m和n是否直接或间接连接,即在同一个集合(连通区域);count():返回集合(连通分量、连通区域)的个数等。
Union-Find 通常用于解决图论中的连通性问题。动态连通性其实可以抽象成给一幅图连线 这里所说的「连通」是一种等价关系,也就是说具有如下三个性质:
1、自反性:节点 p 和 p 是连通的。
2、对称性:如果节点 p 和 q 连通,那么 q 和 p 也连通。
3、传递性:如果节点 p 和 q 连通,q 和 r 连通,那么 p 和 r 也连通。
一些使用 DFS 深度优先算法解决的问题,也可以用 Union-Find 算法解决。
7.2.实现UNION-FIND算法
Union-Find 的实现方式有多种,最常用的是基于树的实现方式,其中每个集合被表示为一棵树,其中每个结点指向其父节点,根结点指向自己。通过路径压缩和按秩合并等优化方式,Union-Find 的时间复杂度可以达到近乎常数级别。其时间复杂度为 O(α(n)),其中 α(n) 是阿克曼函数的反函数,可以认为是一个非常小的常数。
并查集的实现步骤如下:
- 初始化,每个节点的父亲节点都是自己。
- 查找某个节点所在的集合,即找到该节点的根节点。
- 合并两个节点所在的集合,即将其中一个节点的根节点指向另一个节点的根节点。
并查集UNION-FIND框架如下:
class UnionFind:
def __init__(self, n):
self.parent = list(range(n)) # 记录每个节点的根节点 self.parent = [i for i in range(n)]
self.count = n # 集合/连通分量的个数
def find(self, x): # 查找根节点,并进行路径压缩
if x != self.parent[x]:
self.parent[x] = self.find(self.parent[x]) # 如果 parent[x] 不等于 x,即 x 不是根节点,就递归调用 find(parent[x]),寻找 parent[x] 的根节点,并将其更新为 x 的根节点,这里采用了路径压缩的技巧
return self.parent[x]
def union(self, x, y):
root_x, root_y = self.find(x), self.find(y) # 找到 x 和 y 的根节点
if root_x == root_y:
return False
self.parent[root_x] = root_y # 两个连通分量合并成一个连通分量
self.count -= 1
#可有可无
def isConnected(self, p: int, q: int) -> bool: # 判断节点 p 和节点 q 是否连通
rootP = self.find(p)
rootQ = self.find(q)
return rootP == rootQ
def count(self) -> int: # 返回图中的连通分量个数
return self.count
# ACM模式下
# 输入获取
nums = input().split()
colors = input().split()
# 并查集
class UnionFindSet:
def __init__(self, n):
self.fa = [idx for idx in range(n)]
self.count = n
def find(self, x):
if x != self.fa[x]:
self.fa[x] = self.find(self.fa[x])
return self.fa[x]
return x
def union(self, x, y):
x_fa = self.find(x)
y_fa = self.find(y)
if x_fa != y_fa:
self.fa[y_fa] = x_fa
self.count -= 1
# 算法入口
def getResult():
n = len(nums)
ufs = UnionFindSet(n)
for i in range(n):
for j in range(i+1, n):
if nums[i] == nums[j] or colors[i] == colors[j]:
ufs.union(i, j)
count = {}
for i in range(n):
f = ufs.find(i)
count[f] = count.get(f, 0) + 1
return max(count.values())
# 算法调用
print(getResult())
8.最小生成树【KRUSKAL(克鲁斯卡尔算法)算法、PRIM(普里姆)算法】
8.1.最小生成树
「树」和「图」的根本区别:树不会包含环,图可以包含环。 这意味着如果一幅图没有环,完全可以拉伸成一棵树的模样。即树就是「无环连通图」。
什么是图的「生成树」?就是在图中找一棵包含图中的所有节点的树。即树是含有图中所有顶点的「无环连通子图」。 一幅图可以有很多不同的生成树。对于加权图,每条边都有权重,所以每棵生成树都有一个权重和,那么在所有可能的生成树中,权重和最小的那棵生成树就叫「最小生成树」。如下图:
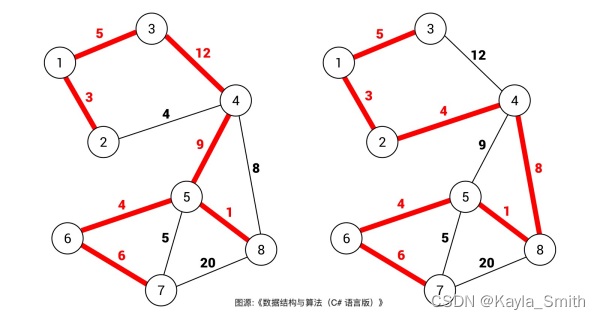
一般来说,我们都是在无向加权图中计算最小生成树的,所以使用最小生成树算法的现实场景中,图的边权重一般代表成本、距离这样的标量。
8.2.Kruskal算法
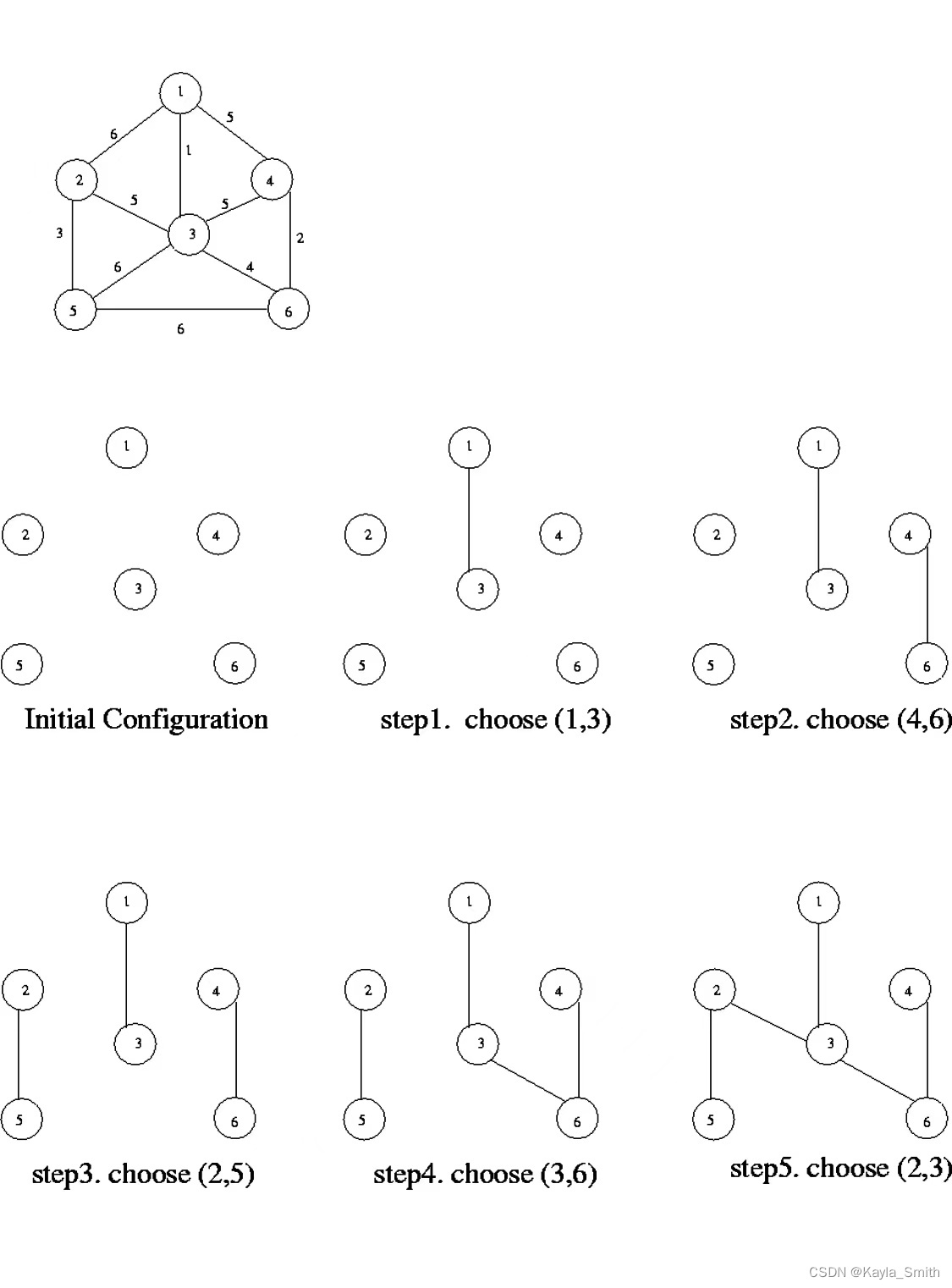
所谓最小生成树(Minimum Spanning Treemst (MST)),就是图中若干边的集合,要保证这些边:
1、包含图中的所有节点
2、形成的结构是树结构(即不存在环)。
3、权重和最小。
第1、2条是指要形成无环连通子图,对于连通性,应该可以想到 Union-Find 并查集算法,用来高效处理图中联通分量的问题。Union-Find 在 Kruskal 算法中的主要作用是保证最小生成树的合法性,即确保生成的是不一棵树【不含环】。
对于一棵树,什么情况下加入一条边会使得树变成图(出现环)?
对于添加的这条边,如果该边的两个节点本来就在同一连通分量里,那么添加这条边会产生环;反之,如果该边的两个节点不在同一连通分量里,则添加这条边不会产生环。
而判断两个节点是否连通(是否在同一个连通分量中)就是 Union-Find 算法的用处所在。
第 3 点,如何保证得到的这棵生成树是权重和最小的。
这里就用到了贪心思路:将所有边按照权重从小到大排序,从权重最小的边开始遍历,如果这条边和mst中的其它边不会形成环,则这条边是最小生成树的一部分,将它加入mst集合;否则,这条边不是最小生成树的一部分,不要把它加入mst集合。 这样,最后mst集合中的边就形成了最小生成树
主要的难点是利用 Union-Find 并查集算法向最小生成树中添加边,配合排序的贪心思路,从而得到一棵权重之和最小的生成树。
Kruskal算法框架如下:
from typing import List, Tuple
class KruskalMST:
def __init__(self, vertices: int, edges: List[Tuple[int, int, int]]):
"""
:param vertices: 顶点数量
:param edges: 边的列表,每个元素是一个三元组 (u, v, w),表示一条边 (u, v) 权值为 w
"""
self.vertices = vertices
self.edges = edges
self.parent = [i for i in range(vertices)] # 初始化每个顶点的祖先为自己
def find(self, x: int) -> int:
# 查找根节点,并进行路径压缩
if x != self.parent[x]:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x: int, y: int) -> None:
# 将 x 和 y 所在的集合合并
root_x, root_y = self.find(x), self.find(y)
if root_x != root_y:
self.parent[root_x] = root_y
def kruskal(self) -> List[Tuple[int, int, int]]:
# 执行 Kruskal 算法,返回最小生成树上的边的列表,每个元素是一个三元组 (u, v, w),表示一条边 (u, v) 权值为 w
self.edges.sort(key=lambda x: x[2]) # 按照边的权值从小到大排序
result = []
for edge in self.edges:
u, v, w = edge
if self.find(u) != self.find(v):
result.append(edge)
self.union(u, v)
return result
8.3.PRIM算法
Kruskal使用了UNION-FIND和贪心思想,而PRIM也使用贪心思想来让生成树的权重尽可能小,但不需要事先对所有边排序,而是利用优先级队列动态实现排序的效果,也就是「切分定理」,然后使用 BFS 算法思想 和 visited 布尔数组避免成环。
8.3.1.切分定理
「切分」就是将一幅图分为两个不重叠且非空的节点集合。如下图,红色的这一刀把图中的节点分成了两个集合,就是一种「切分」,其中被红线切中的的边(标记为蓝色)叫做「横切边」
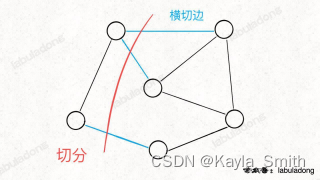
「切分定理」:对于任意一种「切分」,其中权重最小的那条「横切边」一定是构成最小生成树的一条边。
因为如果那条边不是权重最小的,说明这棵树还有降权重的空间,就不是最小生成树。
依此,最小生成树的算法思路:每一次「切分」一定可以找到最小生成树中的一条边,那每次都把权重最小的「横切边」拿出来加入最小生成树,直到把构成最小生成树的所有边都切出来为止。可以说这就是 Prim 算法的核心思路。
首先随便选一个点,假设就从 A 点开始切分按照切分定理,这些「横切边」AB, AF 中权重最小的边一定是最小生成树中的一条边,现在已经找到最小生成树的第一条边(边 AB),接下来可以围绕 A 和 B 这两个节点做切分,又可以从这个切分产生的横切边(图中蓝色的边)中找出权重最小的一条边,也就又找到了最小生成树中的第二条边 BC,再围绕着 A, B, C 这三个点做切分,产生的横切边中权重最小的边是 BD,那么 BD 就是最小生成树的第三条边,
接下来再围绕 A, B, C, D 这四个点做切分……
Prim 算法的逻辑就是这样,每次切分都能找到最小生成树的一条边,然后又可以进行新一轮切分,直到找到最小生成树的所有边为止。
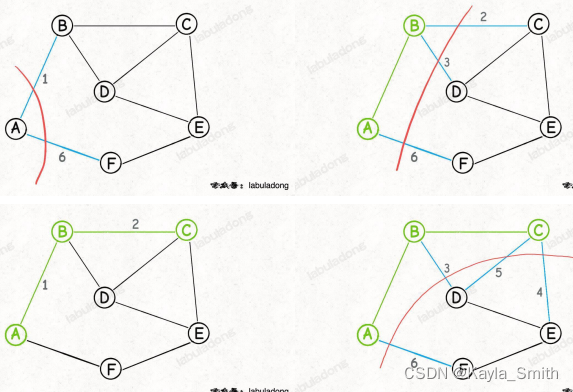
这样设计算法有一个好处,就是比较容易确定每次新的「切分」所产生的「横切边」。
当我知道了节点 A, B 的所有「横切边」(不妨表示为 cut({A, B})) 是否可以快速算出 cut({A, B, C}),也就是节点 A, B, C 的所有「横切边」有哪些? 是可以的,因为我们发现:其中cut({C}) 就是节点 C 的所有邻边:
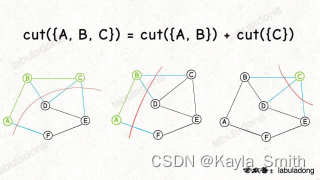
这个特点使我们用我们写代码实现「切分」和处理「横切边」成为可能:
在进行切分的过程中,我们只要不断把新节点的邻边加入横切边集合,就可以得到新的切分的所有横切边。
但是,cut({A, B}) 的横切边和 cut({C}) 的横切边中 BC 边重复了。
不过这很好处理,用一个布尔数组 inMST 辅助,防止重复计算横切边就行了。
最后一个问题,我们求横切边的目的是找权重最小的横切边,怎么做到呢?
很简单,用一个优先级队列存储这些横切边,就可以动态计算权重最小的横切边了。
import heapq
from typing import List, Tuple
class PrimMST:
def __init__(self, vertices: int, graph: List[List[Tuple[int, int]]]):
"""
:param vertices: 顶点的数量
:param graph: 图的邻接矩阵,每个元素是一个列表,表示与该顶点相关联的边的信息,如 [(v1, w1), (v2, w2), ...]
"""
self.vertices = vertices
self.graph = graph
def prim(self) -> List[Tuple[int, int, int]]:
"""
执行 Prim 算法,返回最小生成树上的边的列表,每个元素是一个三元组 (u, v, w),表示一条边 (u, v) 权值为 w
"""
heap = [(0, 0, 0)] # 建立一个堆,用于存放待处理的边,初值为 (0, 0, 0),表示从第一个顶点开始
visited = [False] * self.vertices # 标记每个顶点是否已经被访问过
result = []
while len(result) < self.vertices - 1: # 直到找到 n-1 条边为止
cost, u, v = heapq.heappop(heap) # 取出堆顶元素,堆中元素为 (权值, 起点, 终点)
if visited[v]: # 如果已经访问过了,就跳过
continue
visited[v] = True # 标记为已访问
result.append((u, v, cost)) # 加入到最小生成树的边集中
for next_v, weight in self.graph[v]: # 遍历 v 的所有邻接点,将 (v, next_v, weight) 加入堆中
if not visited[next_v]:
heapq.heappush(heap, (weight, v, next_v))
return result
再回顾一下 Prim 算法和 Kruskal 算法 的联系:
Kruskal 算法是在一开始的时候就把所有的边排序,然后从权重最小的边开始挑选属于最小生成树的边,组建最小生成树。
Prim 算法是从一个起点的切分(一组横切边)开始执行类似 BFS 算法的逻辑,借助切分定理和优先级队列动态排序的特性,从这个起点「生长」出一棵最小生成树。
9.Dijkstra算法
9.1.什么是Dijkstra算法
Dijkstra算法使用类似广度优先搜索的方法解决赋权图(Dijkstra 算法要求不能存在负权重边)的单源最短路径问题。
Dijkstra 算法(戴克斯特拉算法)就是一个 BFS 算法的加强版,它们都是从二叉树的层序遍历衍生出来的。
标准的 Dijkstra 算法会把从起点 start 到所有其他节点的最短路径都算出来。输入是一幅图 graph 和一个起点 start,返回是一个记录最短路径权重的数组。
如果需求只是计算从起点 start 到某一个终点 end 的最短路径,那么在标准 Dijkstra 算法上稍作修改就可以更高效地完成这个需求,
9.2.用bfs求最短路径与用dirjstra算法求最短路径的联系与区别
Dijkstra算法:用于带权有向图中求单源最短路径。
BFS算法:用于无权图的单源最短路径问题,在所有边的权值都相等时等同于Dijkstra算法
BFS和Dijkstra算法都是用于解决最短路径问题的算法,但它们的实现方法和寻找最短路径的方式有所不同。
联系:
- 都能用于寻找最短路径。
- 都可以处理有向无环图和有向图。
区别: - 实现方法不同:BFS采用广度优先搜索策略,Dijkstra采用贪心策略。
- 寻找最短路径的方式不同:BFS对所有相邻的节点进行一次性扩展,而Dijkstra算法按照从起点到各个节点的距离从小到大的顺序依次扩展。
- 时间复杂度不同:BFS最坏情况下时间复杂度为O(|V|+|E|),Dijkstra算法的时间复杂度为O((|V|+|E|)log|V|),其中|V|表示节点的个数,|E|表示边的个数。
在实际问题中,如果图的边权值为非负整数,则Dijkstra算法是最佳选择;当边权值为1时,BFS也可以作为寻找最短路径的算法之一。而如果图中存在负权边,则只能使用Dijkstra算法的变种算法。
9.3.实现Dijkstra算法
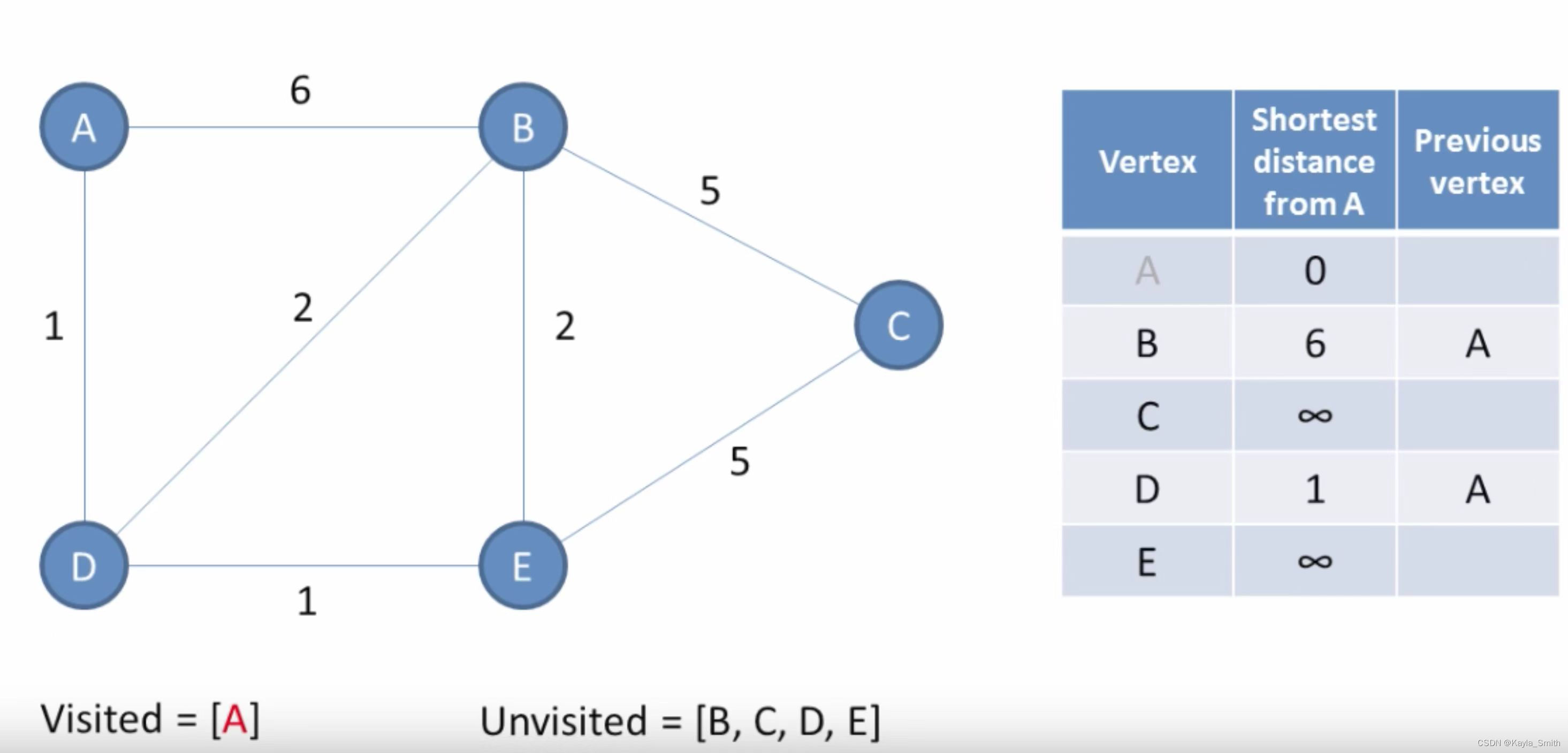
Dijkstra算法是一种用于单源最短路径问题的贪心算法。它的基本思想是将图中所有顶点分成已知最短路径的顶点集合和未知最短路径的顶点集合,每次从未知最短路径的顶点中选择与源点距离最短的顶点,将其加入已知最短路径的顶点集合中,并且以该节点为基础继续拓展其他未知节点的距离。
代码实现中,我们使用了一个表示堆的 min-heap,其中每个元素是一个元组 (dist, node),表示从源点到该节点的距离和该节点的顶点编号。具体实现时,我们利用一个邻接表存储所有的边,从源点开始遍历,每次将离源点最近的节点加入已知最短路径的顶点集合中,并且以该节点为基础拓展其他未知节点的距离,利用堆来维护未知节点中距离最小的那一个。代码中大部分的注释解释了每个函数的作用和算法的具体实现细节。
# Dijkstra,其实,Dijkstra 可以理解成一个带 dp table(或者说备忘录)的 BFS 算法,伪码如下:
# 计算从起点 start 到其他节点的最短距离。输入是一幅图 graph 和一个起点 start,返回是一个记录最短路径权重的数组。
# 使用python中的heapq实现堆:实现堆可以帮助我们在优先队列中快速找到距离最小的节点。Python中的heapq库提供了一些实用的函数,例如heappush、heappop和heapreplace等,可以对列表中的项进行有效的堆的插入、删除和替换等操作
import heapq
from typing import List, Tuple
class DijkstraSP:
def __init__(self, vertices: int, edges: List[Tuple[int, int, int]], source: int):
"""
:param vertices: 图中顶点的数量
:param edges: 图中边的列表,每个元素是一个三元组 (u, v, w),表示一条边从 u 出发,到达 v,权值为 w
:param source: 最短路径的起点
"""
self.vertices = vertices
self.graph = [[] for _ in range(vertices)] # 邻接表存储图,第 i 个元素为顶点 i 的邻接表
for u, v, w in edges:
self.graph[u].append((v, w)) # 按照起点存储所有的边
self.source = source
def dijkstra(self) -> List[int]:
"""
执行 Dijkstra 算法,返回从源点到其他所有顶点的最短距离
"""
distance = [float('inf')] * self.vertices # 初始化距离数组为正无穷,即每个节点到源点的距离
distance[self.source] = 0 # 源点到自己的距离为 0
heap = [(0, self.source)] # 建立一个堆,存放(距离,顶点)的元组
while heap:
dist, node = heapq.heappop(heap) # 弹出堆中距离最小的顶点,即当前离源点最近的顶点
if dist > distance[node]: # 如果找到的顶点不是目前已知的从源点到达该顶点的最短路径,则忽略该顶点
continue
for neighbor, weight in self.graph[node]: # 遍历目前已知最短路径的下一个顶点以及和该顶点相邻的顶点
new_distance = dist + weight # 计算目前已知最短路径的下一个顶点到当前顶点的距离
if new_distance < distance[neighbor]: # 如果从源点到达该相邻顶点的距离更短,则更新距离数组和堆
distance[neighbor] = new_distance
heapq.heappush(heap, (new_distance, neighbor))
return distance
# 大根堆,源点到某个点的最值
visited = [0] * n
heap = [[-1,start]]
while heap:
wei,node = heapq.heappop(heap)
if node == end:
return -wei
if visited[node] == 1:
continue
visited[node] = 1
for nei,neiWei in graph[node]:
new_wei = wei * neiWei
heapq.heappush(heap,[new_wei,nei])
return 0















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









