






python 程序,语音识别文字 做了报错,多线程处理,加了前端窗口,超级详细讲解,讲清楚每一个包。
你的导师会惊讶你比他还懂,为了能当老板的女婿,赶紧拍!声明下,除了官方文档部分,这是我原创的。
本程序已经封装的非常完善了,可以独立运行。
ID:3850650752670976
神捕手
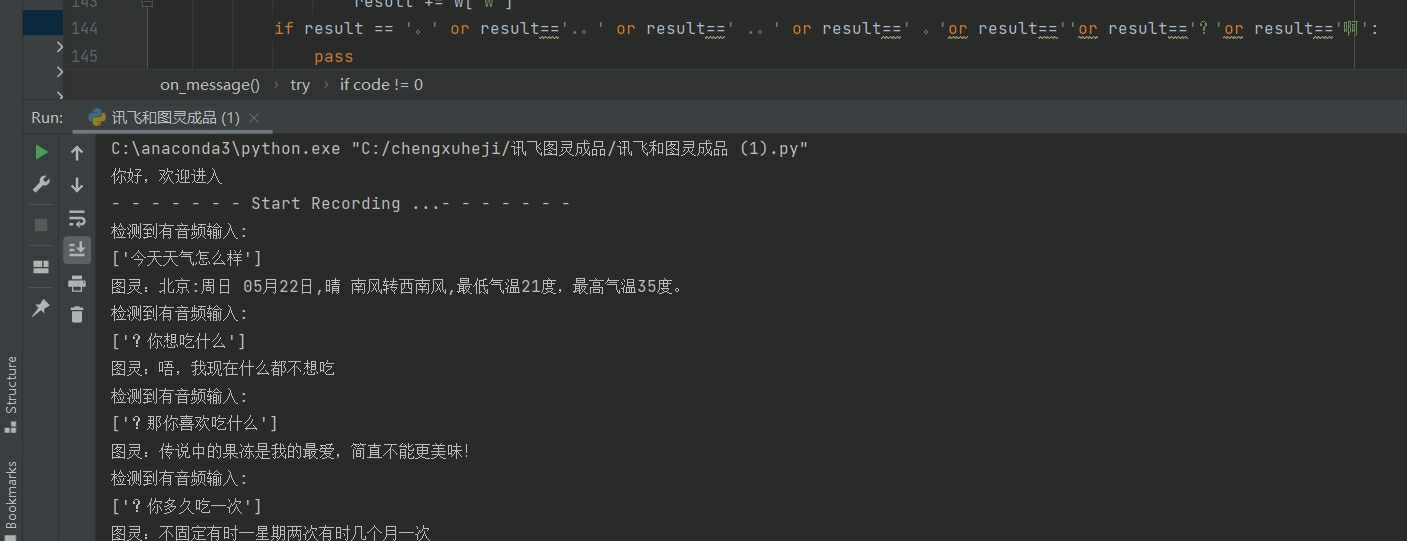

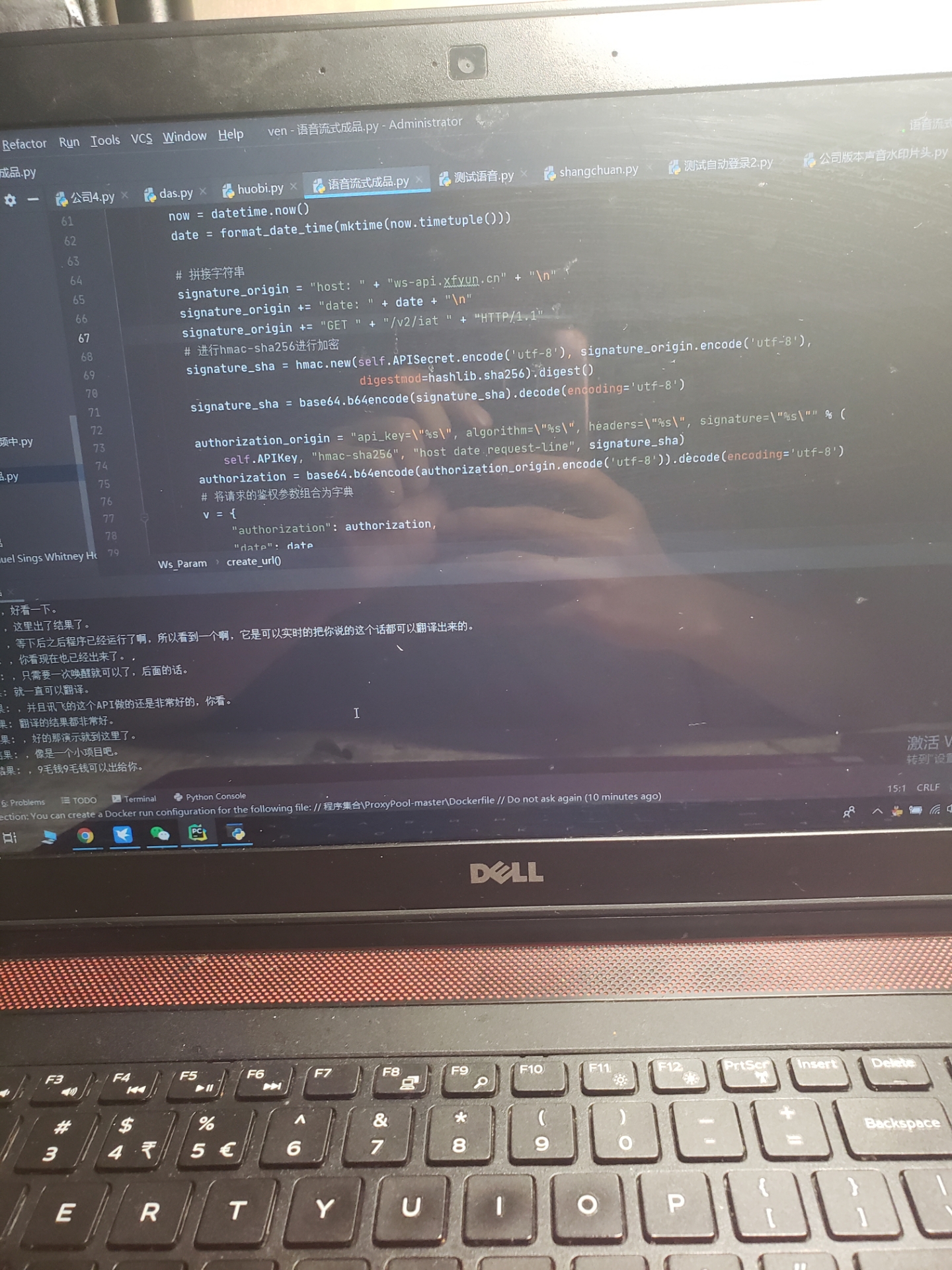
Python语言在程序开发中具有广泛的应用,其强大的语法和丰富的库使得开发者能够快速、高效地完成各种任务。其中,语音识别文字转换是一项非常有挑战性的技术,它涉及到多线程处理和前端窗口的操作。本文将对Python程序进行详细讲解,力求讲清楚每一个包的功能与使用方法,以帮助读者更好地理解和运用这项技术。
首先,我们需要明确语音识别文字转换的基本原理。语音识别是指将人类的语音信息转换为文本形式的过程,其核心是对声音信号进行分析和识别。Python提供了多个强大的库来完成语音识别任务,如SpeechRecognition、pydub、pyaudio等。其中,SpeechRecognition库是一个优秀的开源库,支持多个语音识别引擎(如Google、IBM等),并提供了简洁的API接口,方便开发者使用。
在进行语音识别文字转换时,多线程处理是一项重要的技术手段。由于语音识别过程中,需要进行实时的音频流处理,因此使用多线程可以提高程序的响应速度和并发能力。Python中的多线程处理可以使用threading库来实现,通过创建多个线程,每个线程负责处理一部分音频流数据,从而实现并行化处理。在多线程处理过程中,需要注意线程的同步和互斥,以避免数据竞争和死锁等问题。
另外,为了更好地展示语音识别文字转换的结果,我们可以加入前端窗口进行可视化展示。Python的GUI库有很多选择,如Tkinter、PyQt、wxPython等。这些库提供了丰富的图形界面元素和事件处理机制,可以方便地创建窗口、按钮、文本框等组件,并通过事件回调函数响应用户的操作。通过将语音识别结果实时显示在前端窗口中,用户可以直观地观察到转换的效果,增强用户体验。
在本文中,我们将详细讲解每一个涉及到的包的功能和使用方法。首先,我们将介绍SpeechRecognition库的基本使用方法,包括语音识别的配置、音频文件的读取和处理,以及各种语音识别引擎的选择和使用。接着,我们将深入探讨多线程处理的实现原理和技术要点,包括线程的创建和管理、线程间的通信和同步机制等。最后,我们将介绍前端窗口的创建和使用,包括窗口的设计和界面元素的布局,以及事件处理函数的编写和绑定。
总结一下,本文详细讲解了Python语音识别文字转换的实现过程。通过对语音识别的基本原理、多线程处理和前端窗口的使用进行深入分析,我们希望能够帮助读者更好地理解和应用这项技术。本程序已经封装得非常完善,可以独立运行,读者可以根据自己的实际需求进行修改和扩展。除了官方文档部分,本文是我原创的,希望能对读者有所启发。如果读者有任何问题或建议,欢迎在评论区留言。
相关的代码,程序地址如下:http://coupd.cn/650752670976.html

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









