







Apollo总体设计&原理浅析
https://www.apolloconfig.com/
微服务架构~携程Apollo配置中心架构剖析
Category: Apollo | 芋道源码 —— 纯源码解析博客
总体设计
- 总体设计基本从官方文档拷贝,已阅读过官方文档,可跳过此章节
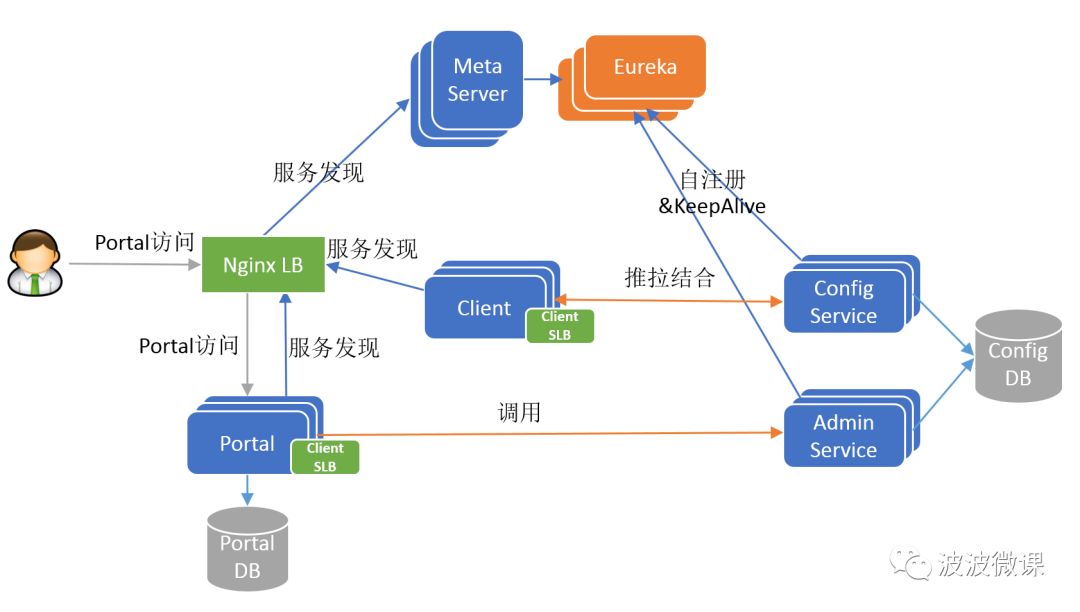
架构设计

Config Service
- 提供配置获取接口
- 提供配置更新推送接口(基于Http long polling)
- 服务端使用Spring DeferredResult实现异步化,从而大大增加长连接数量
- 目前使用的tomcat embed默认配置是最多10000个连接(可以调整),使用了4C8G的虚拟机实测可以支撑10000个连接,所以满足需求(一个应用实例只会发起一个长连接)。
- 接口服务对象为Apollo客户端
Admin Service
- 提供配置管理接口
- 提供配置修改、发布等接口
- 接口服务对象为Portal
Meta Server
- Portal通过域名访问Meta Server获取Admin Service服务列表(IP+Port)
- Client通过域名访问Meta Server获取Config Service服务列表(IP+Port)
- Meta Server从Eureka获取Config Service和Admin Service的服务信息,相当于是一个Eureka Client
- 增设一个Meta Server的角色主要是为了封装服务发现的细节,对Portal和Client而言,永远通过一个Http接口获取Admin Service和Config Service的服务信息,而不需要关心背后实际的服务注册和发现组件
- Meta Server只是一个逻辑角色,在部署时和Config Service是在一个JVM进程中的,所以IP、端口和Config Service一致
Eureka
- 基于Eureka和Spring Cloud Netflix提供服务注册和发现
- Config Service和Admin Service会向Eureka注册服务,并保持心跳
- 为了简单起见,目前Eureka在部署时和Config Service是在一个JVM进程中的(通过Spring Cloud Netflix)
Portal
- 提供Web界面供用户管理配置
- 通过Meta Server获取Admin Service服务列表(IP+Port),通过IP+Port访问服务
- 在Portal侧做load balance、错误重试
Client
- Apollo提供的客户端程序,为应用提供配置获取、实时更新等功能
- 通过Meta Server获取Config Service服务列表(IP+Port),通过IP+Port访问服务
- 在Client侧做load balance、错误重试
再附一张调用链路较为清晰的架构图
实体关系

- App
- App信息
- AppNamespace
- App下Namespace的元信息,可以理解为 Java Class
- Cluster
- 集群信息
- Namespace
- 集群下的namespace, 可以理解为 Java Instance
- 私有、公有、关联
- Item
- Namespace的配置,每个Item是一个key, value组合
- Release
- Namespace发布的配置,每个发布包含发布时该Namespace的所有配置
- Commit
- Namespace下的配置更改记录
- Audit
- 审计信息,记录用户在何时使用何种方式操作了哪个实体。
- 审计信息,记录用户在何时使用何种方式操作了哪个实体。
配置推送设计

上图简要描述了配置发布的大致过程:
- 用户在Portal操作配置发布
- Portal调用Admin Service的接口操作发布
- Admin Service发布配置后,发送ReleaseMessage给各个Config Service
- Config Service收到ReleaseMessage后,通知对应的客户端
ReleaseMessage 的实现

- Admin Service在配置发布后会往ReleaseMessage表插入一条消息记录,消息内容就是配置发布的AppId+Cluster+Namespace,参见DatabaseMessageSender
- Config Service有一个线程会每秒扫描一次ReleaseMessage表,看看是否有新的消息记录,参见ReleaseMessageScanner
- Config Service如果发现有新的消息记录,那么就会通知到所有的消息监听器(ReleaseMessageListener),如NotificationControllerV2,消息监听器的注册过程参见ConfigServiceAutoConfiguration
- NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端
配置推送至客户端
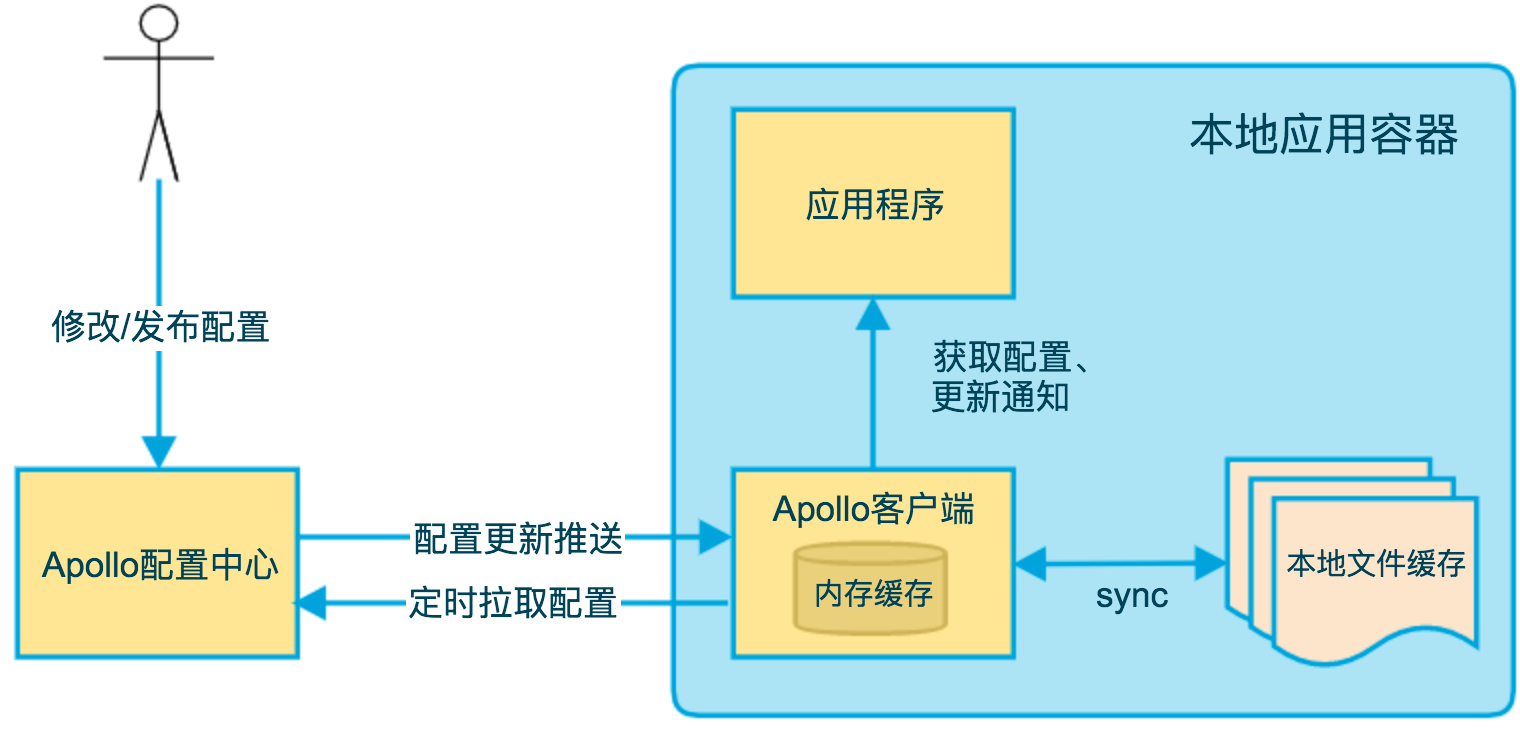
上图简要描述了Apollo客户端的实现原理:
- 客户端和服务端保持了一个长连接,从而能第一时间获得配置更新的推送。(通过Http Long Polling实现)
- 客户端还会定时从Apollo配置中心服务端拉取应用的最新配置。
- 这是一个fallback机制,为了防止推送机制失效导致配置不更新
- 客户端定时拉取会上报本地版本,所以一般情况下,对于定时拉取的操作,服务端都会返回304 - Not Modified
- 定时频率默认为每5分钟拉取一次,客户端也可以通过在运行时指定System Property: apollo.refreshInterval来覆盖,单位为分钟。
- 客户端从Apollo配置中心服务端获取到应用的最新配置后,会保存在内存中
- 客户端会把从服务端获取到的配置在本地文件系统缓存一份
- 在遇到服务不可用,或网络不通的时候,依然能从本地恢复配置
- 应用程序可以从Apollo客户端获取最新的配置、订阅配置更新通知
问题
- portal 如何管理多个环境
- 如何准实时发布消息
- 如何实现灰度发布
主体逻辑
主要从 3 方面讲解:资源创建(App、Cluster、Namespace、Item)、配置发布、Client 配置同步。
资源创建
- 调用链路可查看架构图,Portal --> Meta Server 获取 Admin Service 地址,Portal --> Admin Service 请求各资源的 CRUD 接口
- Meta Server 只是逻辑层,是对 Eureka 的封装,Admin Service 配上 Eureka Server 的地址,注册到 Eureka Server,Meta Server 就可知道 Admin Service 的地址
Portal
- 代码入口
- apollo-portal 模块下的 xxxController.create,xxx 为资源名称,如 AppController.create
- 用户的访问权限控制都在 Portal 实现(依赖 Spring Security),基于 RBAC(Role-Based Access Control)模型实现
- 创建 Namespace 时,对于 Portal 来说,是创建 AppNamespace,因为Portal 只关注管理的 App 中 Namespace 的元信息,如名称、是否公共等
- 主要逻辑,Cluster、Item 与 App、Namespace 有所不同
- Cluster、Item,访问权限控制 --> 直接调用 Admin Service 接口
- App、Namespace,访问权限控制 --> 数据落到 apolloportaldb 相关表 --> 事件监听机制调用 Admin Service 接口
Admin
- 代码入口
- apollo-adminservice 模块下的 xxxController.create,xxx 为资源名称,如 AppController.create
- 主要逻辑,基本是对各实体的 CRUD,这里就不详细讲
疑问与思考-提问
- Portal 如何知道各环境的 Meta Server 地址?
- Portal 创建 App、Namespace 时,数据落库和调用 Admin Service 接口是不在同一个事务的,如何保证App、Namespace在 Portal、Admin Service 中的数据一致性?
- 用户权限控制放在 Portal,那直接调用 Admin Service 是不是可以越过权限控制?
- 为什么创建 Cluster、Item 直接调用 Admin Service,而创建 App、Namespace 是通过事件监听机制调用?
疑问与思考-解答
- Portal 如何知道各环境的 Meta Server 地址?
- 阅读 PortalMetaServerProvider 可得到答案,从配置获取,优先级由高到低:
- database > System properties > OS environment > configuration file
- 阅读 PortalMetaServerProvider 可得到答案,从配置获取,优先级由高到低:
- Portal 创建 App、Namespace 时,数据落库和调用 Admin Service 接口是不在同一个事务的,如何保证App、Namespace在 Portal、Admin Service 中的数据一致性?
- Apollo 并没有为这个问题增加分布式事务锁,而是提供了补偿机制,在进入 App 配置管理页面时,右下角会提供按钮,同步 Portal、Admin Service 的 App、Namsepace

- 用户权限控制放在 Portal,那直接调用 Admin Service 是不是可以越过权限控制?
- Admin Service 通过系统参数
admin-service.access.control.enable开启鉴权,默认是关闭的 - Admin Service、Portal 都是通过
admin-service.access.tokens配置鉴权的 token
- Admin Service 通过系统参数
// Admin Service 的格式是字符串,多个 token 逗号分隔
token1,token2,...
// Portal 的格式是 json对象字符串,记录每个环境的 token
{env1: token1, env2: token2}
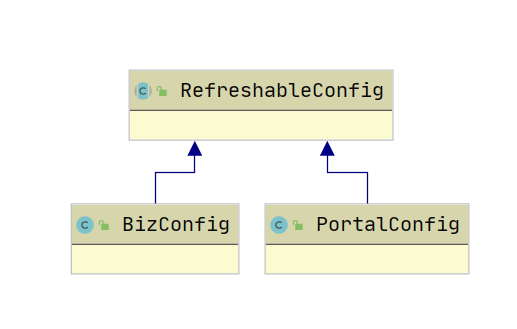
- Admin Service、Portal 的系统参数分别配置在
apolloconfigdb.serverconfig、apolloportaldb.serverconfig表- Admin Service、Portal 的系统参数实现类分别是 BizConfig、PortalConfig,他们都继承了 RefreshableConfig,RefreshableConfig 实现了定时刷新配置,间隔为 60s(模板方法模式)
- 为什么创建 Cluster、Item 直接调用 Admin Service,而创建 App、Namespace 是通过事件监听机制调用?
- 应该是出于职责单一原则的考虑
- 对于 Cluster、Item,Portal 接口的职责是传递用户的请求,由 Admin Service 提供具体操作服务
- 对于 App、Namespace,Portal 接口的职责是将需要管理的 App、Namespace 落地,所以通过事件监听机制把通知 Admin Service 的逻辑解耦出来
- 应该是出于职责单一原则的考虑
记录变更(建造者模式)ConfigChangeContentBuilder
灰度发布
发布配置-灰度发布-设计

上图描述了创建一个 namespace2 的灰度版本后,实体间的关系
- 从原本集群中,圈出一个子集群
childCluster,并创建namespace2-branch作为这个集群的namespace2,且namespace2-branch是继承于父集群的namespace2-master - 子集群包含哪些 host 由灰度规则确定
- 子集群里的 host 从
namespace2-branch读取 namespace2 的配置 - 除了子集群的其他 host,从
namespace2-master读取 namespace2 的配置 - 灰度版本进行全量发布的时候,会把
namespace2-branch的配置合并到namespace2-master - 灰度发布对于 client 是无感的,即 host1、host2、host3 访问 Config Service 获取 namespace2 配置使用的 Namespace 名称是 namespace2
主体逻辑
- 理解了灰度发布的设计,应该能猜到发布动作的实现逻辑,下面大概描述下发布的主体逻辑
创建灰度版本
- 创建 childCluster
- 创建 namespace-branch
灰度版本发布
- 创建灰度版本的 Release
- 创建灰度发布规则 GrayReleaseRule,Release 中记录着 Release 的 id,表示这条灰度规则中的 host 从指定 Release 获取配置
- 发送 ReleaseMessage
普通发布
- 创建 master 版本的 Release
- 如果会造成 branch 版本的配置变化,还会创建 branch 版本的 Release 和 GrayReleaseRule
- 发送 ReleaseMessage
灰度版本全量发布
- 将 branch 配置合并到 master,并创建 master 版本的 Release
- 若要删除灰度版本,则删除灰度的子集群,并删除灰度的 GrayReleaseRule (实际是修改状态为删除)
- 发送 ReleaseMessage
灰度版本放弃发布
- 删除子集群
- 发送 ReleaseMessage
Client 读取配置

从官方文档-客户端设计章节(本文配置推送至客户端小节从此拷贝)可知 Client 获取配置有两种方式
- 定时轮询,Client 定时请求 Config Service 的配置查询接口获取最新配置
- 长轮询,轮询 Config Service 的
/notifications/v2接口,获取配置更新通知,若有,则调用 Config Service 的配置查询接口获取最新配置
源码解析
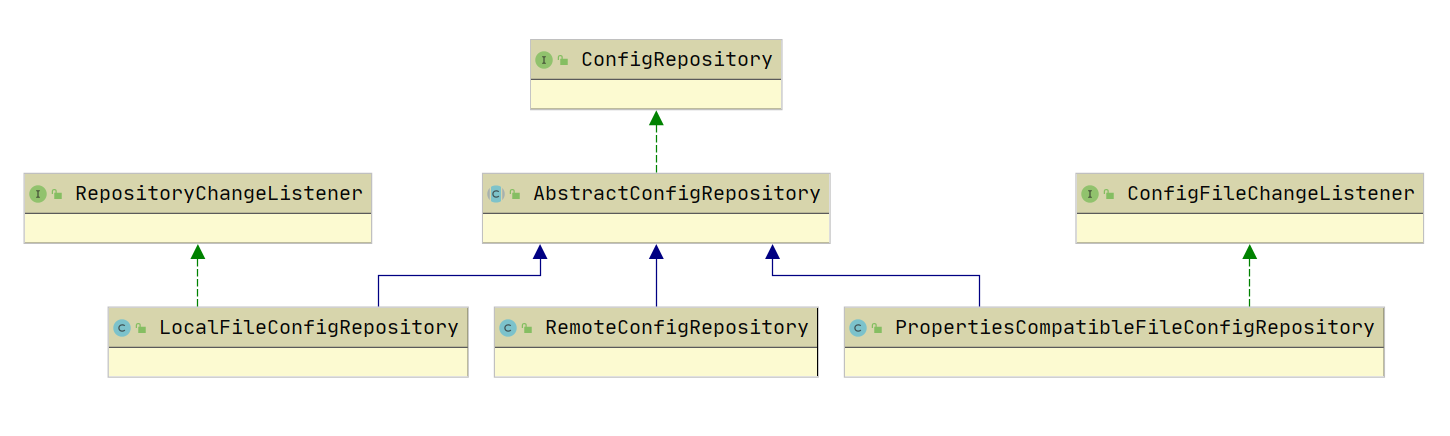
Apollo Client 同步配置主要依赖 ConfigRepository 接口
- LocalFileConfigRepository,从本地文件同步配置
- RemoteConfigRepository,从 Config Service 同步配置
- PropertiesCompatibleFileConfigRepository,兼容 yml、yaml 配置
Client
- Client 同步最新配置的主要依赖 RemoteConfigRepository
public RemoteConfigRepository(String namespace) {
m_namespace = namespace;
m_configCache = new AtomicReference<>();
m_configUtil = ApolloInjector.getInstance(ConfigUtil.class);
m_httpClient = ApolloInjector.getInstance(HttpClient.class);
m_serviceLocator = ApolloInjector.getInstance(ConfigServiceLocator.class);
remoteConfigLongPollService = ApolloInjector.getInstance(RemoteConfigLongPollService.class);
m_longPollServiceDto = new AtomicReference<>();
m_remoteMessages = new AtomicReference<>();
m_loadConfigRateLimiter = RateLimiter.create(m_configUtil.getLoadConfigQPS());
m_configNeedForceRefresh = new AtomicBoolean(true);
m_loadConfigFailSchedulePolicy = new ExponentialSchedulePolicy(m_configUtil.getOnErrorRetryInterval(),
m_configUtil.getOnErrorRetryInterval() * 8);
// 先尝试同步一次
this.trySync();
// 开启定时刷新任务
this.schedulePeriodicRefresh();
// 开启长轮询任务
this.scheduleLongPollingRefresh();
}
RemoteConfigRepository 在构造方法中,
- RemoteConfigRepository.trySync() 先同步一次配置
- 主要逻辑是调用 Config Service 的发布配置查询接口
- 通过 RemoteConfigRepository.schedulePeriodicRefresh() 开启定时刷新任务·
- 主要逻辑是定时调用 RemoteConfigRepository.trySync() 进行同步配置
- 周期默认 5s
- 通过 RemoteConfigRepository.scheduleLongPollingRefresh() 开启长轮询任务
- 主要逻辑是调用 Config Service 的
/notifications/v2接口,得到新消息通知 - 周期默认 2s
- 有新消息,会回调 RemoteConfigRepository#onLongPollNotified
- 这里面主要也是异步调用了 RemoteConfigRepository.trySync()
- 这里面主要也是异步调用了 RemoteConfigRepository.trySync()
- 主要逻辑是调用 Config Service 的
Config Service
Config Service 在 Client 同步最新配置过程中主要职责有
- 提供查询最新配置的接口,ConfigController#queryConfig
- 提供轮询是否有新配置发布的接口,NotificationControllerV2#pollNotification
- 扫描 apolloconfigdb 是否有新发布,ReleaseMessageScanner#afterPropertiesSet
ConfigController#queryConfig
- 主要是通过 namespace、cluster、appId 获取最新的发布 Release(release1)
- 然后查找 namespace 关联的公共 namespace 的最新发布 Release(release2)
- 最后将 release2 的配置合并到 release1
NotificationControllerV2#pollNotification
- 将请求用 Map 存起来,然后挂起
- 定时扫描是否有最新发布的任务,扫描到新发布时,在从 Map 获取请求进行响应
- 若一直没有新发布,Map 中的请求就会超时,默认 60s,超时相应 403 表示无修改
ReleaseMessageScanner#afterPropertiesSet
- 从数据库读取最新的 ReleaseMessage
- 通知所有监听器
- 监听器在初始化 ReleaseMessageScanner 时就已注册(MessageScannerConfiguration#releaseMessageScanner ),包括 NotificationControllerV2















 2850
2850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









