






希望是附丽于存在的,有存在,便有希望,有希望,便是光明。
鲁迅
什么是内存模型 - 计算机内存模型
内存模型,Memory Model,这是一个与计算机硬件有关的概念。
CPU和缓存一致性
一个很基础的概念,计算机在执行程序的时候,每条指令都是在CPU中执行的,而执行的时候,计算机上的数据,是放在计算机的主内存也就是物理内存中。在计算机发展的初始时代,是没有问题的,但是随着CPU的飞速发展,执行速度越来越快,而内存技术并没有跟上,这就会导致内存的读取写入速度与CPU的执行速度差越来越大,CPU每次操作内存都会耗费许多时间等待。
举个简单的例子,一个公司,在初创时代,工作起来没有任何问题,但是老板能力开始飞速的提高,而员工没有大的变化,老板每一次交代的任务,员工都不能准时的完成,老板都需要等待,这就会无形中拖慢整个公司的节奏。
这种情况怎么解决?总不能向下靠拢,老板去适应员工的节奏吧?
计算机对于这个现象给出的办法,就是在CPU和内存之间增加一个高速缓存。这也就变成了,CPU不会在和主内存直接交互,而是直接从它的高速缓存中读取和写入数据,当运算结束后,在将高速缓存的数据刷新到主内存中。
老板和底层员工不在直接产生交接,而是增设一个小组长或者是中间设置一个管理者,老板和管理者进行沟通,管理者在把老板的意思传达给底层执行者。
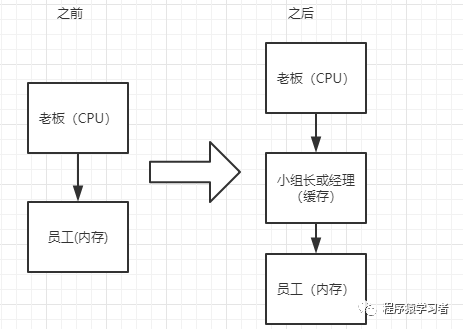
随着CPU能力原来越高,一层缓存已经不能满足需求了,就逐渐衍生出多级缓存。
按照数据读取顺序与CPU结合的紧密程度,缓存又划分了一级缓存(L1)、二级缓存(L2)、三级缓存(L3),每一级缓存都是下一级缓存的一部分。
所以在程序的执行中,CPU要读取一个数据,就要先从L1中查找,如果没有再去L2,如果还没有就去L3,最后就去内存中查找。
随着公司的扩大,老板的能力越来越高,公司上市了。公司架构又增设了许多高层、中层、底层管理者,一级一级之间逐层管理。
单核CPU有一套缓存体系。
多核CPU,有多个核心,每个核心都有自己的一套L1(或也含有L2),而共享L3(或L2)
公司由原来的一个大BOSS,现在变成了董事会机制,每一个领导都分管自己的一个直接部门,而大家共同使用的还是公司的底层架构。
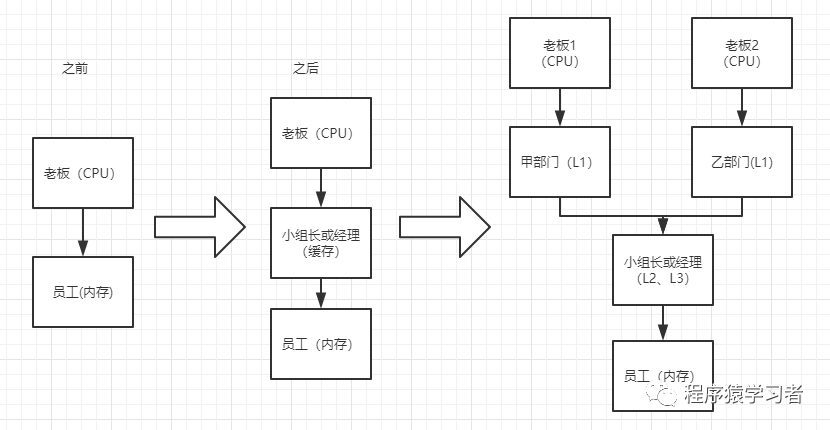
到现在,其实还没有出现问题,接下来,问题就要来了。
单线程中,CPU缓存只被一个线程访问,不会出现什么问题。
单核CPU多线程,进程中的多线程会同时访问进程中的共享数据,cpu将某块内存加载到缓存后,不同线程访问相同的物理地址,都会映射到相同的缓存位置,这样即使发生线程切换,缓存仍不会失效。但是由于任何时刻都只能有一个线程在执行,因此不会出现缓存访问冲突
多核CPU多线程,每个核都最少有一个L1。多个线程访问进程中的某个共享内存,而且是在不同的核心上执行,
则每个核心都有自己的一份共享内存的缓冲,由于多核是并行的,可能会出现多个线程同时执行而导致缓存的数据不同的情况。
也就是说,cpu和主存之间增加缓存,就可能会出现缓存一致性问题。
公司的两个部门对一个人产生了两个不同的判定,甲部门对这个人评价为优等,表示要升职,而乙部门表示这个人有过错,要辞退这个人,但是甲乙两个部门是平级的,所以最后的结果就会导致,这个人可能被辞退了,而甲部门在做升职的时候,这个人不见了。
处理器优化和指令重排
处理器为了使运算单元充分利用,会对输入的代码进行乱序执行处理,这就是处理器优化
而除了处理器会对代码进行优化之外,编程语言也会对代码进行优化,比如java虚拟机的即时编译器(JIT)进行指令重排。
如果甲乙部门对某个员工的决定进行随意执行和乱序执行的话,对于员工个部门,甚至整个公司,肯定是灾难性的
其实,对于编程来说,缓存一致性问题就是可见性问题。处理器优化会导致原子性问题,指令重排序会导致有序性问题。
什么是内存模型 - java内存模型
解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。目的是保证并发编程场景中的原子性、可见性和有序性。
尼古拉斯·赵四
java内存模型的基本概念(一)
java内存模型,其实本质上就是约束java程序运行的一种规范。
java内存模型规定,所有的变量都存储在主内存中,每条线程都有自己的工作内存,该内存中保存了该线程中用到的变量的主内存拷贝,线程对变量的操作必须在工作内存中进行,但是不能直接读写主内存。不同的线程之间不能直接访问对方的工作内存内的变量。(有兴趣的可以参考一下本人编写的多线程:学好JAVA基础(七):多线程)应该对多线程和内存模型都有更深的理解。
java中,提供了synchronized实现原子性。
提供了volatile实现可见性。synchronized和final也可以。
volatile和synchronized都可以保证程序的有序性。但是用法不同,volatile是通知禁止指令重排序,synchronized是保证同一时刻只能运行一个线程。在这就不多说了。
最后说一下,synchronized因为控制了同一时刻线程运行的数量,所以效率不能保证,不建议随便使用。
java内存模型的基本概念(二)
Memory Barrier(内存屏障)
内存屏障(英语:Memory barrier),也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。大多数现代计算机为了提高性能而采取乱序执行,这使得内存屏障成为必须。语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
维基百科
内存屏障,大致就是这么一条命令:
保证特定操作的执行顺序。
影响某些数据的内存可见性。
CPU或者编译器为了性能优化,在保证结果一致的前提下,对程序进行重排序,而插入一条Memory Barrier,就会告诉CPU或者编译器,你那些重排序不好使,必须按照我的规则来,什么时候重排序,什么时候刷新缓存。
如一个 Write-Barrier(写入屏障)将刷出所有在 Barrier 之前写入 cache 的数据,因此,任何CPU上的线程都能读取到这些数据的最新版本。
比如volatile。
JMM会在写入这个字段之后插进一个Write-Barrier指令,并在读这个字段之前插入一个Read-Barrier指令。
也就是说。volatile修饰的变量,每次写更新,都会强制刷新到主内存中,而每次读,都会强制从内存中获取新的数据。
volatile在禁止了程序的重排序的前提下,保证了数据的可见性。
happens-before规则
程序顺序规则 :线程中的每个操作,happens-before它之前的每个操作。(可能对于这个解释会有疑问,这句话的大概意思就是:实际执行的顺序可能与我们预想的顺序不一致,但是结果肯定一致)
监视器锁规则:对于一个锁的操作,happens-before后续对这个锁的加锁操作(对一个锁来说,当一个线程进行解锁操作之后,前一个使用当前锁的线程的操作结果对它可见。)
volatile域规则:对于一个volatile变量的写操作,happens-before之后对这个变量的读操作。(如果一个线程对volatile变量进行写操作,那么一定对另一个线程的读操作可见)
传递性规则:如果A happens-before B,B happens-before C,那么A happens-before C。(只能表示A对B可见,B对C可见,A对C可见,但是执行顺序并不能保证一定是前一个一定在后一个之前执行)
start()规则:主线程A启动线程B,线程B可以看到主线程A启动线程B之前的操作。(如果主线程A启动,这时主线程A启动线程B,那么启动线程B之前主线程A的所有共享变量对线程B可见)
join()规则:主线程A等到线程B执行完成,待线程B完成后,主线程A可以看到线程B内的所有操作。也就是说,子线程B的所有操作,happens-before join()的返回.(如果主线程A在等待线程B执行完成后,那么线程B对共享变量的改变对主线程A可见)
happens-before可以理解为,前一个线程的操作结果对后一个线程可见
指令重排序
在执行程序时,为了提高性能,编译器和处理器会对指令做重排序。但是,JMM确保在不同的编译器和不同的处理器平台之上,通过插入特定类型的Memory Barrier来禁止特定类型的编译器重排序和处理器重排序,为上层提供一致的内存可见性保证。
指令重排序主要分为三种
编译器重排序(JVM)
指令级并行处理器
处理器重排序(CPU)
源代码到最终执行的指令序列如图:

as-if-serial语义
不管怎么执行指令重排序,程序执行的结果都不能被改变。
最后,写作不易,求一波关注






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











