








1.MobileNetV1文章
https://mydreamambitious.blog.csdn.net/article/details/124560414
2.重新搭建MobileNetV1模型结构(便于训练)
注:只要将Github上下载的代码中网络结构换成下面的这个MobileNetV1结构即可(如果采用的是面向对象的方式设计的网络结构的话,在训练数据的时候需要做一些调整)并且再将代码中的一些名称修改一下即可。
需要修改的名称如下:
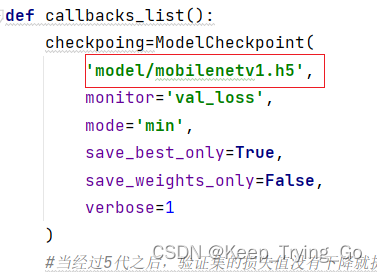
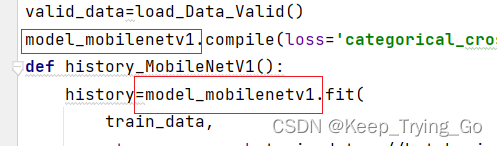


重新搭建的结构
def DepthWiseConv(inputs,filter,stride=(1,1)):
"""
:param filter: 深度可分离卷积中的1x1卷积个数
:param stride: 深度卷积的步长
:return:
"""
depthwiseconv = layers.DepthwiseConv2D(kernel_size=[3, 3], strides=stride, padding='same')(inputs)
depthbatch = layers.BatchNormalization()(depthwiseconv)
depthrelu = layers.Activation('relu')(depthbatch)
conv11 = layers.Conv2D(filter, kernel_size=[1, 1], strides=[1, 1], padding='same')(depthrelu)
conv11batch = layers.BatchNormalization()(conv11)
conv11relu = layers.Activation('relu')(conv11batch)
return conv11relu
def MobileNetV1(input_shape=(224,224,3),num_classes=5):
input=keras.Input(input_shape)
conv1 = layers.Conv2D(32, kernel_size=[3, 3], strides=[2, 2], padding='same')(input)
conv1batch = layers.BatchNormalization()(conv1)
conv1relu = layers.Activation('relu')(conv1batch)
x=DepthWiseConv(conv1relu,filter=64, stride=(1, 1))
x=DepthWiseConv(x,filter=128, stride=(2, 2))
x=DepthWiseConv(x,filter=128, stride=(1, 1))
x=DepthWiseConv(x,filter=256, stride=(2, 2))
x=DepthWiseConv(x,filter=256, stride=(1, 1))
x=DepthWiseConv(x,filter=256, stride=(2, 2))
for i in range(5):
x=DepthWiseConv(x,filter=512, stride=(1, 1))
x=DepthWiseConv(x,filter=512, stride=(2, 2))
x=DepthWiseConv(x,filter=1024, stride=(1, 1))
avgpool = layers.GlobalAveragePooling2D()(x)
dense = layers.Dense(num_classes)(avgpool)
dropout = layers.Dropout(rate=0.8)(dense)
softmax = layers.Activation('softmax')(dropout)
model=Model(inputs=input,outputs=softmax)
return model
model_mobilenetv1=MobileNetV1(input_shape=(224,224,3),num_classes=5)
# model_mobilenetv1.summary()
3.训练的结果
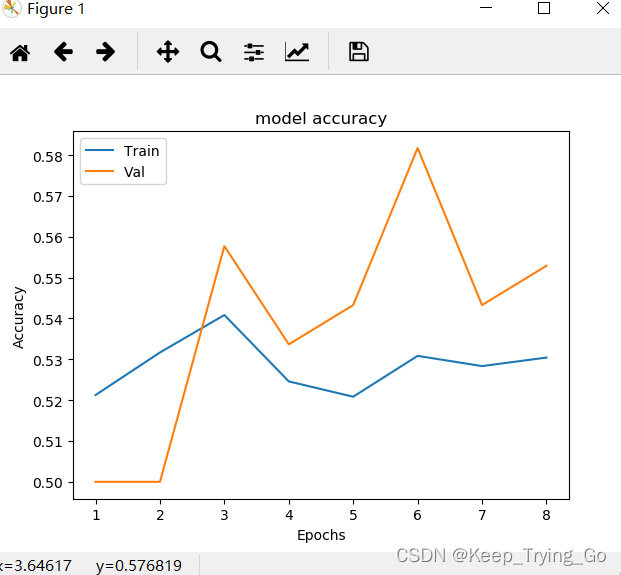

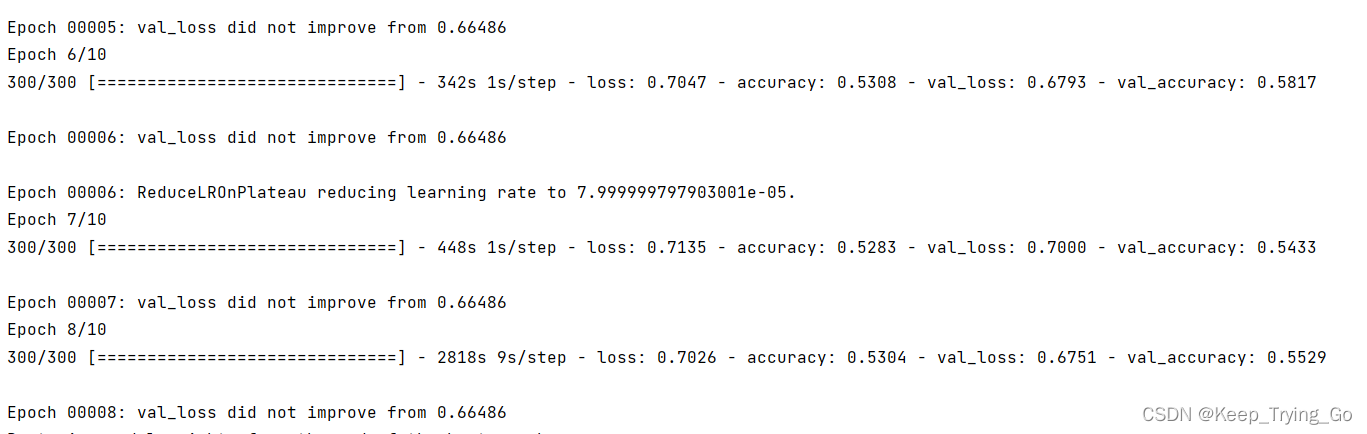
由于数据集不是很多,只有近1000张图片,并且之包含两个类别(猫-cat,狗-dot)所以训练的最后效果一般,读者可以根据自己的需要收集图片进行训练。

4.图像分类测试
只需要将flask中加载的权重文件换成自己训练的就可以了(flask这部分代码在从Github下载的文件中)。
https://github.com/KeepTryingTo/-.git

flask.py文件:

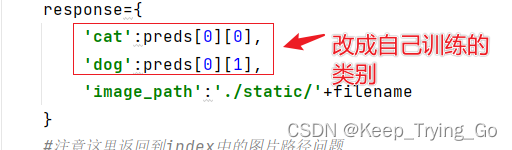
前端文件:index.html
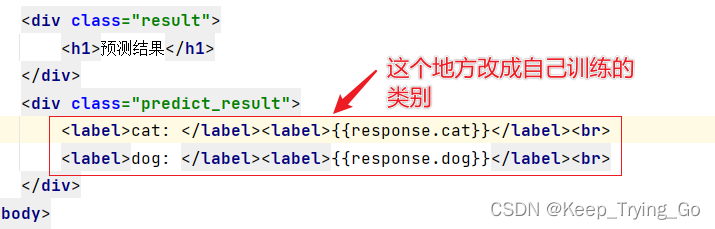
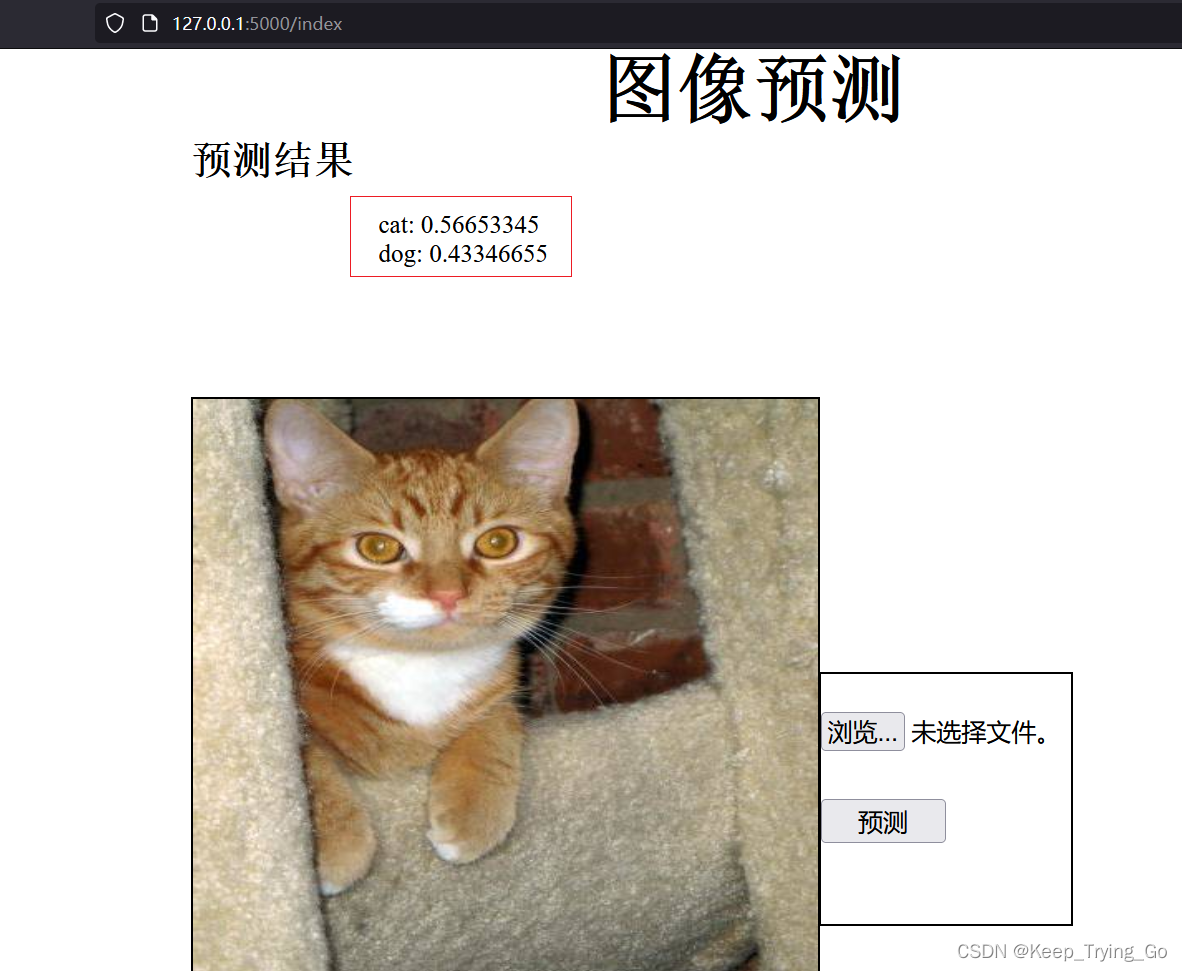

从预测结果来看和模型训练的效果差不多,读者可以自己多训练几代(epoch)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









