






目录
在看这篇博文之前,可能有小伙伴会疑问关于迁移学习和微调之前不是已经讲过吗?为什么这里还要继续讲解呢?并且网上或者视频都能找到相关的内容,是不是下面的讲解就不值得看呢?不是的,看过网上讲解的,包括我较早之前给出的代码案例和讲解,甚至有些时候别人已经告诉你什么时候该使用迁移学习和微调,应该注意什么事项,这些内容本身没有问题,对于想要了解迁移学习的初学者来说也没有问题,但是大家应该能看到并没有一个实际的证明迁移学习和微调比从头开始训练一个模型更加的好或者从时间上来说有多大的优势,而且很多时候都是从概念讲解或者直接给出一段代码,如果能讲解的更加深入一点就好了
本文再次来详解迁移学习和微调,并不是因为其他人的讲解有问题,我总是感觉很多都是从概念来讲解或者直接贴出一段代码,并没有更加深入的理解或者讲解其中的内容,因为迁移学习和微调在实现下游任务的时候非常的重要,有一个好的预训练模型,在很多场景下都能得到广泛的应用,并且自己要实现在通用的大规模数据集上训练得到一个好的预训练模型是非常难得,不仅仅是成本和时间上的问题。因此,如果我们不需要自己训练并且还能实现一个好的效果,不管是从时间和成本上来讲的话都是比较优的。
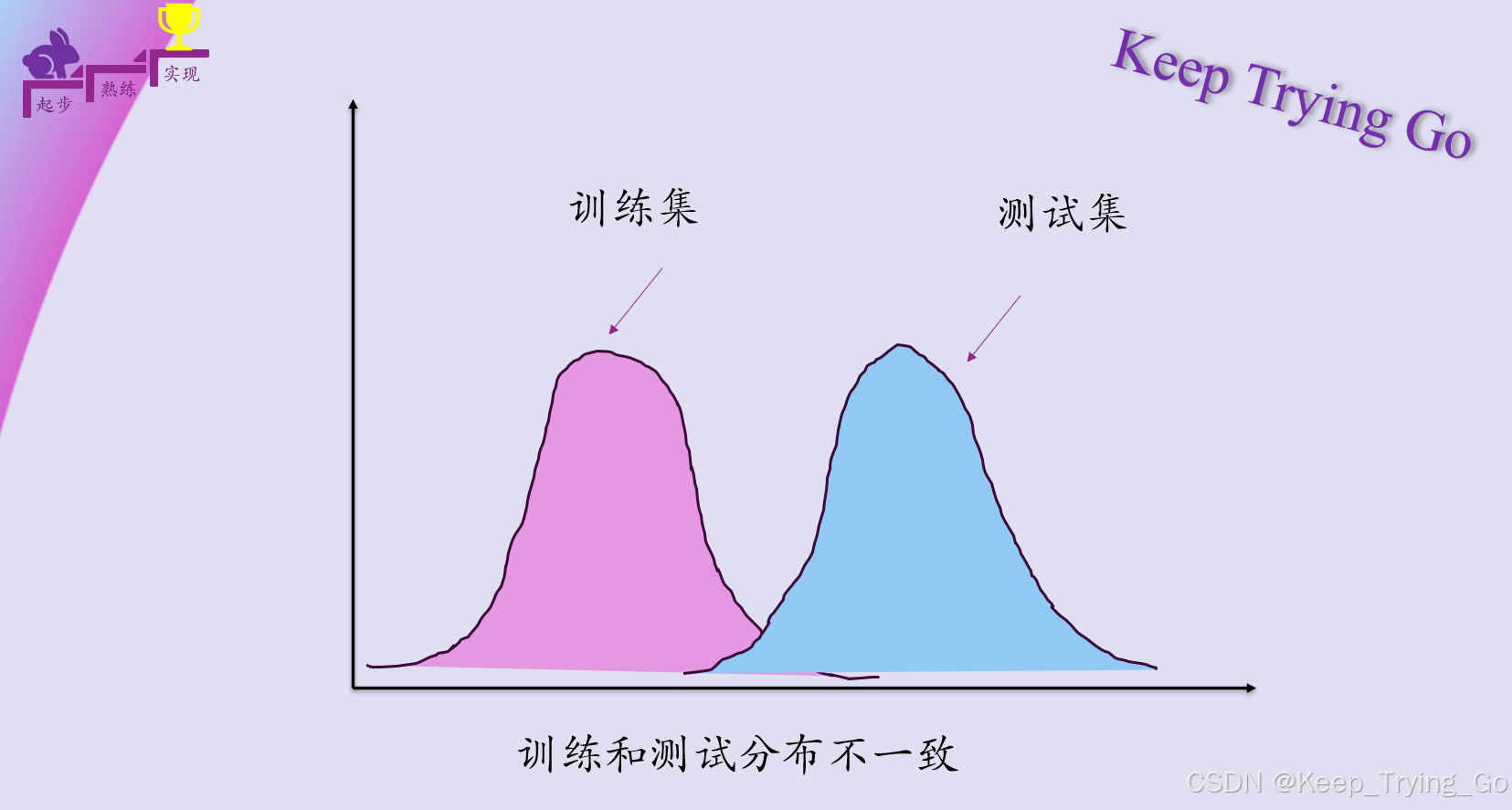
训练集和测试集分布不一致
其实对于大部分的小伙伴都应该清楚,我们对模型进行训练的时候,一般都会认为训练集和测试集是满足相同分布的,只是这一点我们很多时候并没有太去关心,因为我们大部分使用的是公开的数据集(因为如果要和其他论文方法作对比的话,更多的是使用公开数据集)。假设我们自己划分数据集的话,如果训练集和测试集的分布差异较大的话,会发现最终的结果离预期的效果较远,只要程序的其他部分没有问题,像这种情况对于不熟悉或者不注意的小伙伴很难找到原因。我们都知道,要准备一个和测试集相同分布的大规模训练集是很困难的,不仅是时间和成本的问题,数据集的有效测试也需要进行。如下图所示:训练集和测试集分布不一致情况
迁移学习和微调引言
为了解决大部分人都能在下游任务或者自己的领域训练一个效果比较好的模型,采用迁移学习和微调是目前最好的选择,不需要大规模的训练数据集标注,节约的成本和时间。迁移学习所使用的预训练模型是在通用大型数据上训练得到的,虽然这些所说的“通用大型数据”和自己的子任务数据分布还是存在差异,但是模型已经在大规模数据集上学习到了相关的泛化知识,如何将这些泛化知识迁移到我们的子任务中呢?于是采用“迁移学习和微调”。
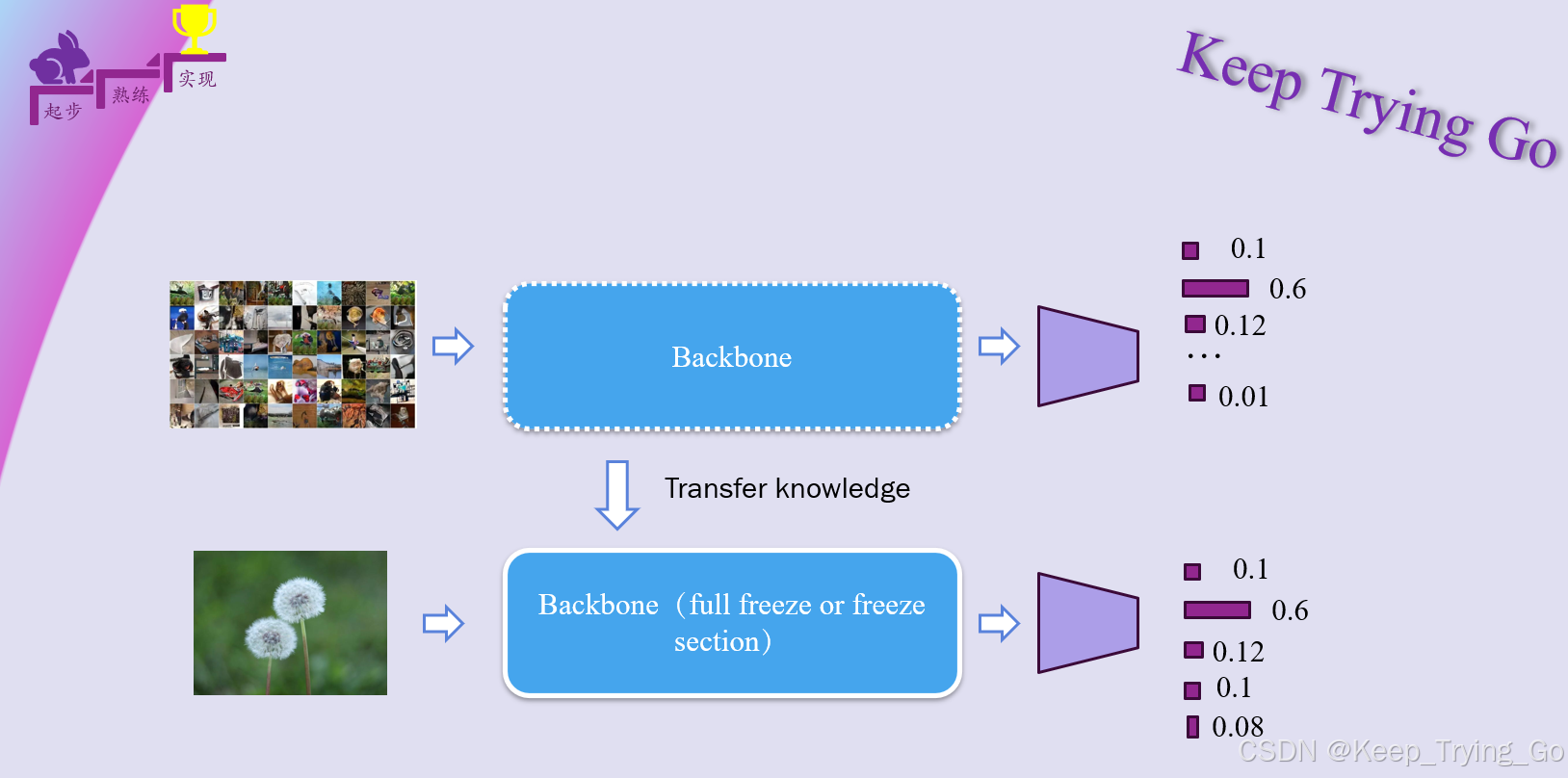
以下我们还是要把相关的概念给列出来,其次是对其比较通俗的讲解:以下提到的概念只要理解就好,如果 有些概念现在还不能理解就直接跳过,后期慢慢理解,最后通过实验的方式进一步理解其中的含义
迁移学习:核心思想是将一个领域(源领域)上学到的知识迁移到另一个领域(目标领域)
归纳迁移学习
源领域和目标领域的任务不同,但数据分布相似。通过在源领域上训练模型,然后在目标领域上微调。通俗讲就是训练在一个数据集上,然而应用是在另外一个数据集上。
- (1) 基于特征的方式:将预训练模型的输出或者是中间隐藏层的输出作为 特征直接加入到目标任务的学习模型中.目标任务的学习模型可以是一般的浅 层分类器(比如全连接层等)或一个新的神经网络模型.
- (2) 精调的方式:在目标任务上复用预训练模型的部分组件,并对其参数 进行精调(Fine-Tuning).
转移学习
源领域和目标领域的任务相同,但数据分布不同。通常需要对模型进行适当的调整。通常假设源领 域有大量的标注数据,而目标领域没有(或只有少量)标注数据,但是有大量的 无标注数据.目标领域的数据在训练阶段是可见的.其实可以看成是域适应。
跨域迁移学习
- 源领域和目标领域的任务和数据分布都不同。需要更复杂的模型和方法来实现知识的迁移。
注:“领域”是什么?什么才是不同的“领域”?
大致解释:在我们看论文或者相关域泛化任务的时候,总是会看到“领域”这个词。“领域”官方的解释就是一个特定的应用场景或者数据集的类型。通俗的理解比如计算机视觉和自然语言处理是两个不同的应用领域,其中计算机视觉主要涉及图像的处理,比如图像分类,图像增强,目标检测,语义分割等;而自然语言处理涉及文本处理,比如文本分类,情感分类,问答系统,文本生成等。如果从数据领域细分角度来看的话,比如人群统计数据,医疗图像分割数据,视频数据等。如果从任务细分角度来理解的话,比如图像分类领域,目标检测领域,图像分割领域,文本分类领域等。总之从上面“域”的划分类型来看的话,其实并没有一个硬性的标准划分,如果对任务看待的角度不同,其实也可以理解为不同“域”。
- 微调是迁移学习中的一个重要步骤,指的是在目标任务上对预训练模型进行进一步训练,以适应特定的任务需求。微调通常涉及对模型的参数进行小幅度调整,以提高在目标任务上的性能。
微调的策略(实验中体现)
- 全模型微调:对整个模型进行微调,适用于源任务和目标任务相似的情况。
- 部分微调:只微调模型的最后几层,适用于源任务和目标任务差异较大的情况。
- 冻结层:在微调过程中,可以选择冻结某些层的权重,只训练特定的层,以保持预训练模型的特征提取能力。
微调的优势(这些都将在后面的实验得到证明)
- 提高性能:通过微调,模型能够更好地适应目标任务,提高预测准确性。
- 节省时间:相比从头开始训练模型,微调可以显著减少训练时间和计算资源。
- 利用已有知识:微调能够有效利用在源任务上获得的知识,提升模型的泛化能力。
注:搭建的模型不一定是要和预训练模型整体结构相同,也就是说我们搭建的模型可能比预训练模型要深后者要浅,但是我们可以将预训练模型的部分层权重参数迁移到搭建的模型当中,对搭建模型的部分层微调,迁移之后的层权重参数不再是随机初始化,而是有规律的。像这种预训练模型整体结构和搭建的模型会有所区别,可能是任务方面差别比较大,因此一般都是将浅层权重参数迁移到搭建的模型当中,其他部分的参数进行随机初始化。
- 两种方式来自定义预训练模型:
- 方式一:
- 特征提取:使用先前网络学习的表示从新样本中提取有意义的特征。您只需在预训练模型上添加一个将从头开始训练的新分类器,这样便可重复利用先前针对数据集学习的特征映射。
- 无需(重新)训练整个模型。基础卷积网络已经包含通常用于图片分类的特征。但是,预训练模型的最终分类部分特定于原始分类任务,随后特定于训练模型所使用的类集。
- 方式二:
- 微调:解冻已冻结模型库的一些顶层,并共同训练新添加的分类器层和基础模型的最后几层。这样,我们便能“微调”基础模型中的高阶特征表示,以使其与特定任务更相关。
实验验证
实验设备,参数以及实验数据
| 实验设备 | 实验数据 | 参数设置 |
|---|---|---|
| 驱动 511.81 CUDA 11.6 NVIDIA GeForce RTX 2050 显存4G | flower photos(包含5种花;daisy-黛西,dandelion-蒲公英,rose-玫瑰,sunflower-太阳花,tulip-郁金香) | 输入模型图像大小 = 224 |
ImageNet数据集:imageNet.txt
链接:https://pan.baidu.com/s/1ZfuJ1E9QIiy6RgfnizdihQ
提取码:8shl
注:ImageNet数据集中包含rose这个花的类别,其他类别不包含。
模型参数比较
| 模型名称 | 总的参数 | 可训练参数 |
|---|---|---|
| mobilenet_v3_small,pretrained = True(修改分类层,冻结backbone的前5层) | 1,,522,981 | 1,498,757 |
| mobilenet_v3_small,pretrained = True(修改分类层,冻结backbone的前10层) | 1,,522,981 | 1,240,613 |
| mobilenet_v3_small,pretrained = True(修改分类层,冻结backbone) | 1,522,981 | 595,973 |
| mobilenet_v3_small,pretrained = False(修改分类层) | 1,522,981 | 1,522,981 |
| 自定义模型Model | 67,973 | 67,973 |
训练结果比较
| 模型名称 | 最好结果 | 训练时间 |
|---|---|---|
| mobilenet_v3_small,pretrained = True(修改分类层,冻结backbone的前5层) | 92.2% | 3995.35s |
| mobilenet_v3_small,pretrained = True(修改分类层,冻结backbone的前10层) | 90.6% | 2576.45s |
| mobilenet_v3_small,pretrained = True(修改分类层,冻结backbone) | 87.3% | 753.23s |
| mobilenet_v3_small,pretrained = False(修改分类层,p=0.2) | 67.7% | 1859.50s |
| mobilenet_v3_small,pretrained = False(修改分类层,p = 0.5) | 68.0% | 4755.05s |
| 自定义模型Model | 63.8% | 1913.66s |
注:从实验的结果来看的话,mobilenet_v3_small使用了预训练模型并且冻结住backbone前5层之后最终的分类效果最好(注意是否过拟合问题),并且训练所用时间只是没有使用预训练模型的一般还少,这个就已经说明了上面我们提及的关于微调的优势。
其中自定义模型的参数和mobilenet_v3_small相比效果要差很多,但是效果却比mobilenet_v3_small没有使用预训练模型的效果还要差一点,虽然自定义模型比没有使用mobilenet_v3_small预训练模型的性能要差,但是这并不代表自定义模型的测试效果就要比mobilenet_v3_small差,这个在看了后面训练结果分析之后才能知道,因为上面只是给出每个类型训练之后的最终结果,其中过拟合的风险完全可能存在。
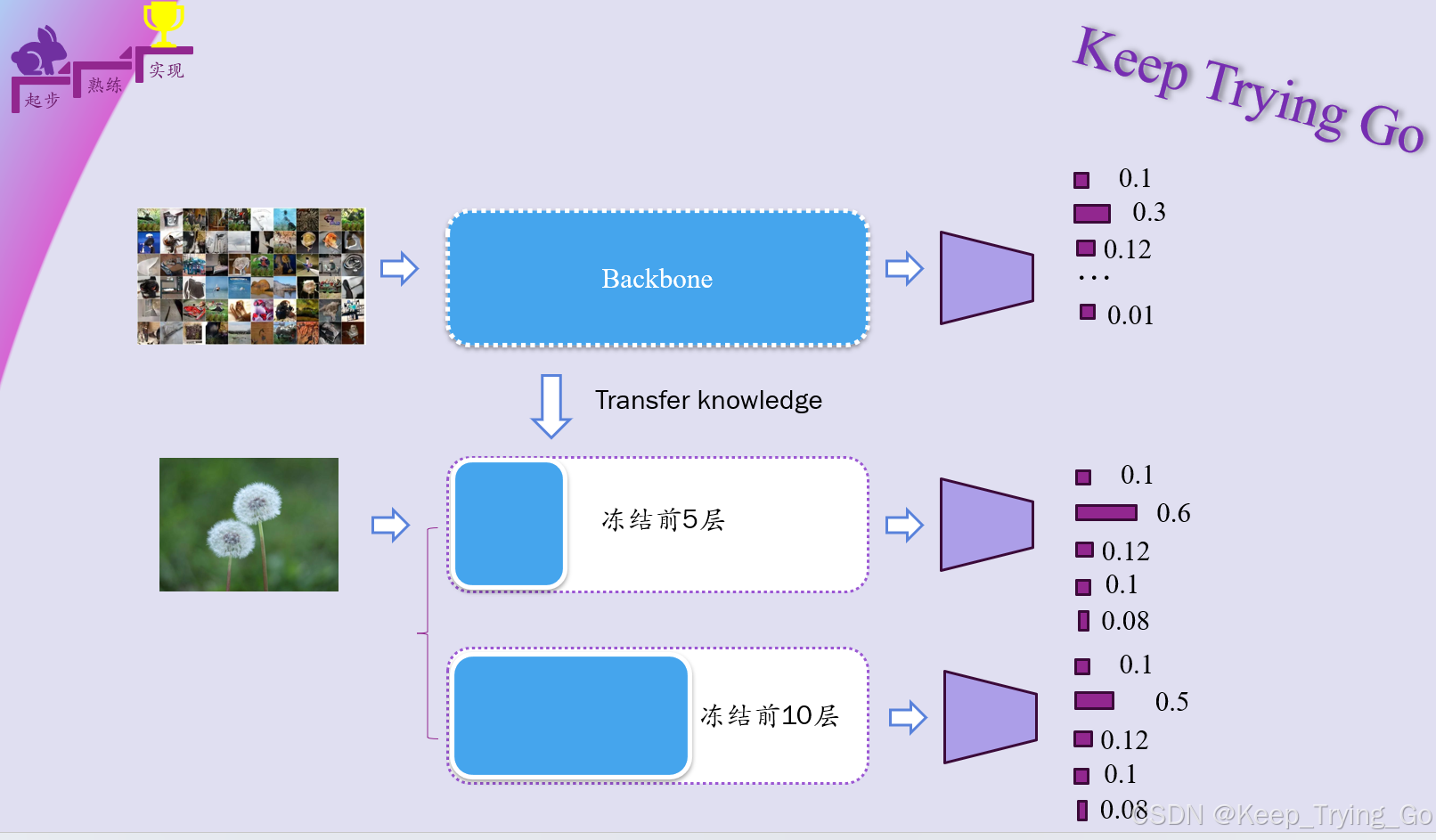
以下会选择冻结之后训练结果最好的和其他结果进行比较
训练结果损失比较
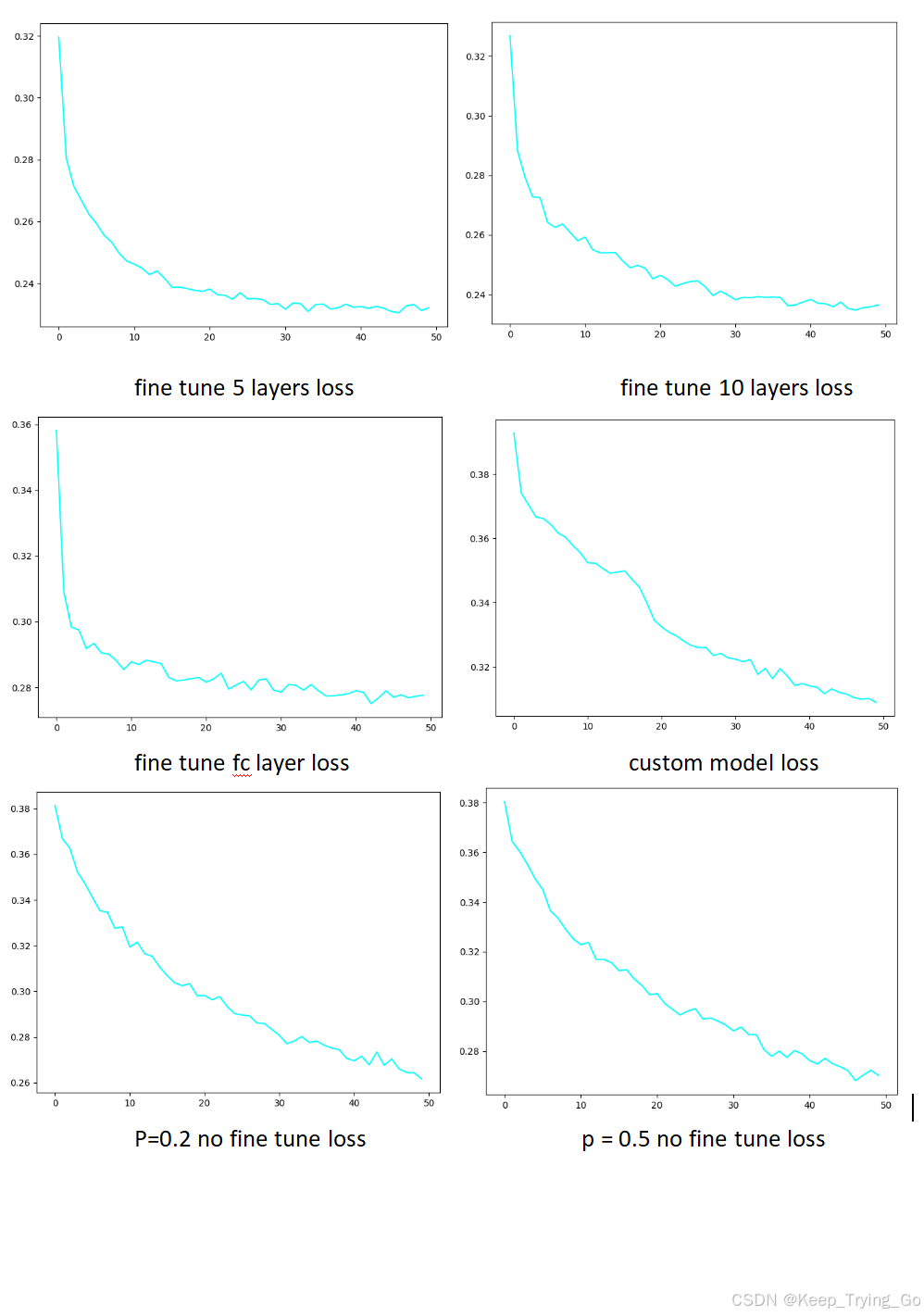
注:可以从六个图中可以看到,对使用了预训练模型的mobilenet_v3_small进行微调,其中冻结mobilenet_v3_small预训练模型的前5,10层的最终损失下降比只修改mobilenet_v3_small的分类层损失下降要多一点,这也预示着只修改mobilenet_v3_small的分类层也许没有得到次优解。如果mobilenet_v3_small不使用预训练模型的话可以看到最终的损失下降也没有得到次优解,并且由于mobilenet_v3_small模型的参数量相比于自定义模型的参数量要多得多,因此,mobilenet_v3_small没有使用预训练模型去训练图像很有可能过拟合,虽然我们设置了正则化Dropout的随机丢弃概率p = 0.2和p = 0.5,至于是否过拟合,后面的测试实验就可以看到。
训练结果训练准确率比较
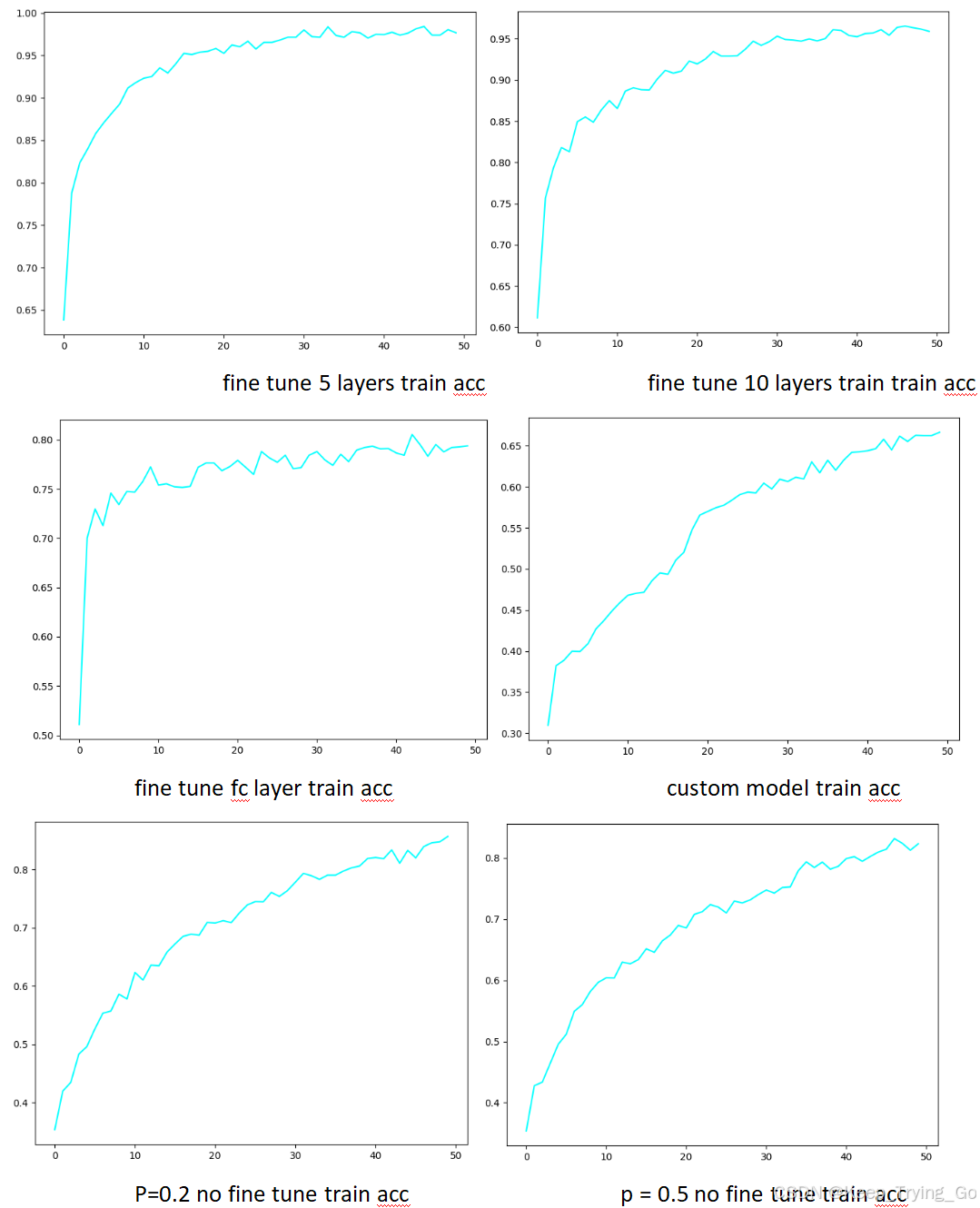
注:从训练结果准确率和最终的准确率结果来看,除了自定义模型的最终效果比较差一些之外,其他模型的训练结果准确率好像都不错,难道这能说明最终的问题吗?其实不是的,这只能代表一方面的问题,还不能说明效果比较好的模型没有出现过拟合,因为还没有进行测试,只有到测试集的上效果才能看得比较明显。其中采用了mobilenet_v3_small预训练模型的训练结果看起来都比较不错,而且准确率上升都比较快相比于其他类型的结果。
训练结果验证准确率比较
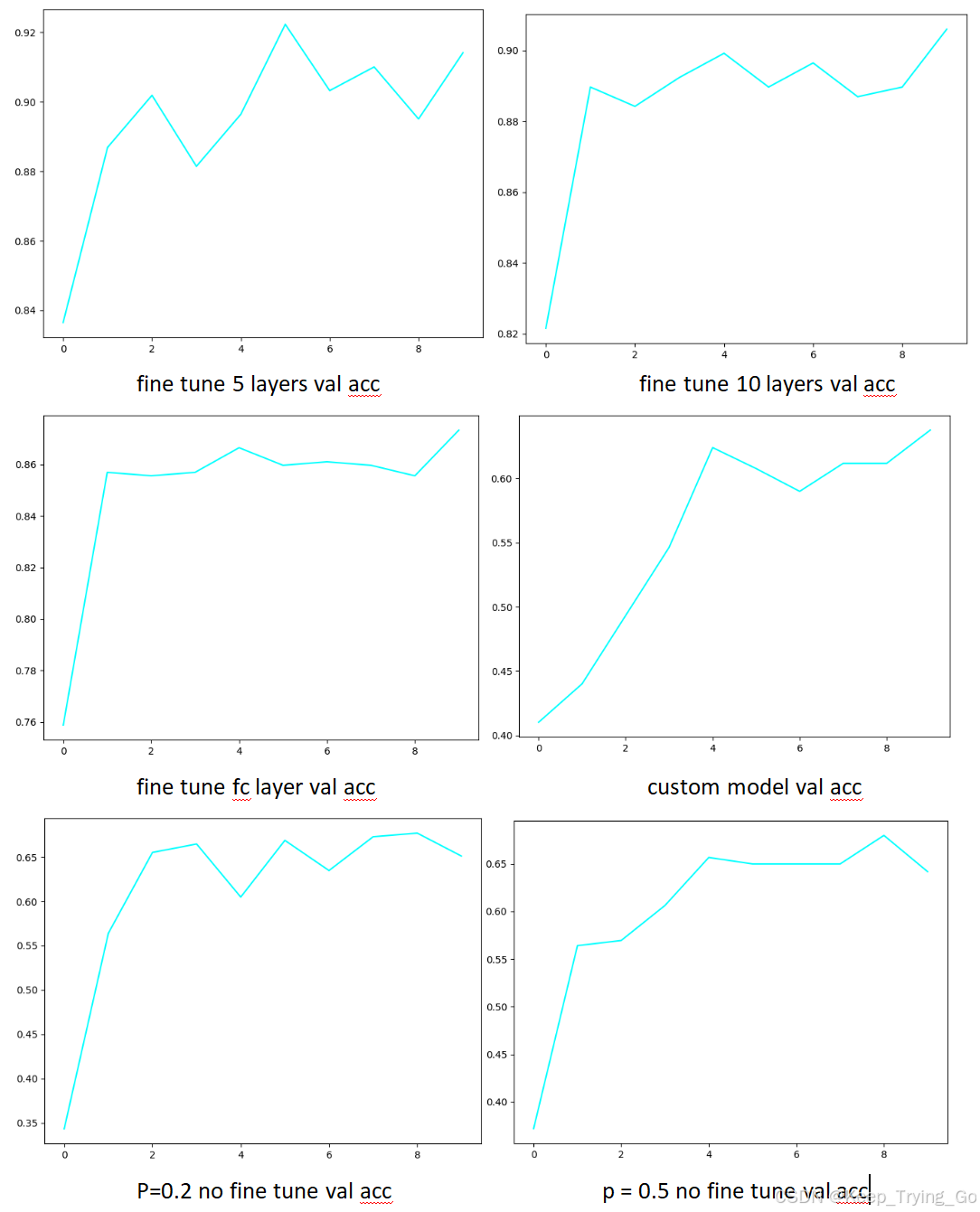
注:从使用了预训练的mobilenet_v3_small并对其进行微调的前三个图出现了轻微的过拟合现象,然而自定义模型出现过拟合的现象稍微小一点,最后没有使用mobilenet_v3_small预训练模型的训练出现了明显的过拟合现象,因此从这里就可以猜到对其进行最后的测试效果应该是比较差的,事实也确实是如此,从实验结果以及mobilenet_v3_small模型参数量来看,应该是模型相比于给定的数据集量过强。
测试结果对比

注:从上面训练结果的准确率和验证结果准确率以及最终图像的测试效果来看,没有使用mobilenet_v3_small预训练模型(最后两张测试图)结果来看,测试的结果是失败的,因为前面也看到了,确实是过拟合了。而对使用了预训练模型的mobilenet_v3_small进行微调之后,效果还是比较不错的,那么为什么如果只微调最后的分类层之后测试得到的效果比较差呢?以下总结来分析:
问题分析(重要)
- 问题1:为什么如果只微调最后的分类层之后测试得到的效果比较差呢?分析原因有几点。
- 第一点:因为ImageNet数据集中只包含rose玫瑰数据集,导致训练得到的mobilenet_v3_small中对我们提供的五种花识别率也比较低;
- 第二点:由于只微调最后的分类层的话,中间的backbone被冻结,由第一点可知,本身mobilenet_v3_small对我们提供的花识别率比较低,因此如果再次冻结backbone,那么会导致训练特征泛化不足,无法根据提供的数据集调整其提取的特征。
- 问题2:为什么从0开始训练mobilenet_v3_small会出现过拟合的现象呢?
- 主要还是因为模型相比于提供的数据集过于复杂,虽然我们知道mobilenet_v3_small模型属于轻量化的模型,参数已经是非常的少了,但是我们提供的数据集本身也比较少。
- 问题3:为什么只冻结mobilenet_v3_small的浅层之后训练得到的效果更好呢?
- 其实第一个问题就已经分析一部分了,如果只冻结mobilenet_v3_small浅层的话,那么将有更多的参数可以被训练,那么这些参数将会去拟合给定的数据分布,特征对该类型的数据泛化性也更强,不仅仅利用了ImageNet数据普遍有的特征,同时也拥有了我们提供数据集的特征;
- 我们知道模型的浅层一般包含了图像中物体的边缘,角点等信息,而更加高级的语义信息包含在深层,因此不冻结深层对于学习数据集特征更加的有利,而且从冻结mobilenet_v3_small前5层和冻结前10层的结果就可以看到,冻结mobilenet_v3_small前5的效果更好,这也说明了刚才的推断。
- 问题4:为什么我们在对mobilenet_v3_small从0开始训练并将随机丢弃概率p从0.2改为0.5之后,训练时间上会减少呢?
- 主要还是因为p是表示用于正则化的Dropout的随机丢弃概率,因此丢弃的概率越高,全连层之间的连接被丢弃的概率也越高,是防止过拟合风险的一种方式,既然被丢弃了,被丢弃的部分暂时不用训练,那么对于训练也加快了。但是却并没有改变其过拟合的风险。
总结:其实上面提出的问题就已经在回答了我们在做迁移学习和微调的过程中应该注意什么,从这个实验的过程读者就应该能够看到,在使用迁移学习和微调的过程中应该注意什么,我们并没有给读者很多概念,而是让读者从这个实验的结果去分析我们应该注意什么,使用了预训练的mobilenet_v3_small并冻结浅层出现过拟合的风险更小,上面的实验分析和最后提出的问题以及分析结果都可以看到,如果读者去做这个实验的话,也许你只需要简单看一下概念并很快就可以理解为什么是这样了。
其实如果将其预训练模型应用到其他领域结论也是如此,比如图像分割,目标检测效果怎么样!读者可以去尝试,因为自从迁移学习和微调方法出来之后,很多都使用迁移学习和微调的方式,并且得到了很好的效果,现在的语言模型也是采用微调的方式,应用到下游任务中。
迁移学习和微调论文推荐
| 论文及下载地址 | 大致内容 |
|---|---|
| DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter | 通过知识蒸馏技术在预训练阶段构建一个小型通用语言表示模型,使其在多种任务上具有良好的表现,同时大幅降低计算和内存需求。 |
| EffiSegNet: Gastrointestinal Polyp Segmentation through a Pre-Trained EfficientNet-based Network with a Simplified Decoder | 基于预训练EfficientNet网络及简化解码器的全新分割框架(将EfficientNet预训练模型作为backbone迁移和微调进行模型训练) |
| How transferable are features in deep neural networks? | 这篇论文主要是研究了深度神经网络中不同层特征的可转移性,第一层学习的特征通常是通用的,最后一层特征是特定的,随着层数的不断增加,特征的可转移性会收到高层神经元对原始任务的特化和邻近层之间的协同适应会导致优化困难。结果表明,在目标任务和原始任务差异显著的情况下,从较远的任务迁移特征比使用随机化特征表现更好,同时较少特征初始化能够在经过调优后持续提升网络的泛化能力。 |
| Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks | 对预训练的BERT网络的修改,通过采用孪生网络和三元组网络结构,生成语义上有意义的句子嵌入,从而提高了句子对比的效率,并支持大规模语义相似度比较与聚类(通过为BERT的微调) |
| SHERL: Synthesizing High Accuracy and Efficient Memory for Resource-Limited Transfer Learning | 参数高效传输学习(PETL)方法依赖于冻结大部分模型参数,以降低训练开销;将特征适应过程分为早期和后期两个互补步骤,以提高对预训练模型知识的利用效率,其中
|
| Universal Language Model Fine-tuning for Text Classification | 通用语言模型微调(ULMFiT)的方法,以提高自然语言处理(NLP)中的文本分类性能,该方法通过有效的迁移学习技术减少了训练样本的需求。 |
注:以上推荐的论文我们从论文摘要以及论文总结就可以看出是非常值得去看的,想要对知识迁移和微调有一个更加深入的理解,可以研究一下。“知识蒸馏”的概念并没有提及,关于这方面的知识点读者可以去了解,其中一篇知识蒸馏的论文很出名,可以从那篇论文出发去理解,本质是“将较大模型的知识点迁移到小模型中,让小模型也能学习到一点大模型的能力”。视乎这个内容和我们今天讲解的没有太多的关系,其实不是的,迁移学习和微调



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









