







论文下载地址:https://arxiv.org/pdf/1612.03242v2.pdf
目录

提出目的和方法
提出目的
现有的文本到图像的方法生成的样本虽然能大致反映给定描述的意思,但往往缺乏必要的细节和生动的物体部分。本文提出了堆叠生成对抗网络(StackGAN),以生成基于文本描述的256x256的照片级真实图像。
提出方法
通过草图-精炼过程将这一困难问题分解为更易管理的子问题。第一阶段的GAN根据给定的文本描述勾画出物体的原始形状和颜色,从而生成第一阶段的低分辨率图像。第二阶段的GAN将第一阶段的结果和文本描述作为输入,并生成具有照片真实细节的高分辨率图像。它能够纠正第一阶段结果中的缺陷,并通过精炼过程添加引人注目的细节。为了提高合成图像的多样性和稳定条件GAN的训练,我们引入了一种新颖的条件增强技术,鼓励潜在条件流形的平滑性。

整体模型架构

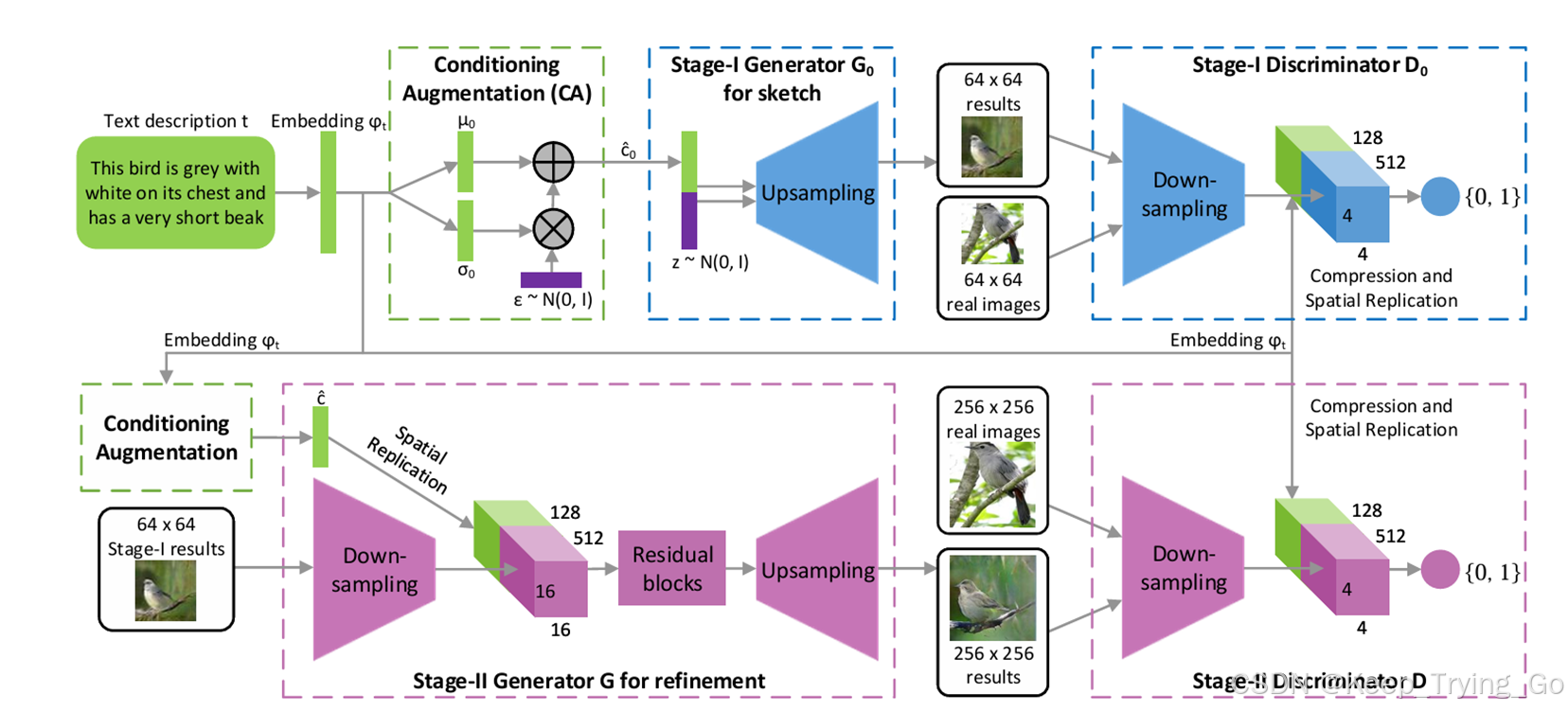
Stage-I GAN


Stage-II GAN


Conditioning Augmentation
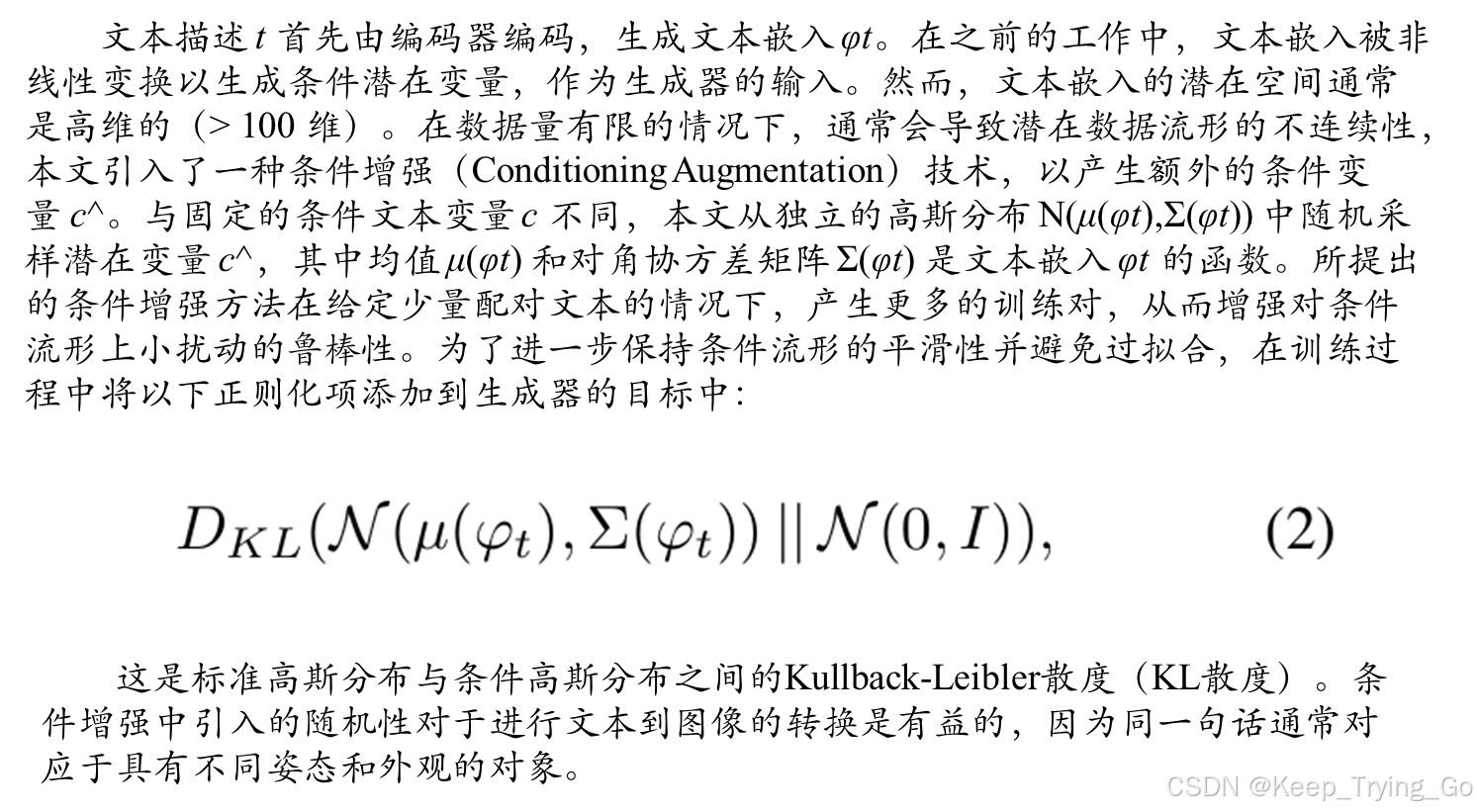
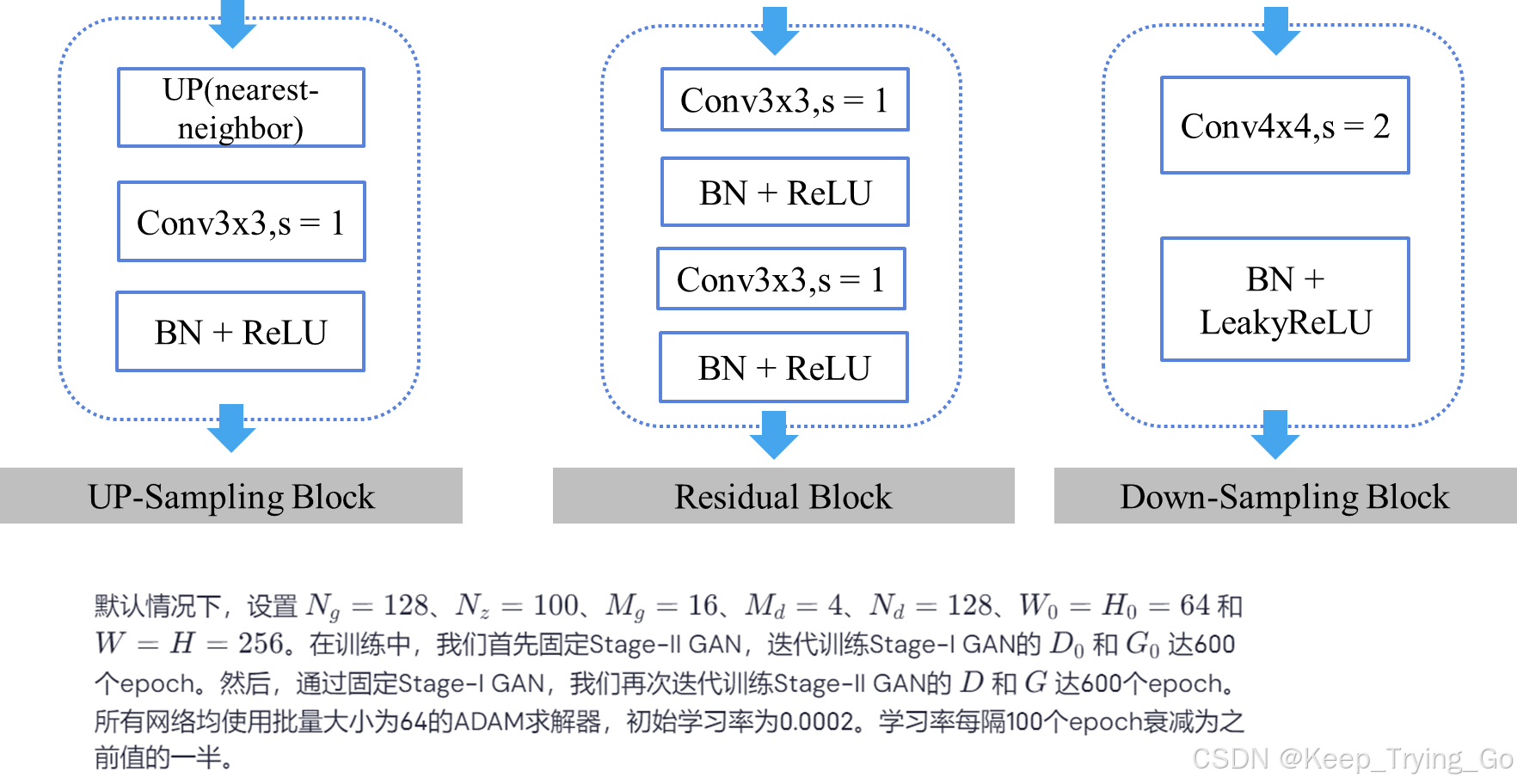
算法实现
class condEmbedding(nn.Module):
def __init__(self, noise_dim, emb_dim):
super(condEmbedding, self).__init__()
self.noise_dim = noise_dim
self.emb_dim = emb_dim
self.linear = nn.Linear(noise_dim, emb_dim*2)
self.relu = nn.LeakyReLU(0.2, inplace=True)
def sample_encoded_context(self, mean, logsigma, kl_loss=False):
# epsilon = Variable(torch.cuda.FloatTensor(mean.size()).normal_())
# print('epsion.size: {}'.format(epsilon.size())) # torch.Size([1, 128])
stddev = logsigma.exp()
epsilon = torch.FloatTensor(mean.size()).normal_().to(mean.device)
# print('epsion.size: {}'.format(epsilon.size()))
return epsilon.mul(stddev).add_(mean)
def forward(self, inputs, kl_loss=True):
'''
inputs: (B, dim)
return: mean (B, dim), logsigma (B, dim)
'''
out = self.relu(self.linear(inputs))
mean = out[:, :self.emb_dim]
log_sigma = out[:, self.emb_dim:]
c = self.sample_encoded_context(mean, log_sigma)
return c, mean, log_sigma实验部分


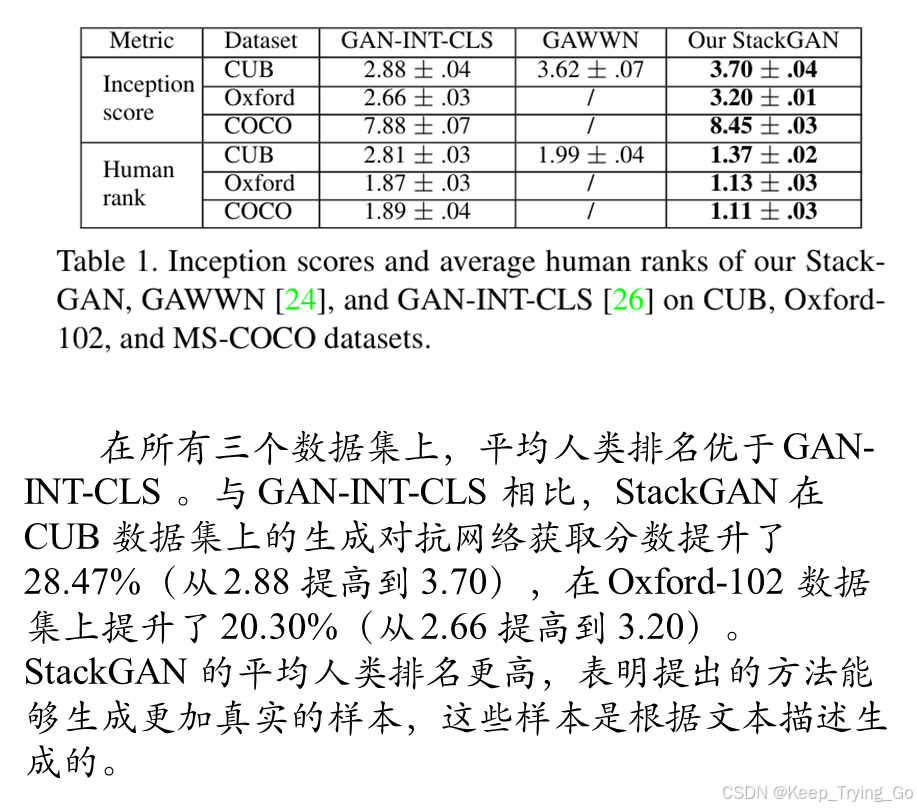




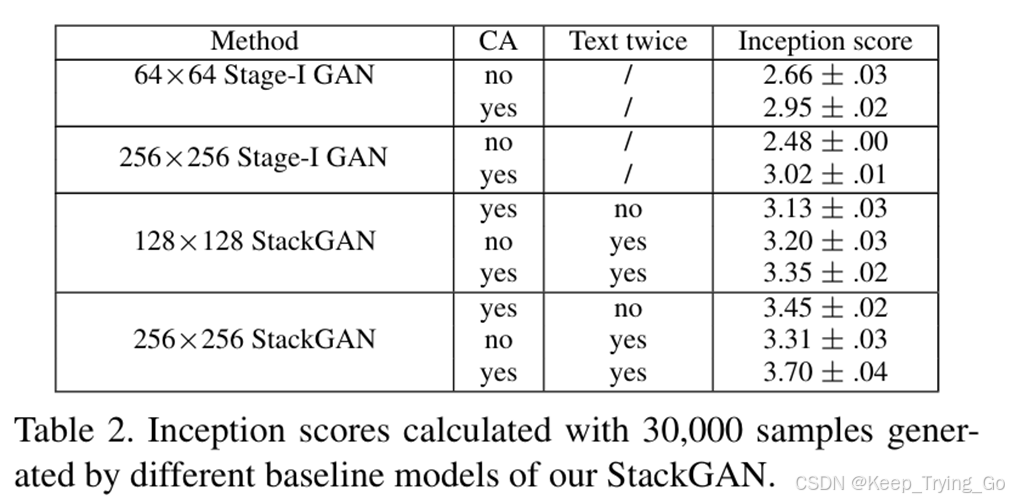
训练和测试
https://mydreamambitious.blog.csdn.net/article/details/144683705(数据集介绍和下载)
通过百度网盘分享的文件:char-CNN-RNN
链接:https://pan.baidu.com/s/1a-5cJIiyHlAxtG2FmuRXhQ
提取码:0l8p



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









