







代码下载地址:https://github.com/KeepTryingTo/DeepLearning/tree/main/Text2Image/RATLIP-main
论文下载链接:https://arxiv.org/pdf/2405.08114v1.pdf
目录
循环仿射变换(Recurrent Affine Transformations)
文本遗忘抑制( Suppression of Text forgetting )
各位小伙伴,在看本文之前建议先看一下 论文GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis详解(代码详解)因为RATLIP是在GALIP的基础上进行改进的。

提出目的和方法
提出目的
使用文本描述作为条件合成高质量的照片级图像非常具有挑战性。生成对抗网络(GANs)是该任务的经典模型,但通常会遭遇图像与文本描述之间的一致性低以及合成图像的丰富性不足等问题。最近,条件仿射变换(CAT),例如条件批量归一化和实例归一化,已应用于GAN的不同层,以控制图像中的内容合成。CAT是一个多层感知器,能够基于相邻层之间的批量统计独立预测数据,且缺少向其他层提供的全局文本信息。
提出方法
为了解决以上问题,首先建模CAT和递归神经网络(RAT),以确保不同层可以访问全局信息。在RAT之间引入随机注意力,以减轻递归神经网络中信息遗忘的特征。此外,生成器和判别器都利用了强大的预训练模型Clip,该模型已广泛应用于通过学习多模态表示来建立文本与图像之间的关系。判别器利用CLIP的能力来理解复杂场景,从而准确评估生成图像的质量。
整体模型架构
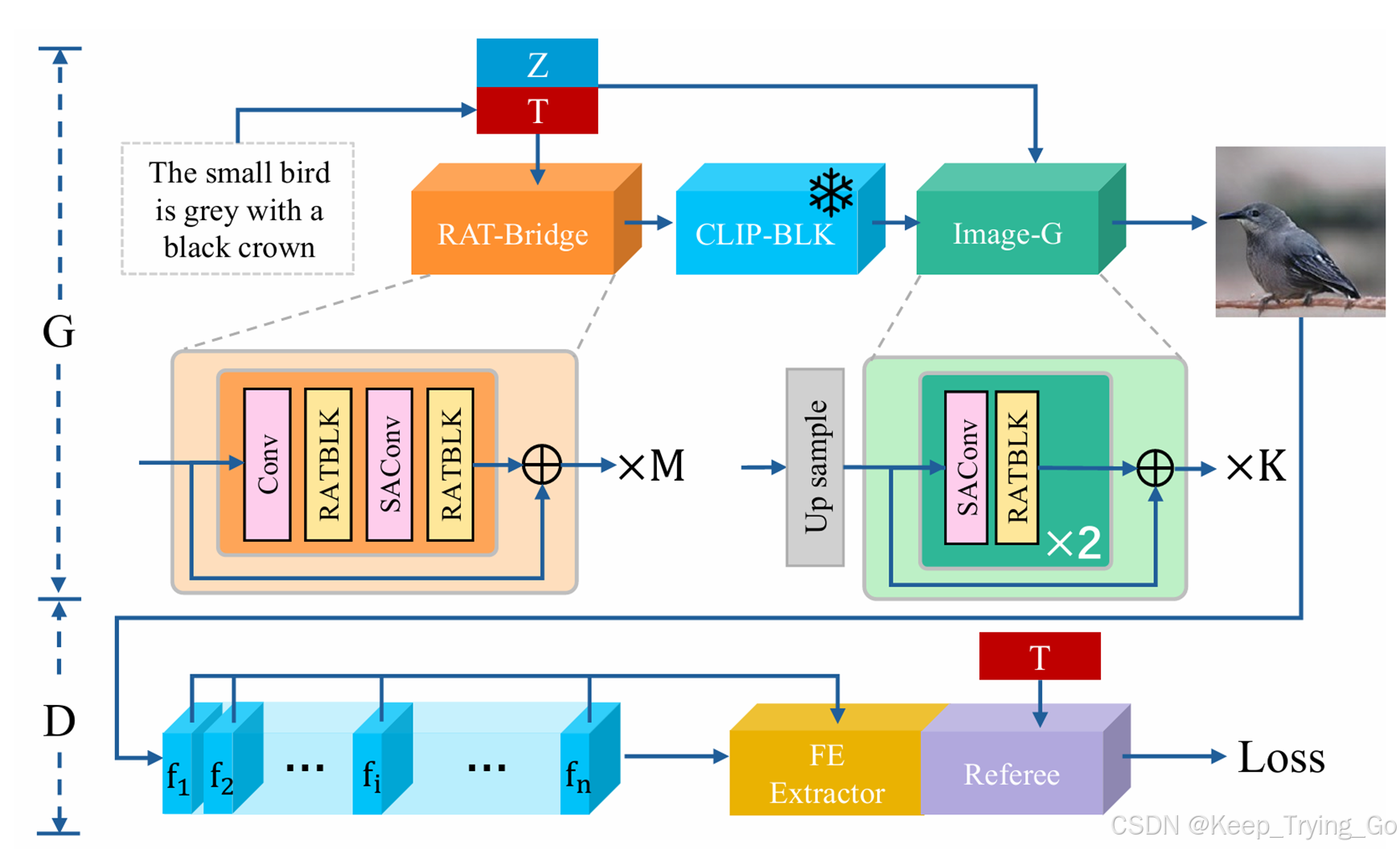
在生成器中,预训练的 CLIP 文本编码器将输入的文本描述编码为句子向量 T 。噪声向量 Z 是从高斯分布中采样的,以便在合成内容中引入更多的多样性。首先,将向量 T 和 Z 输入到 RAT 桥接(RAT Bridge),其中包含 RAT 块(RATBLKs),并且每两个 RATBLK 关联一个卷积模块(SAConv),该模块使用了 Shuffle Attention。RAT 桥接将输入向量转换为符合冻结的 CLIP-ViT 特征值 F 的桥接特征,并将其传递到 CLIP-BLK。最后,图像生成器(image-G)从向量 T、Z 和来自 CLIP-BLK 的桥接特征 F 合成高质量图像。
鉴别器基于冻结的 CLIP-ViT,并包含一个配对鉴别器(Mate-D)。CLIP-ViT 在 CLIP-BLK 中通过卷积层和一系列转换器块将图像转换为图像特征。Mate-D 包含两个块,其中黄色的块是特征提取器(FE Extractor),紫色的块是裁判(Referee),如图所示。特征提取器从 CLIP-BLK 收集桥接特征 F。裁判根据 F 和句子向量 T 预测对抗损失。通过区分合成图像和真实图像,鉴别器帮助生成器合成更高质量的图像。
循环仿射变换(Recurrent Affine Transformations)
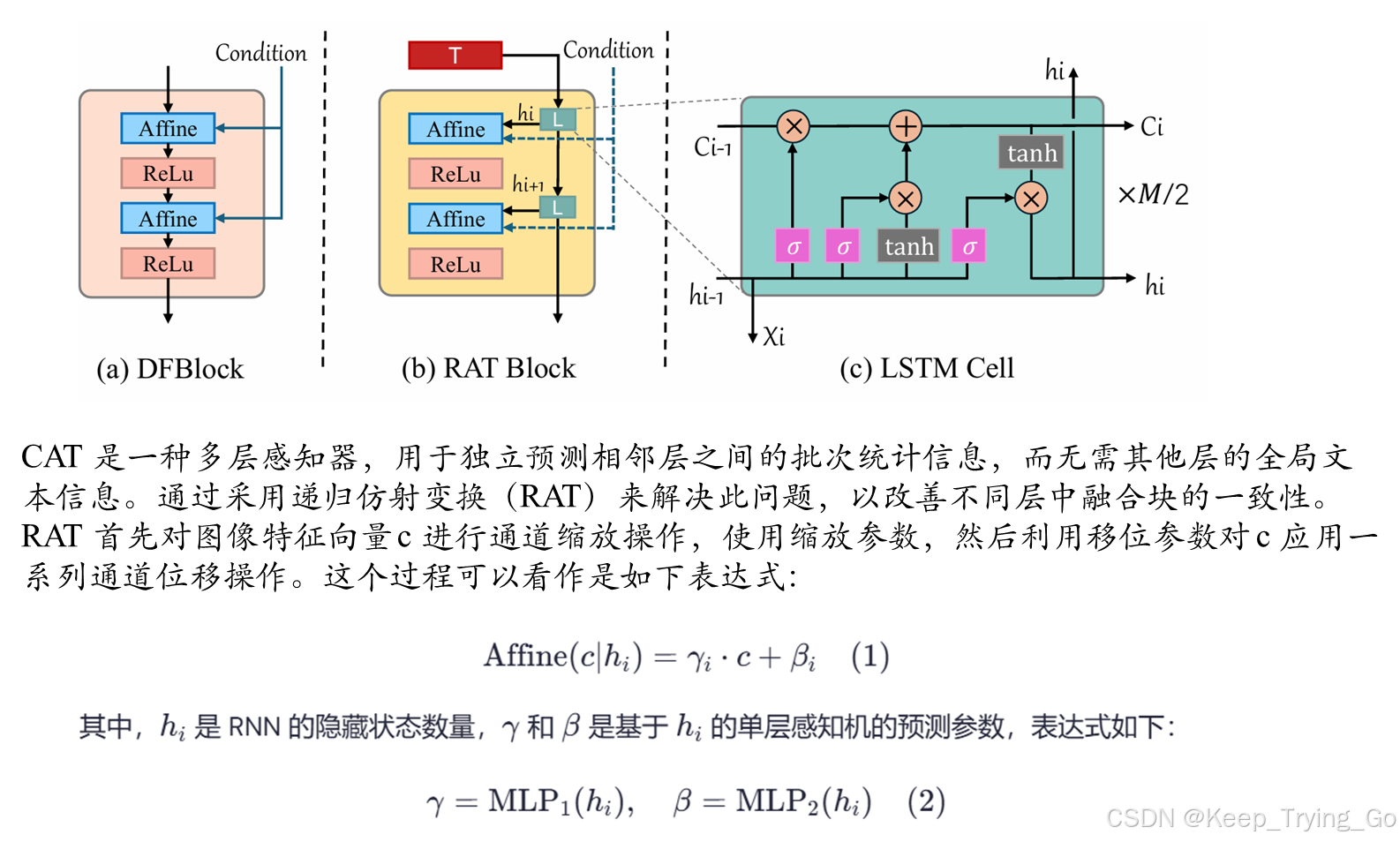
图 2-a 描绘了基线中的文本融合模块 DFBlock。“条件”表示多层感知器的条件仿射变换结构(CAT),它通过学习返回两个预测参数。图 2-b 说明了设计的 RAT 块,在结构上展现出明显的优势。通过利用图 2-c 中的 LSTM 单元进行跳跃连接和权重贡献,融合块之间的文本信息保持一致,而不需要相同的 DFBlock 来基于批次统计进行文本融合。这显著增强了文本融合的程度。

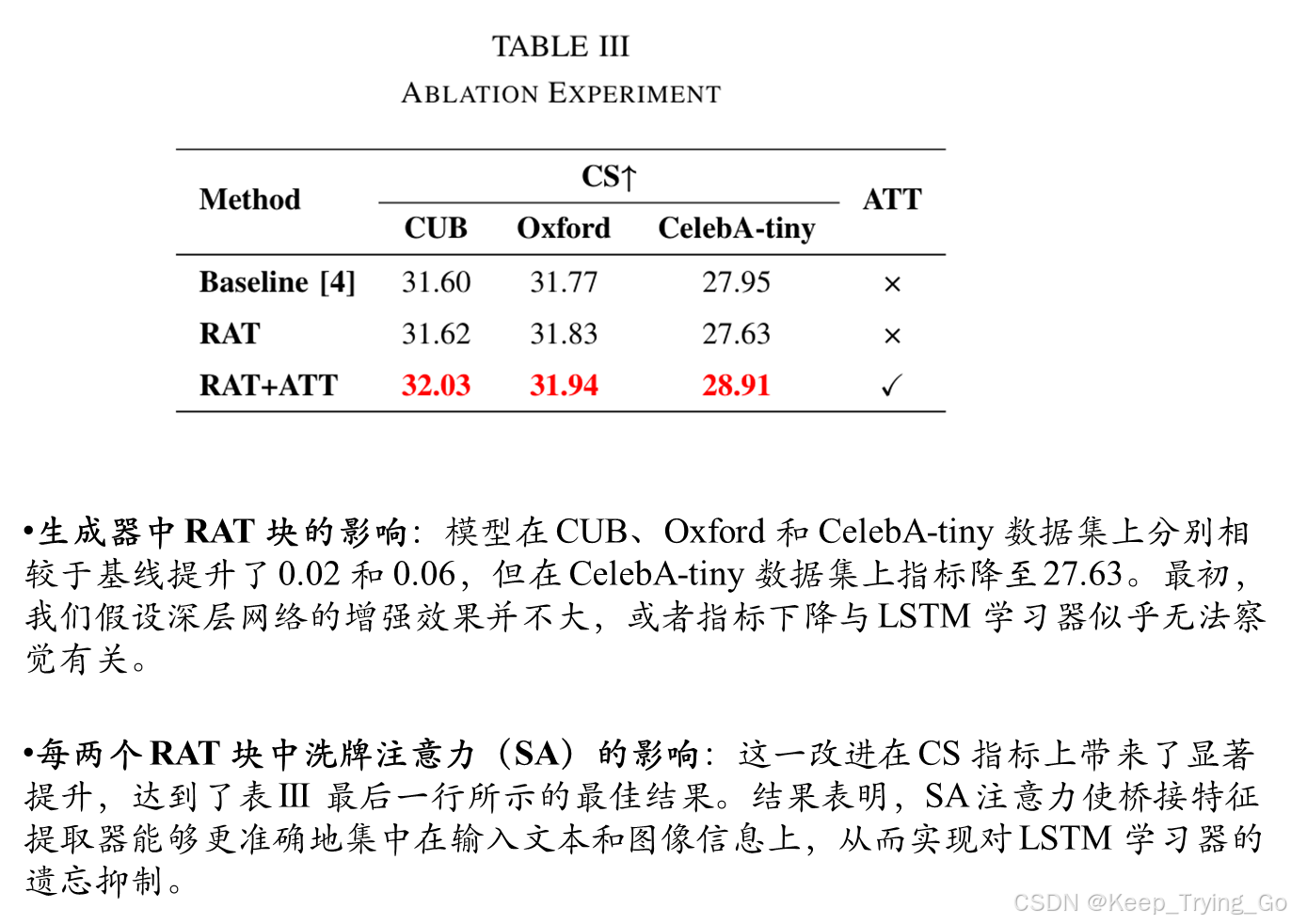
文本遗忘抑制( Suppression of Text forgetting )
根据 LSTM 在长期学习中容易丢失信息的特性,引入了在两个 RAT 块之间的打散注意力(SA),旨在增强文本与上下文的记忆并减缓信息的遗忘。
卷积块注意力模块(CBAM)旨在捕捉像素级的对偶关系和通道依赖性。空间和通道注意力旨在获得最佳结果,但不可避免地会给模型带来显著的计算负担。打散注意力(SA)可以更好地解决这个问题。打散注意力(SA)采用了一种洗牌规则,将传入的参数进行合理分组。这种交互操作打散了空间和通道信息,计算出的组随后被重新融合,从而形成丰富的信息表示。
如图 1 所示,RAT-Bridge 的内部结构。由于每个 LSTM 单元存储 64 个隐藏层,因此网络的较深层可能会在梯度下降过程中丢失部分参数。这一现象被称为“生物遗忘”。本文在第一个 RATBLK 之后添加了打散注意力(SA),以便让信息首先通过学习者,然后再集中注意力。这种方法类似于生物学中的行为学习:首先进行学习(RATBLK 学习),然后进行复习(打散注意力),以这种方式迭代,以维持长期稳定的知识转移。让模型能够减轻文本信息的遗忘。
损失函数

实验部分
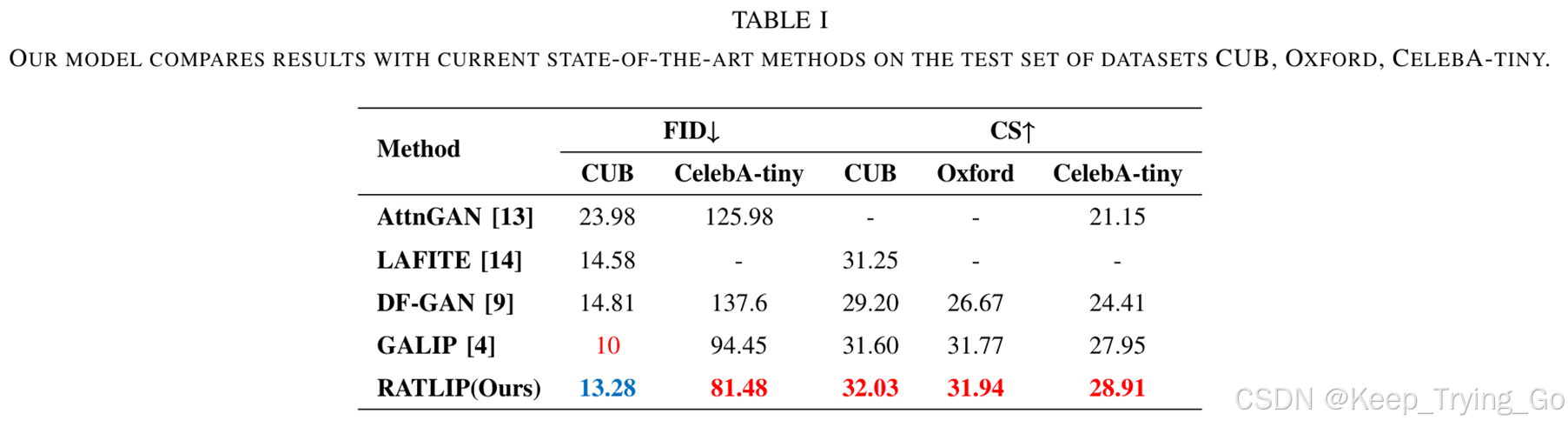
比较实验。将其与几种当前最先进的方法进行了比较。结果见表 I。在 FID 指标下,CeleA-tiny 排名第一,而 CUB 排名第二(较低的 d 分数表示更高的排名)。CeleA-tiny 实现了最先进的(SOTA)性能。在 CS 指标下,所有三个数据集的得分相比于第二名的得分提高了大约 0.78 到 0.96。

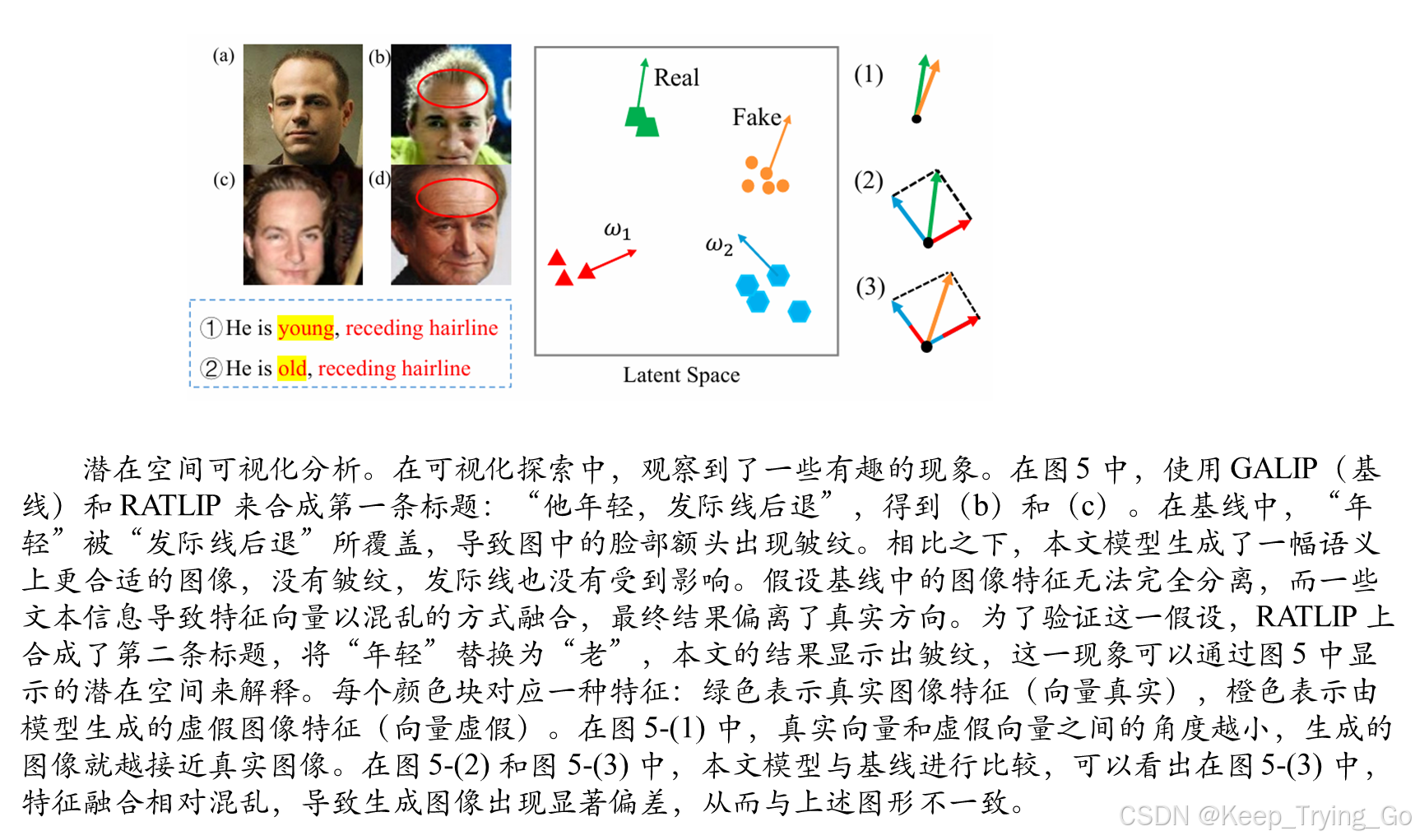
参数分析。LSTM 单元具有隐藏层 hi。值过高或过低都会对模型产生负面影响。因此,进行了参数分析实验,以探讨 h=0,4,8,16,32,64,128对模型参数总数和 CS 值的影响。在表 II 中,模型结果以红色突出显示。随着网络层数的增加,CS 分数呈上升趋势,但同时计算的参数数量迅速增加。为了选择合适的 h 值,我们使用了 Grad-CAM [26] 来可视化合成的照片,如图 3 所示。注意,显著特征区域以红色表示。从图中可以看到,从 h=0到 h=32,红色区域分布在目标的各个区域,要么不是集中在目标上,要么偏离主体,无法很好覆盖目标,而在 h=64时,红色区域完全覆盖了目标,并且在 h=128 时也一样,但覆盖的区域更大。综上所述,可以暂时得出结论,最理想的隐藏层数量是 h=64。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









