







 本文介绍了如何使用Python自动化获取华图和粉笔网站的错题。针对粉笔,需要通过抓包获取题目和解析数据,利用requests和headers请求数据,将图片数据转换为PDF。华图网站则可以直接抓包获取数据,数据解析后存储为word文档。总结了两者在爬取和解析上的区别。
本文介绍了如何使用Python自动化获取华图和粉笔网站的错题。针对粉笔,需要通过抓包获取题目和解析数据,利用requests和headers请求数据,将图片数据转换为PDF。华图网站则可以直接抓包获取数据,数据解析后存储为word文档。总结了两者在爬取和解析上的区别。
这篇博客对于考公人或者其他用华图或者粉笔做题的人比较友好,通过输入网址可以自动化获取华图以及粉笔练习的错题。
粉笔网站
我们从做过的题目组中获取错题
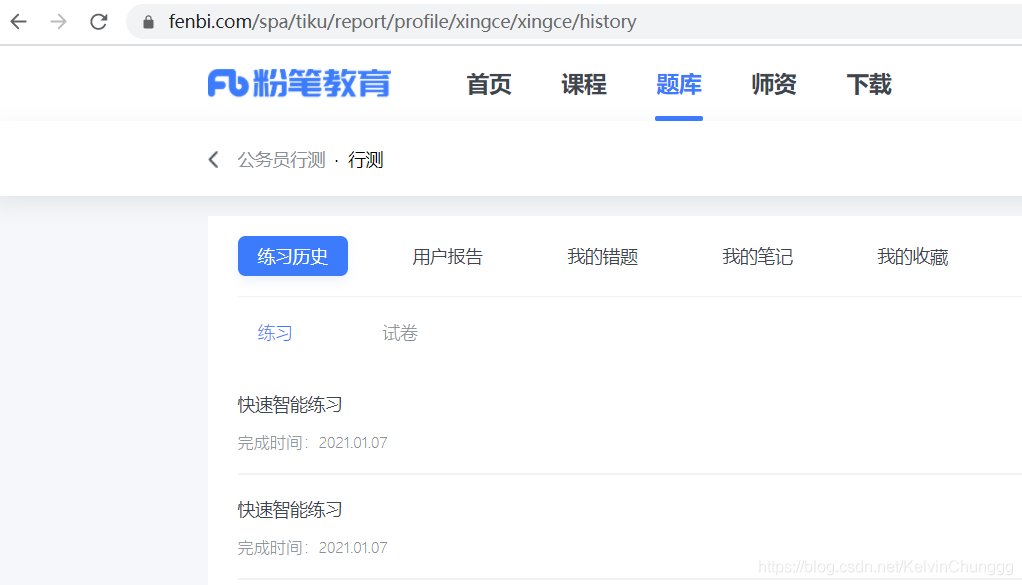
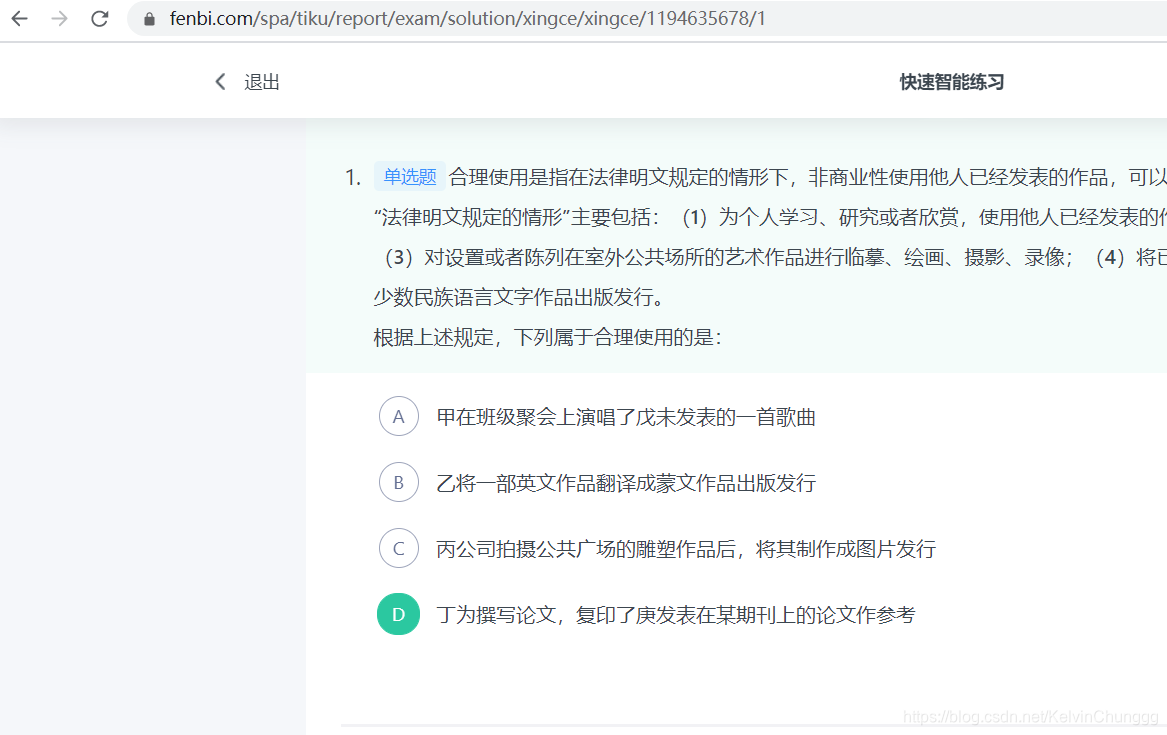
打开某一次做题组,我们首先进行抓包看看数据在哪里

我们发现现在数据已经被隐藏,事实上数据在这两个包中:
https://tiku.fenbi.com/api/xingce/questions
https://tiku.fenbi.com/api/xingce/solutions
一个为题目的一个为解析的。此url要通过传入一个题目组参数才能获取到当前题目数据,而题目组参数在这个包中
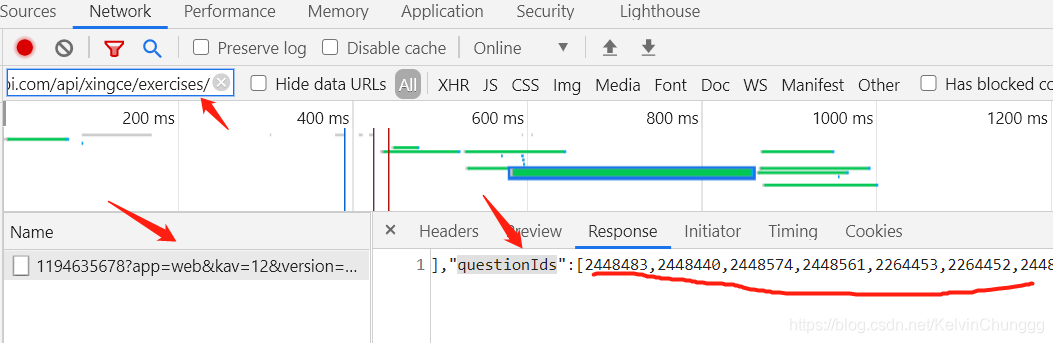
以网址的倒数第二个数字串有关

url的规则为'https://tiku.fenbi.com/api/xingce/exercises/'+str(id_)+'?app=web&kav=12&version=3.0.0.0',id_即为下划线数字
通过请求这个包获取到参数然后通过参数请求上面两个包(
https://tiku.fenbi.com/api/xingce/questions
https://tiku.fenbi.com/api/xingce/solutions
)即可获取到题目数据,而且自己的答案在也在https://tiku.fenbi.com/api/xingce/exercises/'+str(id_)+'?app=web&kav=12&version=3.0.0.0这个包中。
不过粉笔的题目数据有些是图片,而且图片在题目中,选项中,这里以word文档存储操作docx库有些吃力,于是我想到了直接构造HTML代码,然后通过pdfkit转为pdf(具体如何下载可以参考百度,要下载wkhtmltopdf.exe)即可变为错题集在平板或者其他设备中看。
(请求时一定要携带完整的headers,否则很可能获取不到数据)
具体操作看代码解析
###此函数用于解析题目和每道题的答案
def jiexi(liebiao):
new = []
timu_last = []
for each in liebiao:
new.append(re.sub(r'flag=\\"tex\\" ','',each))
for each in new:
timu_last.append(re.sub(r'\\','',each))
return timu_last
###此函数用于解析选项
def xuanxiang(liebiao):
xuanxiang_v2 = []
xuanxiang_v3 = []
for each in liebiao:
a = re.sub('<p>','',each)
a = re.sub('</p>','',a)
xuanxiang_v2.append(a)
for each in xuanxiang_v2:
each = each+'</p>'
xuanxiang_v3.append(each)
return xuanxiang_v3
import requests
import re
import pdfkit
import os
url = str(input("请输入练习的网址:"))
###获取本节练习id
id_ = re.findall(r'https://www.fenbi.com/spa/tiku.*?/xingce/xingce/(.*?)/',url,re.S)[0]
mid_url = 'https://tiku.fenbi.com/api/xingce/exercises/'+str(id_)+'?app=web&kav=12&version=3.0.0.0'
headers = {
#####完整的headers,自己添加
}
response = requests.get(url=mid_url,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
###获取题目组参数
id_list = re.findall('\"questionIds\"\:\[(.*?)\]\,',page_text,re.S)
###获取自己的答案
your_answer = re.findall(r'"answer":{"choice":"(.*?)",',page_text,re.S)
###此练习名称
name = re.findall(r'"name":"(.*?)",',page_text,re.S)[0]
###真正存储数据的包
timu_url = 'https://tiku.fenbi.com/api/xingce/questions'
params = {
'ids': id_list
}
response = requests.get(url=timu_url,headers=headers,params=params)
response.encoding = 'utf-8'
page_text = response.text
###获取正确答案
true_answer = re.findall('"correctAnswer":{"choice":"(.*?)"',page_text,re.S)
###真正存储数据的包
solution_url = 'https://tiku.fenbi.com/api/xingce/solutions'
response = requests.get(url=solution_url,headers=headers,params=params)
response.encoding = 'utf-8'
page_text = response.text
###获取解析
solution_list = re.findall(r'"solution":"(.*?)","userAnswer"',page_text,re.S)
solution_last = jiexi(solution_list)
cailiao = []
timu = []
###获取单选题题目和复合题的题目
for each in response.json():
timu.append(each['content'])
try:
cailiao.append(each['material']['content'])
except:
cailiao.append('none')
###获取选项信息
A_option = re.findall('\"options\"\:\[\"(.*?)\"\,\".*?\"\,\".*?\"\,\".*?\"\]',page_text,re.S)
B_option = re.findall('\"options\"\:\[\".*?\"\,\"(.*?)\"\,\".*?\"\,\".*?\"\]',page_text,re.S)
C_option = re.findall('\"options\"\:\[\".*?\"\,\".*?\"\,\"(.*?)\"\,\".*?\"\]',page_text,re.S)
D_opti 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









