






转载地址:MindSpore21天实战营(2):基于BERT实现中文新闻分类实战_MindSpore_昇腾论坛_华为云论坛
作者:胡琦
“ModelArts + MindSpore”实战BERT中文新闻分类
Copy攻城狮人狠话不多,学AI就到huaweicloud.ai,和“MM”一起玩转AI。
前言
大家好,我是Copy攻城狮胡琦,有幸参与华为业界首个全场景AI实战营。今天是MIndSpore 21天实战营的第二次课,光接触的名词就已经碉堡了--一站式AI开发平台ModelArts、全栈全场景AI计算框架MindSpore、昇腾Ascend 910 8卡服务器、最强NLP模型BERT,优秀的她们组合在一起会有怎样的化学反应?关于BERT,本大狮有幸尝试过基于TensorFlow的实现--【手模手学ModelArts】分分钟部署一个Bert命名实体识别在线服务,并尝试以该服务为原型“落地AI”--【Copy攻城狮日志】ModelArts与AppCube双“魔”合璧庆双节,从0到1实现了一个简单的命名实体识别应用。这次,我们将基于MIndSpore实现中文新闻分类实战。
准备
本次实战基于一站式AI开发平台ModelArts,使用昇腾Ascend 910环境,搭载MIndSpore-0.5-python3.7-aarch64。
依旧感谢小助手的暖心提示,另外有看到小伙伴问优惠券哪里领,建议关注MIndSpore官方微信及ModelArts官网。
1️⃣ 环境准备(本次实验不涉及使用到本地环境):
准备项目:华为云账号和昇腾集群公测资格
步骤:
❶ 华为云账号注册(地址: https://www.huaweicloud.com/)。
❷ 按照操作指引完成账号注册,账号注册完成后,进入到ModelArts界面,进行昇腾集群公测资格的申请。(地址: https://www.huaweicloud.com/product/modelarts.html)。
❸ 按照指引完成公测资格申请。
❹ 要完成公测资格申请,需要完成两步,实名认证和访问授权,其中实名认证需要各位学员使用自己的身份证号码和姓名完成认证,认证的审核需要一定的时间,约为1天左右。
❺ 访问授权的则直接点击右下方的“自动创建”按钮,其他的默认即可。
❻ 在弹出的界面当中点击“立即申请”按钮。
❼ 之后可以查看自己的审批状态。“审批通过”则代表已经取得了公测资格。
2️⃣ 知识准备:
Python相关知识:
参考链接:https://www.liaoxuefeng.com/wiki/1016959663602400/1017063413904832
bert论文:https://arxiv.org/abs/1810.04805
3️⃣ 数据集和代码:
中文维基数据集:https://dumps.wikimedia.org/zhwiki/
数据集提取:https://github.com/attardi/wikiextractor
BERT预训练模型: http://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
tnews数据集: https://storage.googleapis.com/cluebenchmark/tasks/tnews_public.zip
代码:https://21days-bert.obs.cn-north-4.myhuaweicloud.com/bert.zip
BERT官方仓库: https://github.com/google-research/bert
MindSpore提供的bert_base.ckpt:https://21days-bert.obs.cn-north-4.myhuaweicloud.com/bert_base.ckpt?AccessKeyId=M7KX8KLMT0ZL1P8QWXZ5&Expires=1634522231&Signature=1CSNQY%2BK%2BmQxRBkqBwBHMbf0%2BE4%3D
数据处理
本次数据处理基于ModelArts的我的笔记本实现,不得不夸赞一下我的笔记本--即开即用、用于机器学习的在线集成开发环境,可以轻松的构建、训练、调试、部署机器学习算法与模型。无论是CPU环境还是GPU环境,一键切换,且仍然保留工作空间的文件,用来处理数据也是非常便捷。本次实践采用MindSpore 21天实战营提供的处理之后的tnews数据集。
中文wiki数据集提取
我们下载的中文维基数据集是.bz2后缀的文件,需要进行转换,这里用到的工具是wikiextractor,WikiExtractor.py是一个Python脚本,可从Wikipedia数据库转储中提取和清除文本。这里使用pip安装,在我的笔记本中新建.ipynb文件执行:
!pip install wikiextractor
!python -m wikiextractor.WikiExtractor zhwiki-latest-pages-articles.xml.bz2 -o tnews-pre --log_file wiki.log可运行!python -m wikiextractor.WikiExtractor查看具体参数,我这里将数据提取到tnew-pre文件夹,由于数据比较庞大,提取比较耗时,我开了8U+64GiB的环境,CPU基本跑到80%,大概20分钟左右。
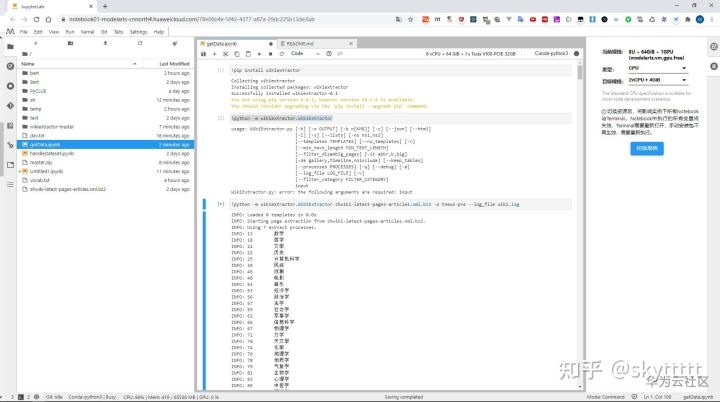
提取完毕会生成形如AA/wiki_00的文件,里面的内容包裹在doc中。
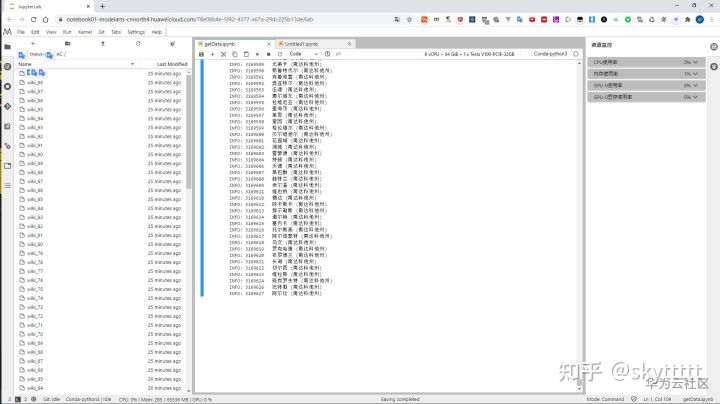
转换数据集格式
此次实践在MindSpore中使用的是tfrecord的格式,同时为数据集添加词表处理,这里就需要用到BERT预训练模型中的中文语义表文件==vocab.txt,整个过程通过BERT提供的脚本create_pretraining_data.py实现。这里我思考了一下,从数据集中抽取了20条,以8:2的比例拆分生成train.tf_record和dev.tf_record,不知道逻辑和流程对不对。
生成tfrecord格式:
python bert/create_pretraining_data.py \
--input_file=text/AN/wiki_72,text/AC/wiki_68,text/AK/wiki_02,text/AD/wiki_78,text/AE/wiki_77,text/AG/wiki_71,text/AN/wiki_90,text/AO/wiki_21,text/AI/wiki_19,text/AK/wiki_77,text/AM/wiki_00,text/AA/wiki_76,text/AH/wiki_63,text/AF/wiki_21,text/AJ/wiki_55,text/AG/wiki_19 \
--output_file=temp/train.tf_record \
--vocab_file=vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
python bert/create_pretraining_data.py \
--input_file=text/AA/wiki_77,text/AL/wiki_48,text/AB/wiki_44,text/AJ/wiki_62 \
--output_file=temp/dev.tf_record \
--vocab_file=vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5这里值得注意的是,当我下载完bert源码时,通过pip去安装依赖,默认装的TensorFlow是2.x的版本,需要重新安装1.x的版本,不然在进行tfrecord格式生成时会报错TensorFlow 2.x下没有某些特定的API,这应该是bert/create_pretraining_data.py这个脚本本身使用的是低版本的TensorFlow。数据格式转换结果如下:
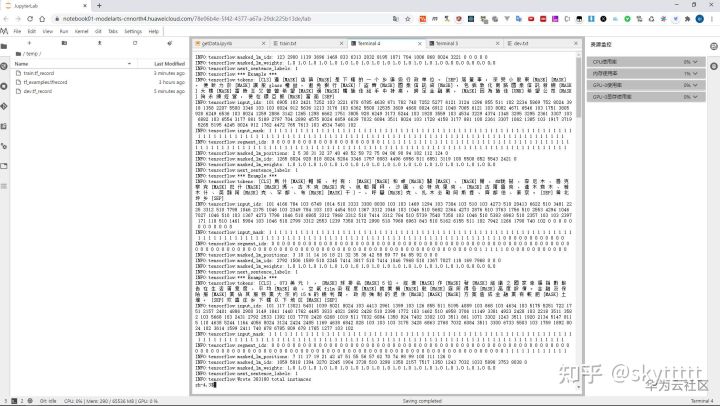
转换完毕,我们还能通过Moxing将文件直接上传到OBS:
import moxing as mox
mox.file.copy_parallel('train.tf_record','obs://huqi88/mindspore-camp/BERT-new/dataset/tnews/train.tf_record')
mox.file.copy_parallel('dev.tf_record','obs://huqi88/mindspore-camp/BERT-new/dataset/tnews/dev.tf_record')BERT fine-tune
首先我们将代码、数据集、预训练模型按照如下位置上传到OBS:
├─bert // MindSpore提供的BERT代码
│ ├─scripts
│ └─src
│ └─vocab.txt
│ └─bert_base.ckpt
| └─src
└─dataset // 处理完毕的数据集
│ └─tnews
│ └─├─dev.tf_record
│ └─├─train.tf_record鉴于近期ModelArts训练作业中用到的昇腾910资源比较火爆,本次实践转用ModelArts的notebook中的Ascend资源,因此我们需要在开发环境中新建一个Ascend 910的notebook。
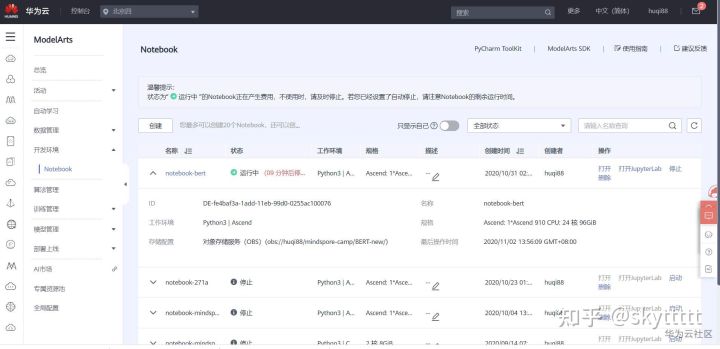
在使用Ascend环境的时候,我们的文件是挂载在OBS中的,因此在新建环境的时候,我们要注意OBS的路径,我这边直接选择的是包含代码、预训练模型文件以及数据集的最外层文件夹目录,同时还需要在notebook的文件界面点击Sync OBS将环境中的文件和OBS中的文件进行同步。
我们在bert代码的目录下新建finetune.ipynb,编写finetune的代码。当然,这里值得注意的是,如果基于实战营的源代码来运行的话,需要简单修改一些配置。比如bert/src/finetune_config.py中我们需要修改一些文件路径的参数。
我的finetune.ipynb如下,其实是复制的finetube.py,简单修改下配置:
import os,sys
source_file_path = os.environ['HOME'] + '/work/' + 'bert' + '/'
os.chdir(source_file_path)
print(source_file_path)
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
'''
Bert finetune script.
'''
import os
import sys
import argparse
from src.utils import BertFinetuneCell, BertCLS, BertNER, BertSquad, BertSquadCell
from src.finetune_config import cfg, bert_net_cfg, tag_to_index
import mindspore.common.dtype as mstype
from mindspore import context
from mindspore import log as logger
import mindspore.dataset as de
import mindspore.dataset.transforms.c_transforms as C
from mindspore.nn.wrap.loss_scale import DynamicLossScaleUpdateCell
from mindspore.nn.optim import AdamWeightDecayDynamicLR, Lamb, Momentum
from mindspore.train.model import Model
from mindspore.train.callback import Callback
from mindspore.train.callback import CheckpointConfig, ModelCheckpoint
from mindspore.train.serialization import load_checkpoint, load_param_into_net
import moxing as mox
os.environ['MINDSPORE_HCCL_CONFIG_PATH'] = os.getenv('RANK_TABLE_FILE')
job_id = os.getenv('JOB_ID')
job_id = job_id if job_id != "" else "default"
device_id = int(os.getenv('DEVICE_ID'))
device_num = int(os.getenv('RANK_SIZE'))
# global_rank_id = int(os.getenv('RANK_ID').split('-')[-1])
global_rank_id = 2
rank_id = device_id + global_rank_id * 8
class LossCallBack(Callback):
'''
Monitor the loss in training.
If the loss is NAN or INF, terminate training.
Note:
If per_print_times is 0, do not print loss.
Args:
per_print_times (int): Print loss every times. Default: 1.
'''
def __init__(self, per_print_times=1):
super(LossCallBack, self).__init__()
if not isinstance(per_print_times, int) or per_print_times < 0:
raise ValueError("print_step must be in and >= 0.")
self._per_print_times = per_print_times
def step_end(self, run_context):
cb_params = run_context.original_args()
with open("./loss.log", "a+") as f:
print("epoch: {}, step: {}, outputs are {}".format(cb_params.cur_epoch_num, cb_params.cur_step_num,
str(cb_params.net_outputs)))
def get_dataset(batch_size=1, repeat_count=1, distribute_file=''):
'''
get dataset
'''
ds = de.TFRecordDataset([cfg.data_file], cfg.schema_file, columns_list=["input_ids", "input_mask",
"segment_ids", "label_ids"])
type_cast_op = C.TypeCast(mstype.int32)
ds = ds.map(input_columns="segment_ids", operations=type_cast_op)
ds = ds.map(input_columns="input_mask", operations=type_cast_op)
ds = ds.map(input_columns="input_ids", operations=type_cast_op)
ds = ds.map(input_columns="label_ids", operations=type_cast_op)
ds = ds.repeat(repeat_count)
# apply shuffle operation
buffer_size = 960
ds = ds.shuffle(buffer_size=buffer_size)
# apply batch operations
ds = ds.batch(batch_size, drop_remainder=True)
return ds
def get_squad_dataset(batch_size=1, repeat_count=1, distribute_file=''):
'''
get SQuAD dataset
'''
ds = de.TFRecordDataset([cfg.data_file], cfg.schema_file, columns_list=["input_ids", "input_mask", "segment_ids",
"start_positions", "end_positions",
"unique_ids", "is_impossible"])
type_cast_op = C.TypeCast(mstype.int32)
ds = ds.map(input_columns="segment_ids", operations=type_cast_op)
ds = ds.map(input_columns="input_ids", operations=type_cast_op)
ds = ds.map(input_columns="input_mask", operations=type_cast_op)
ds = ds.map(input_columns="start_positions", operations=type_cast_op)
ds = ds.map(input_columns="end_positions", operations=type_cast_op)
ds = ds.repeat(repeat_count)
buffer_size = 960
ds = ds.shuffle(buffer_size=buffer_size)
ds = ds.batch(batch_size, drop_remainder=True)
return ds
def sync_dataset(data_url):
import moxing as mox
import sys
import time
sync_lock = "/tmp/copy_sync.lock"
if device_id % min(device_num, 8) == 0 and not os.path.exists(sync_lock):
mox.file.copy_parallel(data_url, "dataset/")
print("===finish download datasets===")
try:
os.mknod(sync_lock)
except:
pass
print("===save flag===")
while True:
if os.path.exists(sync_lock):
break
time.sleep(1)
def test_train():
'''
finetune function
'''
target = device_target
if target == "Ascend":
devid = int(os.getenv('DEVICE_ID'))
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", device_id=devid)
elif target == "GPU":
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
if bert_net_cfg.compute_type != mstype.float32:
logger.warning('GPU only support fp32 temporarily, run with fp32.')
bert_net_cfg.compute_type = mstype.float32
else:
raise Exception("Target error, GPU or Ascend is supported.")
#BertCLSTrain for classification
#BertNERTrain for sequence labeling
if cfg.task == 'NER':
if cfg.use_crf:
netwithloss = BertNER(bert_net_cfg, True, num_labels=len(tag_to_index), use_crf=True,
tag_to_index=tag_to_index, dropout_prob=0.1)
else:
netwithloss = BertNER(bert_net_cfg, True, num_labels=cfg.num_labels, dropout_prob=0.1)
elif cfg.task == 'SQUAD':
netwithloss = BertSquad(bert_net_cfg, True, 2, dropout_prob=0.1)
else:
netwithloss = BertCLS(bert_net_cfg, True, num_labels=cfg.num_labels, dropout_prob=0.1)
if cfg.task == 'SQUAD':
dataset = get_squad_dataset(bert_net_cfg.batch_size, cfg.epoch_num)
else:
dataset = get_dataset(bert_net_cfg.batch_size, cfg.epoch_num)
# optimizer
steps_per_epoch = dataset.get_dataset_size()
print("step per epoch: ", steps_per_epoch)
if cfg.optimizer == 'AdamWeightDecayDynamicLR':
optimizer = AdamWeightDecayDynamicLR(netwithloss.trainable_params(),
decay_steps=steps_per_epoch * cfg.epoch_num,
learning_rate=cfg.AdamWeightDecayDynamicLR.learning_rate,
end_learning_rate=cfg.AdamWeightDecayDynamicLR.end_learning_rate,
power=cfg.AdamWeightDecayDynamicLR.power,
warmup_steps=int(steps_per_epoch * cfg.epoch_num * 0.1),
weight_decay=cfg.AdamWeightDecayDynamicLR.weight_decay,
eps=cfg.AdamWeightDecayDynamicLR.eps)
elif cfg.optimizer == 'Lamb':
optimizer = Lamb(netwithloss.trainable_params(), decay_steps=steps_per_epoch * cfg.epoch_num,
start_learning_rate=cfg.Lamb.start_learning_rate, end_learning_rate=cfg.Lamb.end_learning_rate,
power=cfg.Lamb.power, weight_decay=cfg.Lamb.weight_decay,
warmup_steps=int(steps_per_epoch * cfg.epoch_num * 0.1), decay_filter=cfg.Lamb.decay_filter)
elif cfg.optimizer == 'Momentum':
optimizer = Momentum(netwithloss.trainable_params(), learning_rate=cfg.Momentum.learning_rate,
momentum=cfg.Momentum.momentum)
else:
raise Exception("Optimizer not supported.")
# load checkpoint into network
ckpt_config = CheckpointConfig(save_checkpoint_steps=steps_per_epoch, keep_checkpoint_max=1)
ckpoint_cb = ModelCheckpoint(prefix=cfg.ckpt_prefix, directory=cfg.ckpt_dir, config=ckpt_config)
print(cfg.pre_training_ckpt)
param_dict = load_checkpoint('/home/ma-user/work/bert/bert_base.ckpt')
# param_dict = load_checkpoint(cfg.pre_training_ckpt)
load_param_into_net(netwithloss, param_dict)
update_cell = DynamicLossScaleUpdateCell(loss_scale_value=2**32, scale_factor=2, scale_window=1000)
if cfg.task == 'SQUAD':
netwithgrads = BertSquadCell(netwithloss, optimizer=optimizer, scale_update_cell=update_cell)
else:
netwithgrads = BertFinetuneCell(netwithloss, optimizer=optimizer, scale_update_cell=update_cell)
print("start to train.")
model = Model(netwithgrads)
print(cfg.epoch_num, dataset)
model.train(cfg.epoch_num, dataset, callbacks=[LossCallBack(), ckpoint_cb])
parser = argparse.ArgumentParser(description='Bert finetune')
# parser.add_argument('--device_target', type=str, default='Ascend', help='Device target')
# parser.add_argument('--data_url', type=str, default='Ascend', help='data url')
# parser.add_argument('--train_url', type=str, default='Ascend', help='train url')
# args_opt = parser.parse_args()
device_target = 'Ascend'
# predict='侃爷参选'
data_url='obs://huqi88/mindspore-camp/BERT-finetune-new/dataset/tnews/'
train_url='obs://huqi88/mindspore-camp/BERT-notebook'
if __name__ == "__main__":
print("start to run.", sys.argv)
sync_dataset(data_url)
test_train()
if rank_id % device_num == 0:
mox.file.copy_parallel("/home/ma-user/work/train", train_url)执行代码之后,会进行3个epoch的训练,然后将训练得到的tnews-3_3335.ckpt。在我的这次实践中该ckpt文件存放在/home/ma-user/work/train,并且会上传到OBS。
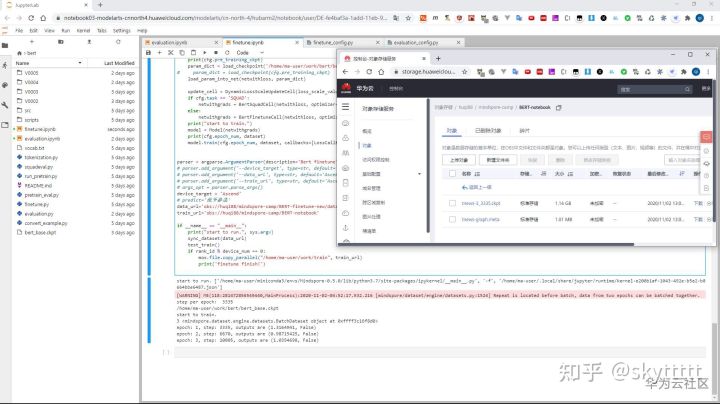
验证
同样的我们把evaluation.py复制过来新建evaluation.ipynb,修改少许代码及evaluation_config配置,即可验证上一步finetune得到的模型。
我的evaluation.ipynb如下,依旧注意的是路径,当然还有predict入参。本次尝试判断侃爷参选,结果是娱乐新闻,还是挺准备的。
import os,sys
source_file_path = os.environ['HOME'] + '/work/' + 'bert' + '/'
os.chdir(source_file_path)
print(source_file_path)
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
"""
Bert evaluation script.
"""
import os
import sys
import argparse
import numpy as np
import mindspore.common.dtype as mstype
from mindspore import context
from mindspore import log as logger
from mindspore.common.tensor import Tensor
import mindspore.dataset as de
import mindspore.dataset.transforms.c_transforms as C
from mindspore.train.model import Model
from mindspore.train.serialization import load_checkpoint, load_param_into_net
from src.evaluation_config import cfg, bert_net_cfg
from src.utils import BertNER, BertCLS, BertCLSModel
from src.CRF import postprocess
#from src.cluener_evaluation import submit
from src.finetune_config import tag_to_index
from convert_example import convert_text
import moxing as mox
# 省略部分代码
parser = argparse.ArgumentParser(description='Bert eval')
# parser.add_argument('--device_target', type=str, default='Ascend', help='Device target')
# parser.add_argument('--data_url', type=str, default='Ascend', help='data url')
# parser.add_argument('--train_url', type=str, default='Ascend', help='train url')
# parser.add_argument('--predict', type=str, default='', help='text to predict')
# args_opt = parser.parse_args()
target = 'Ascend'
predict='侃爷参选'
data_url='obs://huqi88/mindspore-camp/BERT-new/dataset/tnews/'
if __name__ == "__main__":
# target = args_opt.device_target
print(target)
if target == "Ascend":
devid = int(os.getenv('DEVICE_ID'))
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", device_id=devid)
elif target == "GPU":
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
if bert_net_cfg.compute_type != mstype.float32:
logger.warning('GPU only support fp32 temporarily, run with fp32.')
bert_net_cfg.compute_type = mstype.float32
else:
raise Exception("Target error, GPU or Ascend is supported.")
print("start to run.", sys.argv)
num_labels = cfg.num_labels
if predict != '':
test_predict(predict)
else:
sync_dataset(data_url)
test_eval()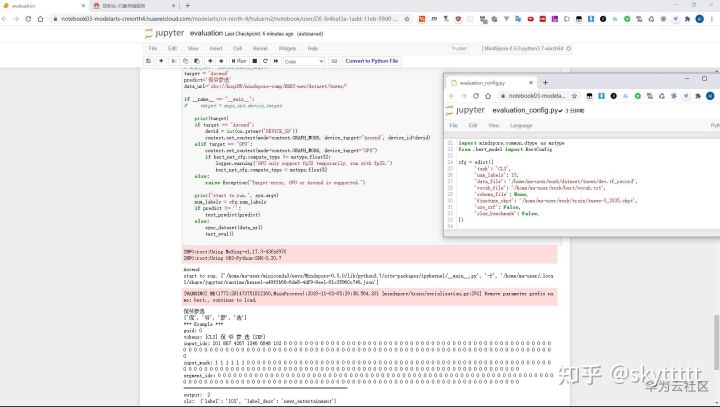
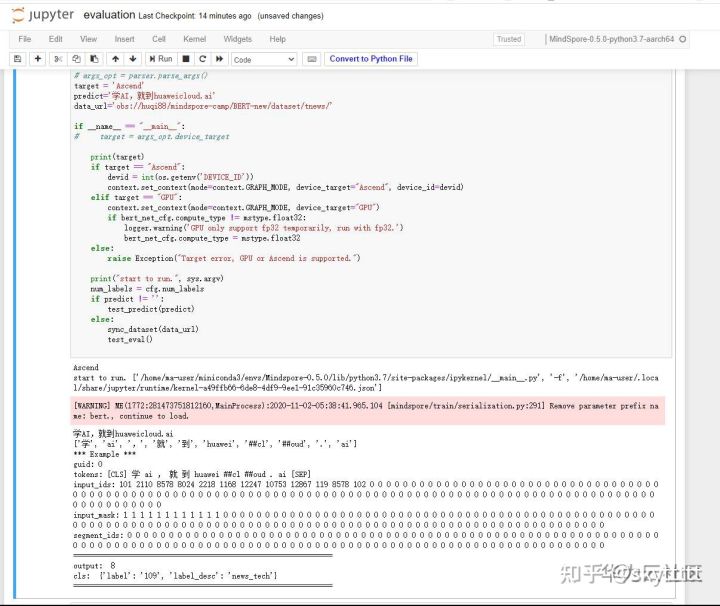
notebook运行Ascend的好处是免排队,而且调试非常方便。比如,再判断一下学AI,就到huaweicloud.ai,我记得在句在训练任务中通过设置参数传递的时候是不允许输入的。在notebook中轻松就能判断出来,不错,就是技术类的!
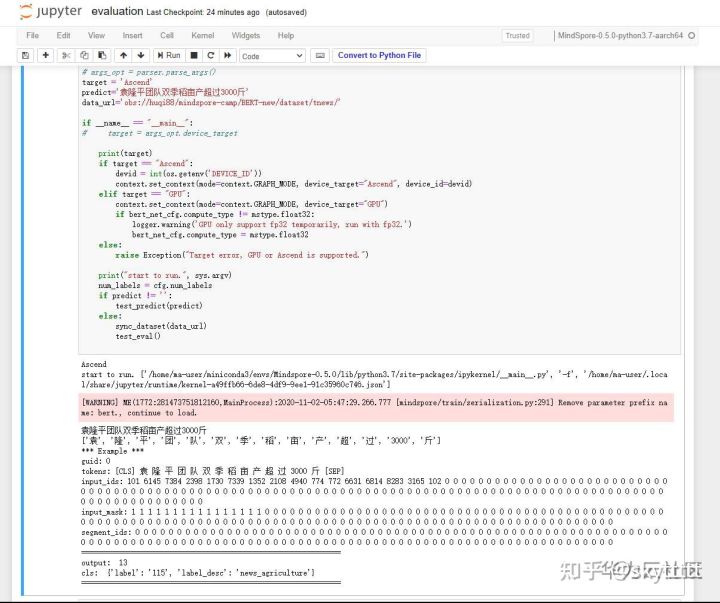
再来试试今日头条:袁隆平团队双季稻亩产超过3000斤,厉害了,检测到农业新闻!
本次分享就告一段落,我是Copy攻城狮胡琦,欢迎一起来参与MindSpore 21天实战营,全场景AI实战营,从小白到大牛只需21天!
















 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









