






一、web应用与http协议
①Web请求
应用程序有两种模式C/S、B/S
C/S是客户端与服务端程序,拥有独立的客户端
B/S是浏览器端/服务器端应用程序,借助浏览器运行
Web请求——浏览器发送请求,服务端接收,处理数据,响应数据的过程
a.最简单的web请求代码示例
import socket
sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sock.bind(("127.0.0.1",8800))
sock.listen(5)
while True:
print('server waiting...')
conn,addr = sock.accept()
data = conn.recv(1024)
print(data)
conn.send(b'HTTP/1.1 200 OK\r\n\r\nHello Luffycity')
conn.close()
- HTTP/1.1 200 OK\r\n\r\n——响应首行
固定的格式
1.1代表版本
200代表响应状态码,200表示没有问题,还有404等其他的状态码
OK文本解释,提示发送的数据没有问题
\r\n\r\n用于和后面的响应体分隔开 - Hello Luffycity——响应体(真正的数据)
b.带HTML标签的请求代码示例
conn.send发送的数据是HTML文本字符串时
conn.send(b'HTTP/1.1 200 OK\r\n\r\n<h1>Hello Luffycity</h1><img src = "图片地址">')
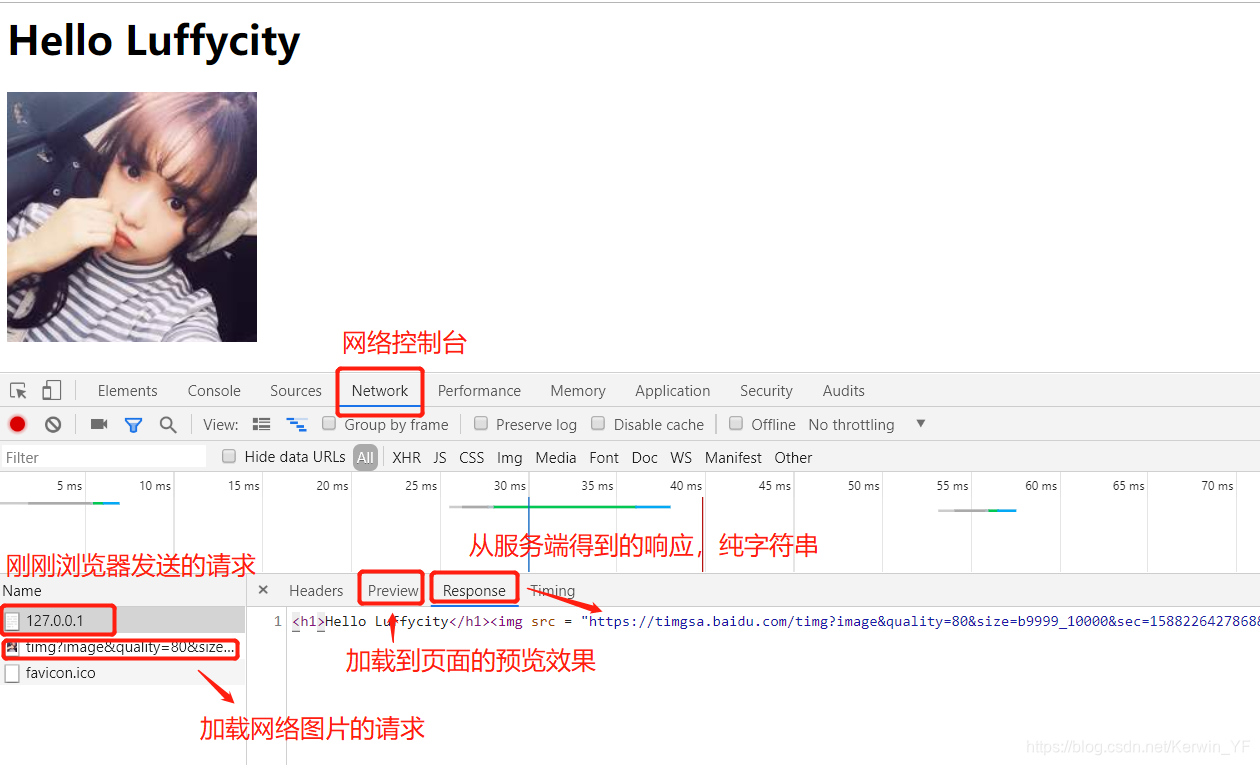
c. 直接读取写好的html进行响应
- 提前写好html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Page</title>
</head>
<body>
<h1>Hello Luffycity</h1>
<img src = "https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1588226427868&di=ef04fef04c62c288fe2483ca1f839eab&imgtype=0&src=http%3A%2F%2Fuploads.xuexila.com%2Fallimg%2F1706%2F1010-1F60QP005.png">
<a href="http://www.baidu.com">百度一下</a>
</body>
</html>
- 发送响应前读取html文件
with open('page.html','r',encoding='utf-8') as f:
#读取全部html文件
html_data = f.read()
send_data = 'HTTP/1.1 200 OK\r\n\r\n%s'%html_data
#编码后发送
conn.send(send_data.encode('utf-8'))
②http请求协议与响应协议
http协议包含由浏览器发送数据到服务器需要遵循的请求协议与服务器发送数据到浏览器需要遵循的请求协议
用于HTTP协议交互的信被为HTTP报文
请求端(客户端)的HTTP报文叫做请求报文
响应端(服务器端)的 做响应报文
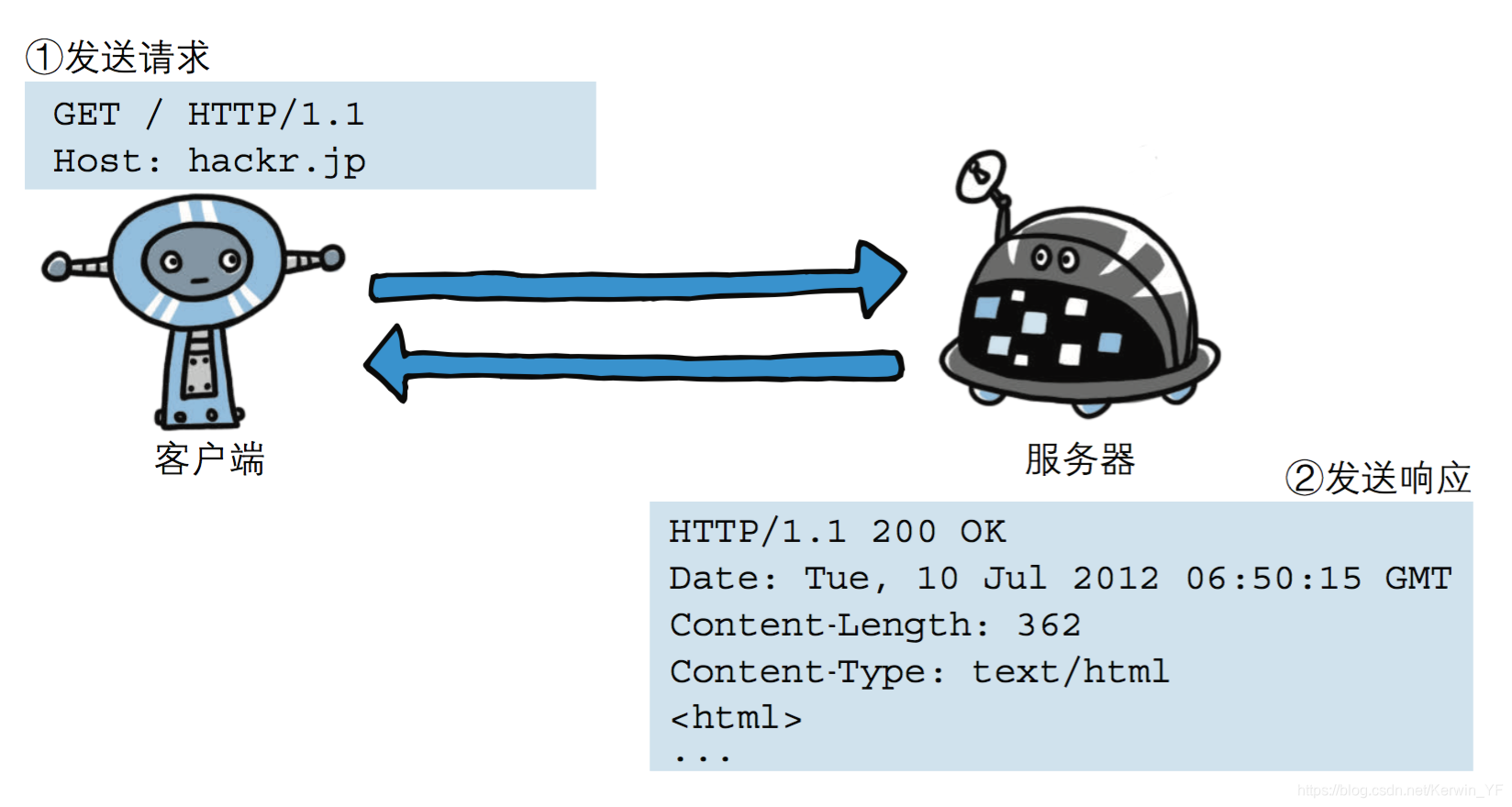
③请求协议
请求格式
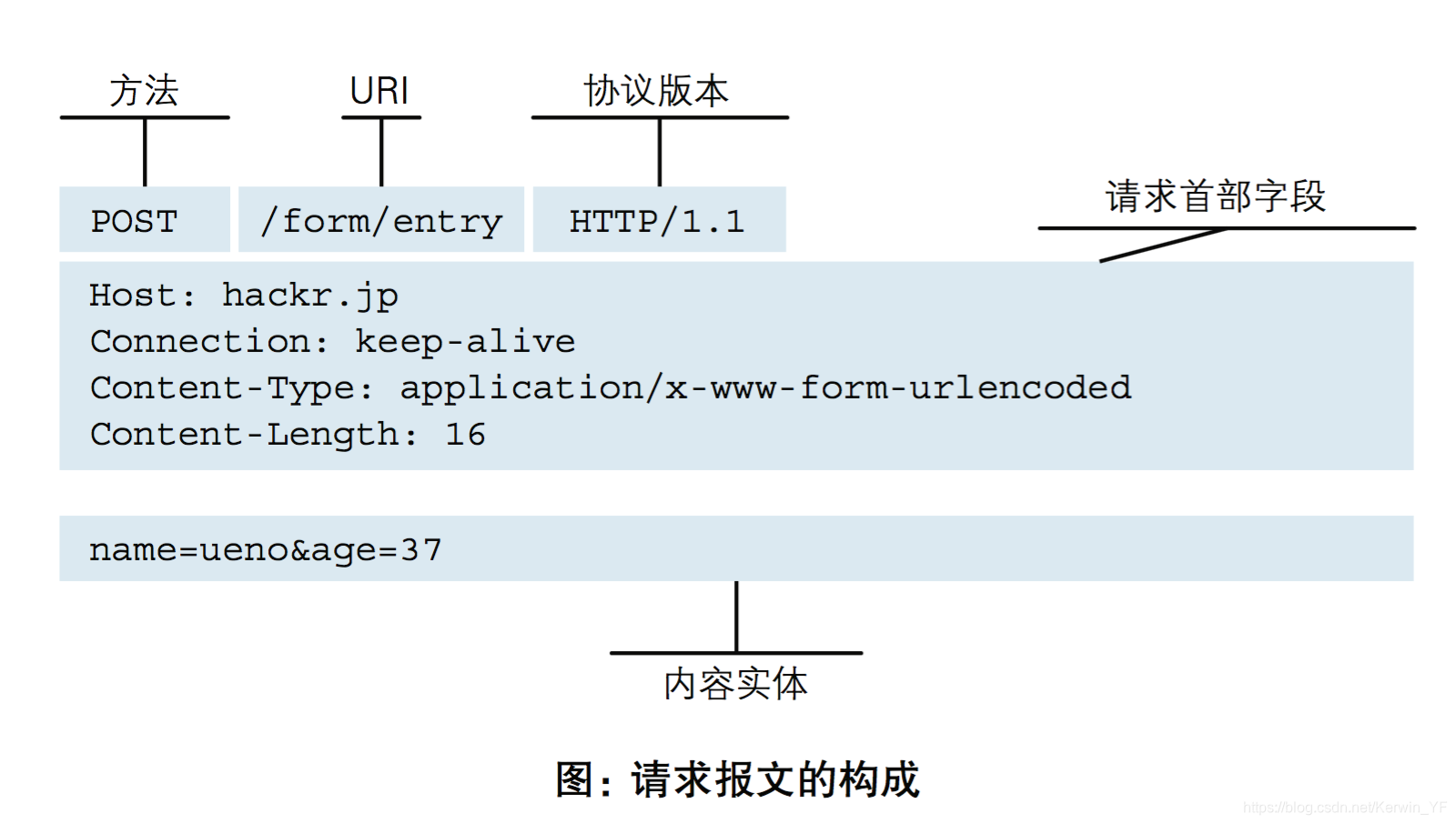
- 请求首行
方法:post、get
URL
协议版本 - 请求头:若干个键值对,描述这次请求的具体情况
- 服务器地址:Host
- 连接方式:Connection
keep-alive(响应结束可以等待自定义一个时间,默认3000ms)
close(响应结束立即断开连接) - 内容类型:Content-Type
指明请求的数据格式 - 内容长度
请求数据的字节个数
- 请求体
只有POST请求才有请求体
真实数据,中间以&分割
请求方式:get与post请求
- GET方式没有请求体!GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456
POST方法是把提交的数据放在HTTP包的Body(请求体)中. - GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制
- GET方式提交数据,会带来安全问题,用户名和密码将出现在URL上
- 涉及数据库的删改操作用post请求,查询用get请求’、
代码示例——GET请求
#请求报文
GET /path='XXXX'?username=alex&password=abc123 HTTP/1.1\r\nHost: 127.0.0.1:8800\r\nConnection: keep-alive\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: zh-CN,zh;q=0.9\r\n\r\n
请求首行
方式:GET
URL:/path='XXXX'?username=alex&password=abc123
协议版本:HTTP/1.1
请求头
服务器地址:Host: 127.0.0.1:8800
连接方式:Connection: keep-alive
内容类型:Upgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: zh-CN,zh;q=0.9
请求首行、请求头、请求头内的键值对都是通过\r\n分割
请求头与请求体之间通过\r\n\r\n两个分割
代码示例——POST请求
- 创建login.html文件
#记住action是你提交数据的地址,method方式为post
<form action="http://127.0.0.1:8800" method="post">
<lable for="user">用户名</lable>
<input type="text" id="user" name="username">
<label for="pwd">密码</label>
<input type="password" id="pwd" name="password">
<input type="submit" value="登陆">
</form>
input的name作为key,value作为值,组成键值对
- 服务端收到的POST请求
#post请求报文
POST / HTTP/1.1\r\nHost: 127.0.0.1:8800\r\nConnection: keep-alive\r\nContent-Length: 29\r\nCache-Control: max-age=0\r\nOrigin: http://127.0.0.1:8800\r\nUpgrade-Insecure-Requests: 1\r\nContent-Type: application/x-www-form-urlencoded\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\nReferer: http://127.0.0.1:8800/path='XXXX'?username=alex&password=abc123\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: zh-CN,zh;q=0.9\r\n\r\nusername=Alex&password=abc123
最后的请求体数据:
username=Alex&password=abc123
④响应协议
响应格式

响应体——浏览器拿到后渲染到页面上的内容
send_data = 'HTTP/1.1 200 OK\r\nName:Kerwin\r\n\r\n%s'%html_data
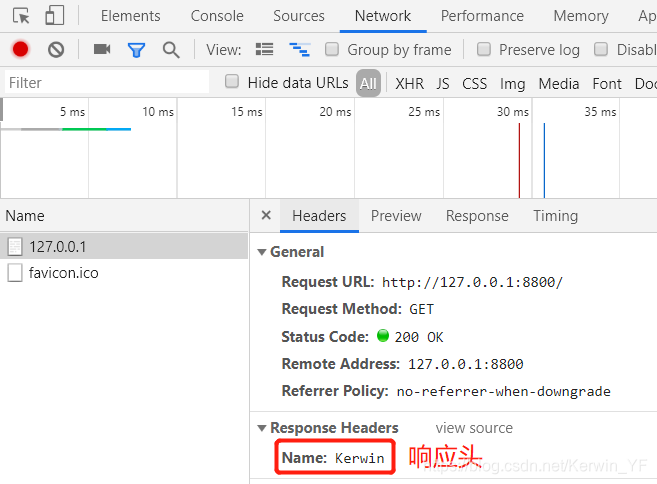
响应状态码
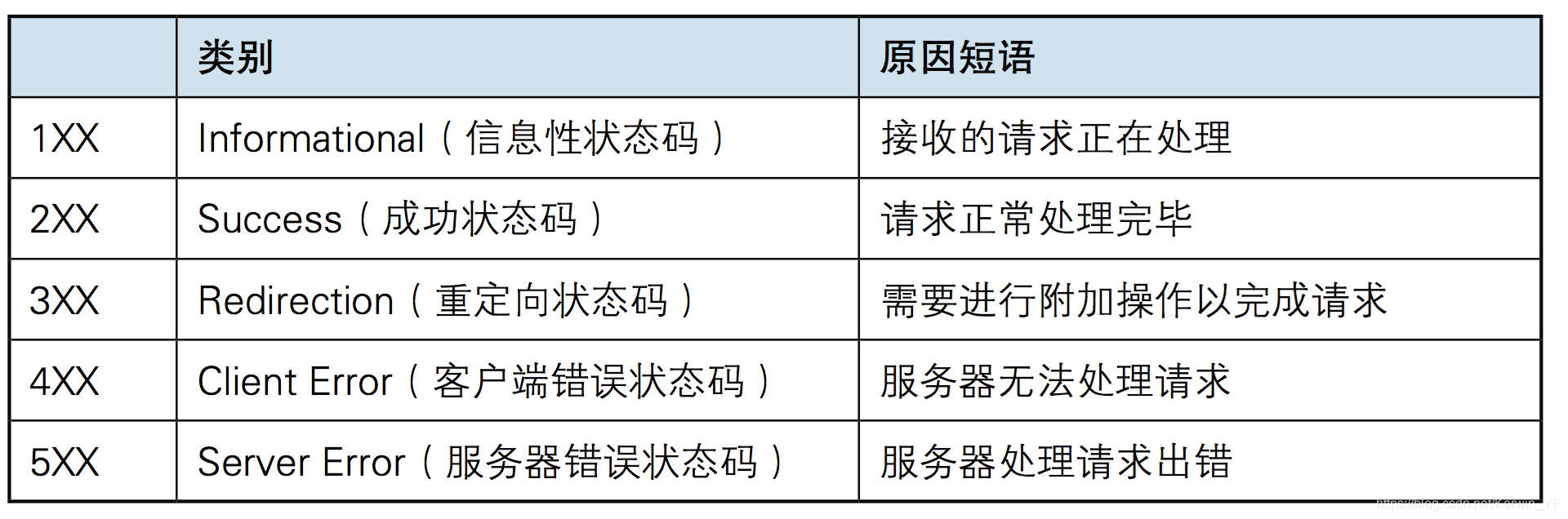
- 重定向
当网址更换后,浏览器请求时服务器回复重定向至另一个网址
应用于网站域名搬家的情况下
⑤wsgiref模块
WSGI——Web Server Gateway Interface
- URL
URL组成由:协议://IP:端口(默认80)/路径?a=1&b=2
wsgiref模块作用
按着http请求协议解析数据
专注于web业务开发
path = data.get('path')
if path == '/login':
return login.html
按着http响应协议封装数据
wsgiref模块使用
from wsgiref.simple_server import make_server
def application(environ,start_response):
#按照http请求协议解析出来的数据(字典形式):environ
#按照http响应协议组装数据:start_response
path = environ['PATH_INFO']
print(path)
start_response("200 OK",[('Content-Type','text/html')])
if path == '/login':
with open('login.html','r',encoding='utf-8') as f:
data = f.read()
if path == '/index':
with open('index.html','r',encoding='utf-8') as f:
data = f.read()
return [data.encode('utf-8')]
#封装了socket的实例化,bind,listen三个行为,定义回调函数
httped = make_server('127.0.0.1',8800,application)
print('开始连接')
#等待用户连接:conn,addr = sock.accept()
httped.serve_forever() #一旦连接,执行回调函数application
- from wsgiref.simple_server import make_server
导入模块 - httped = make_server(‘127.0.0.1’,8800,application)
实例化,绑定IP和端口,设置回调函数
一旦收到请求协议,执行回调函数 - httped.serve_forever()
相当于sock.accept - def application(environ,start_response)
定义回调函数需要传入2个参数
environ是解析后的请求协议字符串(字典形式)
start_response是按照http响应协议组装数据 - start_response设置
- start_response(“200 OK”,[(‘Content-Type’,‘text/html’)])
第一个参数"200 OK":响应状态码
第二个参数[(‘Content-Type’,‘text/html’)]:可填可不填([ ]) - return [data.encode(‘utf-8’)]
return的数据必须加中括号,内容必须为byte类型
网站图标请求favicon.ico
def application(environ,start_response):
start_response('200 OK',[('Content-Type','text/html')])
path = environ['PATH_INFO']
#如果路径为图标请求路径
if path == '/favicon.ico':
#加载图片,发送图片
with open('favicon.ico','rb') as f:
data = f.read()
return [data]
⑥DIY一个简易版Web框架
1. 目录结构
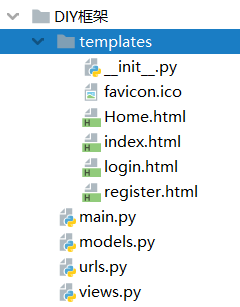
2. main.py: 启动文件,封装了socket
from wsgiref.simple_server import make_server
from urls import url_patterns
def application(environ,start_response):
#按照http请求协议解析出来的数据(字典形式):environ
#按照http响应协议组装数据:start_response
path = environ['PATH_INFO']
start_response("200 OK",[('Content-Type','text/html')])
func = None
for item in url_patterns:
if path == item[0]:
func = item[1]
break
if func:
return [func(environ)]
else:
return [b'404 Wrong']
3. urls.py: 路径与视图函数映射关系 ---- url控制器
from views import *
url_patterns = [
('/login', login),
('/index', index),
('/favicon.ico', favicon),
('/register', register),
('/timer',timer),
('/auth',auth)
]
4. views.py 视图函数,固定有一个形式参数:environ ----- 视图函数
def login(environ):
with open('templates/login.html','rb') as f:
data = f.read()
return data
def index(environ):
with open('templates/index.html','rb') as f:
data = f.read()
return data
def favicon(environ):
with open('templates/favicon.ico','rb') as f:
data = f.read()
return data
def register(environ):
with open('templates/register.html','rb') as f:
data = f.read()
return data
def timer(environ):
import datetime
now = datetime.datetime.now().strftime("%Y-%m-%d %X")
return now.encode('utf-8')
from urllib.parse import parse_qs
#登陆认证函数,通过login中的<form action="http://127.0.0.1:8800/auth" method="post">请求进来
def auth(request):
#取出form表单中的user和pwd的值
try:
request_body_size = int(request.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
request_body = request['wsgi.input'].read(request_body_size)
data = parse_qs(request_body)
print(data)
user=data.get(b"username")[0].decode("utf8")
pwd=data.get(b"password")[0].decode("utf8")
import pymysql
conn = pymysql.connect(
host = '192.168.50.253',
port = 3306,
user = 'root',
password = '123',
db = 'web',
charset = 'utf8'
)
#获得游标
cursor = conn.cursor()
#通过用户login输入的用户名和密码查询数据库
sql = 'select * from userinfo where name = %s and password = %s'
rows = cursor.execute(sql,(user,pwd))
if rows:
with open('templates/Home.html','rb') as f:
data = f.read()
return data
else:
return (b'Username or Password Wrong')
5. templates文件夹: html文件 -----模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Page</title>
</head>
<body>
<h4>登陆页面</h4>
<form action="http://127.0.0.1:8800/auth" method="post">
<lable for="user">用户名</lable>
<input type="text" id="user" name="username">
<label for="pwd">密码</label>
<input type="password" id="pwd" name="password">
<input type="submit" value="登陆">
</form>
</body>
</html>
6. models: 在项目启动前,在数据库中创建表结构 ----- 与数据库相关
#生成数据表
#仅仅在程序开启前在数据库中创建用户信息表
import pymysql
conn = pymysql.connect(
host = '192.168.50.253',
port = 3306,
user = 'root',
password = '123',
db = 'web',
charset = 'utf8'
)
cursor = conn.cursor()
sql = '''
create table userinfo(
id int primary key,
name varchar(20),
password varchar(20)
)
'''
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
二、Django简介
①MVC与MTV模型
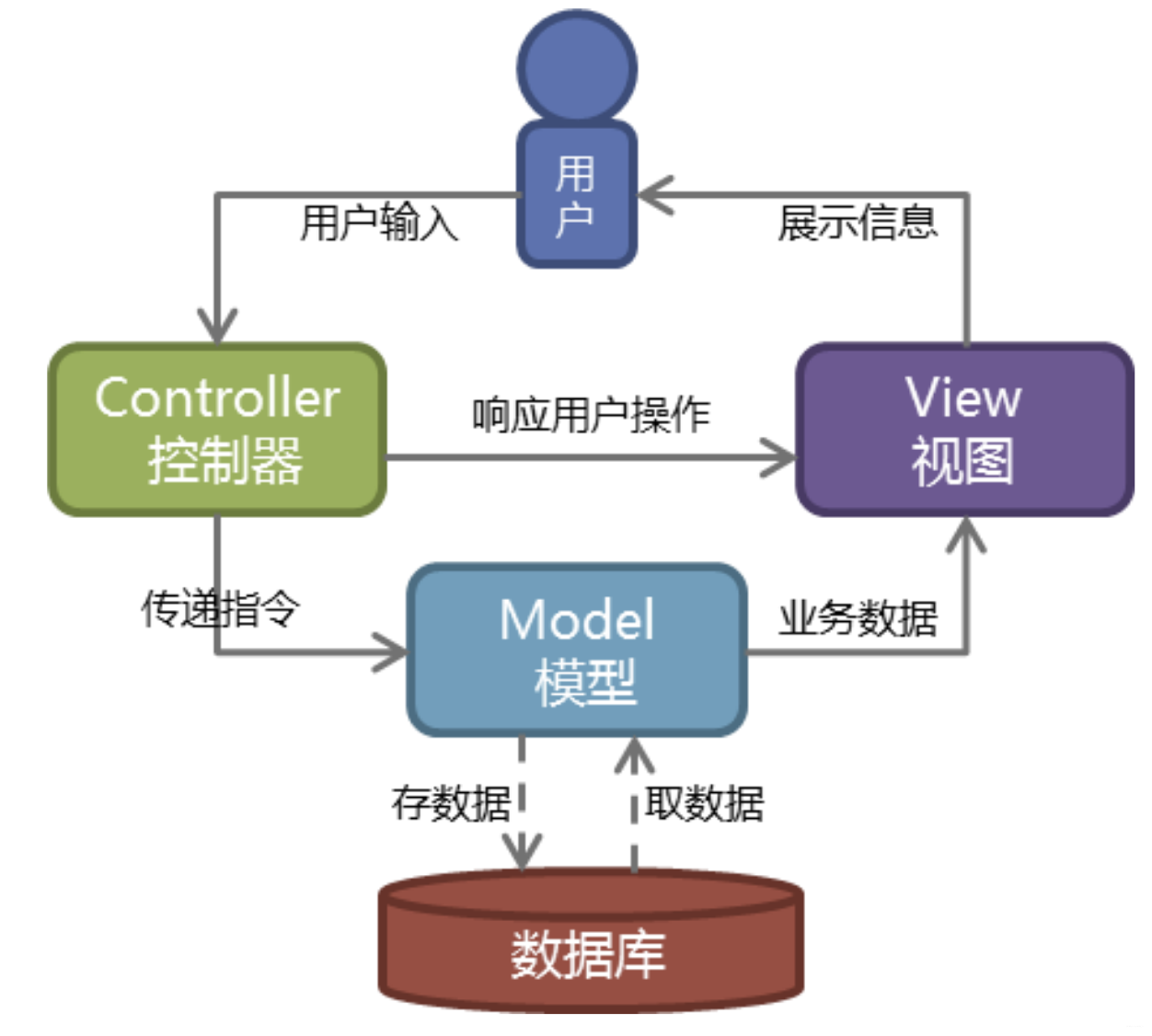
1. MVC
MVC就是把Web应用分为模型(M),控制器©和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起
模型(model)负责业务对象与数据库的映射(ORM)
视图(view)负责与用户的交互(页面)
控制器(control)接受用户的输入调用模型和视图完成用户的请求
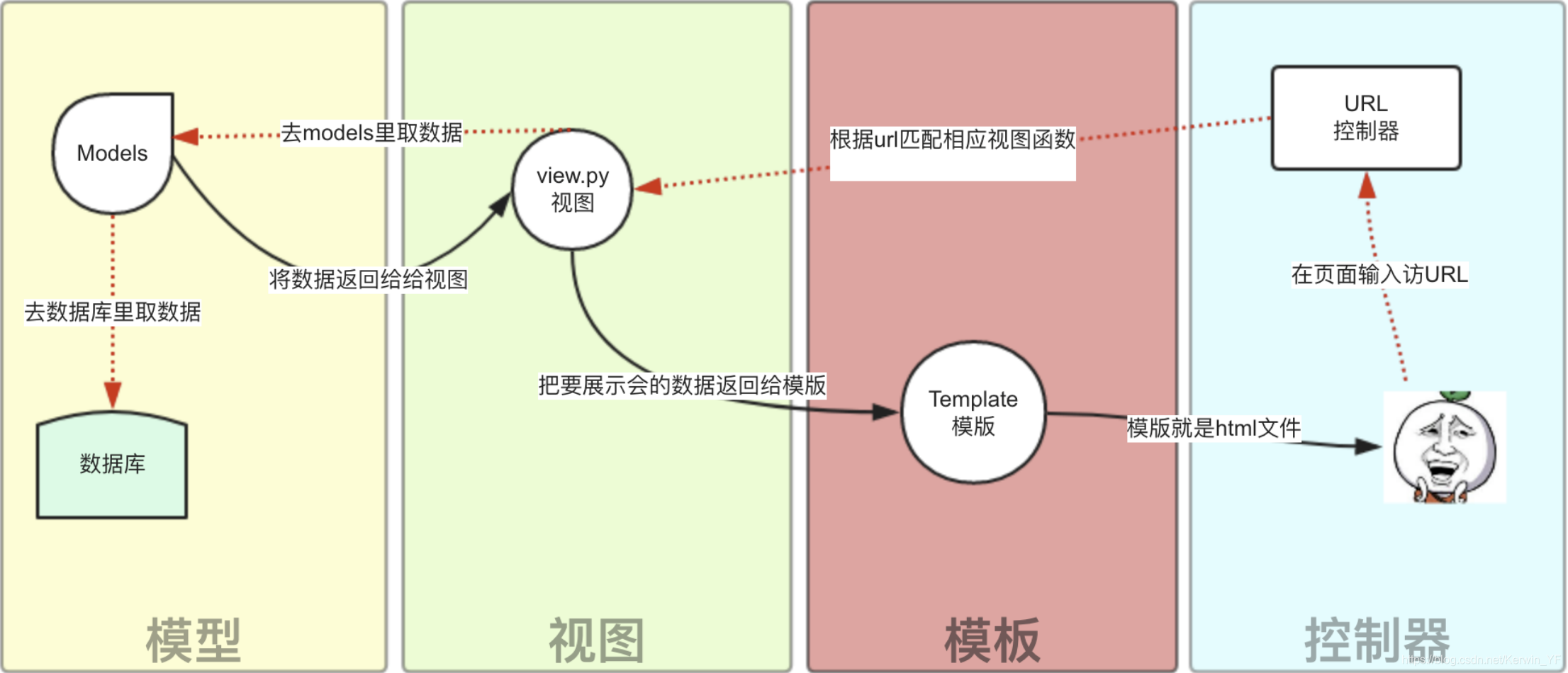
1. MTV——Django基于MTV模型
Django的MTV分别是值:
- M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。
- T 代表模板 (Template):负责如何把页面展示给用户(html)。
- V 代表视图函数(View): 负责业务逻辑,并在适当时候调用Model和Template
- 除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template
②Django的下载与基本命令
1. 下载Django
pip3 install django
2. 创建一个django project
找到项目的文件夹

在文件夹下运营创建Django项目命令:
django-admin.py startproject 项目名

当前目录下会生成mysite的工程,目录结构如下:
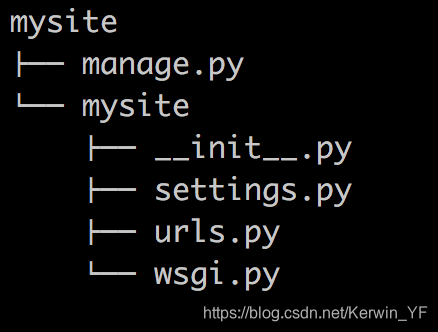
- manage.py ----- Django项目里面的工具(命令行参数),通过它可以调用django shell和数据库等。
- settings.py ---- 包含了项目的默认设置,包括数据库信息,调试标志以及其他一些工作的变量。
- urls.py ----- 负责把URL模式映射到应用程序(控制器)
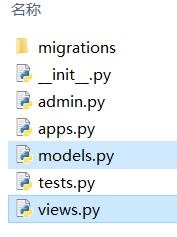
3. 在mysite目录下创建应用
python manage.py startapp 应用名

会在manage.py同级创建blog的应用文件夹,记住views.py是视图函数文件,models.py是模型负责交互数据库的文件
5. 在mysite同级目录下创建templates文件夹
以后用到的html文件都放在这个文件夹内
6. 启动django项目
python manage.py runserver 8080
访问:http://127.0.0.1:8080/时就可以看到
③Django简单示例
1. url控制器
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('timer/',views.timer), #添加timer路径调用的视图函数中timer方法
]
2. 视图函数
def timer(request): #必须传入request参数
import datetime
now = datetime.datetime.now()
ctime = now.strftime("%Y-%m-%d %X")
return render(request,'timer.html',{'ctime':ctime}) #render是找到timer.html文件,加载为bytes数据发送
- 视图函数中必须传入参数request,相当于之前说的environ
request是一个全局变量,它可以在模板、视图中使用 - return必须用render返回
- 第一个参数:必须为request
- 第二个参数:为加载的html文件(路径可以在setting中自定义)
- 第三个参数:{key:value}——用一个大括号包裹
可以实现将数据以字典的形式传给html文件中
3. 模板HTML文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>timer</title>
</head>
<body>
#{{视图函数返回的数据中的key}}
<h3>当前时间为: {{ctime}}</h3>
</body>
</html>
- 通过 {{ 视图函数返回的数据中的key }} 获取数据
用两个大括号包裹 - Django找不到templates文件夹是,需要在setting中找到TEMPLATES并设置:
‘DIRS’: [os.path.join(BASE_DIR,‘templates’)]
④静态文件配置
1. 当遇到引用jQuery遇到的问题
- urls路由分发:
urlpatterns = [
click事件的url路径映射函数
path('click/',views.click)
]
- views视图函数:
def click(request):
str = '我是Click事件'
return render(request,'click.html',{'str':str})
通过Django的render传输一个字符串
- html文件
<head>
<meta charset="UTF-8">
<title>Click</title>
<style>
h1{
color:red;
}
</style>
客户端浏览器找不到jquery的路径
<script src="jquery-3.5.0.js"></script>
</head>
<body>
<h1>{{str}}</h1>
<h4>点击上述文字变绿色</h4>
<script>
$('h1').click(function(){
$(this).css('color','green')
})
</script>
- 问题原因:
< script src=“jquery-3.5.0.js”></ script>
HTML文件中引入的jquery文件路径在客户端电脑上找不到
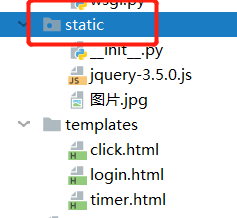
2. 静态引入文件的解决办法
在服务端创建static文件夹,专门存静态文件,修改配置文件中的STATIC找寻路径
- 创建同级static文件夹
- 修改setting
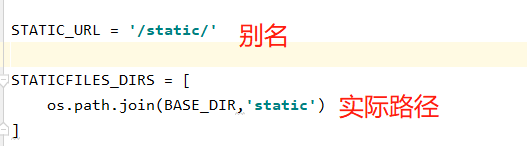
STATICFILES_DIRS = [
os.path.join(BASE_DIR,'static')
]
#在html中引入的link标签路径填写:/static/...文件路径
三、Django的路由层
①路由控制之简单配置
1. urls控制器中引入from django.urls import path,re_path
与Django自带urls导入的path模块不同,需要额外引入re_path模块
用于正则表达式
2. views视图函数中引入from django.shortcuts import render,HttpResponse
与Django自带的render函数不同,HTTPResponse直接传入字符串渲染到浏览器中
3. 利用re_path正则匹配urls控制器
利用正则匹配实现多种路径对应一个视图函数
urlpatterns = [
re_path(r'^articles/2003/$', views.special_case_2003),
re_path(r'^articles/([0-9]{4})/$', views.year_archive),
re_path(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive),
re_path(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
re_path(r'^$',views.index) #代表只访问127.0.0.1:8888不带任何路径时执行index函数
]
- re_path(r’^articles/2003/$', views.special_case_2003)
匹配以articles/2003/开头和结尾的路径时调用special_case_2003函数 - re_path(r’^articles/([0-9]{4})/$', views.year_archive)
匹配articles/20XX/,任意四位数的年份,并作为参数传给函数
year_archive(request,year) - re_path(r’^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive)
匹配articles/2020/05/,将年份2020,月份05作为参数传给函数
month_archive(request,year,month) - 注意:
1.若要从URL 中捕获一个值,只需要在它周围放置一对圆括号(将作为参数传给函数)
2.不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是^articles 而不是 ^/articles。
3.每个正则表达式前面的’r’ 是可选的但是建议加上。它告诉Python 这个字符串是“原始的” —— 字符串中任何字符都不应该转义
②有名分组
上面的示例使用简单的、没有命名的正则表达式组(通过圆括号)来捕获URL 中的值并以位置 参数传递给视图
更高级的用法中,可以使用命名的正则表达式组来捕获URL 中的值并以关键字 参数传递给视图
在Python 正则表达式中,命名正则表达式组的语法是(?P< name >pattern),其中name 是组的名称,pattern 是要匹配的模式
from django.urls import path,re_path
from app01 import views
urlpatterns = [
re_path(r'^articles/2003/$', views.special_case_2003),
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail),
]
使用有名函数后,views函数中必须的形参必须等于名称的关键字
year和month必须和(?P< name >pattern)中的name相同
def articles(request,year,month):
return
/articles/2005/03/ 请求将调用views.month_archive(request, year='2005', month='03')函数,而不是views.month_archive(request, '2005', '03')。
/articles/2003/03/03/ 请求将调用函数views.article_detail(request, year='2003', month='03', day='03')。
③分发
问题——当多个应用多个路径需要匹配的url过多时,在全局urls文件中写入的urlpatterns过多会代码冗余,可以通过分发至app01、app02等应用中单独的urls文件进行处理
1. 全局urls配置
from django.contrib import admin
from django.urls import path,re_path,include
from app01 import views
urlpatterns = [
re_path(r'^app01/',include('app01.urls'))
]
- 需要额外引入include将路径分发至app01文件夹中的urls文件
- 例如传入路径为:app01/articles/1992/10/
include会取出app01/后(articles/1992/10/)去app01/urls中匹配
2. app01中的urls配置
from django.contrib import admin
from django.urls import path,re_path
from app01 import views
#传入的路径为经过全局urls修改后的:articles/1992/10/
urlpatterns = [
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/',views.articles)
]
3. 无app01路径的路由分发
http://127.0.0.1:9999/app01/articles/1992/10/
如果想去除路径中的app01进行路由分发
在全局urls中写:
urlpatterns = [
#以任意开头,任意结尾
re_path(r'^',include('app01.urls'))
]
④路由控制的反向解析
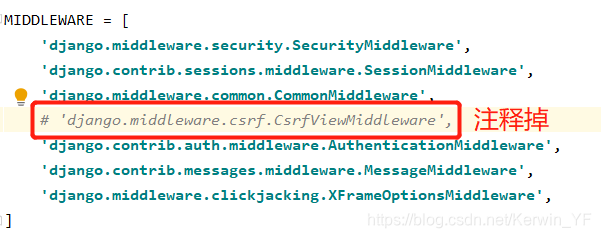
1. 利用Django实现登陆验证账号功能
- 第一步:setting需要设置MIDDLEWARE,否则报错CSRF验证失败
- 第二步:urls
urlpatterns = [
path('login/',views.login),
]
- 第三步:HTML文件
<body>
<h1>登陆页面</h1>
<form action="http://127.0.0.1:9999/login/" method="post">
<label for="user">用户名</label>
<input type="text" id="user" name="username">
<label for="pwd">密码</label>
<input type="password" id="pwd" name="password">
<input type="submit" value="登陆">
</form>
</body>
注意:form表单点击后会继续跳转到login的url路径中,利用POST请求覆盖掉之前GET请求的页面
- 第四步:views视图函数
def login(request):
if request.method == 'GET':
return render(request,'login.html')
elif request.method == 'POST':
username = request.POST['username']
password = request.POST['password']
if username == 'alex' and password == 'abc123':
return HttpResponse('登陆成功')
else:
return HttpResponse('用户名或者密码错误')
- 如果为GET请求,响应login页面
- 如果为POST请求,获取POST请求体数据,验证后再进行响应
- request.POST获取到的是请求体数据,以字典形式传入{‘username’: [‘alex’], ‘password’: [‘123’]}
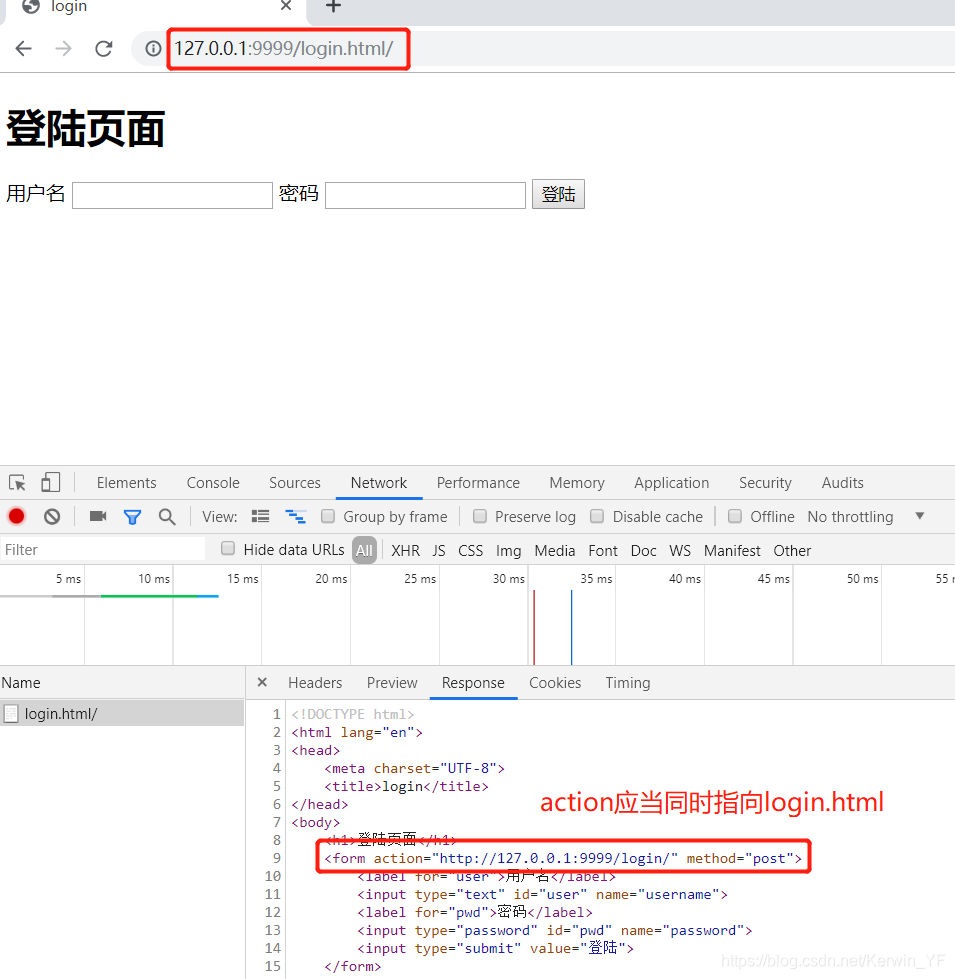
2. 更改url路径时,html文件中form的action路径未更改报错的情况
- 更改url中路径映射视图函数
urlpatterns = [
路径修改为login.html
path('login.html/',views.login),
]
- form表单中的action还是指向login,点击后找寻不到路径报错
3. 反向解析
可以解决修改url路径时,不会影响众多表单中指向该链接的action路径,避免修改过多其他html文件路径
思路——在全局url中定义别名,在html文件中使用模板语法,通过Django修改路径
- 全局url定义别名
取一个别名叫Log
urlpatterns = [
path('login.html/',views.login,name = 'Log'),
]
- html文件中form表单的action指向使用模板语法{% url ‘Log’ %}
<body>
<h1>登陆页面</h1>
#模板语法
<form action="{% url 'Log' %}" method="post">
<label for="user">用户名</label>
<input type="text" id="user" name="username">
<label for="pwd">密码</label>
<input type="password" id="pwd" name="password">
<input type="submit" value="登陆">
</form>
</body>
form表单中action路径缩略方法:
1. 不填写代表以当前url进行post请求
2. /index/代表拼接当前ip和端口,再加/index/路径去请求
- 当发送GET请求login时,渲染到浏览器的html文件中的form的action指向已经改变
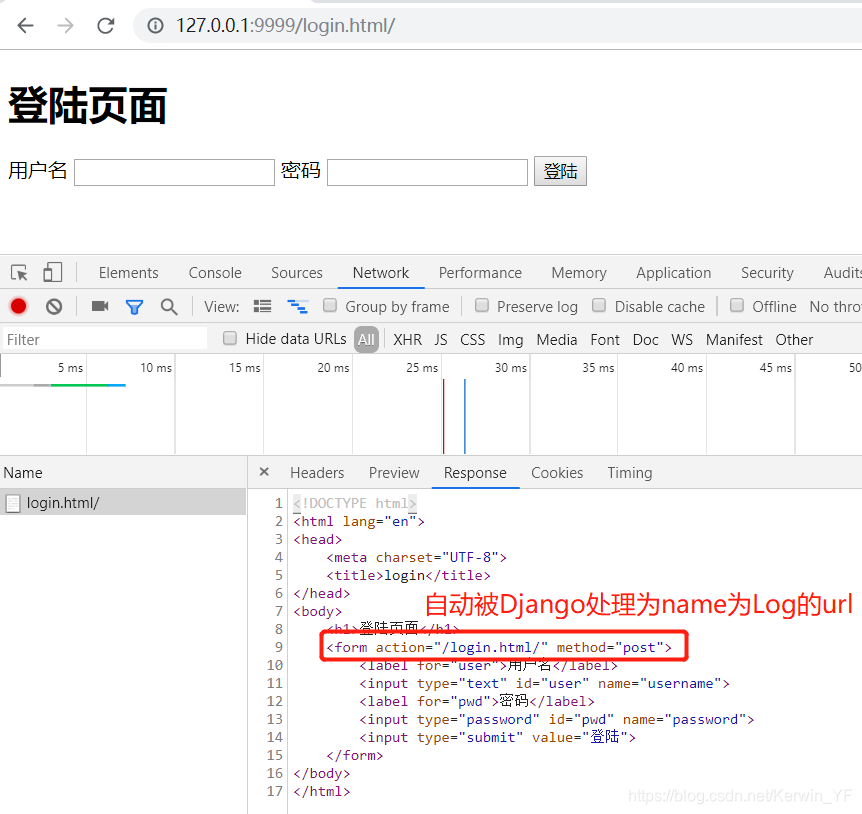
这种数据处理后传给浏览器步骤:
1. GET请求login页面
2. 全局url指向views.login
3. 函数处理执行return render(request,‘login.html’)
4. 在render去解析html并发送客户端时,发现模板语法后,找全局url中name='Log’的路径替换给html文件
⑤流程控制(视图函数)的反向解析
还有一种反向解析是在视图函数(views)中利用python脚本获取url
- 第一步:引入reverse模块
from django.urls import reverse
- 第二步:全局url定义别名
urlpatterns = [
path('timer/',views.timer,name='timer'),
re_path(r'^article/([0-9]{4})',views.article,name='article_year')
]
- 情形一:无正则表达式的reverse
def timer(request):
print(reverse('timer'))
找到全局url中别名为timer的路径,打印结果为:
/timer/
- 情形二:有正则表达式的reverse(需要传入参数)
def article(request,year):
url = reverse('article_year',args=(2020,))
print(url)
找到全局url中别名为article_year的路径:r'^article/([0-9]{4})'
由于有正则表达式的存在,必须传入一个符合正则的参数:例如2020
打印结果为:/article/2020
return HttpResponse('Hello World')
⑥反向解析之名称空间
1. url别名冲突问题
由于给url起的别名没有作用域,Django在反解URL时,会在项目全局顺序搜索,当查找到第一个name指定URL时,立即返回
我们在开发项目时,会经常使用name属性反解出URL,当不小心在不同的app的urls中定义相同的name时,可能会导致URL反解错误,为了避免这种事情发生,引入了命名空间
1. 全局urls配置:
#创建2个app,分别进行路由分发
urlpatterns = [
re_path(r'^app01/',include('app01.urls')),
re_path(r'^app02/',include('app02.urls')),
]
2. app01的urls配置:
#执行的是app01的views视图,url别名叫index
from django.contrib import admin
from django.urls import path,re_path
from app01 import views
urlpatterns = [
path('index/',views.index,name='index')
]
3. app02的url配置:
#执行的是app02的views视图,url别名也叫index
from django.contrib import admin
from django.urls import path,re_path
from app02 import views
urlpatterns = [
path('index/',views.index,name='index')
]
4. app01和app02的views函数都如下:
#返回的数据是url反向解析
def index(request):
return HttpResponse(reverse('index'))
- 效果如下:
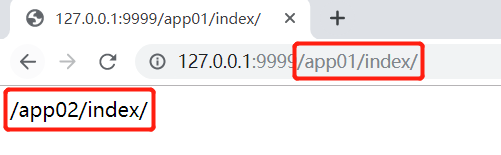
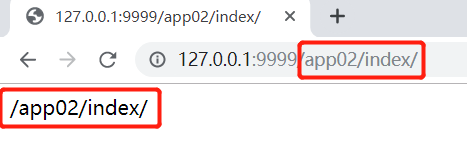
无论通过app01或者app02的views函数中解析出来找到name为index的路径都是/app02/index/
2. 解决办法——名称空间(namespace)
- 第一步:全局urls中分发的同时,定义名称空间(不可以重复)
urlpatterns = [
re_path(r'^app01/',include(('app01.urls','app01'))),
re_path(r'^app02/',include(('app02.urls','app02'))),
#include(('app02.urls','app02'))
include方法中传入的参数必须为元组形式:
include( ('分发路径','名称空间') )
]
- 第二步:在app01和app02各自的view方法中reverse反解url时参数传入名称空间
def index(request):
return HttpResponse(reverse('app01:index'))
#reverse('app01:index')
代表反解得到的是app01名称空间下的index
⑦path方法
1. 问题
urlpatterns = [
re_path('articles/(?P<year>[0-9]{4})/', year_archive),
re_path('article/(?P<article_id>[a-zA-Z0-9]+)/detail/', detail_view),
re_path('articles/(?P<article_id>[a-zA-Z0-9]+)/edit/', edit_view),
re_path('articles/(?P<article_id>[a-zA-Z0-9]+)/delete/', delete_view),
]
- 第一个问题,函数 year_archive 中year参数是字符串类型的,因此需要先转化为整数类型的变量值
可以在views函数中用int(year)处理,但每个函数都要写 - 第二个问题,三个路由中article_id都是同样的正则表达式,但是你需要写三遍,当之后article_id规则改变后,需要同时修改三处代码
2. path转化器
from django.urls import path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug>/', views.article_detail),
]
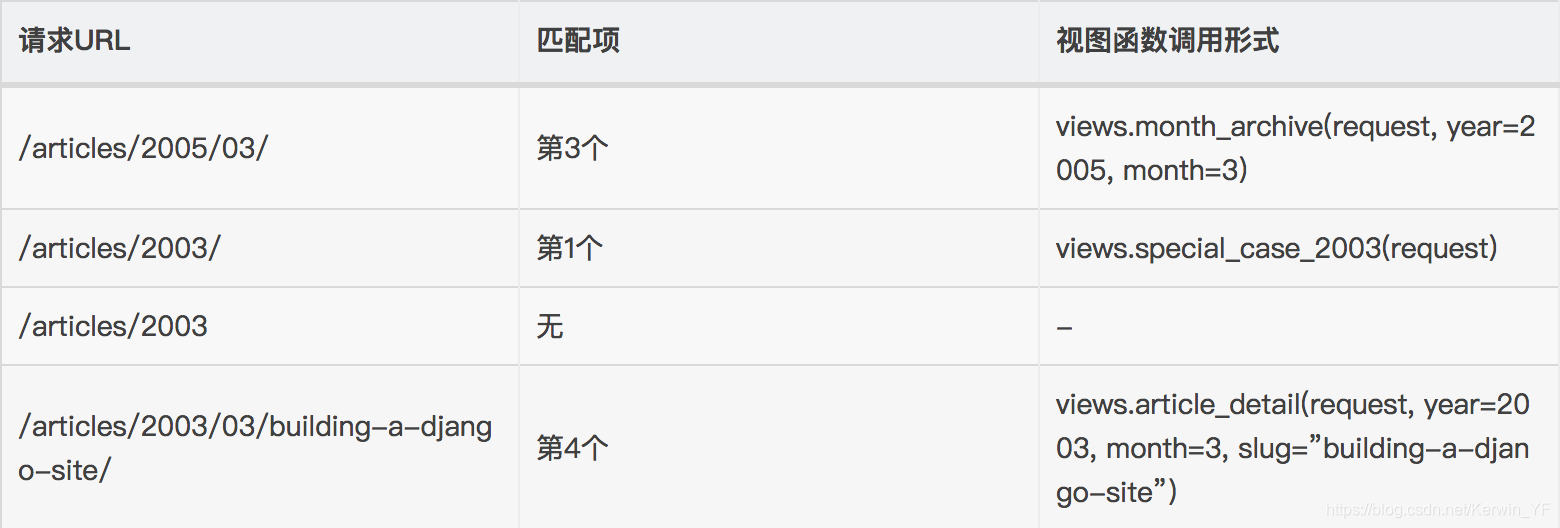
- 基本规则:
- 使用尖括号<>从url中捕获值。
- 捕获值中可以包含一个转化器类型(converter type),比如使用 int:name 捕获一个整数变量。若果没有转化器,将匹配任何字符串,当然也包括了 / 字符。
- 无需添加前导斜杠。
- Django默认支持以下5个转化器:
- str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
- int,匹配正整数,包含0。
- slug,匹配字母、数字以及横杠、下划线组成的字符串。
- uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
- path,匹配任何非空字符串,包含了路径分隔符,特殊符号(?不可以,因为它是url的分隔符)
3. 自定义转化器
- 第一步——创建新的urlconvert的py文件,在其中写入自定义转化器类
对于一些复杂或者复用的需要,可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
- regex 类属性,写正则表达式
- to_python(self, value) 方法,value是由类属性 regex 所匹配到的字符串,返回具体的Python变量值,以供Django传递到对应的视图函数中。
- to_url(self, value) 方法,和 to_python 相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
class YearConvert:
regex = '[0-9]{4}'
def to_python(self,value):
return int(value)
def to_url(self,value): #反向解析
return '%04d' % value
- 第二步——引入register_converter并用register_converter()方法将刚才自定义的类注册到Django
#引入register_converter
from django.urls import path,re_path,register_converter
#引入urlconvert文件中的自定义类
from app01.urlconvert import YearConvert
#register_converter(自定义类名,转化器名)
register_converter(YearConvert,'YYYY')
- 第三步——使用自定义的转化器
urlpatterns = [
path('article/<YYYY:year>/',views.year)
]
#views.year函数要传入形参year,捕捉到的YYYY数据会传给视图函数
四、Django的视图层
①请求对象(HttpRequest)
1. request属性
def index(request):
1. 请求方式
print(request.method) #GET或POST
2. 类似于字典的对象,包含GET或POST请求的所有参数
取值需要用request.POST.get('username')方法
print(request.GET) #{'username': ['alex'], 'password': ['123']}>
print(request.POST)
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用:
#request.POST.getlist("hobby")
因为多个select标签的name属性相同,组成的键值对后面的会覆盖前面的,用get永远只能取出来最后一个
3. 表示请求的路径
print(request.path) #/index/,如果url只是ip+port:127.0.0.1:8888,那么打印结果就是根目录/
return render(request,'index.html')
2. request方法
def index(request):
print(request.path) #/index/
print(request.get_full_path()) #/index/?name=alex
return render(request,'index.html')
如果请求的url是:http://127.0.0.1:8888/index/?name=alex
request.path只返回路径
request.get_full_path()返回的是路径+数据
②响应对象(HttpResponse)
响应对象主要有三种形式
1. HttpResponse()
HttpResponse()括号内直接跟一个具体的字符串作为响应体
2. render()
本质上也是基于HttpResponse做出的字符串响应,只是封装了找寻html文件,读文件,传参数,发送等功能
render(request, template_name,{'name':'alex,'age':18})
传入了参数的html并不是html文件,属于模板文件,它将会被Django解析并传入参数后发送给浏览器
3. redirect()
传递要重定向的一个硬编码的URL
def my_view(request):
...
return redirect('https://www.baidu.com/')
五、Django的模板层
①模板语法之变量
1. render()第三个参数可以通过{{}}传入参数,涉及不同类型数据传参如下:
- views函数传入各种类型参数
def index(request):
int = 10 #整数
list = [11,22,33,44] #列表
dict = {'name':'alex','age':18} #字典
bool = True #布尔
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
alex = Person('alex',28) #对象
egon = Person('egon',38)
person_list = [alex,egon] #对象组成的列表
return render(request,'index.html',locals())
locals()方法是将局部变量组成键值对传参,key就是=左边,value就是=右边
等同于{‘int’=int,‘list’=list}
- html中插入参数
<p>{{ int }}</p>
<p>{{ list }}</p>
<p>{{ dict }}</p>
<p>{{ bool }}</p>
<p>{{ alex }}</p>
<p>{{ person_list }}</p>
- 渲染到浏览器中

2. 深度查询(又叫句点符)
当需要深度查询列表中index为1的值时,可以使用句点符
模板语法变量查询中,所有的查询都是用点(.)来查询的,无论是列表或者字典
html中用句点符进行深度查询
<p>{{ list.1 }}</p> #查询结果为22
<p>{{ dict.name }}</p> #查询结果为alex
<p>{{ person_list.1.age }}</p> #查询结果为38
②模板语法之过滤器
过滤器的作用——将视图函数传入的参数做修饰(过滤)后渲染到页面上
- 过滤器语法
{{obj|filter__name:param}}
obj为传入的数据name
- Django自带的过滤器
1. default
如果一个变量是false或者为空,使用给定的默认值。否则,使用变量的值。例如:
{{ value|default:"数据为空" }}
2. length
返回值的长度。它对字符串和列表都起作用。例如:
{{ value|length }}
如果 value 是 ['a', 'b', 'c', 'd'],那么输出是 4。
3. filesizeformat
将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如:
{{ value|filesizeformat }}
如果 value 是 123456789,输出将会是 117.7 MB
4. date
将日期格式化为:2020-05-10
如果 value=datetime.datetime.now()
{{ value|date:"Y-m-d" }}
5. slice
将字符串或者列表切片
如果 value="hello world"
{{ value|slice:"2:-1" }}
6. truncatechars
如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾
{{ value|truncatechars:9 }} #超过9位的字符将以省略号替代
truncatewords——以单词为计数截断
7. safe
如果传入的value="<a href="">点击</a>",那么渲染到页面上的就是'<a href="">click</a>'
原因在于:Django会对html语法的字符串value进行转义(依据html特殊字符转义<>等特殊符号)再渲染到页面上
目的:为了安全,如果用户在评论区多次传入alert('XXX'),那么下次加载页面会跳出很多弹窗,所以Django将其转义成字符串
如果传入的html或js语句是安全的,添加safe过滤
{{ value|safe}} #页面就会正常显示a标签
8. add
将value与后面的参数100相加
{{ value|add:100 }}
9. upper
将value转为大写
{{ value|upper }}
③模板语法之标签
1. for标签
- 遍历每一个元素,语法:
{% for i in list %}
#逻辑代码
{% endfor %}
可以利用{% for obj in list reversed %}反向完成循环。
示例:
#views中
list = [11,22,33,44]
#html中
{% for i in list %}
<p>{{ i }}</p>
{% endfor %}
渲染到页面的:
<p>11</p>
<p>22</p>
<p>33</p>
<p>44</p>
- 遍历一个字典,语法:
{% for key,val in dic.items %}
<p>{{ key }}:{{ val }}</p>
{% endfor %}
示例:
#views中
dict = {'name':'alex','age':18}
#html中
{% for k,v in dict.items %}
<p>{{ k }}:{{ v }}</p>
{% endfor %}
渲染到页面的:
<p>name:alex</p>
<p>age:18</p>
- 获取循环的次数{{ forloop }}
forloop.counter:从1开始
forloop.counter0:从0开始
if forloop.first 判断第一次循环
if forloop.last 判断最后一次循环
示例:
#views中
list = ['A','B','C','D']
#html中
{% for i in list %}
<p>{{ forloop.counter }} : {{ i }}</p>
{% endfor %}
渲染到页面的:
<p>1 : A</p>
<p>2 : B</p>
<p>3 : C</p>
<p>4 : D</p>
- for … empty
for 标签带有一个可选的{% empty %} 从句,以便在给出的组是空的或者没有被找到时,给出提示
必须在for的模板标签内添加
#views中
list = []
#html中
{% for i in list %}
<p>{{ i }}</p>
{% empty %}
<p>数据为空</p>
{% endfor %}
渲染到页面的:
<p>数据为空</p>
2. if标签
对条件进行判断执行响应的html代码
#views中
score = 40
#html中
{% if score >= 90 %}
<p>成绩优秀</p>
{% elif score >= 60 and score < 90 %}
<p>成绩合格</p>
{% else %}
<p>成绩较差</p>
{% endif %}
渲染到页面的:
<p>成绩较差</p>
3. with标签
当深度查询的长度过长,可以使用一个简单的名字替代这个过长的变量
#views中
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
alex = Person('alex',28)
egon = Person('egon',38)
person_list = [alex,egon]
#html中
{% with person_list.1.name as name %} #用name替代person_list.1.name的深度查询,即egon
{{ name }}
{% endwith %}
渲染到页面的:
egon
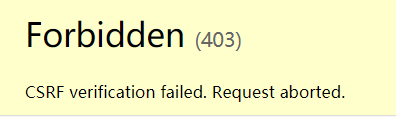
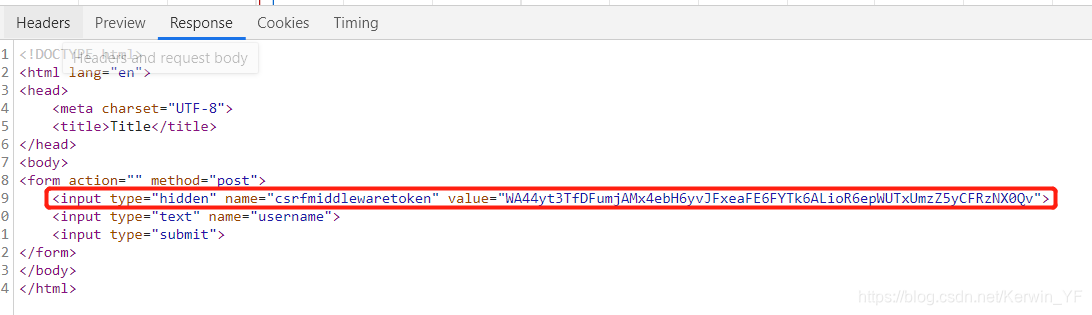
4. csrf_token标签
作用机制——为了安全,用户在GET请求login页面时,Django发送一串csrf随机校验码,在下次POST请求时,后台进行验证,如果不一致就会禁止请求
- html文件
form表单下面添加{% csrf_token %}标签
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="" method="post">
#添加csrf_token标签
{% csrf_token %}
<input type="text" name="username">
<input type="submit">
</form>
</body>
</html>
- 当第一次访问http://127.0.0.1:8888/login/,属于GET请求时,会得到Django写的隐藏input标签(带随机验证码)
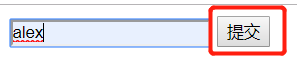
- 当第二次点击submit按钮用POST请求时,数据库会进行验证码核对
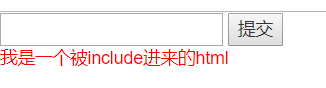
5. include标签
引用其他html文件中的html代码
- 语法:
{% include '引入的文件名.html' %}
- 同级创建被include进来的add.html文件
<p style="color:red">我是一个被include进来的html</p>
- 在主html文件中include插入
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
{% include 'Bootstrap.html' %}
</head>
<body>
<form action="http://127.0.0.1:8888/login/" method="post">
{% csrf_token %}
<input type="text" name="username">
<input type="submit">
</form>
#引入html代码
{% include 'add.html' %}
</body>
</html>
- 效果:
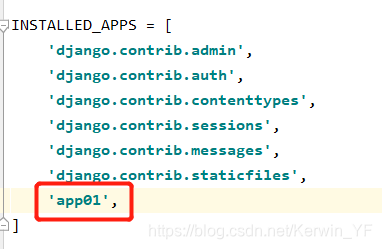
④自定义标签与过滤器——解决模板文件(html)中代码复用问题
1. 在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag.
2. 在app中创建templatetags模块(模块名只能是templatetags)
3. 创建任意 .py 文件,如:my_tags.py或my_filters.py
自定义一个乘法过滤器、乘法标签
#引入模块
from django import template
#实例化register,register的名字是固定的,不可改变
register = template.Library()
1. 乘法过滤器
#添加装饰器
@register.filter
def multi_filter(x,y):
return x * y
2. 乘法标签
@register.simple_tag
def multi_tag(x,y,z):
return x*y*z
- 引入模块from django import template
- 实例化register,register的名字是固定的,不可改变
- 添加装饰器
4. 在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py
类似于python中的import其他文件夹里的模块
{% load my_tags %}
5. 调用
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
1.调用自定义过滤器
#导入my_filters模块
{% load my_filters %}
#调用过滤器
<p>{{ int|multi_filter:11 }}</p>
2. 调用自定义标签
{% load my_filters %}
<p>{% multi_tag int 3 4 %}</p>
</body>
</html>
- 过滤器{{ int|multi_filter:11 }}
以int作为第一个参数,11作为第二个参数传给过滤器函数 - 标签{% multi_tag 2 3 4 %},标签函数名后面加空格,逐一写3个参数,中间空格分开
6. 自定义标签与过滤器的区别
- html模板文件中调用方式
{{ 过滤器 }}和{% 标签 %} - 函数装饰器名称不同
@register.filter和@register.simple_tag - 传入参数不同
过滤器只可以传2个参数,其中第一个被|前面传入的值作为第一个参数
标签传参不受限制,参数之间用空格隔开 - filter可以用在if等语句后,simple_tag不可以
#filter应用在if语句中
{% if int|multi_filter:30 > 100 %}
{{ int|multi_filter:10 }}
{% endif %}
#如果tag应用在if语句中语法报错
{% if multi_tag int 10 > 100 %} #报错
{{ multi_tag int 10 }}
{% endif %}
⑤模板语法之继承
1. 与include标签的区别
与include类似,都可以减少html代码的复用
include标签只可以引入其他文件的html代码,但无法在其中插入自己需求的html代码
extend标签可以及引入其他html代码,又预留自定义代码的盒子
2. 继承的作用

对比上面两张图发现,页面的框架都是左边菜单栏,右边内容栏,菜单栏的样式都是一样的,右边的内容区不一样
为了减少重复编写框架样式:
我们可以创建一个框架html文件base.html,在内容区预留block空白盒子
当写订单页面时,extends引入base框架,再用block写预留盒子的内容
3. 语法
extends引入框架
{% extends "base.html" %}
block填写空白区
{% block 内容区名称 %}
自定义的内容区
{% endblock %}
4. 示例
- base.html框架
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Base</title>
<style>
.menu{
background-color: red;
height: 600px;
width: 200px;
font-size: larger;
color: #fff;
line-height: 600px;
text-align: center;
float: left;
}
.content{
background-color: yellow;
height: 600px;
width: 800px;
font-size: larger;
color: green;
margin-left: 30px;
text-align: center;
float: left;
}
</style>
</head>
<body>
<div class="menu ">
我是菜单栏
</div>
<div class="content">
#预留的内容区域——block
{% block content %}
{% endblock %}
</div>
</body>
</html>
- order.html订单页面
#引用框架
{% extends "base.html" %}
#填写内容
{% block content %}
<h1>订单一:奔驰</h1>
<h1>订单二:宝马</h1>
<h1>订单二:奥迪</h1>
{% endblock %}
- 效果:

5. 注意
- {% extends %}标签必须顶头写在第一行
- base.html中的block内可以写内容,如果在子html中不填入block内容,就会默认继承base的
1. base中写:
<div class="content">
{% block default %}
<h1>来自base的默认订单:保时捷</h1>
{% endblock %}
{% block content %}
{% endblock %}
</div>
2. order中写:
#只填写content盒子的内容,不填写default盒子的内容
{% block content %}
<h1>订单一:奔驰</h1>
<h1>订单二:宝马</h1>
<h1>订单二:奥迪</h1>
{% endblock %}

- 如果你针对同一个盒子,既要继承父html的内容,又要自定义内容,可以使用{{ block.super }} 获取父html文件的默认内容
1. base中写:
{% block content %}
<h1>我是来自base.html的内容</h1>
<h1>来自base的首笔订单:保时捷</h1>
{% endblock %}
2. order中写:
{% block content %}
{{ block.super }} #继承base.html的内容<h1>我是来自base.html的内容</h1><h1>来自base的首笔订单:保时捷</h1>
<h1>订单一:奔驰</h1>
<h1>订单二:宝马</h1>
<h1>订单二:奥迪</h1>
{% endblock %}
- 为了更好的可读性,你也可以给你的 {% endblock %} 标签一个 名字 。例如:
{% block content %}
...
{% endblock content %} #为endblock添加名字
六、Django的模型层一(单表)
①ORM简介
ORM是“对象-关系-映射”的简称
ORM封装的语法功能——通过python语言中对类的操作,ORM翻译成pymysql语句,再执行到mysql中

| python | mysql |
|---|---|
| 类 | 表 |
| 实例化对象 | 一条记录 |
| 类中的属性 | 记录的字段 |
注意——ORM只可以对表和表内记录进行操作,但是无法对数据库操作(创建,删除),所以前提是用mysql建立好数据库
②单表操作
1. 生成表
- 第一步:在数据库中创建数据库orm,在django中创建新的应用app01,在app01中的models.py中写:
from django.db import models
# Create your models here.
class Book(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
pub_date = models.DateField()
price = models.DecimalField(max_digits=8, decimal_places=2)
publish = models.CharField(max_length=32)
objects = models.Manager() #写不写都可以
1. 要导入models模块
2. 生成的类必须要继承models.Model
3. 如何在现有表中临时添加字段(必须设置默认值去填充已有字段),例如:
阅读数:read_num = models.IntegerField(default=0)
评论数:comment = models.IntegerField(default=0)
- 第二步:settings配置数据库连接的信息
setting默认的database注释掉
# DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
# }
# }
填写自己的database
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'orm',# 要连接的数据库,连接前需要创建好
'USER':'root',# 连接数据库的用户名
'PASSWORD':'123',# 连接数据库的密码
'HOST':'127.0.0.1',# 连接主机,默认本级
'PORT':3306# 端口 默认3306
}
}
- 第三步:切换接口MySQLdb为PyMySQL
Django默认接口为MySQLdb,而python支持的是pymsql
在项目(非应用app01)的__init__.py中写:
import pymysql
pymysql.install_as_MySQLdb()
- 第四步:确保配置文件中的INSTALLED_APPS中写入我们创建的app名称
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01' #添加自己的app01
]
- 第五步:python版本高于3.4报错解决
如果cmd执行时报错:
django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.3 or newer is required; you have 0.7.11.None
MySQLclient目前只支持到python3.4,因此如果使用的更高版本的python,需要修改如下:
通过查找路径C:\Programs\Python\Python36-32\Lib\site-packages\Django-2.0-py3.6.egg\django\db\backends\mysql\base.py
这个路径里的文件把以下内容注释掉
if version < (1, 3, 13):
raise ImproperlyConfigured("mysqlclient 1.3.3 or newer is required; you have %s" % Database.__version__)
- 第六步:如果想打印orm转换过程中的sql语句,在settings中进行如下配置:
可以写在setting中任意位置
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
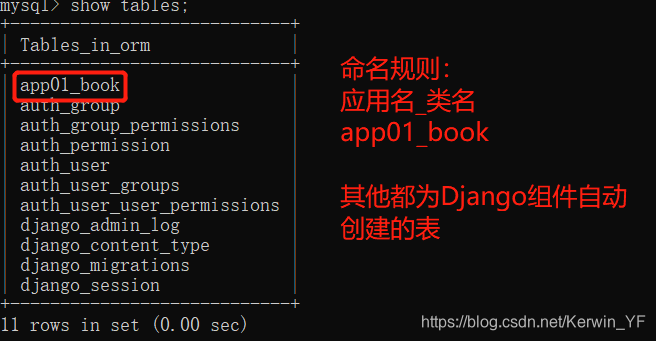
- 第七步:执行数据库迁移命令(在cmd中),在数据库中创建表
python manage.py makemigrations
python manage.py migrate
- 第八步:查看数据库中表是否生成
2. 添加记录
- 方式一:
必须要save才能保存实例化的对象
book_obj=Book(title="python葵花宝典",state=True,price=100,publish="苹果出版社",pub_date="2012-12-12")
book_obj.save()
- 方式二:(常用)
每张表下面都有一个objects的管理器,可以对这张表做增删改查操作
book_obj = Book.objects.create(title='php',price=100,pub_date='2013-12-12',publish='人民出版社')
print(book_obj.title) #php
create方法的返回值是当前新增的这条记录(对象),可以用对象的属性打印出来
- 批量插入数据——bulk_create(obj_list)
def index(request):
book_list = []
for i in range(100):
book_obj = Book(title='金瓶梅%s'%i,price=i*i) #实例化一个Book对象
book_list.append(book_obj)
#到此为止还没有进行过数据库的连接
Book.objects.bulk_create(book_list)
return HttpResponse('ok')
3. 查询表记录
- all()方法:查询所有结果
方法的调用者——objects管理器调用,Book.objects.all()
方法的返回值——返回一个queryset数据,类似[obj1,obj2,obj3…],可以使用列表的操作方法
book_list = Book.objects.all() #返回<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>]>
for obj in book_list: #Queryset数据可以切换,可以for循环取出它的属性
print(obj.title)
- first()和last()方法:查询第一或最后的记录,可以用索引[0]或[-1]替代
方法的调用者——QuerySet对象,是一个对象列表
方法的返回值——返回一个Book obj实例化的对象
两个效果等同,打印的都是Book object (1)
print(Book.objects.all().first())
print(Book.objects.all()[0])
- filter(**kwargs)方法:查询筛选条件相匹配的对象,相当于sql语句的where条件
方法的调用者——objects管理器调用
方法的返回值——返回一个queryset数据
#筛选价格等于200的书
book_list = Book.objects.filter(price=200) #可以写多个参数:title='python',price=100
print(book_list)
print(book_list[0].title)
- get(**kwargs)方法:查询筛选条件相匹配的对象,有且只有一个结果时才有意义,0个或者多个结果会报错
方法的调用者——objects管理器调用
方法的返回值——返回一个Book obj实例化的对象
#查询书名为Java的书
book_obj = Book.objects.get(title='Java')
当查询结果为0,报错:DoesNotExist
当查询结果为多个,报错:MultipleObjectsReturned
- exclude(**kwargs)方法:查询筛选条件相不匹配的对象,是filter方法的取反
方法的调用者——objects管理器调用
方法的返回值——返回一个queryset数据
#筛选价格不等于200的书
book_obj = Book.objects.exclude(price=200)
- order_by(字段)方法:对查询结果排序
方法的调用者——QuerySet对象
方法的返回值——排序后的QuerySet对象
按照id字段升序排列
book_obj = Book.objects.all().order_by('id')
降序排列————在字段名前加负号'-'
book_obj = Book.objects.all().order_by('-id')
多重排序————多个字段参数间用逗号隔开
book_obj = Book.objects.all().order_by('-price','id')
- reverse()方法:对查询结果的QuerySet进行反向排序
- count()方法:返回查询到的QuerySet的对象数量
方法的调用者——QuerySet对象
方法的返回值——数字int类型,这个QuerySet对象的个数
返回的是一个数值
book_qty = Book.objects.all().count()
- exists()方法:如果QuerySet包含数据,就返回True,否则返回False
方法的调用者——QuerySet对象
方法的返回值——True或者False
查询是否有匹配结果,有就返回True
book_exist = Book.objects.filter(price=100).exists()
- values(字段)方法:返回一个ValueQuerySet(一个特殊的QuerySet),是一个可迭代的字典对象
方法的调用者——QuerySet对象
方法的返回值——QuerySet(包含每个字段键值对的字典)
book_list = Book.objects.filter(price=100).values('title','publish')
返回值:
<QuerySet [{'title': 'python红宝书', 'publish': '人民出版社'}, {'title': 'php', 'publish': '人民出版社'}]>
- values_list(字段)方法:与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
方法的调用者——QuerySet对象
方法的返回值——QuerySet(只包含每个值的元组)
book_list = Book.objects.filter(price=100).values_list('title','publish')
返回值:
<QuerySet [('python红宝书', '人民出版社'), ('php', '人民出版社')]>
- distinct():方法:从返回结果中剔除重复纪录
方法的调用者——QuerySet对象
方法的返回值——QuerySet对象
去重只有在数据可能重复时才有意义,对于id字段不可能重复的地方没有意义
distinct一般搭配values或values_list使用去重
对取到的出版社名去重
book_list = Book.objects.all().values_list('publish').distinct()
返回值:
<QuerySet [('人民出版社',), ('上海出版社',)]>
4. 模糊查询(大于、小于等条件查询)
基于双下划线的模糊查询
1. 大于 greater than
Book.objects.filter(price__gt=100)
#价格大于100
2. 小于 little than
Book.objects.filter(price__lt=100)
#价格小于100
3. 在...中
Book.objects.filter(price__in=[100,200,300])
#价格为100或200或300
4. 在...之间
Book.objects.filter(price__range=[100,200])
#100 =< price =< 200
5. 文本包含(区分大小写)
Book.objects.filter(title__contains="python")
#标题名称包含python
6. 文本包含(不区分大小写)
Book.objects.filter(title__icontains="Python")
7. 文本开头\结尾
Book.objects.filter(title__startswith="py") #标题名以py开头
Book.objects.filter(title__endswith="py") #标题名以va结尾
8. 对date日期数据类型的年月日筛选
book_list = Book.objects.filter(pub_date__year=2012,pub_date__month=12,pub_date__day=12)
#查询出版日期为2012-12-12
5. 删除记录
- QuerySet调用delete()方法
result = Book.objects.filter(price=100).delete()
print(result) #(2, {'app01.Book': 2}),是一个元组,包含删除记录数量等信息,基本不用
- model_obj调用delete()方法
result = Book.objects.filter(price=200)[0].delete()
print(result) #(1, {'app01.Book': 1})
6. 修改记录
update()方法
只能够由QuerySet调用,model_obj不可以调用
update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数
result = Book.objects.filter(price=200).update(price=300)
print(result)
#只返回修改的记录数量2,为整数
七、Django的模型层二(多表)
①多表关系
- 建立一对多的关系
在多的表中建立关联字段 - 建立多对多的关系
创建第三张表(关联表):id和两个关联字段 - 建立一对一的关系
在两张表的任意一张表中建立关联字段并加上unique唯一限制
②通过ORM创建表关系
from django.db import models
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
age=models.IntegerField()
# 与AuthorDetail建立一对一的关系
authorDetail=models.OneToOneField(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE)
class AuthorDetail(models.Model):
nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=64)
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField()
class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
# 与Publish建立一对多的关系,外键字段建立在多的一方
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE)
# 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表
authors=models.ManyToManyField(to='Author')
一对一关系——OneToOneField
authorDetail=models.OneToOneField(to=“AuthorDetail”, to_field=“nid”, on_delete=models.CASCADE)
- authorDetail不用加_id写成authorDetail_id:因为Django会自动拼接外键字段_id
- to=“AuthorDetail”:to哪张表名称必须加引号
- to_field=“nid”:如果不写to_field,那么自动外键关系到目标表的主键primary_key
- OneToOne方法自动约束了唯一Unique
一对多关系——ForeignKey
publish=models.ForeignKey(to=“Publish”, to_field=“nid” ,on_delete=models.CASCADE)
on_delete=models.CASCADE在一对多和一对一关系必须添加
代表删除同步
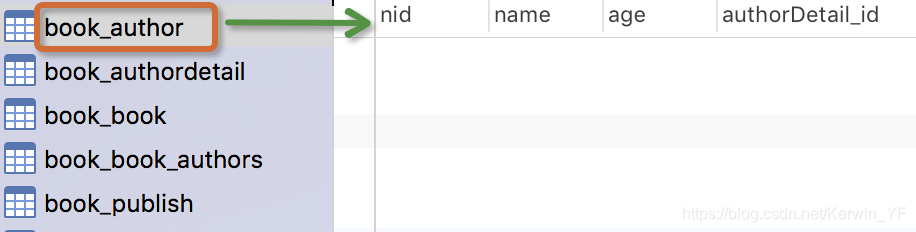
多对多关系——ManyToManyField
authors=models.ManyToManyField(to=‘Author’)
- 实际完成的效果等同于下面的sql语句:
CREATE TABLE book_authors(
id INT PRIMARY KEY auto_increment,
book_id INT,
author_id INT,
FOREIGN KEY (book_id) REFERENCES book(id),
FOREIGN KEY (author_id) REFERENCES author(id)
)
#创建了第三张表,生成2个字段分别关联到两张表
- 新表的名称为该语句所在表名_等号左边的变量
即book_authors
生成的表如下

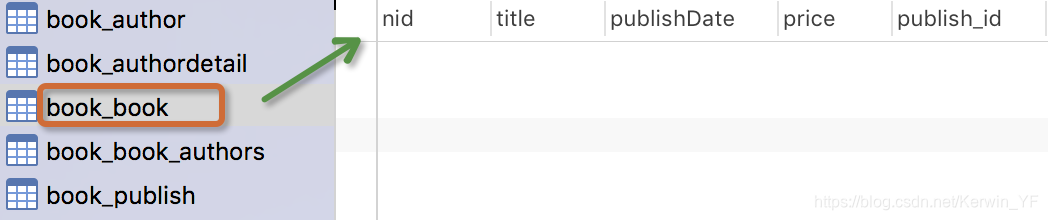
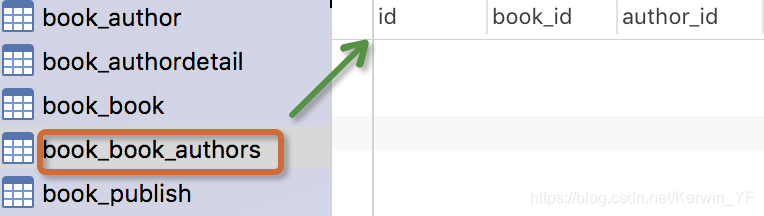
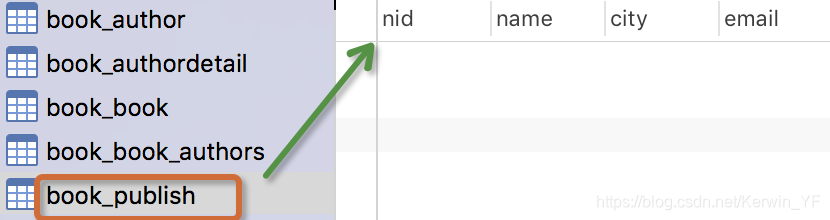
注意事项:
- 表的名称myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称
- id 字段是自动添加的对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
- 这个例子中的CREATE TABLE SQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。
- 定义好模型之后,你需要告诉Django 使用这些模型。你要做的就是修改配置文件INSTALL_APPSZ中设置,在其中添加应用的名称。
- 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None
③添加记录
1. 添加一对多记录
方式1:
publish_obj=Publish.objects.get(nid=1)
book_obj=Book.objects.create(title="金瓶梅",publishDate="2012-12-12",price=100,publish=publish_obj)
方式2:
book_obj=Book.objects.create(title="金瓶梅",publishDate="2012-12-12",price=100,publish_id=1)
- book_obj是刚刚新增的那条记录对象
- publish=publish_obj
将出版社对象直接赋值给Book的publish属性 - publish_id=1
本质上Django会在出版社表搜索id=1的出版社对象,再赋值给Book的publish属性
注意:
- Book表内记录的publish属性等于出版社表内的某一条记录(是个publish对象,可以调用属性)
- publish_id属性等于Book表内publish_id的具体值
- publish.name等于调用publish对象的name属性,获取出版社名称
publish_obj = Book.objects.filter(title='西游记').first().publish
publish_id = Book.objects.filter(title='西游记').first().publish_id
publish_name = Book.objects.filter(title='红楼梦').first().publish.name
print(publish_obj) #Publish object (2)
print(publish_id) #2
print(publish_name) #人民出版社
2. 添加多对多记录
# 当前生成的书籍对象
book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1)
# 为书籍绑定的作者对象
yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录
egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录
# 绑定多对多关系,即向关系表book_authors中添加纪录
book_obj.authors.add(yuan,egon) #authors=models.ManyToManyField(to='Author') 这是在创建Book表时创建的多对多关系
- 由于models.py并没有定义book_authors类,就没有这张表,所以就不能用objects.create创建
- Django针对多对多提供了接口book_obj.authors.add(yuan,egon)方法
本质是,拿到book_obj的主键id,yuan的主键id,在book_authors中创建一条记录
然后再拿到book_obj的主键id,egon的主键id,在book_authors中创建第二条记录 - book_obj.authors.add(1,2,3)——可以直接传author的id作为参数
- book_obj.authors.add(*[1,2,3])——也可以用列表作为参数传参,要加星号 * ,星号可以将列表转为元组
删除多对多记录(解除关系)
1. book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除
book_obj.authors.remove(yuan,egon)
book_obj.authors.remove(1,2,3)
book_obj.authors.remove(*[1,2,3])
2. book_obj.authors.clear() #清空被关联对象
清空book_obj被关联的所有作者
3. book_obj.authors.set([yuan,egon]) #先清空再设置
由于更新作者表需要先clear原先的记录,再add新增的记录,而set内部直接做了这两步操作
并且set内传参的列表不需要加*
查询多对多记录
book_obj.authors.all() #查询与book_obj关联的所有作者对象
返回值是:queryset数据,包含了所有本书关联的作者对象
book_obj.authors.all().values("name") #查询本书所有作者的姓名
打印结果:<QuerySet [{'name': 'alex'}, {'name': 'egon'}]>
④查询记录(基于对象——Mysql的子查询)
1. 正向查询与反向查询
A表与B表有关联,关联属性(字段)在A表中
- 正向查询:A---------》B----------
- 反向查询:B---------》A----------
2. 一对多查询
正向查询:按字段查询publish
查询红楼梦这本书的出版社的名字
字段publish在Book表中
book_obj = Book.objects.filter(title='红楼梦').first() #与红楼梦关联的出版社对象
print(book_obj.publish.name)
反向查询:按表名小写_set查询
查询人民出版社出版过的书籍名称
1. publish.book_set.all()接口
publish = Publish.objects.filter(name='人民出版社').first()
book_list = publish.book_set.all().values('title') #queryset对象
print(book_list)
2. 通过子查询
publish = Publish.objects.filter(name='人民出版社').first()
book_list = Book.objects.filter(publish=publish).values('title') #匹配Book表中publish对象与人民出版社相同的书籍
print(book_list)
3. 多对多查询
正向查询:按字段查询authors
查询红楼梦这本书的所有作者的名字
字段authors在Book表中
book_obj = Book.objects.filter(title='红楼梦').first() #获取红楼梦这本书的对象
author_list = book_obj.authors.all().values('name') #获取关联红楼梦的所有作者queryset对象
print(author_list) #<QuerySet [{'name': 'alex'}, {'name': 'egon'}]>
反向查询:按表名小写_set查询
查询alex写过的所有书籍
author_obj = Author.objects.filter(name='alex').first() #获取alex这个作者的对象
book_list = author_obj.book_set.all().values('title') #获取关联alex的所有书籍queryset对象
print(book_list) #<QuerySet [{'title': '红楼梦'}, {'title': '西游记'}]>
4. 一对一查询
正向查询:按字段查询authorDetail
字段authorDetail在Author表中
查询作者alex的详细信息手机号
author_obj = Author.objects.filter(name='alex').first() #获取alex这个作者的对象
telephone = author_obj.authorDetail.telephone #获取authorDetail作者详情这张表中关联的alex的手机号
print(telephone) #110
反向查询:按表名author查询
查询手机号为110的作者的名字和年龄
authorDetail_obj = AuthorDetail.objects.filter(telephone='110').first() #获取手机号为110的作者详情对象
name = authorDetail_obj.author.name #获取作者详情对象关联的作者对象
age = authorDetail_obj.author.age
print(name) #alex
print(age) #18
⑤查询记录(基于双下划线——Mysql的join连表查询)
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
1. 一对多查询
正向查询:
查询西游记这本书出版社的名字
SQL语句:
select app01_publish.name from app01_book inner join app01_publish
on app01_book.publish_id = app01_publish.nid
where app01_book.title = '西游记'
result = Book.objects.filter(title='西游记').values('publish__name')
print(result) #<QuerySet [{'publish__name': '人民出版社'}]>
- filter就相当于SQL语句中的where条件
- values就相当于SQL语句中的select * 返回值,当它的参数带双下划线就会去join表名
- publish__name:这次正向查询,字段为publish,__name代表查询的是publish表中的name字段(内部实现了join)用book表left join了publish表,必须加引号“”
- 返回值是一个queryset对象
反向查询:
查询西游记这本书出版社的名字
result = Publish.objects.filter(book__title='西游记').values('name')
print(result)
- 从Publish表反向查询西游记这本书,按照表名小写:book__title
- values(‘name’)代表Publish这张表自己的name字段
2. 多对多查询
正向查询:
查询红楼梦这本书的所有作者的名字
SQL语句:先book去join book_authors,再去join authors,再去过滤书名叫红楼梦
select app01_author.name from app01_book inner join app01_book_authors on app01_book.nid = app01_book_authors.book_id
inner join app01_author on app01_book_authors.author_id = app01_author.nid
where app01_book.title = '红楼梦'
result = Book.objects.filter(title='红楼梦').values('authors__name')
print(result) #<QuerySet [{'authors__name': 'alex'}, {'authors__name': 'egon'}]>
- authors__name:authors是Book表下创建多对多关系ManyToMany的字段,在这里它会两次跨表连接:1、第一次连接到book_authors表,第二次连接到author表
反向查询:
查询红楼梦这本书的所有作者的名字(从作者出发,查询作者写的书中有红楼梦这本书的人)
result = Author.objects.filter(book__title='红楼梦').values('name') #通过book__title反向查到作者写过的书名
print(result) #<QuerySet [{'name': 'alex'}, {'name': 'egon'}]>
3. 一对一查询
正向查询:
查询alex的手机号(通过Author表去join与其关联的AuthorDetail表,正向查询按照字段authorDetail查询)
result = Author.objects.filter(name='alex').values('authorDetail__telephone')
print(result) #<QuerySet [{'authorDetail__telephone': 110}]>
反向查询:
查询alex的手机号(通过AuthorDetail表去join与其关联的Author表,反向查询按照表名author查询)
result = AuthorDetail.objects.filter(author__name='alex').values('telephone')
print(result) #<QuerySet [{'telephone': 110}]>
4. 连续跨表
正向查询
查询手机号以110开头的作者出版过的所有书籍名称以及书籍出版社名称
(通过Book表join AuthorDetail,两者并无直接联系,所以必须连续跨表)
result = Book.objects.filter(authors__authorDetail__telephone__startswith='110').values('title','publish__name')
print(result) #<QuerySet [{'title': '红楼梦', 'publish__name': '人民出版社'}, {'title': '西游记', 'publish__name': '人民出版社'}]>
- filter(authors__authorDetail__telephone__startswith=‘110’)
通过book去join author表,再去join authorDetail表,获得telephone属性判断以110开头 - values(‘title’,‘publish__name’)
取值1:book本表下的title书名字段
取值2:book表与publish表join后获得publish下name的值
反向查询
result = Author.objects.filter(authorDetail__telephone__startswith='110').values('book__title','book__publish__name')
print(result)
以Author作者表作为基表的查询
八、Django的模型层三(聚合查询和分组查询)
①聚合查询(aggregate)
查询所有书籍的平均价格
from django.db.models import Avg,Max,Min,Count
result = Book.objects.all().aggregate(avg_price=Avg('price'),max_price=Max('price'))
print(result) #{'avg_price': 133.33, 'max_price': 200}
- 导入聚合函数:from django.db.models import Avg,Max,Min,Count
- aggregate()
聚合统计函数,内部传入聚合函数 - avg_price=Avg(‘price’)
给平均数取名一个字段,如果不命名,Django默认命名为 字段__聚合函数名:price__avg - {‘avg_price’: 133.33, ‘max_price’: 200}
聚合函数aggregate返回值为一个字典,不再是queryset
②单表下的分组查询(annotate)
1. annotate分组统计方法

查询每一个部门的名称以及员工的平均薪水
1. SQL语句:
select dep,AVG(app01_employee.salary) from app01_employee group by dep
2. Django语句:
from django.db.models import Avg,Max,Count,Min
result = Employee.objects.values('dep').annotate(avg_salary=Avg('salary'))
print(result) #<QuerySet [{'dep': '保安部', 'avg_salary': 5000.0}, {'dep': '教学部', 'avg_salary': 51000.0}]>
- Employee.objects.values(‘dep’)
这一步就已经完成了按照dep字段进行分组 - annotate()
分组统计函数,内部传入聚合函数,它取出来的值会作为键值对返回 - 单表分组的ORM语法:
单表.objects.values(“group by的字段”).annotate(聚合函数(“统计字段”))
2. annotate原理解析
result = Employee.objects.all()
#翻译成SQL语句:
select * from employee
result = Employee.objects.values('name')
#翻译成SQL语句:
select name from employee
result = Employee.objects.values('name').annotate(Avg('salary'))
- annotate函数进行分组的依据为前面select的字段
- 当all()后面跟annotate方法时无意义,因为all包含了主键字段
在单表分组下,按着主键进行group by没有任何意义
③多表下的分组查询
书籍表:

作者表:

出版社表:

跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询
1. 多表分组查询1
查询每一个出版社的名称以及出版书籍的个数
1. SQL语句
select app01_publish.name,COUNT('title') from
app01_book inner join app01_publish
on app01_book.publish_id = app01_publish.nid
group by app01_publish.nid
2. Django语句
方式一:以publish.name分组
result = Publish.objects.values('name').annotate(book_count=Count('book__title'))
print(result) #<QuerySet [{'name': '上海出版社', 'book_count': 1}, {'name': '人民出版社', 'book_count': 2}]>
方式二:以publish.id主键进行分组(结合queryset链式函数)
result = Publish.objects.values('nid').annotate(book_count=Count('book__title')).values('name','book_count')
print(result) #<QuerySet [{'name': '人民出版社', 'book_count': 2}, {'name': '上海出版社', 'book_count': 1}]>
- book__title:代表着用publish表去join book表
- 推荐方式二:
先join,再用publish的主键分组,最后一组values(‘name’,‘book_count’),要什么取什么
可以避免用publish.name分组出现name相同,id不同的重名对象分到一组
2. 多表分组查询2
查询每一个作者的名字以及出版过的书籍的最高价格
result = Author.objects.values('nid').annotate(max_price=Max('book__price')).values('name','max_price')
print(result) #<QuerySet [{'name': 'alex', 'max_price': 150}, {'name': 'egon', 'max_price': 100}]>
- 多表分组的ORM语法①:
(每一个)分组依据基础表.objects.values(“主键pk”).annotate(聚合函数(关联表__统计字段))
3. 多表分组查询3
查询每一个书籍的名称以及对应的作者个数
写法一:
result = Publish.objects.values('nid').annotate(book_count=Count('book__title')).values('name','book_count')
写法二:
result = Publish.objects.all().annotate(book_count=Count('book__title')).values('name','book_count')
写法三:
result = Publish.objects.annotate(book_count=Count('book__title')).values('name','book_count')
- 以上三种写法效果相同
应为分组依据为nid是一个主键,每条记录之间都是唯一的,等同于all()或者objects什么都不加 - 多表分组的ORM语法②:
(每一个)分组依据基础表.objects.all().annotate(聚合函数(关联表__统计字段))
4. 带过滤条件的多表分组查询
统计每一本以py开头的书籍的作者个数
result = Book.objects.filter(title__startswith='py').values('pk').annotate(count=Count('authors__name')).values('title','count)
统计书籍作者数大于1的
result = Book.objects.values('pk').annotate(count=Count('authors__name')).filter(count__gt=1).values('title','count')
- 先过滤,再分组查询
④F查询与Q查询
1. F查询——两个字段同时传入filter做比较
当查询中涉及到两个字段进行比较时,filter函数内只能传入一个字段,需要用F去查询另一个字段的值
- 第一步:在原Book表中插入两个新字段:阅读数和评论数

read_num = models.IntegerField(default=0) #必须设置默认值去匹配原有字段,后面再更新值
comment_num = models.IntegerField(default=0)
- 第二步:查询阅读数大于评论数的书籍名称
from django.db.models import F
result = Book.objects.filter(read_num__gt=F('comment_num')).values('title')
print(result) #<QuerySet [{'title': '红楼梦'}, {'title': '西游记'}]>
通过F(‘comment_num’)去查询到评论数的值
必须from django.db.models import F
2. Q查询——描述filter函数中且、或、非的关系
- 用filter只能描述且的关系,用逗号间隔多个条件
#查询书名叫红楼梦且价格等于100的书籍
result = Book.objects.filter(title='红楼梦',price=100)
- 用Q方法描述且、或、非
1. 且的关系在两个Q条件之间加&
result = Book.objects.filter(Q(title='红楼梦')&Q(price=100)).values('title')
print(result) #<QuerySet [{'title': '红楼梦'}]>
2. 或的关系在两个Q条件之间加|
result = Book.objects.filter(Q(title='红楼梦')|Q(price=150)).values('title')
print(result) #<QuerySet [{'title': '红楼梦'}, {'title': '西游记'}]>
3. 非的关系在Q条件前面加~
result = Book.objects.filter(~Q(title='红楼梦')).values('title')
print(result) #<QuerySet [{'title': '西游记'}, {'title': '三国演义'}]>
- 多重Q条件叠加
result = Book.objects.filter(~Q(Q(title='红楼梦')|Q(price=150))).values('title')
print(result) #<QuerySet [{'title': '三国演义'}]>
~Q( Q(title='红楼梦')|Q(price=150) ) #查询书名叫红楼梦或价格为150的书后,再取反
- Q条件结合filter
result = Book.objects.filter(~Q(Q(title='红楼梦')|Q(price=150)),price=200).values('title')
print(result) #<QuerySet [{'title': '三国演义'}]>
条件1:~Q( Q(title='红楼梦')|Q(price=150) )
条件2:price=200
Q条件和filter条件中间用逗号间隔,Q条件必须写在filter条件之前
九、Django与Ajax
①Ajax简介
1. 向服务器发送请求的途径:
- 浏览器地址栏,默认get请求
- form表单:支持get和post两种请求方式
- a标签:默认get请求
- Ajax请求:支持get和post请求
2. Ajax请求
AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步Javascript和XML”
即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML,现在更多使用json数据)
3. Ajax请求特点:
- 异步请求
- 同步交互:客户端发出一个请求后,需要等待服务器响应结束后,才能发出第二个请求;
- 异步交互:客户端发出一个请求后,无需等待服务器响应结束,就可以发出第二个请求。
- 浏览器页面局部刷新
这一特点给用户的感受是在不知不觉中完成请求和响应过程
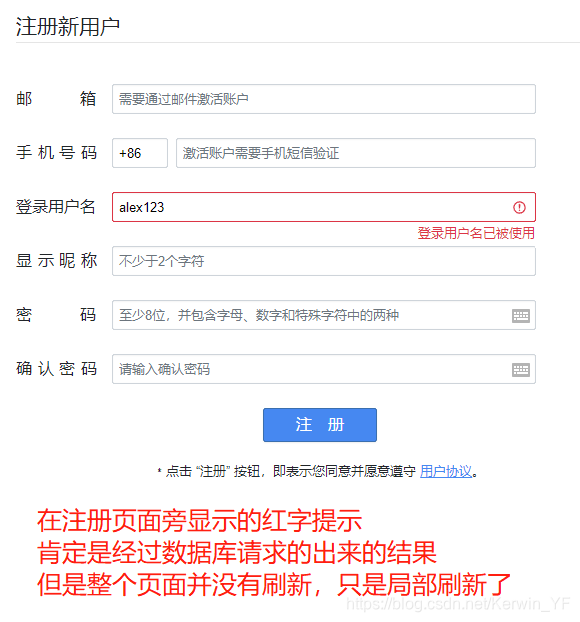
4. Ajax请求优点:
- AJAX使用Javascript技术向服务器发送异步请求
- AJAX无须刷新整个页面
②Ajax的GET请求
$.ajax({
url:'/test/',
type:'get',
success:function (data) {
$('.response').html(data).css('color','red')
}
})
包含3个参数:
- url:Ajax请求的路径
- type:请求的方式,get或post
- success:function (data){ … }:
回调函数,data为服务器响应回来的数据(例子中实现对标签插入红色字体的功能)
③Ajax的POST请求
$('.Ajax').click(function () {
$.ajax({
url:'/test/',
type:'get',
data:{username:'alex',password:'abc123'},
success:function (data) {
{#自己的代码逻辑#}
}
})
})
- data:{username:‘alex’,password:‘abc123’}
data为上传的数据,数据用字典键值对的形式发送,服务器还是一样的用request.POST.get(‘username’)获取数据 - success:function (data) {
{#自己的代码逻辑#}
}
data是服务器处理后返回来的数据
④视图函数views与jQuery的$.ajax之间的数据传输
通过HTTPResponse只能传输字符串,所以python数据类型与JavaScript数据类型的传输通过JSON序列化实现
- views代码:
def login(request):
user_info = {'username':'aelx','password':'abc123'}
import json
return HttpResponse(json.dump(user_info)) #转换成字符串进行传输
通过json.dump(user_info)转成字符串
- html文件中的jQuery代码:
$.ajax({
url:'/test/',
type:'get',
data:{username:'alex',password:'abc123'},
success:function (data) {
var user_info = JSON.parse(data); #转换成objects
var username = user_info.username;
var password = user_info.password;
}
})
通过JSON.parse(data)将数据转成JS的object(如果是python的列表就转成数组Array)
⑤基于form表单的文件上传
1. views视图函数:
def file_put(request):
if request.method == 'POST':
print(request.FILES) #一个文件对象<MultiValueDict: {'image': [<InMemoryUploadedFile: 8H 乳胶弹簧静音床垫 M3.jpg (image/jpeg)>]}>
file_obj = request.FILES.get('image')
with open(file_obj.name,'wb') as f: #file_obj有一个属性叫name,就是form选中文件的文件名:logo.png
for line in file_obj:
f.write(line)
return render(request,'file_put.html')
- form上传的文件都保存在request.FILES中,是一个字典类型,需要通过get(“filename”)取出
- with open(file_obj.name,‘wb’) as f
file_obj传来的文件对象都有一个name属性,就是客户端选中文件的文件名+文件类型(png)
必须使用wb打开,因为基于socket都是通过bytes类型传输
2. html模板层:
<form action="/file_put" method="post" enctype="multipart/form-data">
{% csrf_token %}
用户名 <input type="text" name="username">
头像 <input type="file" name="image">
<input type="submit" value="提交">
</form>
- form表单需要提交属性(编码方式):enctype=“multipart/form-data”
enctype默认为enctype=“application/x-www-form-urlencoded”,传过去的只是文件名
⑥请求头中的ContentType
ContentType指的是请求体的编码类型,告诉服务端解码的方式,分为三种:
- application/x-www-form-urlencoded
将请求体中的数据以url的encode方式编码,类似:user=yuan&age=22 - multipart/form-data
当post请求上传文件时,必须使用此编码方式 - application/json
应用json方式传输数据
⑦Ajax用json传输数据
1. html文件:
<form> #用ajax传输,form不要加任何参数
用户名 <input type="text" id="user">
密码 <input type="password" id="pwd">
<input type="button" value="提交" id="btn">
</form>
<script>
$('#btn').click(function () {
$.ajax({
url:'',
type:'post',
contentType:'application/json', #使用json解码
data:JSON.stringify( #JSON序列化成字符串
{username:'alex',password:'123'}
),
success:function (data){
console.log('OK')
}
})
})
- contentType:‘application/json’
说明使用json解码 - JSON.stringify(数据)
将数据转成字符串发过去,服务端再用JSON解码
2. views文件
def file_put(request):
if request.method == 'POST':
print(request.body) #b'{"username":"alex","password":"123"}'
print(request.POST) #<QueryDict: {}>
import json
userinfo = json.loads(request.body.decode('utf-8'))
print(userinfo) #{"username":"alex","password":"123"}
return HttpResponse('OK')
return render(request,'file_put.html')
- request.body
是请求体(请求报文中包含数据的部分),是bytes类型 - request.POST
只有contentType==urlencoded,请求解码方式为url解码时,POST才有数据(django自动解码),否则数据都在body中,需要自己解码 - json.loads(request.body.decode(‘utf-8’))
loads需要传入字符串的参数,所以需要decode
⑧基于Ajax的文件上传
1. html文件:
<body>
用户名<input type="text" id="username">
头像 <input type="file" id="file">
<input type="button" id="btn" value="提交">
<script>
$('#btn').click(function () {
var formdata = new FormData(); #生成一个新的formdata对象
formdata.append('username',$('#username').val()); #为formdata添加键值对username=$('#username').val()
formdata.append('file',$('#file')[0].files[0]); #为formdata添加文件的键值对
$.ajax({
url:'',
type:'post',
contentType:false, #代表不用编码去处理数据,因为上面的formData自己已经处理完了
processData: false, #代表不用对数据做预处理,如果为True要做预处理,再去看contentType用什么编码去做预处理
data:formdata,
success:function (data) {
console.log(data)
}
})
})
</script>
</body>
- var formdata = new FormData();
生成一个新的formdata对象 - formdata.append(‘username’,$ (‘#username’).val());
为formdata添加键值对username=$(‘#username’).val() - formdata.append(‘file’,$(‘#file’)[0].files[0]);
为formdata添加文件的键值对
$('#file')[0] #获取选择文件input标签的DOM节点:<input type="file" id="file">
$('#file')[0].files #files属性获取选中文件的list:FileList {0: File, length: 1}
$('#file')[0].files[0] #取出index为0的第一个文件
#File {name: "logo.png", lastModified: 1584367796016, lastModifiedDate: Mon Mar 16 2020 22:09:56 GMT+0800 (中国标准时间), webkitRelativePath: "", size: 742, …}
- processData: false,
代表不用对数据做预处理,如果为True要做预处理,再去看contentType用什么编码去做预处理 - contentType:false,
代表不用编码去处理数据,因为上面的formData自己已经处理完了 - data:formdata,
ajax传输的数据直接用上面生成的formdata对象(已经append好键值对)
2. views文件:
def ajax_file(request):
if request.method == 'POST':
print(request.body) #请求体包含数据:b'------WebKitFormBoundaryjgBpgXFZXrAUa9kY\r\nContent...
print(request.POST) #<QueryDict: {'username': ['Kerwin']}>
print(request.FILES) #文件对象<MultiValueDict: {'file': [<InMemoryUploadedFile: slogan.png (image/png)>]}>
file_obj = request.FILES.get('file')
with open(file_obj.name,'wb') as f:
for line in file_obj:
f.write(line)
return render(request,'ajax_file.html')
- request.FILES
所有上传的文件都只保存在request.FILES属性中
十、Django与分页器(Paginator)
①分页器——简单的分页效果
1. views文件
from app01.models import Book
from django.core.paginator import Paginator,EmptyPage #导入分页器和空白页面处理器
def index(request):
book_list = Book.objects.all()
paginator = Paginator(book_list,10) #实例化分页器对象,将book_list分页,每页10个数据
print(paginator.count) #数据总数:100
print(paginator.num_pages) #总页数:10
print(paginator.page_range) #页数的列表:range(1, 11)顾头不顾尾,100条数据每页10个,总共10页
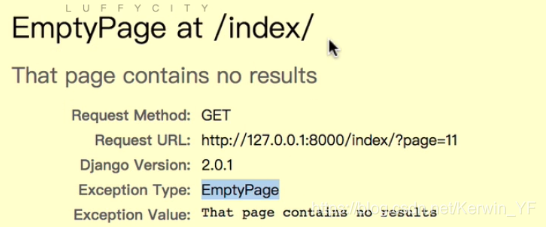
current_page_num = int(request.GET.get('page')) #通过url:http://127.0.0.1:8000/index/?page=1获取page的值
try:
current_page = paginator.page(current_page_num) #paginator.page(2)取到第2页的所有数据对象
#获取current_page内包含对象
#方式一:current_page.object_list
print(current_page.object_list) #<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (4)>, <Book: Book object (5)>, <Book: Book object (6)>, <Book: Book object (7)>, <Book: Book object (8)>, <Book: Book object (9)>, <Book: Book object (10)>]>
#方式二:
for i in current_page:
print(i) #Book object (1)、Book object (2)、Book object (3)。。。
except EmptyPage as e:
current_page = paginator.page(1) #页数的范围是第1-10页,如果超出范围例如-1、12页,就补货到错误跳转到第1页
return render(request,'index.html',locals())
- from django.core.paginator import Paginator,EmptyPage
导入分页器和空白页面处理器 - paginator = Paginator(object_list, per_page)
实例化分页器对象,将book_list分页,每页10个数据 - paginator.count
数据总数:100 - paginator.num_pages
总页数:10 - paginator.page_range
页数的列表:range(1, 11)顾头不顾尾,100条数据每页10个,总共10页 - current_page_num = int(request.GET.get(‘page’))
通过url:http://127.0.0.1:8000/index/?page=1获取page的值 - obj_list = paginator.page(2)
取到第2页的所有数据对象 - 获得当前页面的obj_list两种方法:
方法一:current_page.object_list
方法二:for循环obj_list - EmptyPage空白页面报错器,可以用try…except捕获进行异常处理
2. html文件
url访问路径:http://127.0.0.1:8000/index/?page=2
<body>
<ul>
{% for book in current_page %} #循环当前页面包含的所有数据对象
<li>{{ book.title }}:{{ book.price }}</li>
{% endfor %}
</ul>
</body>
②分页器——分页按钮

实现分页跳转页面,实现当前页面按钮变蓝色
1. html文件
引入Bootstrap的分页组件
<body>
#数据展示列表
<ul>
{% for book in current_page %}
<li>{{ book.title }}:{{ book.price }}</li>
{% endfor %}
</ul>
#分页按钮列表
<nav aria-label="Page navigation">
<ul class="pagination">
#编辑上一页按钮
{% if current_page.has_previous %} #如果当前页面有上一页
<li>
<a href="?page={{ current_page.previous_page_number }}" aria-label="Previous"> #a标签指向上一页
<span aria-hidden="true">上一页</span>
</a>
</li>
{% else %}
<li class="disabled"> #否则上一页按钮disabled不可以点击
<a href="" aria-label="Previous">
<span aria-hidden="true">上一页</span>
</a>
</li>
{% endif %}
#for循环,给每个a标签添加路径
{% for item in paginator.page_range %}
{% if current_page_num == item %} #判断当前页面是否与按钮数字一致,一致给a标签添加active类,使背景色变蓝
<li class="active"><a href="?page={{ item }}">{{ item }}</a></li>
{% else %}
<li><a href="?page={{ item }}">{{ item }}</a></li>
{% endif %}
{% endfor %}
#编辑下一页按钮
{% if current_page.has_next %}
<li>
<a href="?page={{ current_page.next_page_number }}" aria-label="Next">
<span aria-hidden="true">下一页</span>
</a>
</li>
{% else %}
<li class="disabled">
<a href="" aria-label="Next">
<span aria-hidden="true">下一页</span>
</a>
</li>
{% endif %}
</ul>
</nav>
</body>
- href=“?page={{ item }}”
以当前路径拼接url参数:http://127.0.0.1:8000/index/?page=5 - paginator获取关于上一页下一页的方法
page2=paginator.page(2)
print(page2.has_next()) #是否有下一页
print(page2.next_page_number()) #下一页的页码
print(page2.has_previous()) #是否有上一页
print(page2.previous_page_number()) #上一页的页码
③分页器——大量页码的居中显示

在views中修改page_range的范围
def index(request):
book_list = Book.objects.all()
paginator = Paginator(book_list,5) #实例化分页器对象,将book_list分页,每页10个数据
print(paginator.count) #数据总数:100
print(paginator.num_pages) #总页数:10
print(paginator.page_range) #页数的列表:range(1, 11)顾头不顾尾,100条数据每页10个,总共10页
current_page_num = int(request.GET.get('page'))
#修改page_range,当页面数量过多时,使页面按钮一直显示10个
if paginator.num_pages > 11: #按钮数=左5+右5+中间1=11,小于等于11页就正常全部显示
if current_page_num < 7: #当前页面为6或比6小时,只渲染按钮1-11页
page_range = range(1,12)
elif current_page_num > paginator.num_pages - 5: #当页面大于(最大页面-5)时,只渲染最后11页
page_range = range(paginator.num_pages-10,paginator.num_pages+1)
else:
page_range = range(current_page_num-5,current_page_num+6) #否则就显示当前页面-5至当前页面+5
else:
page_range = paginator.page_range
try:
current_page = paginator.page(current_page_num) #paginator.page(2)取到第2页的所有数据对象
#获取current_page内包含对象
#方式一:current_page.object_list
print(current_page.object_list) #<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (4)>, <Book: Book object (5)>, <Book: Book object (6)>, <Book: Book object (7)>, <Book: Book object (8)>, <Book: Book object (9)>, <Book: Book object (10)>]>
#方式二:
for i in current_page:
print(i) #Book object (1)、Book object (2)、Book object (3)。。。
except EmptyPage as e:
current_page = paginator.page(1) #页数的范围是第1-10页,如果超出范围例如-1、12页,就补货到错误跳转到第1页
return render(request,'index.html',locals())
十一、Django与forms组件
①forms组件的字段校验功能
通过自定义form.Form的类(forms组件),当类中定义的字段 = form表单name属性对应的值时,自动进行校验
1. 模型:models.py
class UserInfo(models.Model):
name = models.CharField(max_length=32)
pwd = models.CharField(max_length=32)
email = models.EmailField()
tel = models.CharField(max_length=32)
2. 模板:register.html
<form action="" method="post">
{% csrf_token %}
<p>用户名 <input type="text" name="name"></p>
<p>密码 <input type="text" name="pwd"></p>
<p>确认密码 <input type="text" name="re_pwd"></p>
<p>邮箱 <input type="text" name="email"></p>
<p>手机号 <input type="text" name="tel"></p>
<input type="submit">
</form>
3. 视图:views.py
from django import forms #引入forms模块
#定义一个校验的类
class UserForm(forms.Form): #固定格式,类名可以自定义,必须继承forms.Form
#字段的名字name、pwd等必须和html中form表单的name属性一一对应,因为后期request.POST(字典)会作为参数传给校验类UserInfo
name = forms.CharField(min_length=4) #用forms的char类型可以起到校验字段的功能
pwd = forms.CharField(min_length=4)
re_pwd = forms.CharField(min_length=4)
email = forms.EmailField()
tel = forms.CharField()
def register(request):
if request.method == 'POST':
#form = UserForm({'name':'alex','email':'123456@qq.com','XXX':'YYY'}) #将数据作为参数传给自定义的UserForm类,实例化一个对象
"""
1. 传入参数的key:name、email必须是类UserInfo内的定义字段
2. 如果传入的key不在UserInfo字段里(例如XXX),form校验会忽略它
"""
form = UserForm(request.POST) #request.POST = {'name':'alex','email':'123456@qq.com'...},直接将form提交过来的数据字典作为参数传给校验的UserForm类
print(form.is_valid()) #判断传入的数据是否(bool类型)符合定义的字段格式,即name是否大于4位,email是否为邮箱格式
#如果全部验证成功
if form.is_valid():
print(form.cleaned_data) #UserInfo校验成功的字段作为字典存在cleaned_data中{'name':'alex','email':'123456@qq.com'}
#如果有数据验证失败
else:
print(form.cleaned_data) #打印验证正确的字段
print(form.errors) #UserInfo校验失败的字段,字段名作为键,错误原因作为值(列表形式)以字典存在errors中{'name':['This field is required']}
return HttpResponse('OK')
return render(request,'register.html')
- form = UserForm(request.POST)
给自定义的forms组件传入html中form表单传来的数据(键值对的字典),并实例化对象form - form.is_valid()
bool类型,判断html中form表单来的数据是否全部合法 - form.cleaned_data
字典类型,存储校验正确的数据键值对 - form.errors
Django封装的特殊字典类型,存储校验失败的数据键值对,key = 错误字段,values = [ ‘错误信息’ ]
②forms组件的渲染标签功能
html文件中的input标签name属性值必须和forms组件校验字段的名字相同,Django可以帮助渲染html文件中的标签
1. 方式一:
- 视图:views
#定义一个forms组件
class UserForm(forms.Form):
name = forms.CharField(min_length=4)
pwd = forms.CharField(min_length=4)
re_pwd = forms.CharField(min_length=4)
email = forms.EmailField()
tel = forms.CharField()
def register(request):
form = UserForm() #实例化
return render(request,'register.html',locals()) #将forms组件实例化的对象传给模板htm
- 模板:html
<form action="" method="post">
{% csrf_token %}
<p>用户名{{ form.name }}</p> #<input type="text" name="name" minlength="4" required="" id="id_name">
<p>密码{{ form.pwd }}</p> #如果pwd字段从views传来的时候有值,那value也会渲染到页面上
<p>确认密码{{ form.re_pwd }}</p>
<p>邮箱{{ form.email }}</p>
<p>手机号{{ form.tel }}</p>
</form>
- {{ form.name }}渲染的结果是一个input标签:
< input type=“text” name=“name” minlength=“4” required=“” id=“id_name”>
如果视图函数中form=UserInfo(request.POST)在收到POST请求时有用户写过来的值,那么{{ form.name }}渲染的时候会保存值,避免用户只因为1个错误全部重写 - 通过{{ form.字段 }}渲染,Django自动写好input标签
2. 方式二:通过for循环forms组件的每个字段field
- 视图:views
#定义一个forms组件
class UserForm(forms.Form):
name = forms.CharField(min_length=4,label='用户名')
pwd = forms.CharField(min_length=4,label='密码')
re_pwd = forms.CharField(min_length=4,label='确认密码')
email = forms.EmailField(label='邮箱')
tel = forms.CharField(label='手机号')
给字段插入label参数的值
- 模板:html
<form action="" method="post">
{% for field in form %}
<p>
{{ field.label }} #UserInfo组件定义field时,传入的label参数值:'用户名'、'密码'
{{ field }} #UserInfo组件的各个字段:name、pwd、email等
</p>
{% endfor %}
</form>
③forms组件的渲染错误信息
- 模板:html
<form action="" method="post">
{% csrf_token %}
<p>{{ form.name.label }} {{ form.name }} <span>{{ form.name.errors.0 }}</span></p>
<p>{{ form.pwd.label }} {{ form.pwd }} <span>{{ form.pwd.errors.0 }}</span></p>
<p>{{ form.re_pwd.label }} {{ form.re_pwd }} <span>{{ form.re_pwd.errors.0 }}</span></p>
<p>{{ form.email.label }} {{ form.email }} <span>{{ form.email.errors.0 }}</span></p>
<p>{{ form.tel.label }} {{ form.tel }} <span>{{ form.tel.errors.0 }}</span></p>
<input type="submit">
</form>
{{ form.name.errors.0 }}
form.name是forms校验组件中name字段这个对象,它的errors属性是一个列表,存储校验错误信息,通过.0获取
④forms组件的参数配置
1. 设置forms组件渲染input标签的类型
- 视图:views.py
from django.forms import widgets
#定义一个校验的类
class UserForm(forms.Form):
name = forms.CharField(min_length=4,label='用户名')
pwd = forms.CharField(min_length=4,label='密码',widget=widgets.PasswordInput)
re_pwd = forms.CharField(min_length=4,label='确认密码')
email = forms.EmailField(label='邮箱')
tel = forms.CharField(label='手机号')
- 导入模块widgets:from django.forms import widgets
- 字段中设置widget=widgets.PasswordInput
- 还有widgets.TextInput、widgets.CheckboxInput等
2. 设置forms组件渲染标签的属性(修改CSS)
- 视图:views.py
from django import forms #引入forms模块
from django.forms import widgets
#定义一个校验的类
class UserForm(forms.Form):
name = forms.CharField(min_length=4,label='用户名',widget=widgets.TextInput(attrs={'class':'form-control'}))
pwd = forms.CharField(min_length=4,label='密码',widget=widgets.PasswordInput(attrs={'class':'form-control'}))
re_pwd = forms.CharField(min_length=4,label='确认密码',widget=widgets.TextInput(attrs={'class':'form-control'}))
email = forms.EmailField(label='邮箱',widget=widgets.EmailInput(attrs={'class':'form-control'}))
tel = forms.CharField(label='手机号',widget=widgets.TextInput(attrs={'class':'form-control'}))
- widget=widgets.TextInput(attrs={‘class’:‘form-control’})
在TextInput等类型的input标签内通过attrs={“属性”:“值”}去控制Django自动渲染标签时为标签添加属性
渲染后的标签如下:
#类名配合Bootstrap调整样式
<input type="text" name="name" class="form-control" minlength="4" required="" id="id_name">
3. 设置forms组件渲染错误信息的文字
- 视图:views.py
from django import forms #引入forms模块
from django.forms import widgets
#定义一个校验的类
class UserForm(forms.Form):
name = forms.CharField(min_length=4,label='用户名',error_messages={'required':'该字段不能为空'})
pwd = forms.CharField(min_length=4,label='密码',widget=widgets.PasswordInput)
re_pwd = forms.CharField(min_length=4,label='确认密码')
email = forms.EmailField(label='邮箱')
tel = forms.CharField(label='手机号')
- 在forms组件定义类的字段时插入error_messages
- error_messages的值为一个字典,包含错误类型和提示文字
- 错误类型包括:reuqired不为空,invalid无效的
⑤forms组件校验的局部钩子——自定义校验单个字段
1. 先理解源码功能实现
以下是Django中forms组件校验单个字段的一部分代码(局部钩子)
def _clean_fields(self):
for name, field in self.fields.items():
'''name就是forms组件中的字段,field就是校验的规则:forms.CharField(min_length=4)'''
if field.disabled:
value = self.get_initial_for_field(field, name)
else:
value = field.widget.value_from_datadict(self.data, self.files, self.add_prefix(name))
try:
if isinstance(field, FileField):
initial = self.get_initial_for_field(field, name)
value = field.clean(value, initial)
else:
#1. 首先forms组件字段校验,通过field.clean的方法对用户输入的value进行校验
value = field.clean(value)
self.cleaned_data[name] = value
#2. 再进行用户自定义校验功能
if hasattr(self, 'clean_%s' % name): #判断对象是否有clean_字段名方法?
value = getattr(self, 'clean_%s' % name)() #有的话就执行,获得返回值
self.cleaned_data[name] = value #如果自定义校验成功,就添加进校验成功的cleaned_data中
except ValidationError as e: #如果捕获到Validation错误,就加入errors错误信息中
self.add_error(name, e)
- 用户自定义的校验方法函数名称必须为:clean_字段名
- 用户自定义校验方法如果校验失败,raise Validation错误,并发送错误信息
- 第一步:forms组件校验,成功就放入cleaned_data里;第二步:用户自定义的方法clean_字段进行校验
2. 自定义校验注册用户名是否已存在

from django.core.exceptions import ValidationError #导入ValidationError方法
class UserForm(forms.Form):
name = forms.CharField(min_length=4,label='用户名',widget=widgets.TextInput(attrs={'class':'form-control'}),error_messages={'required':'该字段不能为空'})
pwd = forms.CharField(min_length=4,label='密码',widget=widgets.PasswordInput(attrs={'class':'form-control'}))
re_pwd = forms.CharField(min_length=4,label='确认密码',widget=widgets.TextInput(attrs={'class':'form-control'}))
email = forms.EmailField(label='邮箱',widget=widgets.EmailInput(attrs={'class':'form-control'}))
tel = forms.CharField(label='手机号',widget=widgets.TextInput(attrs={'class':'form-control'}))
1. 函数名称必须为clean_字段名
def clean_name(self):
val = self.cleaned_data.get('name') #用户输入已经通过forms字段校验,存入cleaned_data中
find_name = UserInfo.objects.filter(name=val) #查询数据库中是否用户名重复的对象
if find_name: #如果找到了,报错Validation让Django捕获
raise ValidationError('用户名已存在')
else:
return val
- 导入ValidationError方法
3. 自定义校验手机号是否为11位

def clean_tel(self):
val = self.cleaned_data.get('tel')
if len(val) == 11:
return val
else:
raise ValidationError('手机号码必须为11位')
⑥forms组件校验的全局钩子——自定义校验多个字段
1. 先理解源码功能实现
以下是Django中forms组件校验多个字段的一部分代码(全局钩子)
def _clean_form(self):
try:
cleaned_data = self.clean() #全局钩子:如果全部校验成功,将cleaned_data原封不动返还
except ValidationError as e:
self.add_error(None, e) #字典的key为None时,会加进__all__中:errors={'__all__':[e1,e2,e3...]}
else:
if cleaned_data is not None:
self.cleaned_data = cleaned_data
- 用户自定义校验多字段(全局钩子)的函数名必须为:clean方法,覆盖掉源码的clean()方法
- 全局钩子的错误信息存储在errors={‘_ all _’:[e1,e2,e3…]},key为’ _ _ all _ _’
2. 自定义校验密码与确认密码是否一致

- 视图:views
from django import forms #引入forms模块
from app01.models import UserInfo
from django.core.exceptions import ValidationError
#定义一个校验的类
class UserForm(forms.Form):
name = forms.CharField(min_length=4,label='用户名')
pwd = forms.CharField(min_length=4,label='密码')
re_pwd = forms.CharField(min_length=4,label='确认密码')
email = forms.EmailField(label='邮箱')
tel = forms.CharField(label='手机号')
#定义全局钩子
def clean(self):
pwd = self.cleaned_data.get('pwd')
re_pwd = self.cleaned_data.get('re_pwd')
if pwd == re_pwd:
return self.cleaned_data
else:
raise ValidationError('两次输入的密码不一致')
def register(request):
if request.method == 'POST':
form = UserForm(request.POST) 1. 带参数校验的form对象(包含校验结果clean或error)
#将全局钩子复制给errors,传给模板html
errors = form.errors.get('__all__')
return render(request,'register.html',locals())
form = UserForm() 2. 不带参数校验的form对象(不包含校验结果)
return render(request,'register.html',locals())
- errors = form.errors.get(‘_ all ‘)
全局钩子报错的信息存储在errors={’ all _’:[e1,e2,e3…]},key为’ _ _ all _ _’ - 模板:html
<form action="" method="post">
{% csrf_token %}
<p>用户名 <input type="text" name="name"> <span>{{ form.name.errors.0 }}</span></p>
<p>密码 <input type="text" name="pwd"> <span>{{ form.pwd.errors.0 }}</span></p>
#errors是视图传来的全局钩子错误信息,用.0取出
<p>确认密码 <input type="text" name="re_pwd"> <span>{{ form.re_pwd.errors.0 }}{{ errors.0 }}</span></p>
<p>邮箱 <input type="text" name="email"> <span>{{ form.email.errors.0 }}</span></p>
<p>手机号 <input type="text" name="tel"> <span>{{ form.tel.errors.0 }}</span></p>
<input type="submit">
</form>
- {{ errors.0 }}
errors是views传来的用’_ _ all _ _'取出全局钩子报错信息,用.0取出
⑦forms组件解耦合
所有关于forms组件(验证)的class UserInfo应该写到app01下的单独py文件中,命名不要叫forms(避免与Django碰撞)
十二、Django与cookie
①HTTP协议的无状态保存
客户端与服务端每次请求之间互不关联,称为无状态保存
如果想要第二次请求知道第一次请求的相关数据,需要用到会话跟踪技术(例如:淘宝加载页面需要知道是否已经登录)
会话跟踪技术——在一个会话的多个请求中共享数据
②cookie简介
Cookie——具体的一个浏览器,针对一个服务器,存储的key-value结构(字典)
- 具体的一个浏览器
不同的浏览器存储不同的cookie在磁盘中(一般有效期2周,可设置),相互独立 - 针对一个服务器
特定浏览器存储的cookie只针对特定的一个服务器,相互独立 - key-value结构
可以理解为python中的字典,例如{‘login’:True},服务器可以拿到判断用户是否登录
cookie一旦生成,在每次的请求中都会携带
③cookie的设置与读取
1. 设置cookie
- 本质上render、redirect类都是基于HttpResponse类
参考源码可以看出,render、redirect方法都是在HttpResponse上附加的操作
响应体:
return render()
return redirect()
return HttpResponse()
- set_cookie(key,value)
def login(request):
if request.method == "POST":
user = request.POST.get('user')
pwd = request.POST.get('pwd')
user_obj = UserInfo.objects.filter(user=user,pwd=pwd).first()
if user_obj:
response = HttpResponse('登陆成功') #设置响应体
response.set_cookie('is_login',True) #为响应体设置cookie
return response
return render(request,'login.html')
2. 读取cookie
进入首页时,判断用户是否登陆,如果未登陆就返回登陆界面
def index(request):
print(request.COOKIES) #{'is_login': 'True'}
is_login = request.COOKIES.get('is_login')
if is_login: #如果已经登陆成功,进入首页
return render(request,'index.html')
else: #否则返回登陆页面
return redirect('/login/')
- request.COOKIES
cookie保存在request中,是字典的形式{‘is_login’: ‘True’}
③cookie设置超长时间
设置cookie的存储事件,超过时间cookie失效
1. max_age=None
设置未来时间cookie数据失效,单位:秒
def login(request):
if request.method == "POST":
user = request.POST.get('user')
pwd = request.POST.get('pwd')
user_obj = UserInfo.objects.filter(user=user,pwd=pwd).first()
if user_obj:
response = redirect('/index/')
response.set_cookie('is_login',True,max_age=20) #设置is_login未来20秒内生效
return response
return render(request,'login.html')
2. expires=None
设置固定时间点cookie数据失效
import datetime
date = datetime.datetime(year=2020,month=6,day=2,hour=12,minute=29,second=50)
response.set_cookie('is_login',True,expires=date)
因为东八区,注意小时等于中国时间往前减8小时
④cookie设置有效路径
1. path=‘/’
在该路径下,视图函数才能获取cookie,默认为根目录
response.set_cookie('is_login',True,path='/index/')
⑤删除cookie
response.delete_cookie('is_login')
⑥cookie简单运用——上次登陆时间
- 设置时区
setting文件中设置TimeZone
TIME_ZONE = 'Asia/Shanghai'
- 视图:views
def time(request):
import datetime
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
last_visit_time = request.COOKIES.get('last_visit_time','首次登陆') #从历史cookie中获取上次登陆时间
response = render(request,'time.html',locals())
response.set_cookie('last_visit_time',now) #将当前时间设置为新的上次登陆时间
return response
十三、Django与session
①session简介
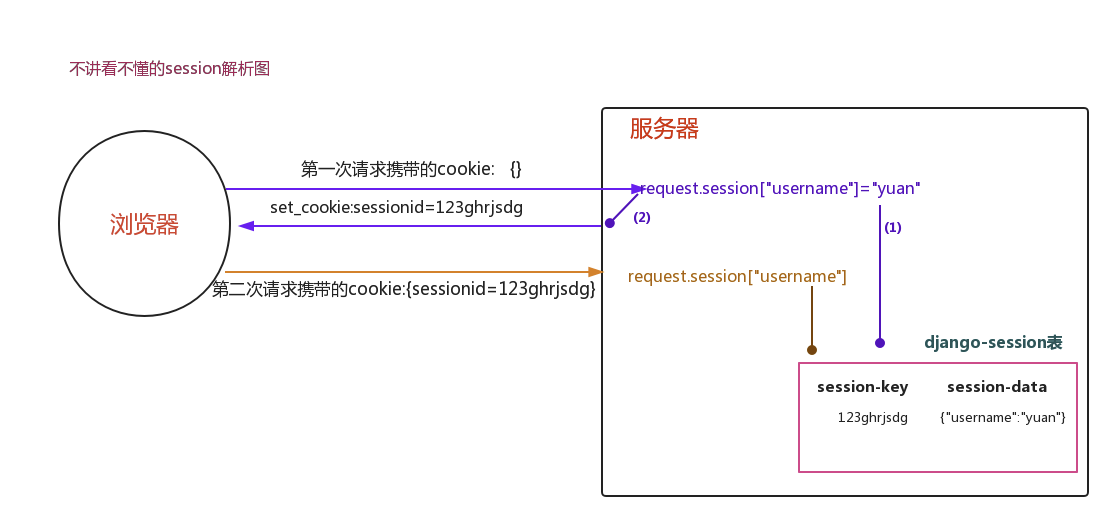
1. 使用cookie带来的问题
cookie的数据存储在浏览器(客户端)中,可以被直接看到,数据不安全
session的数据存储在服务器中,传输过程中cookie只包含一个随机字符串session-key,它就像一把钥匙,可以打开数据库中djang_session表内的数据
2. session实现步骤
- 第一次访问服务器,带着空的cookie:{},但包含登陆input输入的用户名
在服务器会有以下三步骤:
- 写入数据(session-data)进djang_session表
request.session[‘username’]=‘alex’ - 生成钥匙
set_cookie——sessionid=随机字符串 - 在djang_session中对应的记录
session-key对应session-data
- 下一次访问服务器,带着钥匙的cookie:{‘sessionid’:随机字符串}
在服务器会有以下三步骤:
- 读取数据指令:request.session[‘username’]
- 通过cookie获取钥匙session-key
- 带着session-key去djang_session找寻记录,获取session-data
②session的设置与读取
1. 设置session
def login_session(request):
if request.method == "POST":
user = request.POST.get('user')
pwd = request.POST.get('pwd')
user_obj = UserInfo.objects.filter(user=user,pwd=pwd).first()
if user_obj:
request.session['is_login'] = True #写入{'is_login':'True'}
request.session['username'] = user
return render(request,'login.html')
完成后会在djang_session表中存入记录,session_data做了加密处理

2. 读取session
def index_session(request):
username = request.session.get('username') #获取sessionid对应的key(随机字符串),再去djang_session表中去找session_data
return render(request,'index.html',{'username':username})
③session的更新覆盖情况
def login_session(request):
if request.method == "POST":
user = request.POST.get('user')
pwd = request.POST.get('pwd')
user_obj = UserInfo.objects.filter(user=user,pwd=pwd).first()
if user_obj:
request.session['is_login'] = True
request.session['username'] = user #第一次user=alex,第二次user=egon
return HttpResponse('Hello %s'%user)
return render(request,'login.html')
上述情况,第一次用alex登陆,第二次用egon登陆
由于谷歌浏览器的sessionid只有一个,在做request.session[‘username’] = user会覆盖更新

④删除session
1. del删除session_data中单个key
del request.session['username']
2. flush() 删除当前浏览器的整个session
request.session.flush()
"""
内部做了如下操作:
session_key = request.COOKIES.get('sessionid') #获得钥匙
django_session.objects.filter(session_key=session_key).delete() #删除django_session表中的该条记录
response.delete_cookie('sessionid') #把钥匙也删除了
"""
④session设置超长时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
⑤session的配置参数
在Django的setting文件下添加如下配置:
SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认)
SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串(默认)
SESSION_COOKIE_PATH = "/" # Session的有效路径
SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)(默认)
SESSION_EXPIRE_AT_BROWSER_CLOSE = False #是否关闭浏览器使得Session过期(默认)
SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存(默认),例如每次请求保存会将生效日期更新延长
十四、Django与用户认证组件
①用户认证组件简介
1. 数据库迁移,创建auth_user表
通过命令行进行数据库迁移
python manage.py makemigrations
python manage.py migrate
Django自动创建auth_user表
2. 创建超级用户
命令行创建:python manage.py createsuperuser

②用户认证组件的登陆验证功能——auth模块
1. 自己用session存在的问题
- A用户用谷歌浏览器访问服务器的sessionid随机字符串时一样的
- 然后B用户再去访问的时候还是一样的sessionid,此时session_data会进行更新
- 出现session_data中的key:value混合存储,数据混乱
- auth组件内部处理更严谨,B用户登录时会将sessionid和session_data同时更新

2. 视图views应用用户认证auth模块
from django.contrib import auth
def login(request):
if request.method == 'POST':
user = request.POST.get('user')
pwd = request.POST.get('pwd')
#如果验证成功返回user对象,否则返回None
user = auth.authenticate(username=user,password=pwd)
if user:
auth.login(request,user) #内部通过session绑定user,以后调用request.user = user(当前登录对象)
#未登陆之前,request.user是一个匿名对象(auth_user里面的字段都是空值)
return redirect('/index/')
return render(request,'login.html')
- 导入auth模块:from django.contrib import auth
- 用户认证:authenticate()
即验证用户名以及密码是否正确,一般需要username password两个关键字参数
如果验证成功返回user对象,否则返回None - 绑定请求和当前user:login(HttpRequest, user)
内部通过session绑定user(在session表中创建一条记录session_id和session_data)以后调用request.user = user(当前登录对象)
未登陆之前,request.user是一个匿名对象anonymous(auth_user里面的字段都是空值) - 通过auth.login(request,user)绑定user后,通过其他路径访问user对象的账户信息
def index(request):
print(request.user) #alex对象
print(request.user.username) #alex
print(request.user.id) #1
print(request.user.is_anonymous) #False 判断是否为匿名对象
return render(request,'index.html',locals())
③用户认证组件的注销功能——auth模块
def logout(request):
auth.logout(request)
return redirect('/index/')
- auth.logout(request)
解除当前请求与user的绑定

④用户认证组件的User对象方法
1. 判断用是否通过了认证:is_authenticated
1. login路径进行过了user验证,并绑定到request
#如果验证成功返回user对象,否则返回None
user = auth.authenticate(username=user,password=pwd)
auth.login(request,user)
2. index首页路径判断user是否通过了认证
def index(request):
if request.user.is_authenticated:
#通过认证就进入购物车
else:
#未通过认证就返回登陆界面
2. 创建新用户:create_user
def register(request):
if request.method == "POST":
user = request.POST.get('user')
pwd = request.POST.get('pwd')
from django.contrib.auth.models import User #引入auth_user表模型
user_obj = User.objects.create_user(username=user,password=pwd)
return redirect('/login/')
return render(request,'register.html')
- User.objects.create_user(username=user,password=pwd)
由于存储到auth_user中是经过哈希加密的,所以不能直接用objects.create,要用create_user
3. 修改密码
- 修改密码前首先验证旧密码输入是否正确
check_password(passwd)
- 修改新密码
使用 set_password() 来修改密码
user = User.objects.get(username='')
user.set_password(password='')
user.save
⑤判断是否认证的装饰器login_required
1. 应用场景
- 设计一个login页面,判断用户是否登陆成功
- 设计查看订单页面,如果用户未登录返回登陆界面
- 设计查看账户页面,如果用户未登录返回登陆界面
类似的场景有很多条件都是在登陆的情况下再访问页面的,Django提供了login_required装饰器解决
2. login_required装饰器语法
from django.contrib.auth.decorators import login_required
@login_required
def order(request):
若用户没有登录,则会跳转到自定义的login路径(这个值可以在settings文件中通过LOGIN_URL进行修改)
并且转到login页面的URL后面加参数?next=/当前页面路径/


3. 查看订单、查看账户前提条件登陆验证示例
- setting配置
LOGIN_URL = '/login/'
- 视图:views
1. 登陆页面
def login(request):
if request.method == 'POST':
user = request.POST.get('user')
pwd = request.POST.get('pwd')
#验证账户密码是否正确
user = auth.authenticate(username=user,password=pwd)
if user:
auth.login(request,user) #验证成功,在session中生成记录
next_url = request.GET.get('next','/index/') #获取请求路径中的数据:?next=/order/
#如果没有参数next,默认返回首页index
return redirect(next_url)
return render(request,'login.html')
login函数中返回值redirect应该是动态的next_url
#导入login_required函数
from django.contrib.auth.decorators import login_required
2. 查看订单页面
@login_required #加上装饰器,如果没有认证先去login页面,登陆成功后跳转回来order页面
def order(request):
return render(request,'order.html')
3. 查看账户页面
@login_required
def account(request):
return render(request,'account.html')
十五、Django与中间件(Middleware)
①中间件的实现流程
1. 中间件的介绍
中间件是介于request与response处理之间的一道处理过程,并且在全局上改变django的输入与输出,因为改变的是全局,所以需要谨慎实用,用不好会影响到性能
Django默认的Middleware:
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
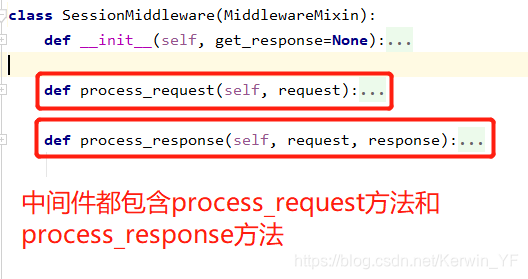
2. 完整的http请求响应流程图
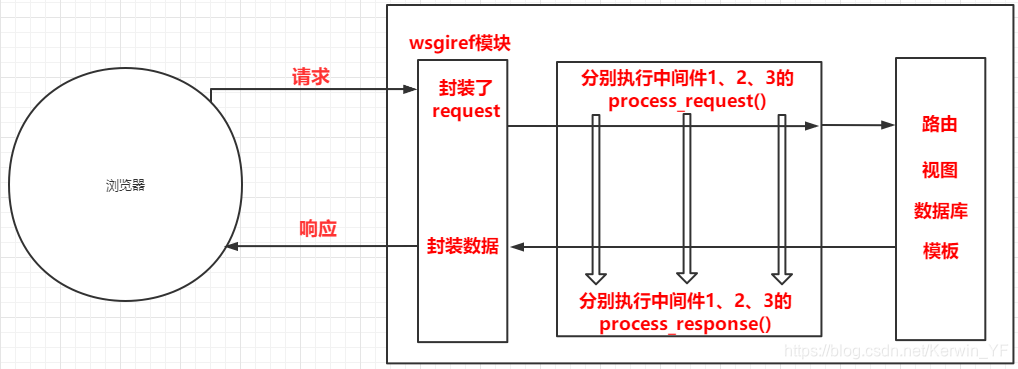
- 无论请求到哪个url函数,整个过程必定经过中间件流程
3. 每次请求和响应都会依次执行中间件的process_request和process_response方法
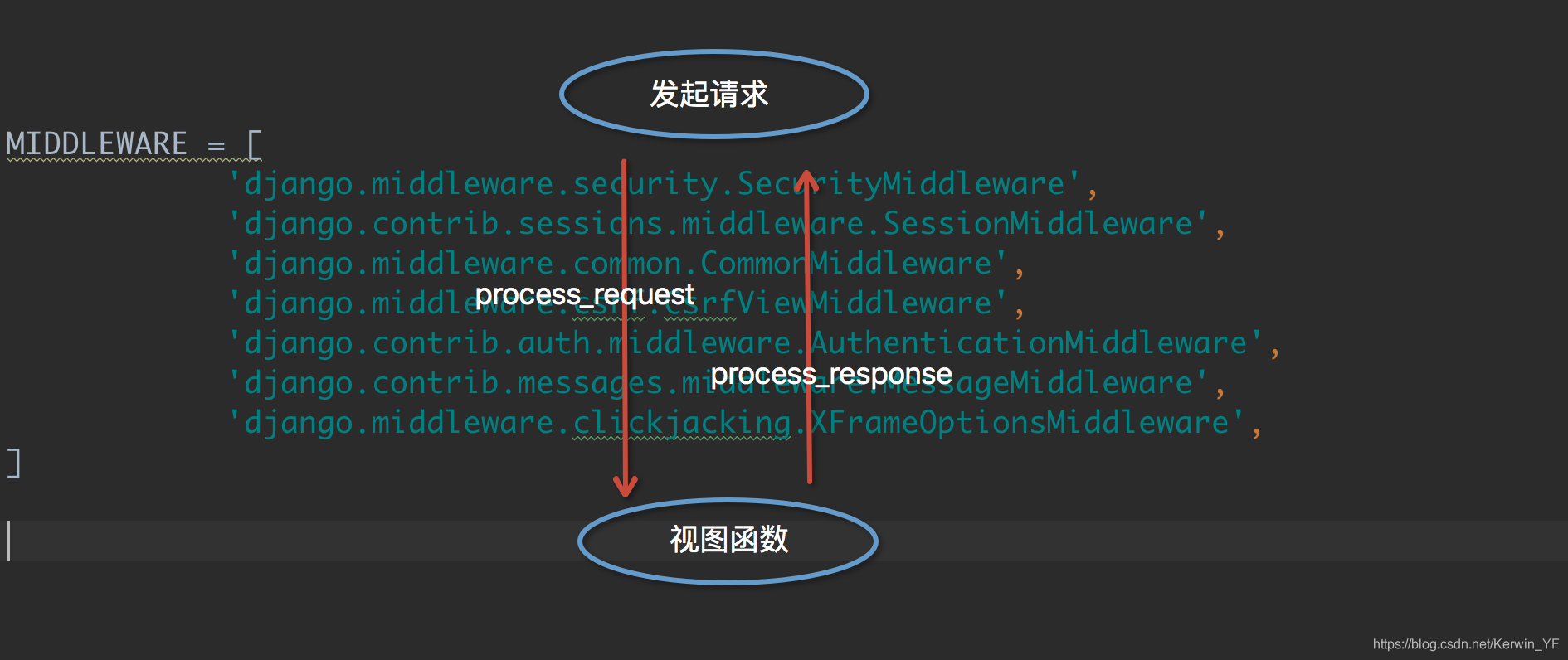
②自定义中间件
1. 创建中间件.py文件
2. 编写自定的中间件
from django.utils.deprecation import MiddlewareMixin #导入MiddlewareMixin类
class Mymiddleware(MiddlewareMixin): #必须继承MiddlewareMixin类
def process_request(self,request): #必须传入request参数
print('中间件生效成功')
3. 在setting中配置自定义中间件
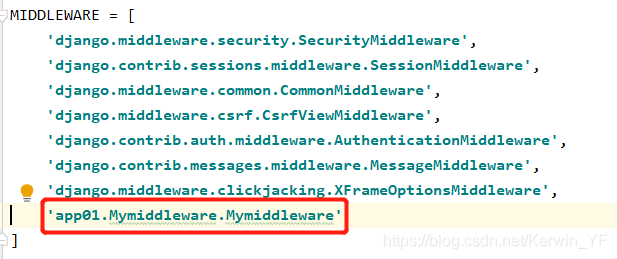
4. 每次访问服务器(不论url)都会执行中间件
③process_request和process_response方法
from django.utils.deprecation import MiddlewareMixin #导入MiddlewareMixin类
class Mymiddleware(MiddlewareMixin): #必须继承MiddlewareMixin类
def process_request(self,request): #必须传入request参数
print('中间件: process_request')
# return HttpResponse('不符合判断条件,Forbidden')
def process_response(self,request,response): #response就是视图传来的响应对象:render(request,'index.html')
print('中间件: process_response')
return response
- request请求时,中间件从前往后执行
response响应时,中间件从后往前执行

- request和response都要传入参数:request
process_response还要传参response,就是views处理完成返回来的响应对象:render(request,‘index.html’) - process_response必须要有return值response
- 如果process_request有返回值,将切断后续的中间件及view执行,直接通过自己的process_response返回值
class Mymiddleware(MiddlewareMixin): #必须继承MiddlewareMixin类
def process_request(self,request): #必须传入request参数
print('中间件: process_request')
if #访问次数过多,疑似机器人访问
return HttpResponse('禁止访问')
def process_response(self,request,response): #response就是视图传来的响应对象:render(request,'index.html')
print('中间件: process_response')
return response
④process_view方法
process_view(self, request, callback, callback_args, callback_kwargs)
1. Mymiddlewares.py修改如下
from django.utils.deprecation import MiddlewareMixin
from django.shortcuts import HttpResponse
class Md1(MiddlewareMixin):
def process_request(self,request):
print("Md1请求")
#return HttpResponse("Md1中断")
def process_response(self,request,response):
print("Md1返回")
return response
def process_view(self, request, callback, callback_args, callback_kwargs):
print("Md1view")
class Md2(MiddlewareMixin):
def process_request(self,request):
print("Md2请求")
return HttpResponse("Md2中断")
def process_response(self,request,response):
print("Md2返回")
return response
def process_view(self, request, callback, callback_args, callback_kwargs):
print("Md2view")
打印结果:
Md1请求
Md2请求
Md1view
Md2view
view函数...
Md2返回
Md1返回
- callback——就是url映射到的views视图函数:<function index at 0x000001C2F6496790>
2. process_view流程图
当最后一个中间的process_request到达路由关系映射之后,返回到中间件1的process_view,然后依次往下,到达views函数,最后通过process_response依次返回到达用户
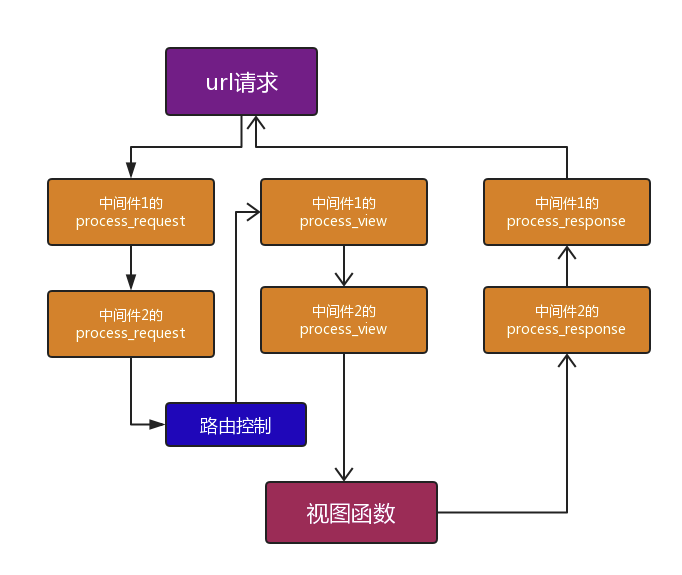
3. process_view可以用来调用视图函数
callback参数就是对应的视图函数(内存地址)
class Md1(MiddlewareMixin):
def process_request(self,request):
print("Md1请求")
#return HttpResponse("Md1中断")
def process_response(self,request,response):
print("Md1返回")
return response
def process_view(self, request, callback, callback_args, callback_kwargs):
# return HttpResponse("hello")
response=callback(request,*callback_args,**callback_kwargs)
return response
注意:process_view如果有返回值,会越过其他的process_view以及视图函数,但是所有的process_response都还会执行。
⑤process_exception方法
只有视图函数出错时才会执行
1. Mymiddlewares.py修改如下
from django.utils.deprecation import MiddlewareMixin #导入MiddlewareMixin类
from django.shortcuts import HttpResponse
class Mymiddleware(MiddlewareMixin): #必须继承MiddlewareMixin类
def process_request(self,request): #必须传入request参数
print('中间件: process_request')
def process_view(self, request, callback, callback_args, callback_kwargs):
print(callback)
def process_response(self,request,response): #response就是视图传来的响应对象:render(request,'index.html')
print('中间件: process_response')
return response
def process_exception(self, request, exception): #exception是报错信息
return HttpResponse(exception)
当views报错时。想要设计好看一点的报错信息页面,可以通过exception中自己return页面操作
2. process_exception流程图
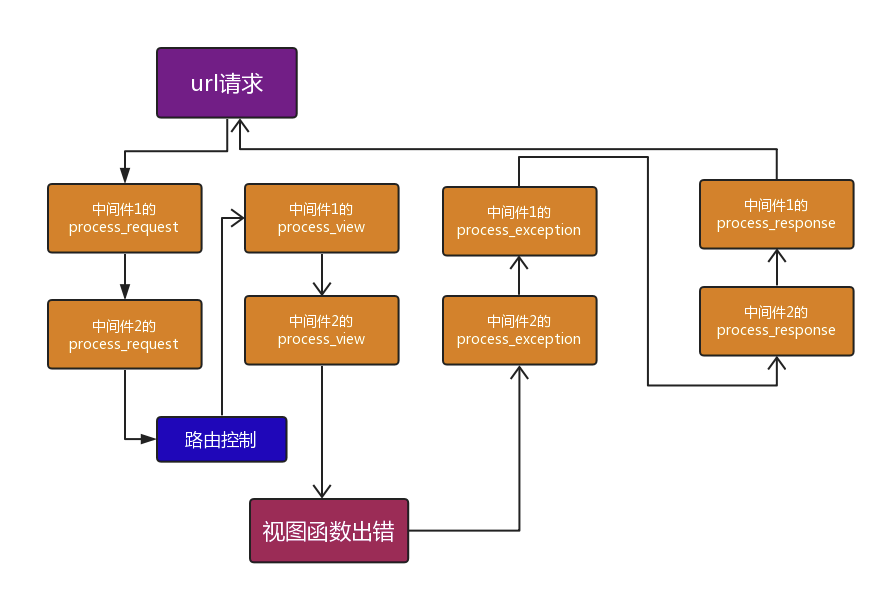
⑥中间件的应用——URL访问过滤
如果用户访问的是login视图(放过)
如果访问其他视图,需要检测是不是有session认证,已经有了放行,没有返回login,这样就省得在多个视图函数上写装饰器了!
from django.utils.deprecation import MiddlewareMixin
from django.shortcuts import redirect
from auth.settings import WHITE_LIST #从setting中导入白名单
class AuthMiddleware(MiddlewareMixin):
def process_request(self,request):
#过滤login,register,logout访问正常通过
if request.path in WHITE_LIST:
return None #不经过下面的校验了
if not request.user.is_authenticated: #如果用户没有被认证成功,就重定向至登陆界面
return redirect('/login/')
- return None
可以中断当前函数执行














 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









