







redis的官网地址,非常好记,是redis.io。
好了,现在对redis有个认识了吧,今天我们讲的是redis集群,他解决了解决redis横向扩展的问题 ,集群的几种实现方式:客户端分片,基于代理的分片,路由查询 。
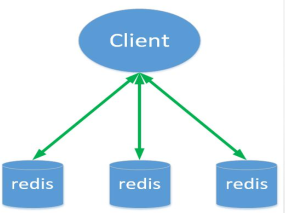
客户端分片
由客户端决定key写入或者读取的节点。包括jedis在内的一些客户端,实现了客户端分片机制。优点:简单,性能高
缺点:业务逻辑与数据存储逻辑耦合,可运维性差,多业务各自使用redis,集群资源难以管理,不支持动态增删节点
结构图:
基于代理的分片
客户端发送请求到一个代理,代理解析客户端的数据,将请求转发至正确的节点,然后将结果回复给客
结构图:
特性:
透明接入,业务程序不用关心后端Redis实例,切换成本低。Proxy 的逻辑和存储的逻辑是隔离的。代理层多了一次转发,性能有所损耗。
开源方案:Twemproxy,codis
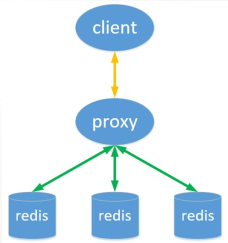
Twemproxy:
Proxy-basedtwtter开源,C语言编写,单线程。
支持 Redis 或 Memcached 作为后端存储。
优点:支持失败节点自动删除,与redis的长连接,连接复用,连接数可配置。自动分片到后端多个redis实例上。多种hash算法:能够使用不同的分片策略和散列函数,可以设置后端实例的权重
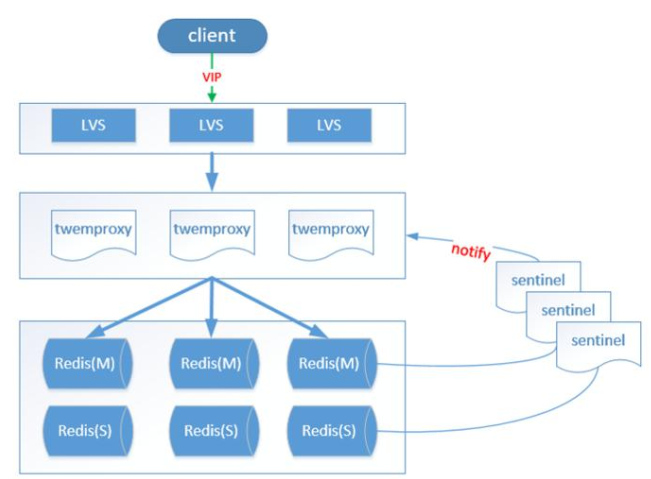
缺点:
性能低:代理层损耗 && 本身效率低下
Redis功能支持不完善:不支持针对多个值的操作
本身不提供动态扩容,透明数据迁移等功能
结构图:
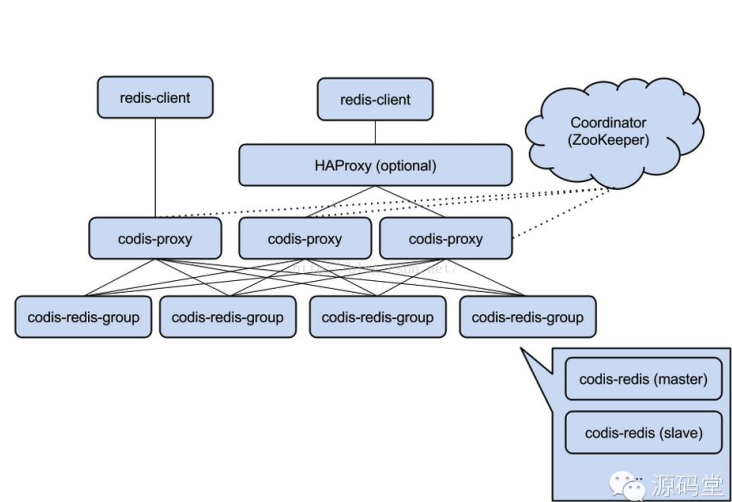
Codis
由豌豆荚于2014年11月开源,基于Go和C开发,是近期涌现的、国人开发的优秀开源软件之一。现已广泛用于
豌豆荚的各种Redis业务场景。从3个月的各种压力测试来看,稳定性符合高效运维的要求。性能更是改善很多,最初
比Twemproxy慢20%;现在比Twemproxy快近100%(条件:多实例,一般Value长度)。
Redis-cluster
我们今天的重点哦,redis官网推出,可线性扩展到1000个节点,无中心架构,一致性哈希思想,客户端直连redis服务,免去了proxy代理的损耗 相当方便,Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况
下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的
优势:
自动分割数据到不同的节点上。
整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,
举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽. magedu
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中得槽移到B和C节
点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节
点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了不过当B和B1 都失败后,集群是不可用的.
Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
客户端向主节点B写入一条命令.
主节点B向客户端回复命令状态.
主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点
处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写
的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少
数实例被孤立。

具体配置:
- 创建三个目录:mkdir -p /data/redis_cluster/7000 /data/redis_cluster/7001 /data/redis_cluster/7002
- 为了启动不冲突,修改配置文件:cp /etc/redis.conf 7000
vim 7000/redis.conf
bind 172.16.250.233本机IPport 7000
daemonize yes //redis后台运行
pidfile /var/run/redis_7000.pid //pidfile文件对应7000,7001,7002
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置
| appendonly yes | //aof日志开启 有需要就开启,它会每次写操作都记录一条日志 |
- 把修改后的文件拷进另外俩目录里:

然后把7000改成7001,7002
- 启动并查看进程:
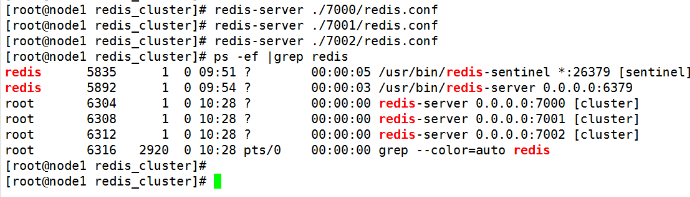
copy工具
下载安装包:

解压文件:

进入目录:cd redis-3.2.3/src/
里面有个redis-trib.rb脚本,现在我们需要安装运行它的环境:
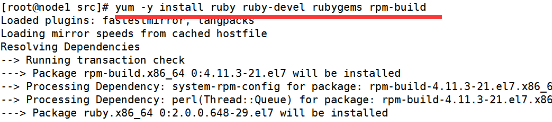
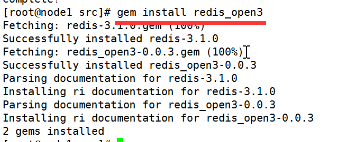
现在对redis的主键进行升级:
现在要运行了哦:
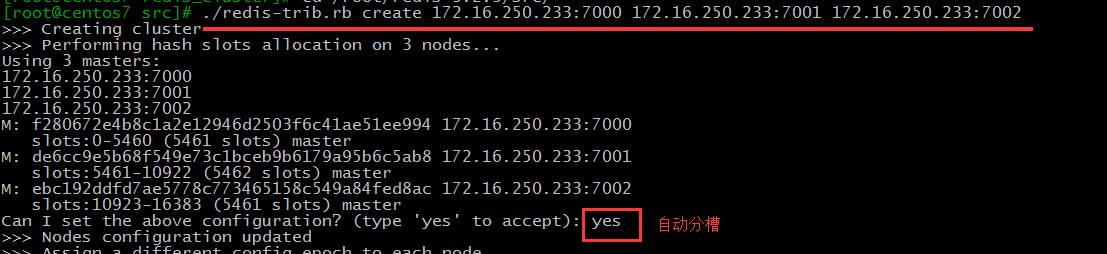
现在就可以集群就已经创建完成了,通过查看端口号可知;

也可以查看日志,验证一下:


















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









