







让我们先看一个问题:
给定一个字符串 S,以及一个模式串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模式串 P 在字符串 S 中多次作为子串出现。
求出模式串 P 在字符串 S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1≤N≤10 5
1≤M≤10 6
输入样例:
3
aba
5
ababa
输出样例:
0 2
这就是著名的KMP问题
朴素的做法
我们先考虑最朴素的做法:

我们将P与S一一对应的去判断,若当前的p[i]≠s[j],那么就将p往后面挪一位,继续与S一一对应的去判断。这个算法很好想,也很超时,别用这个。
经典KMP算法
我们观察到朴素做法中当p[i]≠s[j]时我们只挪了P往后1位,那没有么有方法让P多往后移动几位?
第一步
这一步称之为匹配
首先定义next[i]=j意思是P数组中下标1~j的元素与下标(i-j+1)~i的元素相同,即从1开始长度为j的前缀=从i开始长度为j的后缀
别慌,举个例子你就懂了
P=abcabd(下标从1开始)
next[5]=2 意思是P数组中下标1~2的元素(ab)与下标4(即5-2+1)~5的元素(ab)相等
也就是说,当p[i]≠s[j+1]时(这里j+1你到时候看代码就懂了,只是为了写代码方便,注意红圈是j+1啊!!!,他前面的绿线才是j)
如果橙色这一段=黑色这一段(见下图的①,P段),那么我们就不将P平移1个单位,我们直接将①段平移到②段,即点a平移到了a`,b平移到了b`,大家可以想一想(结合我画的两条黑线),就可以得出②此时在长的绿色线之前的那一段是与蓝色线(S)的元素是相等的。大家可以自己画图来理解。
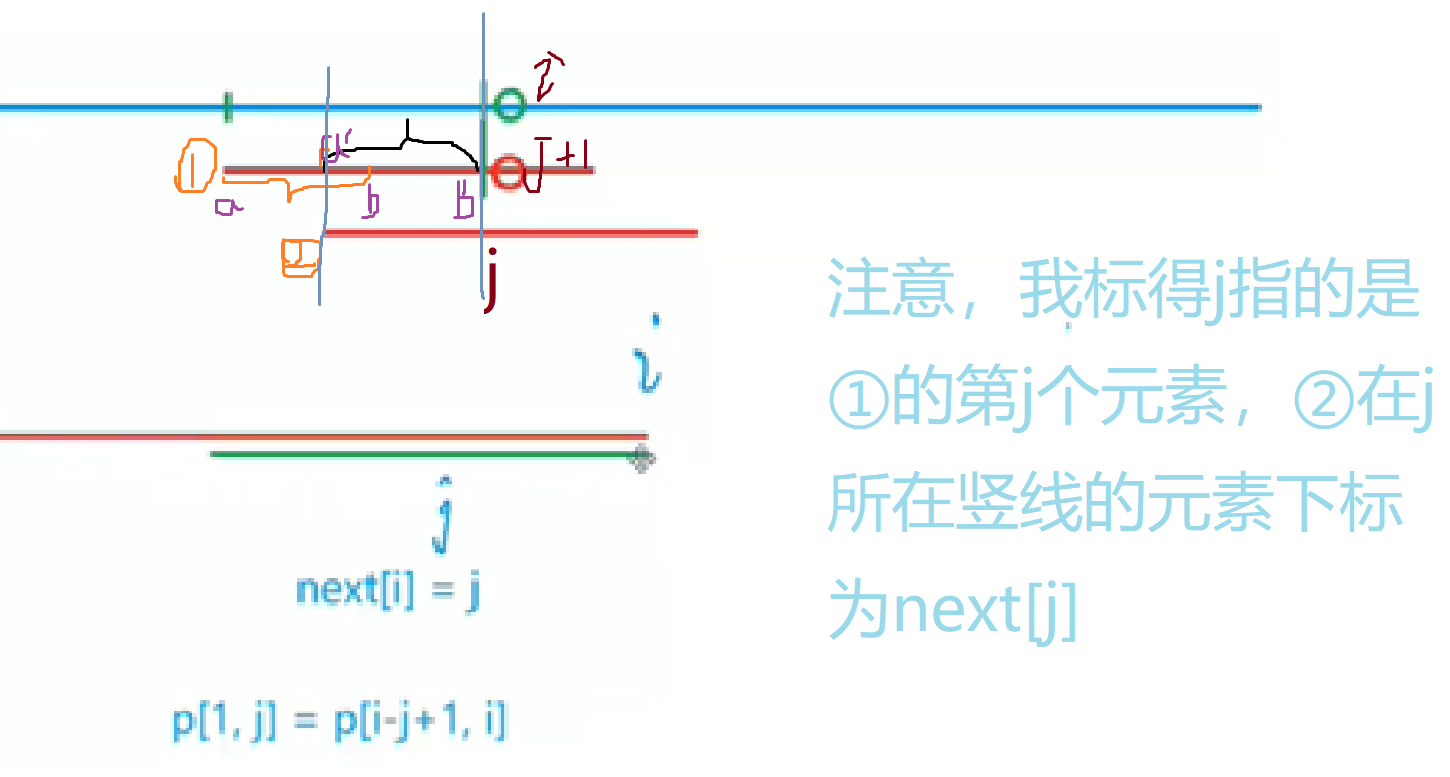
结合上述对next数组的定义,我们可以得到每次当出现①的情况时,我们将b平移到b`,相当于进行一个操作:j=next[j]。这块大家可以画画图理解一下,自己可以举几个实例,勤于动笔才能懂!
第二步
那么该怎么求next数组呢???
我们可以换一个角度分析
假设字符串S=P,那么我们先进行第一步操作,然后让next[i]=j就行了,这一段没有什么解释的必要,主要是跟第一步没多少区别,只是多了一步next[i]=j,不懂的话大家看看代码演算一下
代码
#include<iostream>
using namespace std;
const int N=1e5+5,M=1e6+5;
int n,m;
char p[N],s[M];
int ne[N];//next
int main(){
cin>>n>>p+1>>m>>s+1;
//求出next数组
for (int i=2,j=0;i<=n;i++){
while (j && p[i]!=p[j+1]){//如果不相等,就退
j=ne[j];
}
if (p[i]==p[j+1]){//如果这两个字符相等了,j跳下一个
j++;
}
ne[i]=j;
}
//搭配
for (int i=1,j=0;i<=m;i++){
while (j && s[i]!=p[j+1]){
j=ne[j];
}
if (s[i]==p[j+1]){
j++;
}
if (j==n){
cout<<i-n<<' ';
j=ne[j];
}
}
return 0;
}













 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









