







电商数仓实战
环境搭建快速回忆
这次详细写!------阿里云ECS云服务器抢占式
1.进入环境先创建wts用户
1.useradd wts
2.passwd wts
去/home/下查看有没有wts
接下来很多内容都要在wts下实现,这很重要
2 . 现在root用户下面,给wts赋予超级权力:sudo
1.[root@hadoop100 ~]# vim /etc/sudoers
2.找到下列的部分,添加(wts ALL=(ALL) NOPASSWD:ALL)
##Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
wts ALL=(ALL) NOPASSWD:ALL
3.退出的时候改用!wq的自己看
3 .接下来修改映射
1.windows下hosts,用公网ip
2.云服务器环境:用私有ip(别你妈搞错了,这个时候如果在wts下,要用sudo 的)
4 .三台机子免密登录: 三台同时跑
1. ssh-keygen -t rsa
2. 遇到输入密码就输入密码
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
3.自己ssh验证一下
5 .多个脚本,在wts下的bin下写
111.先xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop112 hadoop113 hadoop114
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
222–jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
333–hadoop.sh 群起脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop112 "/opt/module/hadoop313/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop113 "/opt/module/hadoop313/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop112 "/opt/module/hadoop313/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop112 "/opt/module/hadoop313/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop113 "/opt/module/hadoop313/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop112 "/opt/module/hadoop313/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
jdk配置
1. 概念
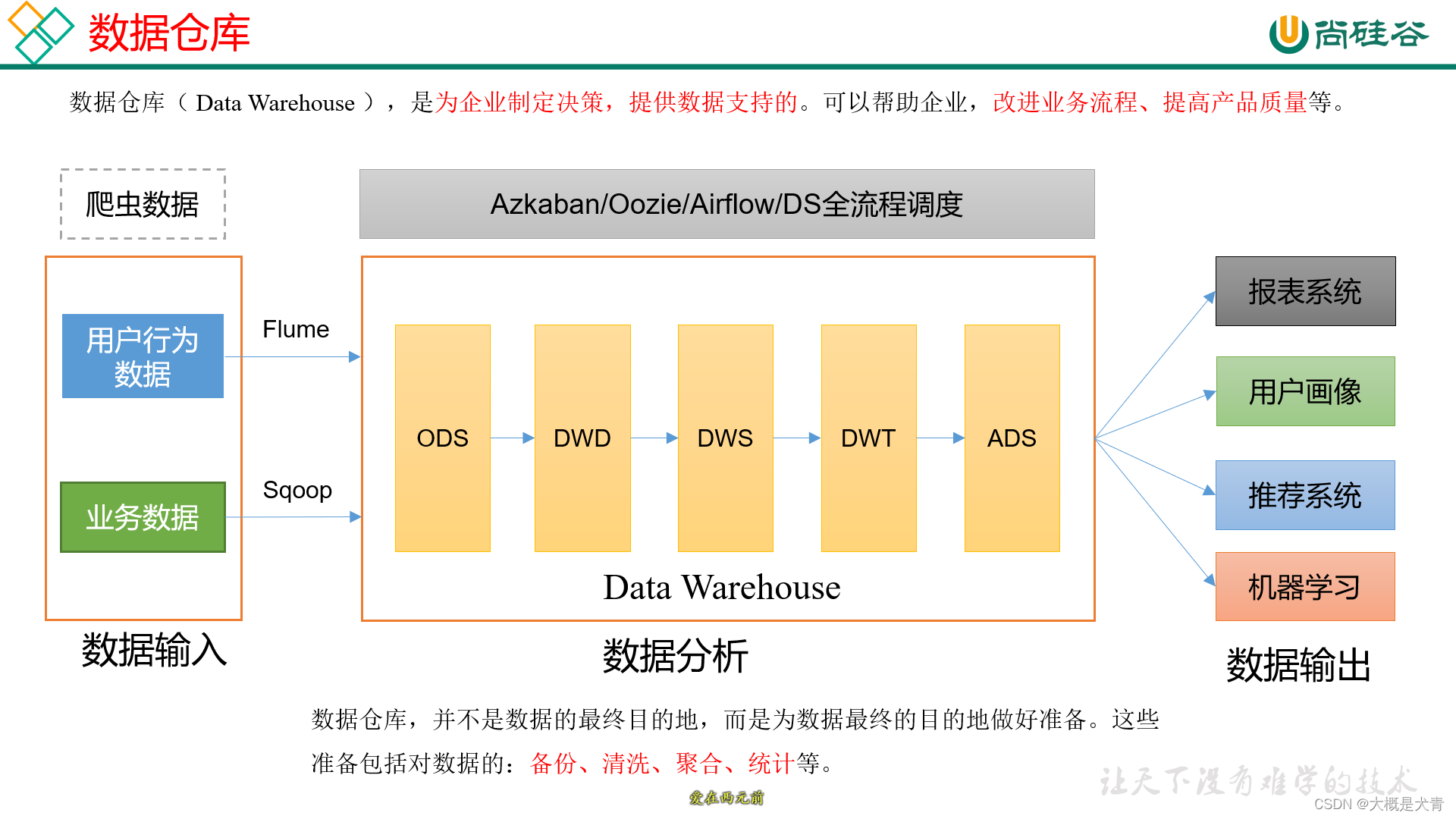
技术选型:

数据流程设计
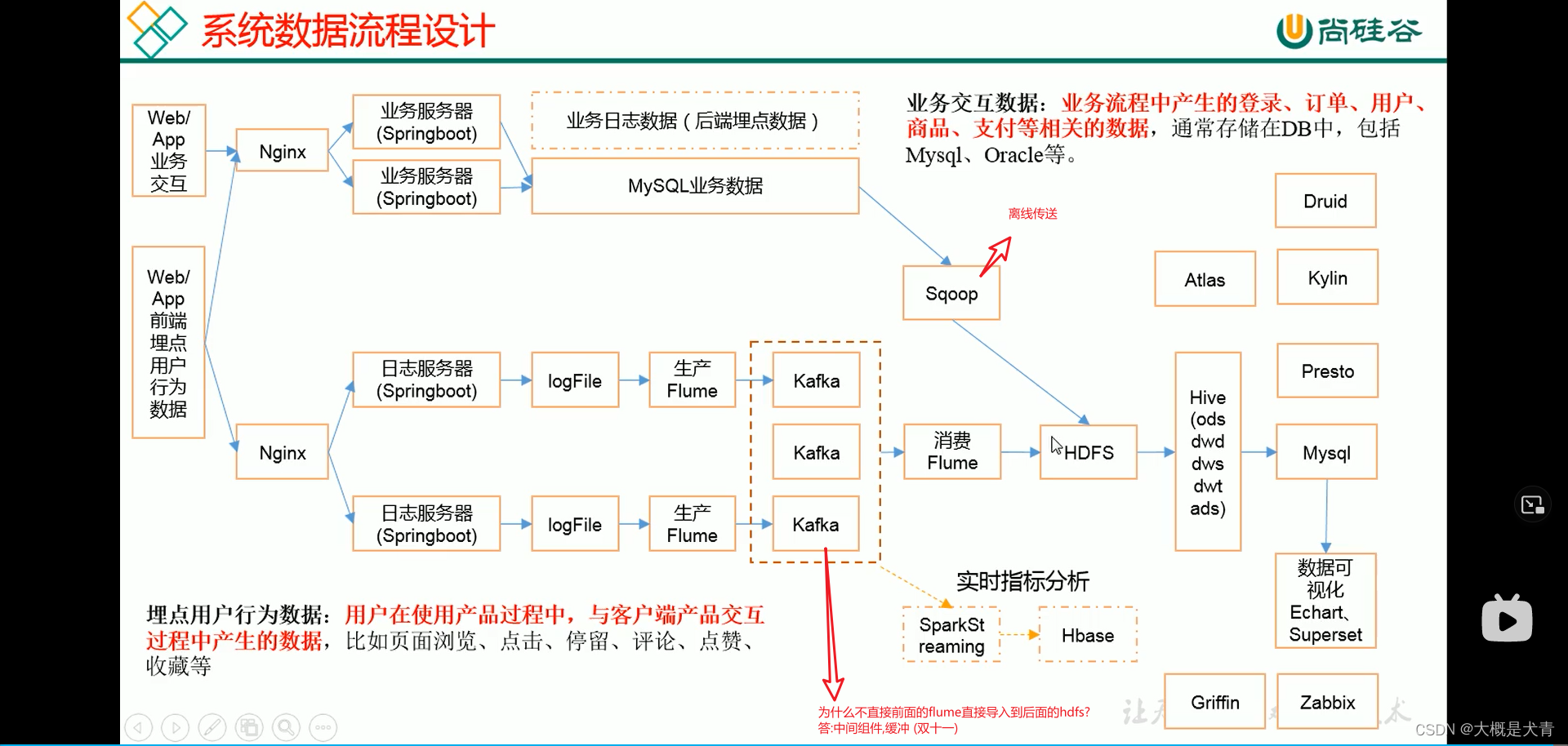
搭建环境
阿里ECS云服务器搭建学习: 密码Wts111111
三台ECS创建wts用户:
useradd wts
passwd wts
输入两边密码
cd /home 有无wts?
让wts有sudoer权力:
[root@hadoop100 ~]# vim /etc/sudoers
修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示:
wts ALL=(ALL) NOPASSWD:ALL
配置windows下hosts映射:不多说了
配置三个ecs之间的映射:不多说了
阿里云ECS云服务器–选择的是抢占式 很便宜
P23课(电脑不够,云服务器来凑;开虚拟机的话后期16G内存根本不够)
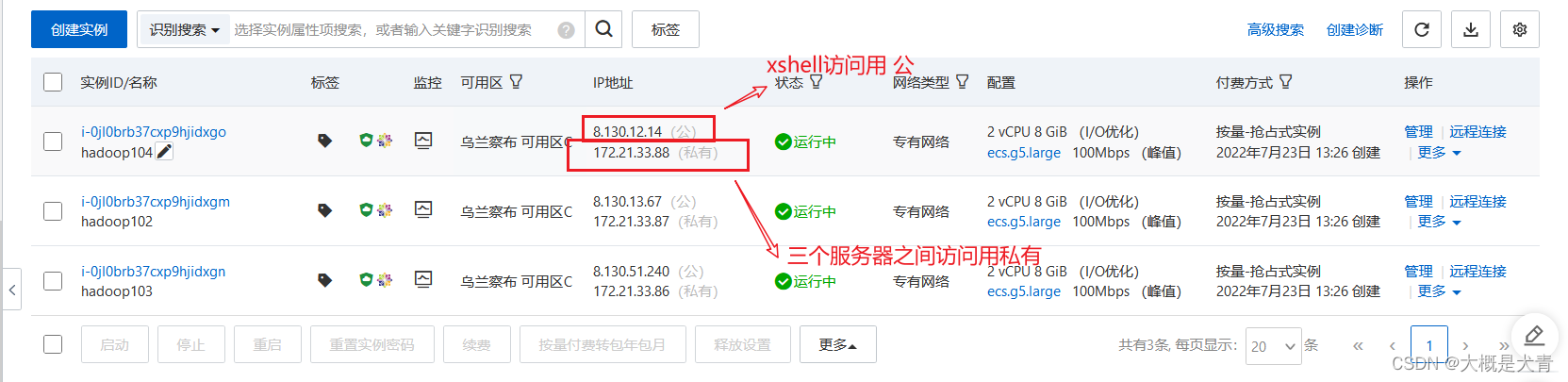
前面根据之前学的mapreduce配置,其中配置三台云服务器之间的免密码登录的时候遇到了点小问题:
1.首先要在三台云服务器里面设置映射:vim /etc/hosts
把相关的私有IP(上图)写进去
2.然后才可以配置之间的免密码登录
解压jdk
创建目录/opt/software jdk传输到这里
创建目录/opt/module jdk解压到这里
[wts@hadoop102 module]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module
生成日志
把材料中的四个文件拖进/opt/module/applog下面
运行:java -jar gmall2020-mock-log-2021-01-22.jar
写集群日志生成脚本lg.sh,脚本统一写在~/bin目录下
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &"
done
把lg.sh脚本和applog文件夹分发到hadoop102 103上面,
(删除hadoop104的applog,要求部署在102和103上面;同时删除刚刚在102运行产生的log日志)
效果:启动脚本,102和103上产生log日志…
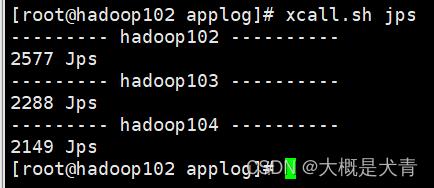
集群所有进程查看脚本
同理在~/bin下创建脚本:vim xcall.sh
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "$*"
done
分发到三个集群,效果:
用户行为数据采集
安装和解压hadoop,配置hadoop
五个地方要配置(core,hdfs,yarn,mapreduce,workers)
另外还要配置历史服务器和日志聚集
下面:
配置全部完成,第一次格式化,第二次启动hadoop
报错了,如下:
 参考大哥:ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. 其中的方式二解决
参考大哥:ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. 其中的方式二解决
最终的效果:红色的区域和老师启动不太一样,但是jps是一样的。(这个方法没有解决yarn的报错,不知道为什么,留着。。。)
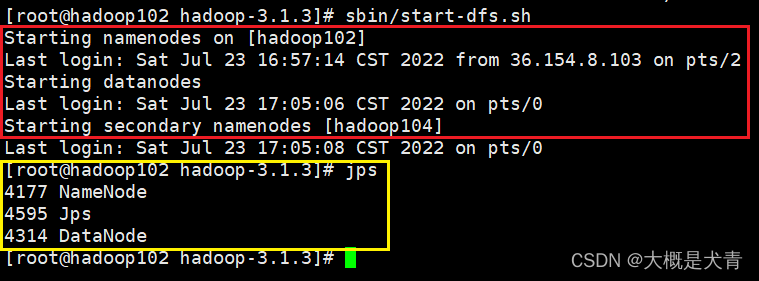
在hadoop103上启动yarn:
报错:

参考:启动start-yarn.sh报错ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no
解决方法:
到 sbin 目录下 更改 start-yarn.sh 和 stop-yarn.sh 信息,在两个配置文件的第一行添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
有报错:jps运行正常,ping三台ECS云服务器的公IP也是同的,但是hadoop102:9870页面打不开
解决办法汇总:
1.Windows下ping一下hadoop102是否通?有问题大概率是windows下的hosts映射
2.虚拟环境,防火墙关了
3.检查hdfs-site.xml 配置web页面的那一块是否写对了
4如果你也是和我一样的阿里云服务ECS,你的安全组端口,要自己配一下9870的端口.(我就是这个问题)
zookeeper
解压改名安装配置
1. 创建zkData 给三台机器各自的myid
2. 配置conf,zoo.cfg
修改数据存储路径到zkData里面
配置设置server.A=B:C:D
群起zookeeper:
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
777 该权限,后就可以使用















 3558
3558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









