







如题,近日开始做新的软件构造实验,从老师处下载的代码框架在导入后出现了文件编码格式问题,所有的中文都变成乱码且IDEA会提示"The file was loaded in a wrong encoding:'UTF-8". 且会提示可以Reload in another encoding,但其他的编码格式也都有warning或error,更改编码后只会使得原本的乱码变成问号。
更严重的问题是,之后尝试运行代码时IDE会在build阶段大量报错Java:非法字符'\uxxxx',也不会提示具体出错位置。首先尝试更改右下角的UTF-8但无果,后来通过preference-editor-fileencoding中查看所有的文件编码发现出错的原因恰恰是因为刚才选择了Reload in another encoding使得正常的UTF-8字符成了非法字符。将所有文件的编码方式改回UTF-8即可正常build。

但中文乱码的问题还没有解决,一个简单粗暴的方式是,不要从github上下载文件然后导入项目,直接从github的浏览页面上复制粘贴,中文可以正常显示。
进一步查找资料,发现了一组汉字乱码的种类和产生原因的汇总,如下:
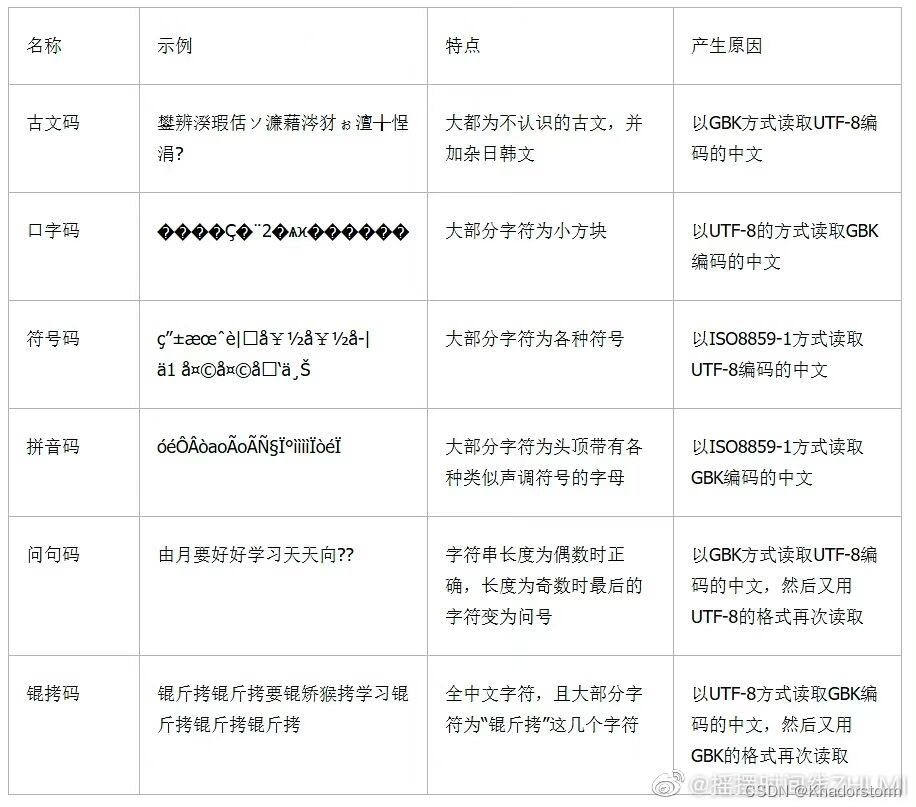
我的情况属于口字码,说明以UTF-8方式读取GBK编码中文。windows以GBK方式编码中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









