






一、摘要
强调image matting(抠图)的现实意义。已有的算法在前景和背景颜色相似或者拥有复杂的纹理时表现较差,主要原因有两个,一个是只运用到低维特征,另一个是缺少高维语境。所以这篇论文提出了深度模型算法可以解决上述两个问题。模型主要包括两个部分。第一部分是一个深度卷积编码-解码网络。这部分的输入包括图片和图片对应的二分图(trimap),输出是 预测的图片对应的alpha matte。第二部分是一个小的卷积神经网络,用于微调第一部分获取的预测alpha图,并获得更锐利的边缘。另外,这篇论文的贡献在于创造了一个拥有49300张训练图片和1000张测试图片的数据集。
二、论文方法
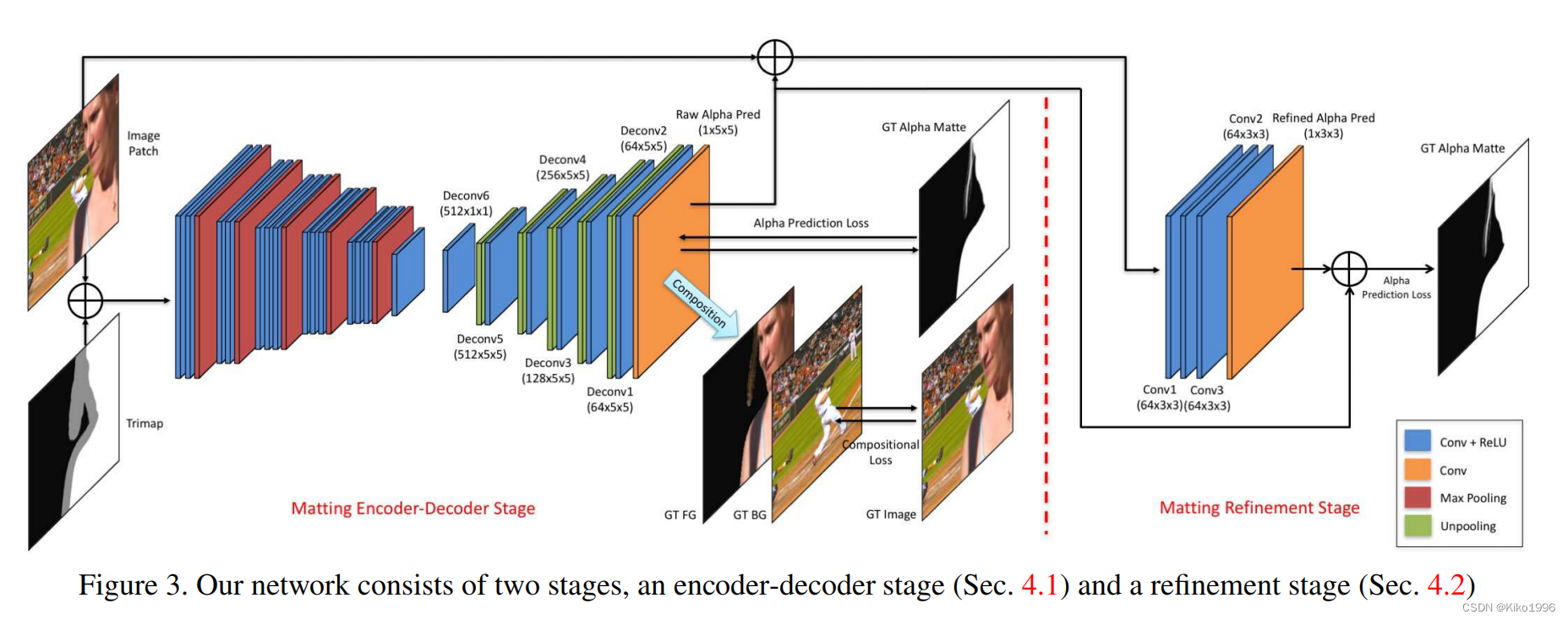
论文提出的网络由两个stage构成。第一步是一个深度卷积的encoder-decoder,其输入是原始图片和对应的trimap。并且这一阶段的损失计算包括alpha估计的误差和组合误差。第二步是一个完全卷积网络,用于调整第一步获得的alpha估计,获得更加精确的alpha值和更确切的边缘。具体描述如下:
1、 Matting encoder-decoder stage
网络结构:原始图像和trimap concate为4通道的输入,encoder包括14层的卷积层和5层的最大池化层。而decoder采用了更小的结构减少参数,包括6个卷积层和5个unpooling层(unpooling层即为最大池化层的逆过程,主要是补零的操作)
损失函数:包括alpha预测误差和组合误差。alpha误差比较直接,是预测值和准确值差的平方再开根号,但是担心其不可微性,还加了个扰动项。而组合误差则是RGB各通道的差值。
alpha的估计损失:
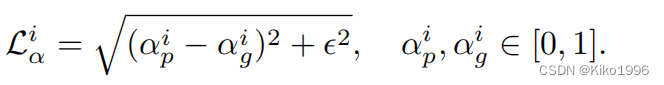
其对应的倒数为:
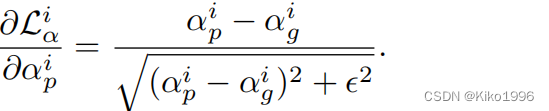
compositional组合损失:

总的loss为前面两项的组合项:
![]()
论文中参数取0.5,使得两部分loss等比例进行加权。但是也提到了在trimap的未知区域,设置为1,使得网络更专注于重要区域。
2、Matting refinement stage
虽然上一步获得的alpha估计已经明显好于其他现存的matting算法,主要是得益于encoder-decoder的结构。但是为了获得更精细化的结果,这一步主要是调整alpha估计并获得更清晰的边缘。
网络结构:输入为第一阶段的alpha估计和原图,concat在一起获得一个四通道的输入。输出是对应的alpha matte。这一阶段的网络是完全的卷积结构,包括4个卷积层,前三个卷积层每个之后都跟随了一个非线性的relu层。在网络中还加了一个skip的操作,将输入数据的第四通道先缩放到0-1,然后加入到网络的输出部分。
在实现过程中,论文先更新encoder-decoder部分直到收敛,然后再更新第二阶段的网络,损失约束只有alpha估计。直到第二阶段网络也收敛了,论文会将两个阶段放在一起微调,使用的是adam算法,学习率为10的-5次方。















 2369
2369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









