






一、Groupby机制
可用作分组的键
- 列表或数组,其长度与待分组的轴一样;
- 表示DataFrame某个列名的值;
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系;
- 函数,用于处理轴索引或索引中的各个标签;
import numpy as np
import pandas as pd
PREVIOUS_MAX_ROWS = pd.options.display.max_rows
pd.options.display.max_rows = 20
np.random.seed(12345)
import matplotlib.pyplot as plt
plt.rc('figure', figsize=(10, 6))
np.set_printoptions(precision=4, suppress=True)
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.random.randn(5),
'data2' : np.random.randn(5)})
df

用Series、Series组成的list作为分组键
# 用Series作为分组键
grouped = df['data1'].groupby(df['key1'])
grouped
'''<pandas.core.groupby.generic.SeriesGroupBy object at 0x000002103BAA4910>'''
# grouped变量成为GroupBy对象
grouped.mean() # 得到series,索引名为groupby 的分组键
'''
key1
a 0.746672
b -0.537585
Name: data1, dtype: float64
'''
# 数据(一个Series)根据分组键进行了聚合,并产生新的Series,其索引名称为key1
# 用Series组成的list作为分组键,得到层次化索引的series,索引名为groupby 的分组键
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means
'''
key1 key2
a one 0.880536
two 0.478943
b one -0.519439
two -0.555730
Name: data1, dtype: float64
'''
用数组组成的list作为分组键
# 用数组组成的list作为分组键
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states, years]).mean()
'''
California 2005 0.478943
2006 -0.519439
Ohio 2005 -0.380219
2006 1.965781
Name: data1, dtype: float64
'''
传递列名、列名组成的list作为分组键
# 传递列名作为分组键,默认情况下所有的数值列都可以聚合
df.groupby('key1').mean()
'''
data1 data2
key1
a 0.746672 0.910916
b -0.537585 0.525384
'''
# 传递列名组成的list作为分组键
df.groupby(['key1', 'key2']).mean()
# 传递列名组成的list作为分组键
df.groupby(['key1', 'key2']).size() # size()方法统计每组中数据的数目
'''
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
'''
【注意】分组键中的任何缺失值,都被排除在结果之外
遍历各分组
GroupBy对象支持迭代,会产生一个由分组名和数据块组成的二维元组序列。
for name, group in df.groupby('key1'):
print(name)
print(group)
'''
a
key1 key2 data1 data2
0 a one -0.204708 1.393406
1 a two 0.478943 0.092908
4 a one 1.965781 1.246435
b
key1 key2 data1 data2
2 b one -0.519439 0.281746
3 b two -0.555730 0.769023
'''
# 通过将元组转换为list,再转换为dict,选择任意一块数据
pieces = dict(list(df.groupby('key1')))
pieces['b']

# 具有多个分组键时,元组中的第一个元素是键值组成的元组
for (k1, k2), group in df.groupby(['key1', 'key2']):
print((k1, k2))
print(group)
'''
('a', 'one')
key1 key2 data1 data2
0 a one -0.204708 1.393406
4 a one 1.965781 1.246435
('a', 'two')
key1 key2 data1 data2
1 a two 0.478943 0.092908
('b', 'one')
key1 key2 data1 data2
2 b one -0.519439 0.281746
('b', 'two')
key1 key2 data1 data2
3 b two -0.55573 0.769023
'''
# groupby默认沿着axis=0上进行分组,也可沿着axis=1的轴进行分组
grouped = df.groupby(df.dtypes, axis=1)
for dtype, group in grouped:
print(dtype)
print(group)
'''
float64
data1 data2
0 -0.204708 1.393406
1 0.478943 0.092908
2 -0.519439 0.281746
3 -0.555730 0.769023
4 1.965781 1.246435
object
key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one
'''
选择一列/所有列的子集:用列名/列名组成的数组对GroupBy对象进行索引
| 用列名/列名组成的数组对GroupBy对象进行索引 | Series.groupby()或DataFrame.groupby() | 两者等价 |
|---|---|---|
df.groupby('key1')['data1'] | df['data1'].groupby(df['key1']) | 返回分组的Series |
df.groupby('key1')[['data2']] | df[['data2']].groupby(df['key1']) | 返回分组的DataFrame |
【注意】聚合后返回的都是一维表,可用unstack()把行索引转为列索引,即二维表
# 用列名对GroupBy对象进行索引,返回分组的Series
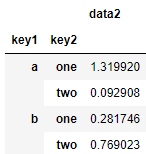
s_grouped = df.groupby(['key1', 'key2'])['data2']
# 聚合后返回一维表
s_grouped.mean()
'''
key1 key2
a one 1.319920
two 0.092908
b one 0.281746
two 0.769023
Name: data2, dtype: float64
'''
# 用列名组成的数组对GroupBy对象进行索引,返回分组的DataFrame
df_grouped = df.groupby(['key1', 'key2'])[['data2']]
# 聚合后返回一维表
df_grouped.mean()
用字典/Series作为分组键
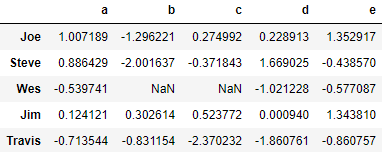
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.iloc[2:3, [1, 2]] = np.nan # Add a few NA values
people
mapping = {'a': 'red', 'b': 'red', 'c': 'blue',
'd': 'blue', 'e': 'red', 'f' : 'orange'}
# 用字典作为分组键,字典中允许包含未用的分组键(如‘f’)
by_column = people.groupby(mapping, axis=1)
by_column.sum()

map_series = pd.Series(mapping)
map_series
'''
a red
b red
c blue
d blue
e red
f orange
dtype: object
'''
# 用Series作为分组键,允许包含未用的分组键(如‘f’)
people.groupby(map_series, axis=1).count()
# 注意,分组键缺失值被排除在结果之外

用函数作为分组键
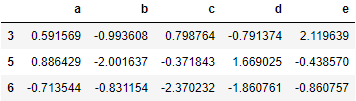
# len默认求行索引长度,并将返回值作为分组名称,如本例中的3、5、6
people.groupby(len).sum()
# 将函数与数组、字典或Series混合,作为分组键;所有的对象在内部都会被转换为数组
# 如下传递的分组键相当于:[[3, 'one'] [5, 'one'] [3, 'one'] [3, 'two'] [3, 'two']]
# 结果中会形成分层索引
key_list = ['one', 'one', 'one', 'two', 'two']
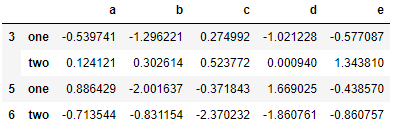
people_grouped = people.groupby([len, key_list]).min()
people_grouped
根据索引层级分组
# 传入level=0,索引层级编号
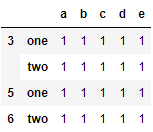
people_grouped.groupby(level=0, axis=1).count()
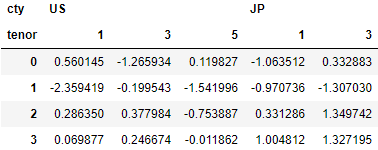
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],
[1, 3, 5, 1, 3]],
names=['cty', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df
# 传入level='cty',索引层级name
hier_df.groupby(level='cty', axis=1).count()
'''
cty JP US
0 2 3
1 2 3
2 2 3
3 2 3
'''
二、数据聚合
| GroupBy的方法 | |||
|---|---|---|---|
| count | 分组中的非NA值的数量 | std、var | 无偏的(分母为n-1)标准差和方差 |
| sum | 非NA值的累和 | min、max | 非NA值的最小值、最大值 |
| mean | 非NA值的均值 | prod | 非NA值的成绩 |
| median | 非NA值的算术中位数 | first、last | 非NA值的第一个和最后一个值 |
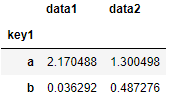
df

# quantile并非显示的为GroupBy对象实现的,但其是Series的方法
# 对GroupBy对象进行切片选择数据块piece,再调用quantile()方法
grouped = df.groupby('key1')
grouped['data1'].quantile(0.9)
'''
key1
a 1.668413
b -0.523068
Name: data1, dtype: float64
'''
# 要使用自定义的聚合函数,需将函数传递给agg()/aggregate方法
def peak_to_peak(arr):
return arr.max() - arr.min()
grouped.agg(peak_to_peak)

# GroupBy对象的describe()方法用于返回每组计数、均值、标准差、四分位数、中位数
grouped.describe()
面向列的多函数应用
tips = pd.read_csv('examples/tips.csv')
# 添加总账单的消费比例列
tips['tip_pct'] = tips['tip'] / tips['total_bill']
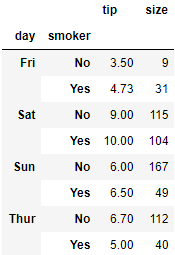
tips[:6]

grouped = tips.groupby(['day', 'smoker'])
# 将函数名以字符串的形式传递给agg()
grouped_pct = grouped['tip_pct']
grouped_pct.agg('mean')
'''
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
'''
# 将函数或函数名组成的列表传递给agg(),会获得column名是这些函数名的DataFrame
grouped_pct.agg(['mean', 'std', peak_to_peak])

# 传递(name, function)元组组成的列表,会获得column名是name的DataFrame
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])
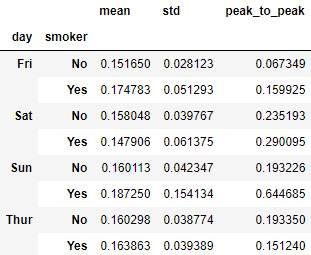
# 指定应用到所有列上函数列表
# 返回分层列索引的DataFrame
# 等价于分别聚合每一列,再以列名作为keys参数用concat拼接的结果相同
functions = ['count', 'mean', 'max']
result = grouped['tip_pct', 'total_bill'].agg(functions)
result
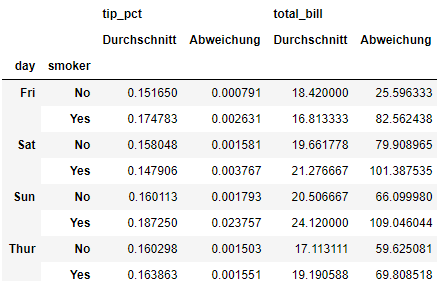
result['tip_pct']

# 传递(name, function)元组组成的列表
ftuples = [('Durchschnitt', 'mean'), ('Abweichung', np.var)]
grouped['tip_pct', 'total_bill'].agg(ftuples)
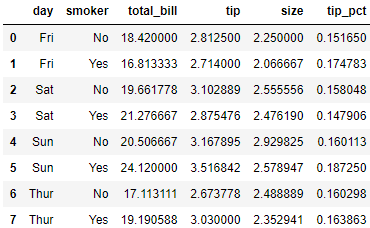
# 将不同的函数应用到不同的列上,传递一个字典实现
grouped.agg({'tip' : np.max, 'size' : 'sum'})
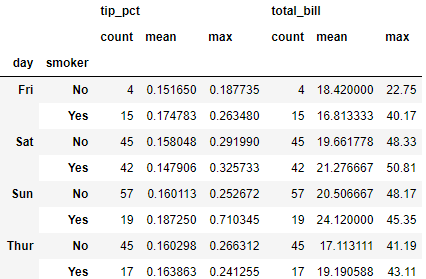
# 将多个不同的函数应用到不同的列上,传递一个字典实现
# 返回的数据具有层级列
grouped.agg({'tip_pct' : ['min', 'max', 'mean', 'std'],
'size' : 'sum'})
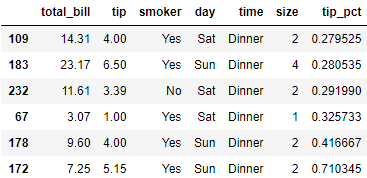
返回不含行索引的聚合数据
# groupby()传递参数as_index=False,禁用将分组键作为行索引
tips.groupby(['day', 'smoker'], as_index=False).mean()
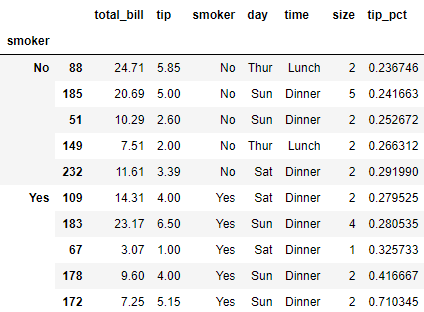
三、Apply: General split-apply-combine
# 定义函数按组选出小费百分比最高的5组
# 先写一个可在特定列中选出最大值所在行的函数
def top(df, n=5, column='tip_pct'):
return df.sort_values(by=column)[-n:]
top(tips, n=6)

list(tips.groupby('smoker')['tip_pct'])
'''
[('No',
0 0.059447
1 0.160542
2 0.166587
3 0.139780
4 0.146808
...
235 0.124131
238 0.130338
239 0.203927
242 0.098204
243 0.159744
Name: tip_pct, Length: 151, dtype: float64),
('Yes',
56 0.078927
58 0.156584
60 0.158206
61 0.144823
62 0.179673
...
234 0.193175
236 0.079365
237 0.035638
240 0.073584
241 0.088222
Name: tip_pct, Length: 93, dtype: float64)]
'''
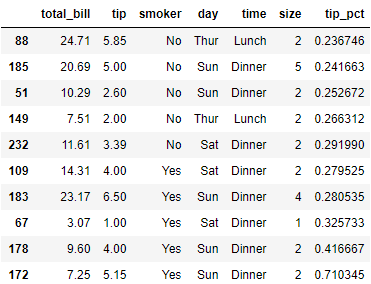
# 按smoker分组,再调用apply得到如下结果
tips.groupby('smoker').apply(top)
# top函数在DataFrame的每一行分组上被调用,
# 之后用pandas.concat将结果合并起来,并用分组名作为各组的标签
# 故结果中包含分层索引,内层索引时原DataFrame的索引值

# 若还想修改传递给函数的参数,可以在传递给apply函数后传递其他参数
# 这里是选出总花费total_bill最高的一笔
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')
result = tips.groupby('smoker')['tip_pct'].describe()
result

result.unstack('smoker')
'''
smoker
count No 151.000000
Yes 93.000000
mean No 0.159328
Yes 0.163196
std No 0.039910
Yes 0.085119
min No 0.056797
Yes 0.035638
25% No 0.136906
Yes 0.106771
50% No 0.155625
Yes 0.153846
75% No 0.185014
Yes 0.195059
max No 0.291990
Yes 0.710345
dtype: float64
'''
# GroupBy对象内部,当调用像describe这样的方法时,实际上是以下代码的简写
f = lambda x: x.describe()
tips.groupby('smoker')['tip_pct'].apply(f)
'''
smoker
No count 151.000000
mean 0.159328
std 0.039910
min 0.056797
25% 0.136906
50% 0.155625
75% 0.185014
max 0.291990
Yes count 93.000000
mean 0.163196
std 0.085119
min 0.035638
25% 0.106771
50% 0.153846
75% 0.195059
max 0.710345
Name: tip_pct, dtype: float64
'''
# 传递group_keys=False给groupby,去掉分组键所形成的的分层索引
# 只保留原DataFrame的原始索引
tips.groupby('smoker', group_keys=False).apply(top)

分位数与桶分析 Quantile and Bucket Analysis
frame = pd.DataFrame({'data1': np.random.randn(1000),
'data2': np.random.randn(1000)})
# 将data1那一列的数值等分成4组
quartiles = pd.cut(frame.data1, 4)
# 查看data1那一列qian10笔分别属于哪一组
quartiles[:10]
'''
0 (-0.387, 1.133]
1 (-0.387, 1.133]
2 (-0.387, 1.133]
3 (-1.908, -0.387]
4 (-1.908, -0.387]
5 (-0.387, 1.133]
6 (-0.387, 1.133]
7 (-3.434, -1.908]
8 (-0.387, 1.133]
9 (-0.387, 1.133]
Name: data1, dtype: category
Categories (4, interval[float64]): [(-3.434, -1.908] < (-1.908, -0.387] < (-0.387, 1.133] < (1.133, 2.654]]
'''
# 由cut返回的Categorical对象可直接传递给groupby
# 会发现data2被按区间分成了4组
grouped = frame.data2.groupby(quartiles)
list(grouped)
'''
[(Interval(-3.434, -1.908, closed='right'),
7 -1.105204
27 -0.383449
37 -1.578347
144 0.350913
202 -1.421750
...
772 -0.512455
826 0.113279
828 -1.460094
830 -0.590572
887 0.365401
Name: data2, Length: 24, dtype: float64),
(Interval(-1.908, -0.387, closed='right'),
3 2.337482
4 0.920129
13 -0.017749
17 -1.620790
18 -0.225226
...
983 1.140204
985 0.130148
995 -0.490551
997 0.232588
999 -0.703736
Name: data2, Length: 322, dtype: float64),
(Interval(-0.387, 1.133, closed='right'),
0 0.780375
1 -1.035697
2 0.835858
5 0.138707
6 0.554307
...
990 -0.174925
992 1.395191
994 0.620955
996 -1.416465
998 2.162370
Name: data2, Length: 517, dtype: float64),
(Interval(1.133, 2.654, closed='right'),
14 -1.595617
26 0.227895
51 -0.705894
62 0.920638
71 0.254233
...
964 0.772942
980 0.996054
987 -0.439194
991 -1.766967
993 -0.712856
Name: data2, Length: 137, dtype: float64)]
'''
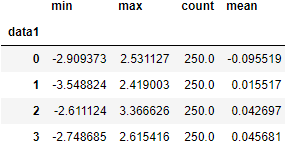
def get_stats(group):
return {'min': group.min(), 'max': group.max(),
'count': group.count(), 'mean': group.mean()}
grouped.apply(get_stats)
'''
data1
(-3.434, -1.908] min -2.079446
max 1.388465
count 24.000000
mean -0.121447
(-1.908, -0.387] min -2.909373
max 2.531127
count 322.000000
mean -0.055206
(-0.387, 1.133] min -3.548824
max 3.366626
count 517.000000
mean 0.033975
(1.133, 2.654] min -2.091554
max 2.615416
count 137.000000
mean 0.038102
Name: data2, dtype: float64
'''
grouped.apply(get_stats).unstack()
# 用qcut
# 传递labels=False,分组标签直接改为0-3的数值,而非区间
grouping = pd.qcut(frame.data1, 4, labels=False)
grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()

示例1:使用指定分组值填充缺失值
# 用均值填充缺失值
s = pd.Series(np.random.randn(6))
s[::2] = np.nan
s
'''
0 NaN
1 0.811639
2 NaN
3 -1.338431
4 NaN
5 1.328141
dtype: float64
'''
s.fillna(s.mean())
'''
0 0.267116
1 0.811639
2 0.267116
3 -1.338431
4 0.267116
5 1.328141
dtype: float64
'''
# 假设需要根据不同的分组来填充值
# 一个方法是先对数据分组,
# 再调用apply,并且在每一个数据块上调用fillna函数
states = ['Ohio', 'New York', 'Vermont', 'Florida',
'Oregon', 'Nevada', 'California', 'Idaho']
data = pd.Series(np.random.randn(8), index=states)
data
'''
Ohio 0.041276
New York -0.465827
Vermont -0.455179
Florida 1.000153
Oregon -0.721495
Nevada -0.221219
California 2.221307
Idaho -0.325338
dtype: float64
'''
# 设置缺失值
data[['Vermont', 'Nevada', 'Idaho']] = np.nan
data
'''
Ohio 0.041276
New York -0.465827
Vermont NaN
Florida 1.000153
Oregon -0.721495
Nevada NaN
California 2.221307
Idaho NaN
dtype: float64
'''
# 分组,并求每组均值
group_key = ['East'] * 4 + ['West'] * 4
data.groupby(group_key).mean()
'''
East 0.191867
West 0.749906
dtype: float64
'''
# 用每组均值填充缺失值
fill_mean = lambda g: g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
'''
Ohio 0.041276
New York -0.465827
Vermont 0.191867
Florida 1.000153
Oregon -0.721495
Nevada 0.749906
California 2.221307
Idaho 0.749906
dtype: float64
'''
# 为每个分组预设了填充值,可以构建分组与预设的填充值组成的字典
# 在使用每个分组内置的name属性
fill_values = {'East': 0.5, 'West': -1}
group_key = ['East'] * 4 + ['West'] * 4
fill_func = lambda g: g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)
'''
Ohio 0.041276
New York -0.465827
Vermont 0.500000
Florida 1.000153
Oregon -0.721495
Nevada -1.000000
California 2.221307
Idaho -1.000000
dtype: float64
'''
示例2:随机采样和排列
# 创建一副扑克牌
# Hearts红桃, Spades黑桃, Clubs梅花, Diamonds方块
suits = ['H', 'S', 'C', 'D']
card_val = (list(range(1, 11)) + [10] * 3) * 4
base_names = ['A'] + list(range(2, 11)) + ['J', 'K', 'Q']
cards = []
for suit in ['H', 'S', 'C', 'D']:
cards.extend((str(num) + suit) for num in base_names)
cards[:14]
'''
['AH',
'2H',
'3H',
'4H',
'5H',
'6H',
'7H',
'8H',
'9H',
'10H',
'JH',
'KH',
'QH',
'AS']
'''
# 创建一个长度为52的Series,索引为牌名cards
deck = pd.Series(card_val, index=cards)
deck[:13]
'''
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
dtype: int64
'''
# 从这副牌中随机取5张
def draw(deck, n=5):
return deck.sample(n)
draw(deck)
'''
KD 10
JC 10
2H 2
9C 9
3D 3
dtype: int64
'''
# 从每个花色中随机取2张
# 先按照花色分组,再基于分组使用apply
get_suit = lambda card: card[-1] # last letter is suit
deck.groupby(get_suit).apply(draw, n=2)
# 这里get_suit会自动对deck的索引进行切分,即对牌名切分
'''
C 9C 9
8C 8
D 6D 6
8D 8
H 8H 8
2H 2
S AS 1
QS 10
dtype: int64
'''
示例3:分组加权平均与相关性
# 对DataFrame的两列进行操作,计算加权平均
df = pd.DataFrame({'category': ['a', 'a', 'a', 'a',
'b', 'b', 'b', 'b'],
'data': np.random.randn(8),
'weights': np.random.rand(8)})
df
# 基于分组的,组内加权平均
# np.average()会先将组内的weights权重分配为加起来和为1,再计算
grouped = df.groupby('category')
get_wavg = lambda g: np.average(g['data'], weights=g['weights'])
grouped.apply(get_wavg)
'''
category
a 0.746913
b -0.171065
dtype: float64
'''
# 计算一个DataFrame,包含标普指数SPX每日收益的年度相关性(通过百分比变化/日报酬率计算)
# parse_dates=True将日期时间分开,只留下日期
# index_col=0将编号0的这一列,设置为行标签
close_px = pd.read_csv('examples/stock_px_2.csv', parse_dates=True,
index_col=0)
close_px.info()
'''
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2214 entries, 2003-01-02 to 2011-10-14
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AAPL 2214 non-null float64
1 MSFT 2214 non-null float64
2 XOM 2214 non-null float64
3 SPX 2214 non-null float64
dtypes: float64(4)
memory usage: 86.5 KB
'''
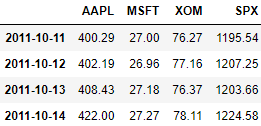
close_px[-4:]
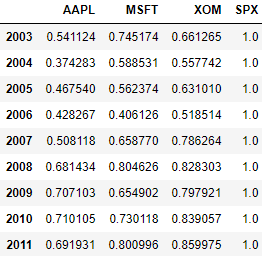
# 定义一个函数,求x的每一列与SPX列的相关系数,即DataFrame与Series间的相关系数
spx_corr = lambda x: x.corrwith(x['SPX'])
# 用pct_change()计算日报酬率
rets = close_px.pct_change().dropna()
rets.tail()
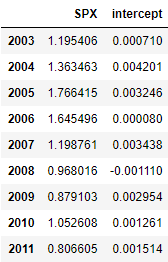
# 从每个行标签中提取每个datatime标签的year属性
get_year = lambda x: x.year
# 按年份对日报酬率进行分组
by_year = rets.groupby(get_year)
# 每一年,日报酬率与每列的相关系数
by_year.apply(spx_corr)
# 计算两个Series之间的相关系数
by_year.apply(lambda g: g['AAPL'].corr(g['MSFT']))
'''
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
dtype: float64
'''
示例4:逐组建性回归
import statsmodels.api as sm
def regress(data, yvar, xvars):
Y = data[yvar]
X = data[xvars]
X['intercept'] = 1.
result = sm.OLS(Y, X).fit()
return result.params
# sm.OLS().fit()执行最小二乘估计
by_year.apply(regress, 'AAPL', ['SPX'])

四、数据透视表与交叉表
| pivot_table()的参数 | |
|---|---|
| values | 需要聚合的列名,默认聚合所有数值型的列 |
| index | 在结果透视表的行上进行分组的列名或其他分组键 |
| columns | 在结果透视表的列上进行分组的列名或其他分组键 |
| aggfunc | 聚合函数或函数列表(默认为’mean’),可以是groupby上下文的任意有效函数 |
| fill_value | 在结果透视表中替换缺失值的值 |
| dropna | 若为True,将不含所有条目均为NA的列 |
| margins | 在结果透视表中添加行/列小计和总计(默认为False) |
# python中的pandas透视表时通过groupby和用分层索引的重塑操作来实现的
# DataFrame.pivot_table(),pandas.pivot_table()默认得到均值表
# 得到行方向上按day和smoker排列的分组平均值的透视表
# index指定透视表中的行索引,即分组
tips.pivot_table(index=['day', 'smoker'])

# 在指定列上聚合(平均),指定的列在结果中作为最外层列索引
# # index指定透视表中的行索引,即分组
# columns='smoker'设定指定列按照smoker分组,在结果中为内层列索引
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],
columns='smoker')
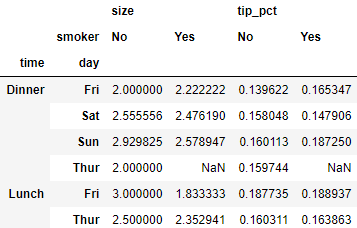
# 设置margins=True,会对原数组分组后求每一列及每一行的均值
# 注意不是在上一个表的基础上每一列/每一行加总后平均
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],
columns='smoker', margins=True)
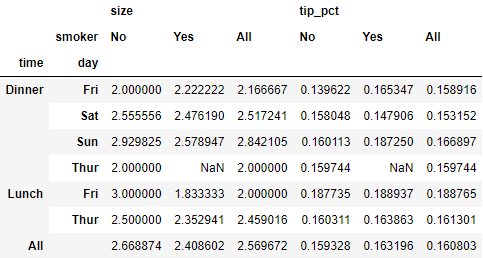
# pivot_table()默认求均值,要使用不同的函数,可将函数传递给参数aggfunc
# 'count'或len将给出一张分组大小的交叉表(计数/出现的频率)
tips.pivot_table('tip_pct', index=['time', 'smoker'], columns='day',
aggfunc=len, margins=True)
# aggfunc='count'得到与上面一样的结果,都默认将缺失值排除在结果中
tips.pivot_table('tip_pct', index=['time', 'smoker'], columns='day',
aggfunc='count', margins=True)

# 传递参数fill_value=0,设置结果中缺失值的填充值
# 与不传aggfunc='mean', 得到相同的结果
tips.pivot_table('tip_pct', index=['time', 'size', 'smoker'],
columns='day', aggfunc='mean', fill_value=0)

交叉表
# pd.crosstab():交叉表计算的是分组中的频率,是透视表的一种
from io import StringIO
data = """\
Sample Nationality Handedness
1 USA Right-handed
2 Japan Left-handed
3 USA Right-handed
4 Japan Right-handed
5 Japan Left-handed
6 Japan Right-handed
7 USA Right-handed
8 USA Left-handed
9 Japan Right-handed
10 USA Right-handed"""
data = pd.read_table(StringIO(data), sep='\s+')
data
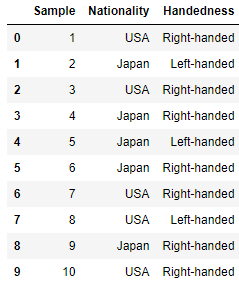
# 按Nationality和Handedness分组数据
pd.crosstab(data.Nationality, data.Handedness, margins=True)
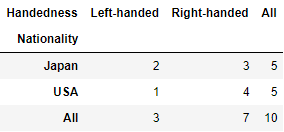
# pd.crosstab()前两个参数可以是数组、Series或数组的列表
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









