







“技术干货”是人大金仓推出的系列主题内容。本期展示的是人大金仓KFS V2.0通过精准过滤和基于表的分片并行入库特性来提升数据的入库效率,打破传统数据同步性能瓶颈,为用户提供极致高效的数据同步能力!
金仓数据同步软件KFS V2.0 强势发布,为用户提供极致高效的数据同步体验。“精准过滤”和“分片并行入库”两大黑科技,打破传统数据同步软件的性能瓶颈。让我们一起来看看它的能力吧!
1
客户现场的两大性能瓶颈
数据采集时延持续增大
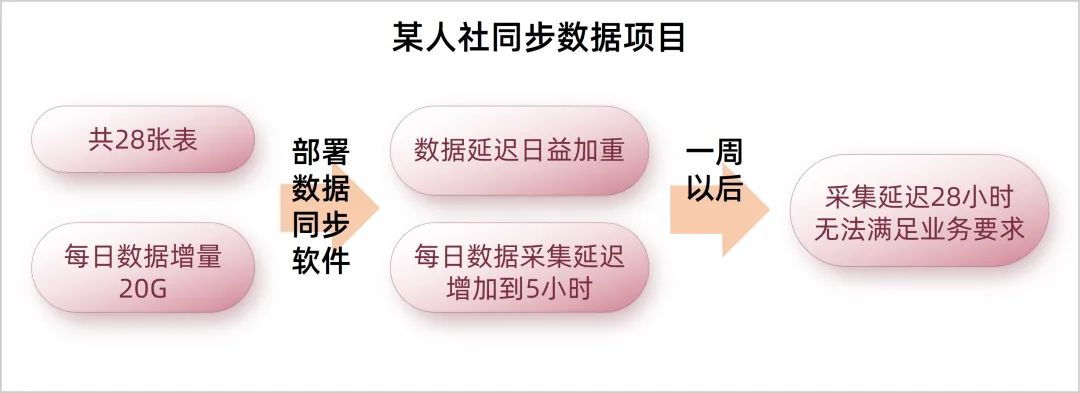
数据入库持续积压
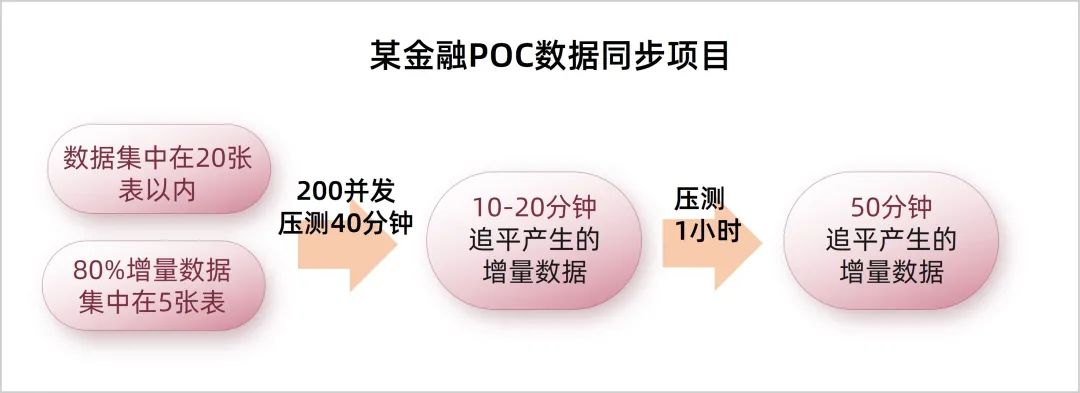
2
问题深度定位
大量不相干数据,浪费同步资源
经过深入分析,发现某人社项目的数据同步场景可以归属为在复杂的、融合了多个业务的数据库实例中,仅需要同步一个业务的数据。如图所示:
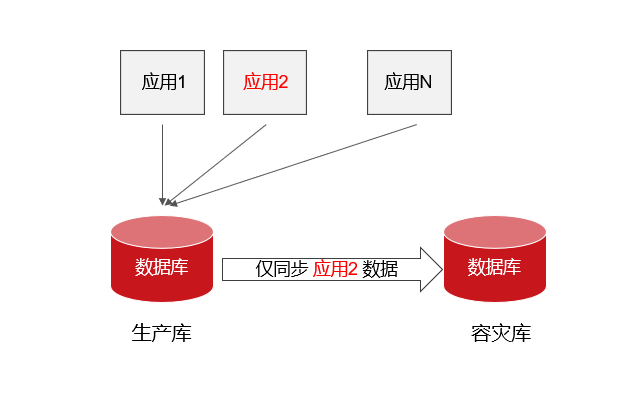
生产数据库上运行了很多业务,每天数据库产生的日志总量上TB,而需要容灾的应用2每天增量数据实际只有几十GB。如何从这上TB的日志中,仅分析需要的数据?例如,在本案例中,每天0-2点存在一些跑批+计算的场景,客户每日需要将计算时产生的中间数据写入临时表,但用于中间态计算的临时表是不需要同步的。
数据在翻译后才能过滤,延迟累计增加

数据同步软件通常会使用多线程、并行流水线的增量数据分析方式。原理大致如上图所示:源端由三个线程同时工作,相互配合完成增量数据的解析和翻译。我们可以使用手机生产流水线做类比。
线程1: 分析底层物理日志格式,解析最原始的数据信息 | 工人1: 原料入库,制作手机零件 |
线程2: 对原始数据进行排序、按照事务拆分;对于完成提交的事务,结合数据字典将事务中的原始数据翻译成可读的事务操作信息(DDL或者DML) | 工人2: 将零件组装为可使用的成品手机 |
线程3: 根据用户设定的过滤和转换规则对事务做进一步处理,仅保留需要同步的表 | 工人3: 根据质检规则,淘汰掉不合格的手机产品 |
其中:过滤和转换规则对下层的线程1和线程2隔离。仅线程3知道用户设定的同步规则,由其基于用户设定的业务规则做数据过滤。即只有工人3才知道产品质检的规则。
以上的增量数据解析流程中,所有的数据库物理日志数据都需要经过线程1和线程2的处理之后,才能由线程3进行过滤。即如果某个数据库每日的物理日志上TB,就算只需要同步其中的部分表,线程1和线程2也必须处理上TB的数据。会导致很多无效的数据分析过程,影响数据同步的整体效率。
大批量交叉事务,PBE特性导致反向优化
同步软件为了提升目标端数据入库的速度,使用了数据库的PBE特性,PBE的原理为:
(1)判定当前入库的操作类型和针对的表;
(2)使用数据库的PREPARE语句来预编译入库操作
(3)给PREPARE语句BIND(绑定)参数;
(4)如果下一条入库的操作和上一条的操作类型、操作表一致,则复用之前的PREPARE语句;
(5)如此往复,直到遇到一条操作类型或者操作表不一致的数据为止;
(6)EXECUTE(执行)之前的语句。并重新PREPARE新语句;
由以上的逻辑可知,如果同步的流程中出现了大量的、操作类型一致的、针对同一张表的操作,那么此PBE特性将极大的发挥其性能,提升入库速度。
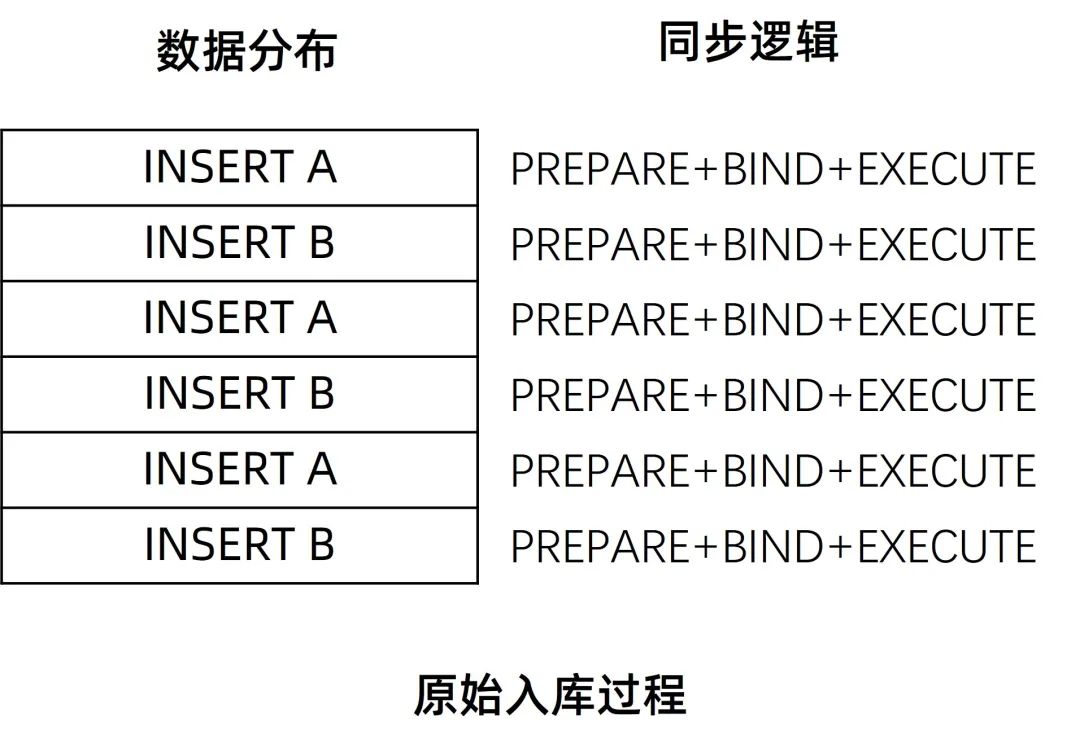
但在上述金融POC数据项目场景下恰好相反,在同步的流程中,主要是一些大批量的,针对不同表的交叉事务,和单个事务中包含了针对不同的表的操作。在此场景中,同步软件引入的数据库PBE特性对入库的性能产生了负优化。例如以下事务,会导致同步软件不断的进行PREPARE预编译,又发挥不出预编译特性的性能。
BEGIN
INSERT TABLE A
INSERT TABLE B
......
INSERT TABLE A
INSERT TABLE B
COMMIT
3
KFS 黑科技实战演练
终结行业痛点
针对以上问题,KFS V2.0 引入了“精准过滤”和“分片并行入库”特性,下面我们将通过实际测试来看看它提升数据同步效率的效果。
模拟测试场景的效果
1
测试模型
在数据库中建立32张表,使用Jmeter工具并行混合插入数据,预先积攒64GB的数据库归档文件。使用KFS对预先积攒的归档数据进行解析,分别测试以下场景中开启和关闭精准过滤特性、开启和关闭分片并行入库特性时的性能:
(1)解析全部32张表数据
(2)仅解析16张表数据
(3)仅解析8张表数据
(4)仅解析4张表数据
(5)仅解析2张表数据
(6)仅解析1张表数据
2
测试目标
验证在复杂业务场景下,KFS 使用“精准过滤”和“分片并行入库”后的性能变化。
3
测试环境
硬件:X86、8核 CPU、16GB 内存、1TB NVME硬盘
操作系统:CentOS 7.6
JDK:1.8
Oracle版本:11GB
4
测试结果
开启源端“精准过滤”后,性能变化曲线
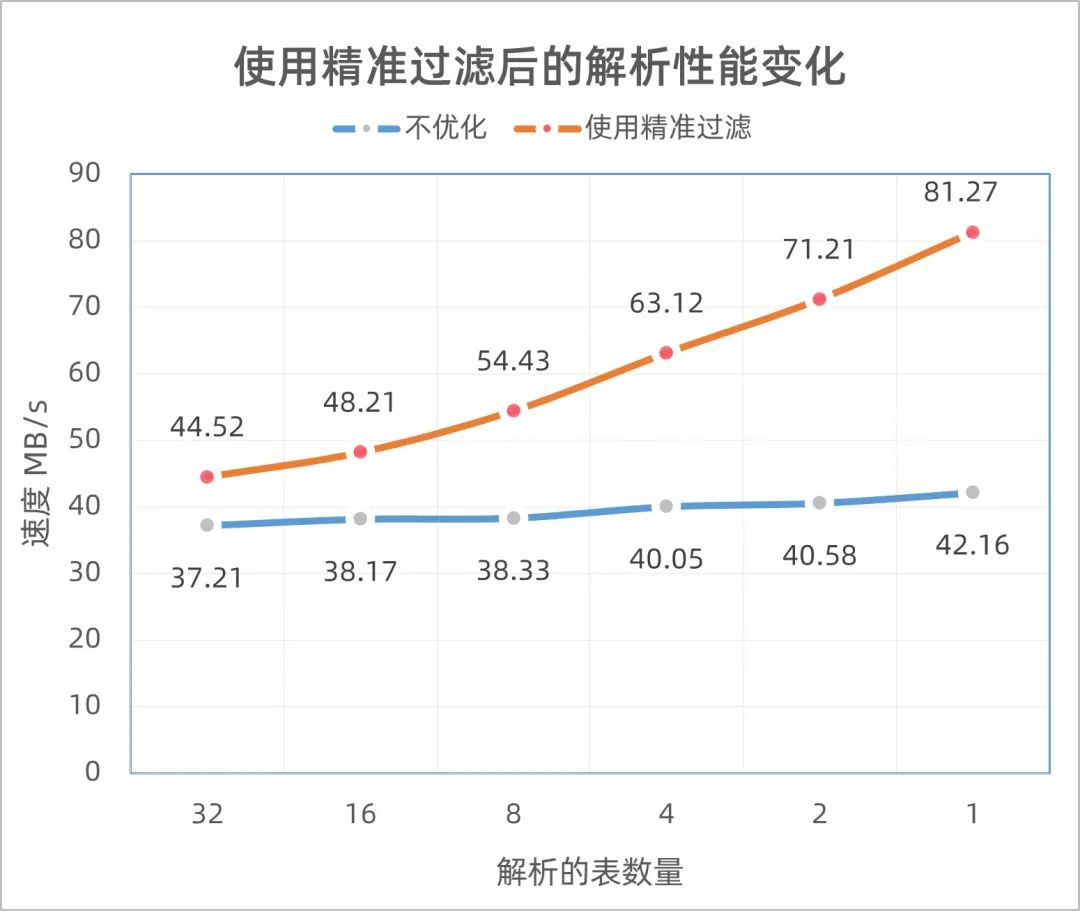
如图,同样的归档数量下。可以看到开启“精准过滤”后,解析的性能随着需要解析表数量的减少呈现比例式的增强。
使用同样的KUFL(中间文件),开启“分片并行入库”后,性能变化曲线
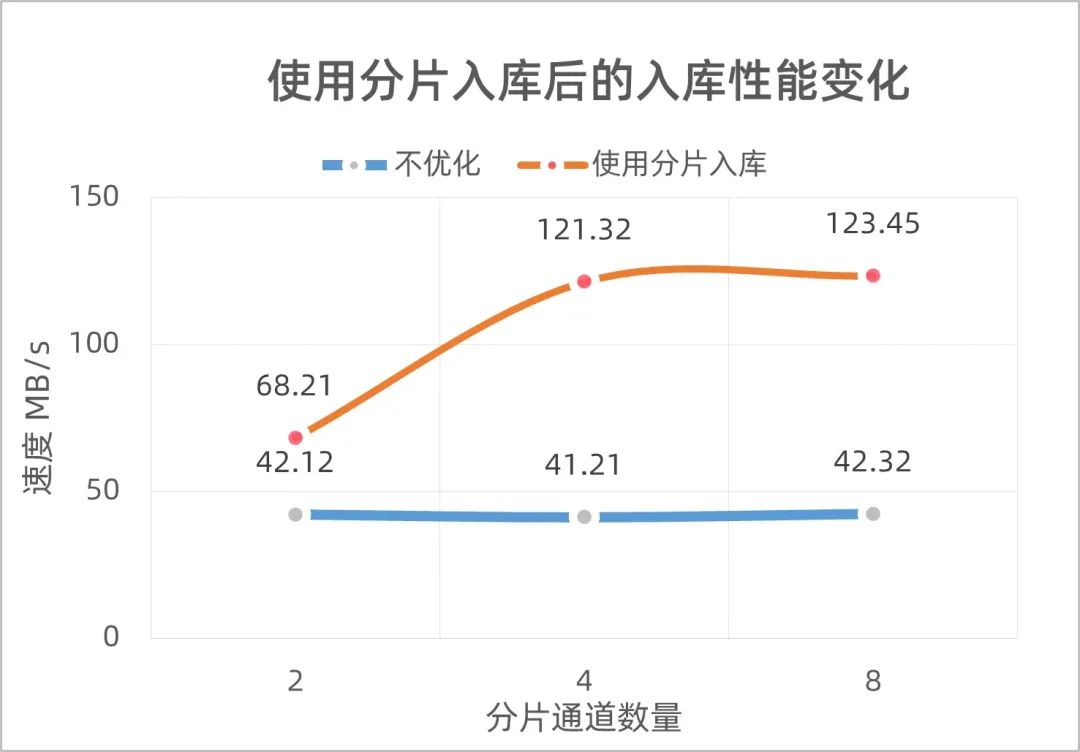
如图,使用解析所有表生成的KUFL(中间文件)入库,数据KUFL下。可以看到开启“分片并行入库”后,入库性能随着分片通道数呈现比例式的增强,但是最大到8个通道时,性能不再增加(数据库本身变为性能瓶颈)。
由于分片并行入库的性能最大在123.45MB/s。所以在同时开启“精准过滤”和“分片并行入库”的测试场景中,直接将分片的数量固定为4个,仅测试解析不同表数据时,从解析到入库全通道的入库性能。
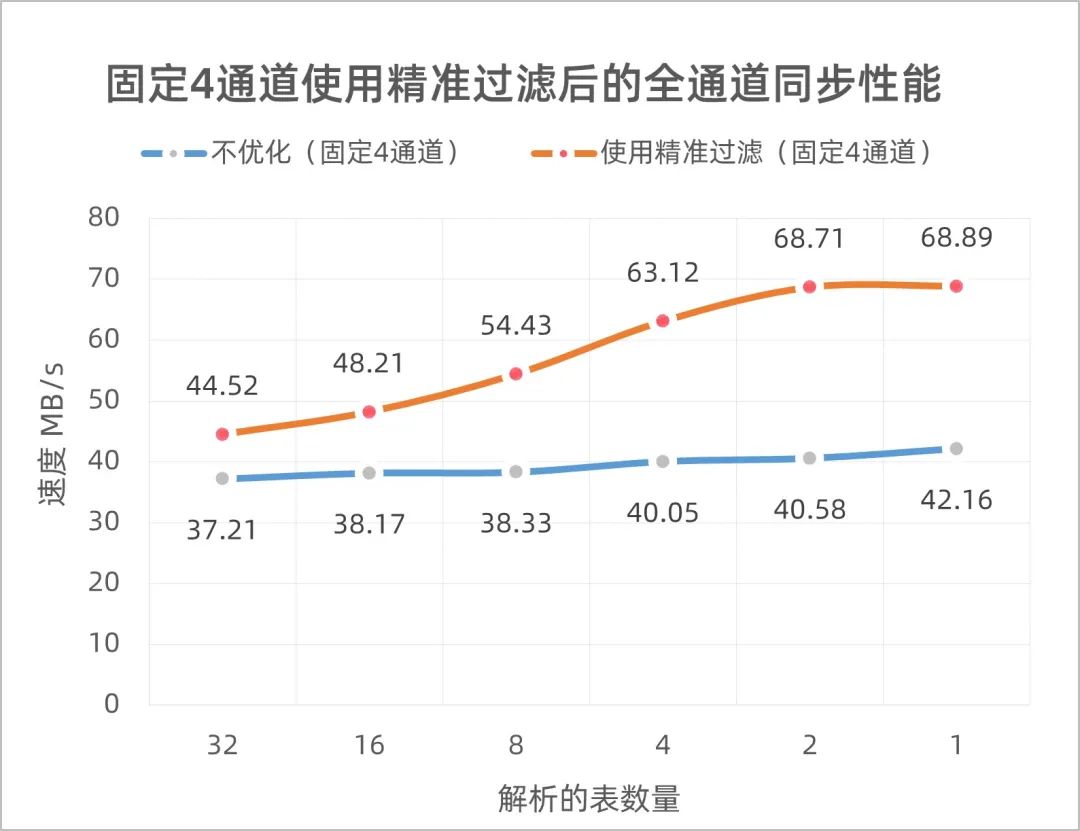
此时,最大性能固定在68.89MB/s,性能瓶颈主要集中在了网络传输上。也就是说源端的解析和目标端的入库,都不再是同步的性能瓶颈。
实际生产环境的效果
1
某人社数据同步项目
在引入了“精准过滤”和“分片并行入库”特性后,其整体平均同步性能从原来的15MB/s左右提升到了28MB/s左右。更重要的是,经过优化后,全天的最大延迟控制在了5分钟以内。

2
某金融POC项目
在引入了“精准过滤”和“分片并行入库”特性后,在200并发的压测场景中,整体同步性能指标从压测30分钟,延迟10-20分钟变为准实时同步,延迟2秒以内。

4
极致性能背后的黑科技
关键技术 ---“精准过滤”
“精准过滤”使用了性能优化中常见的“固定点原则”,指的是针对响应性,固定应当在尽早可能的时间点建立连接,从而保持该链接的成本有效性。
KFS 实现的精准过滤功能,其核心原理在于将同步规则的处理逻辑向下压,不要等到流水线数据处理到线程3时才能够进行过滤,最好能让线程1在读取二进制文件时直接将不相干的业务数据从精准过滤掉(尽早链接原则)。对比手机生产流水线,即在工人1生产零件时就要淘汰会导致手机产品不合格的零件,而不是总要等到最后工人3来进行产品质检。
从精准过滤数据的难点在于:用户设定的上层过滤规则是人类可读的格式,比如仅保留某个表的数据时,其配置规则为模式.表;保留某个模式中全部数据时,配置规则为模式.*。
但是数据库底层的、物理日志中存储的数据并不是表的名称,而是表对象在数据字典的内容ID标记。如何把表的名称和对象ID结合起来,并且还不影响正常的分析逻辑,成为了引入精准过滤能力时要解决的关键问题。
KFS在 V2.0 版本中引入了一个,可双向维护的数据结构来处理这种关系。

如上图:将改进后的同步规则使用一个独有的数据结构存储,此结构同时对 线程1和线程3可见。每个需要被过滤掉的表数据仅需要被线程3处理一次即可以得到其对象ID,将过滤掉表的对象ID填入共用数据结构中。线程1后续在读取物理文件时,需要首先基于队列结构中存储的对象ID做过滤,然后才将没有过滤掉的数据向上传递(线程2 -> 线程3)。从而减少后续线程2和线程3的工作量。
类比手机生产流水线如下图:工人1和工人3 共用一套质检规则,工人3质检淘汰过的产品零件都会被标记,都会记录到质检规则中,后续供工人1使用。在工人1零件制作过程就可以淘汰掉不合格零件,大大减少后续工人的工作量。

此外,KFS V2.0还引入了初始黑名单的机制,客户可以在启动时直接将某些无需同步的表ID信息放入同步黑名单中。这样,对于此类表,连线程3 的第一次过滤动作也不需要了。
关键技术 ---“分片并行入库”
1、 分片并行入库的基础原理
“分片并行入库”技术主要是采用了并行处理的性能优化原则,指的是当且仅当并行带来的增速抵消通信开销和资源争用延迟时,可以引入并行处理。同时,在引入并行处理后,KFS还使用了一些策略来权衡并行线程之间的协作关系。
KFS分片并行入库”的核心原理在于,将不同的事务、以表为单位拆分到不同的入库队列,由单线程的入库模型转变为多线程的入库模型。类比手机零件生产,将不同零件如屏幕、电池、主板等的生产工人分成不同小组,再同步进行制作生产。
(1)引入多线程的多通道入库模型加速入库
(2)单通道内由于是针对单表的操作,数据库的PBE特性可以发挥作用,对性能提升产生叠加效应。
原始入库逻辑
引入分片并行入库特性后的入库逻辑
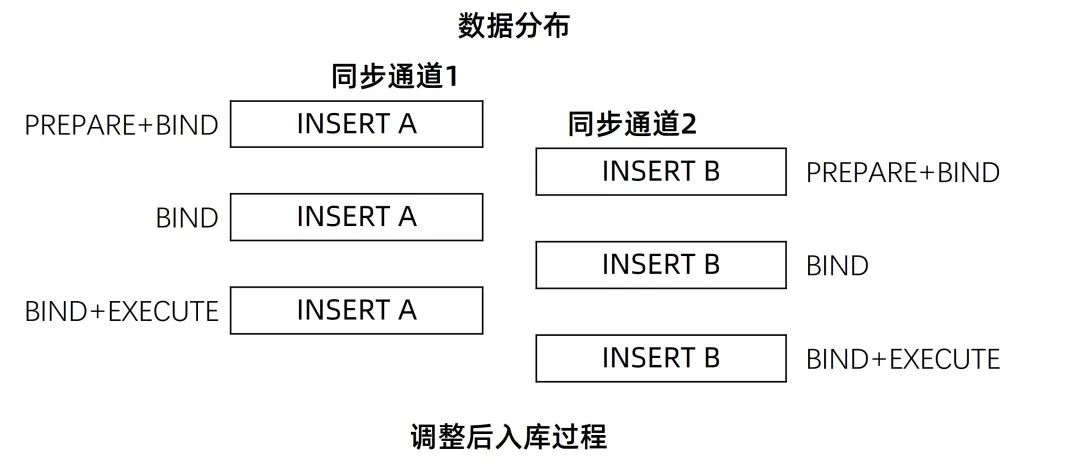
调整后事务被拆分成了两条入库通道,性能为原来的2倍。再加上每个通道都充分使用了数据库的PBE特性,性能又有了进一步的提升。
2、复杂场景的并行分片逻辑
分片后的入库通道是完全并行、互不相干的,而数据库中的表往往并非是不相关的,可能存在一些外键的引用关系。有引用关系表的数据就要求必须按照严格的顺序入库(否则会产生数据冲突)。例如,手机主板包括CPU、内存、各种控制器,它们可能有互相依赖的关系,不能随意更改制作顺序。
基于此,KFS 还使用了Critical数据区的概念。允许客户自行配置将哪些表分配至哪个通道中。对于有强依赖的表,可以配置到同一个通道,并且对于数据严格要求的表,可以将其设置为Critical,表示同步到这些表时,需要保证此数据之前的所有数据都已经入库,然后以单线程的形式同步这些表。类比手机主板生产,规定将CPU生产完成后,才能开始控制器的制作。
完成后,再次恢复为多线程并行分片的入库逻辑,比如初始化一个配置文件,指定针对哪些表的DML操作分配至哪个写线程。
Table=num,表示针对表Table的操作,分配至num写线程
Table=-1,表示针对表Table的操作,由算法进行自动分配
*=-1,表示针对其他表的操作,由算法进行自动分配(比如Hash或者轮询)
(critical)=Table1,Table2 表示针对Table1和Table2的操作,必须在强一致块中(即不允许并行)
5
下期预告
本期针对“分片并行入库”的特性中,介绍了Critical数据区的概念。引入Critical数据区的好处是可以保证在开启分片并行入库特性后数据入库的一致性,但是其缺点也很明显,如果同步过程中频繁的触发Critical屏障,就会使同步性能又降下来。
下一期,我们会继续此话题,介绍KFS中引入的有限容量等待队列特性。看KFS如何通过限容量等待队列特性,在保证数据一致性的前提下,将性能优化到极致。
















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









