






想象一下,无论是会议记录的手写笔记、老照片背后的故事,还是那些密密麻麻的财务报表,只需轻轻一拍,这些曾经难以触及的信息瞬间变得触手可及。
这不仅仅是技术的飞跃,更是对“懒惰”二字最优雅的诠释,哦不,是效率提升的新境界!
今天,咱们就来一场“文字解放运动”,揭秘几款超给力的表格识别图片文字软件。它们不仅识别率高到让你怀疑人生,还兼容多种格式,让你的信息处理之路畅通无阻。

一、翻译相机
为何它适合表格识别:
✿ 多功能集成
翻译相机不仅以其卓越的翻译能力著称,还巧妙融入了表格识别功能,能够迅速捕捉图片中的表格数据,实现信息的无缝转换。
✿ 操作简便
其界面设计直观清晰,即便是初次使用,也能迅速上手。只需轻轻一点,对准表格图片拍摄或上传,瞬间完成免费识别与提取,让数据整理变得轻而易举。
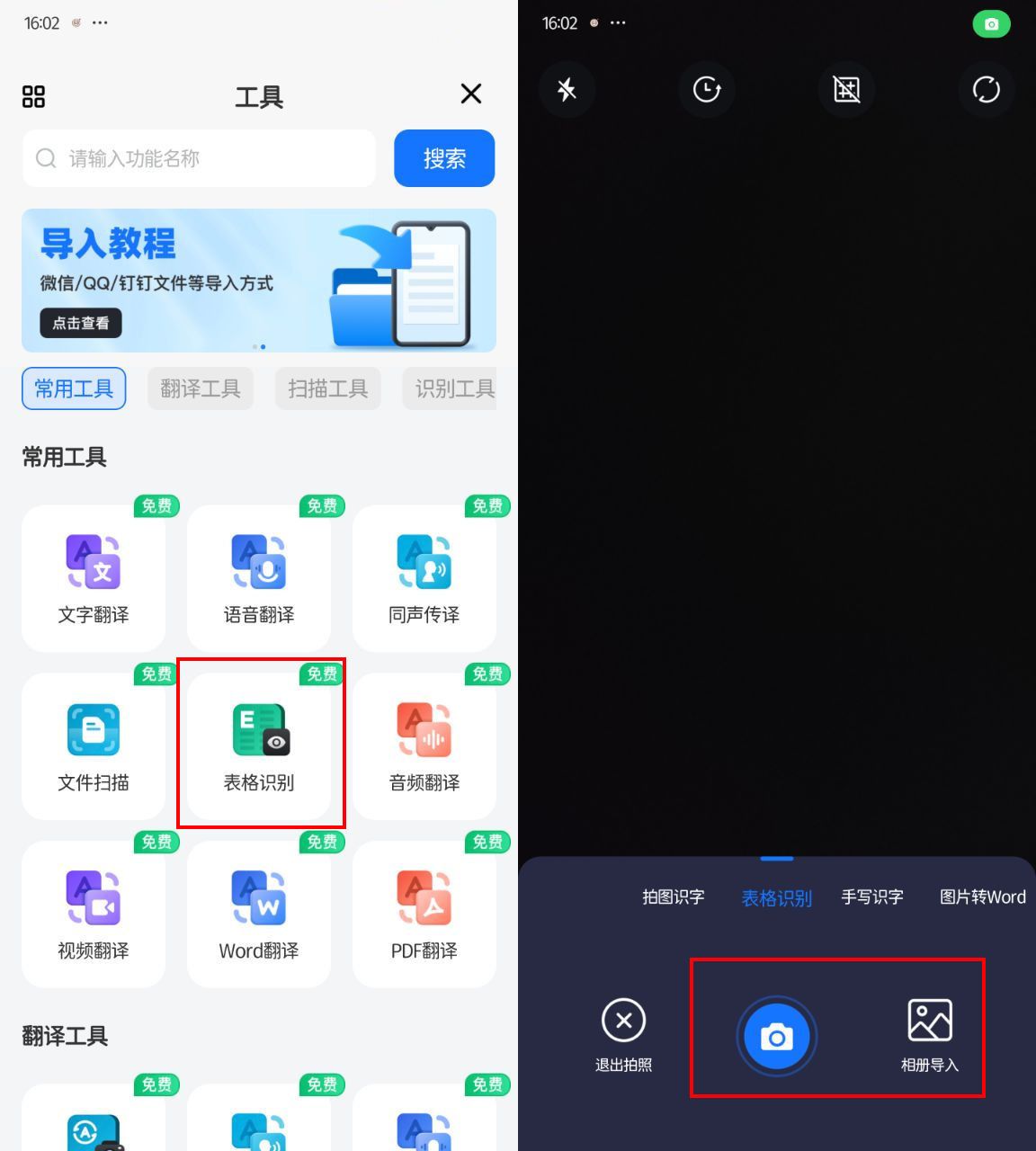
二、夸克
为何它适合表格识别:
✿ 综合工具箱
夸克浏览器内置了丰富的实用工具集,其中就包括表格识别功能。它如同一把瑞士军刀,随时待命,为你的数据处理需求提供强力支持。
✿ 流畅体验
无需跳转至其他应用,夸克浏览器内即可轻松找到并使用表格识别功能,操作流程行云流水,让你的工作更加顺畅无阻。
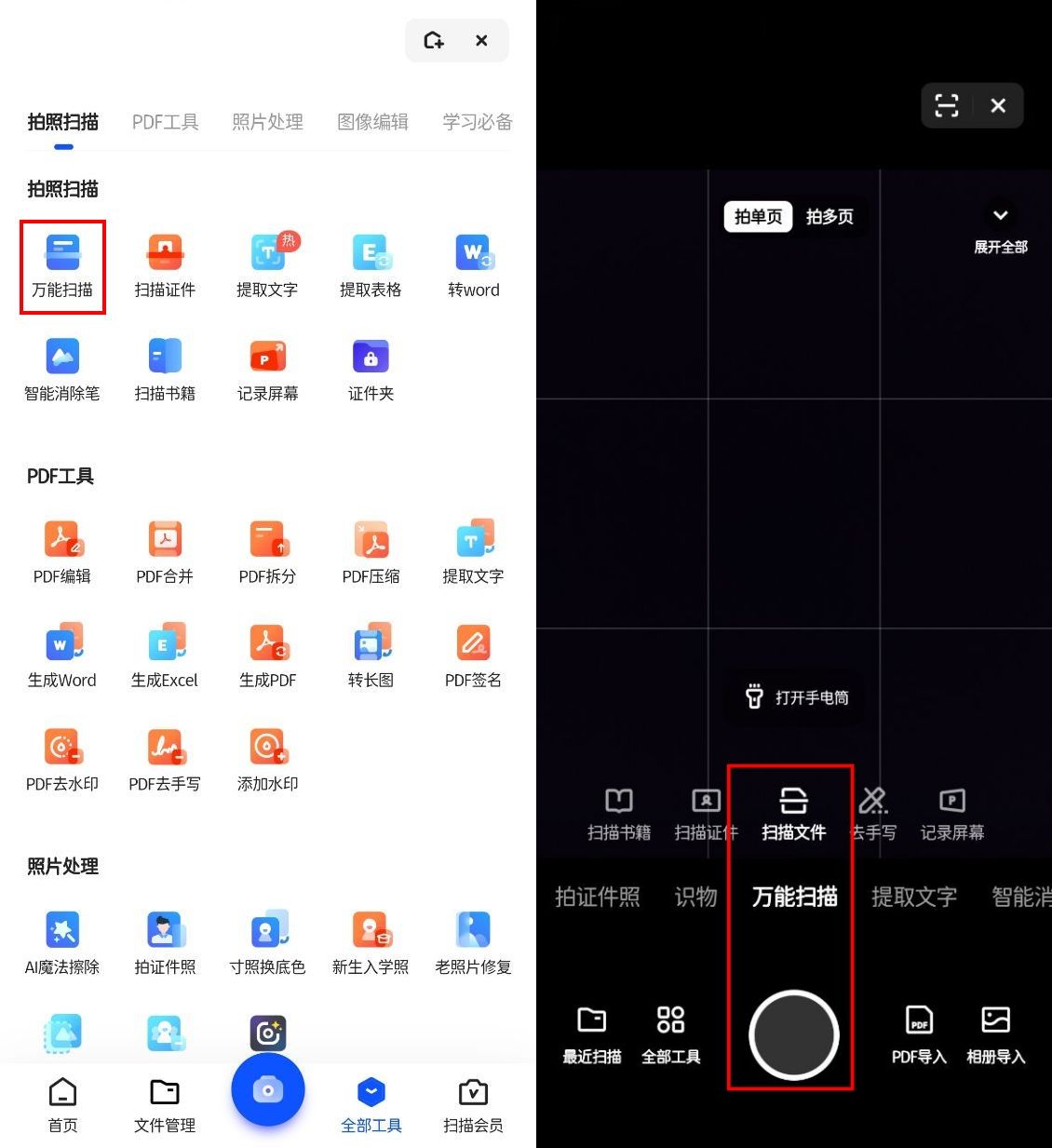
三、百度网盘
为何它适合表格识别:
✿ 云端集成服务
百度网盘,作为领先的云存储平台,不仅提供安全的文件存储服务,还贴心地加入了表格识别功能。让你在云端管理文件的同时,也能轻松提取所需数据。
✿ 便捷操作
只需简单几步,将表格图片上传至百度网盘,利用内置的解析工具,数据即可自动呈现,让你随时随地都能高效处理数据。
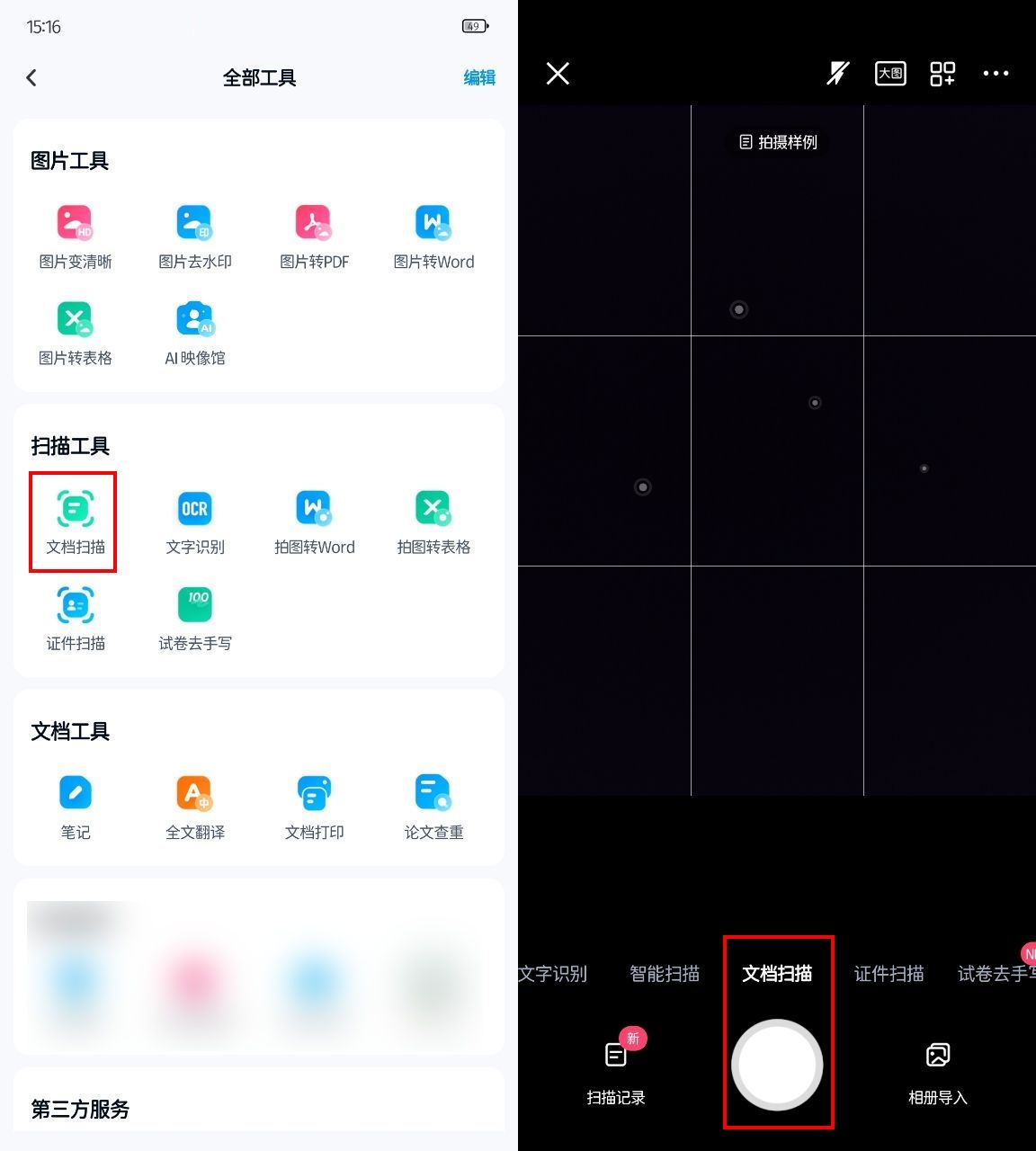
四、WPS Office
为何它适合表格识别:
✿ 办公一体化
WPS Office,作为一款集文档处理、表格编辑、演示制作于一体的全能办公套件,其表格识别功能同样不容小觑。它能够迅速从图片中提取表格数据,助力你的办公效率再上新台阶。
✿ 友好界面
WPS Office以使用者为中心,设计出了简洁明了的操作界面。一键式表格识别功能,让即便是数据处理的初学者也能轻松上手,享受高效办公的乐趣。
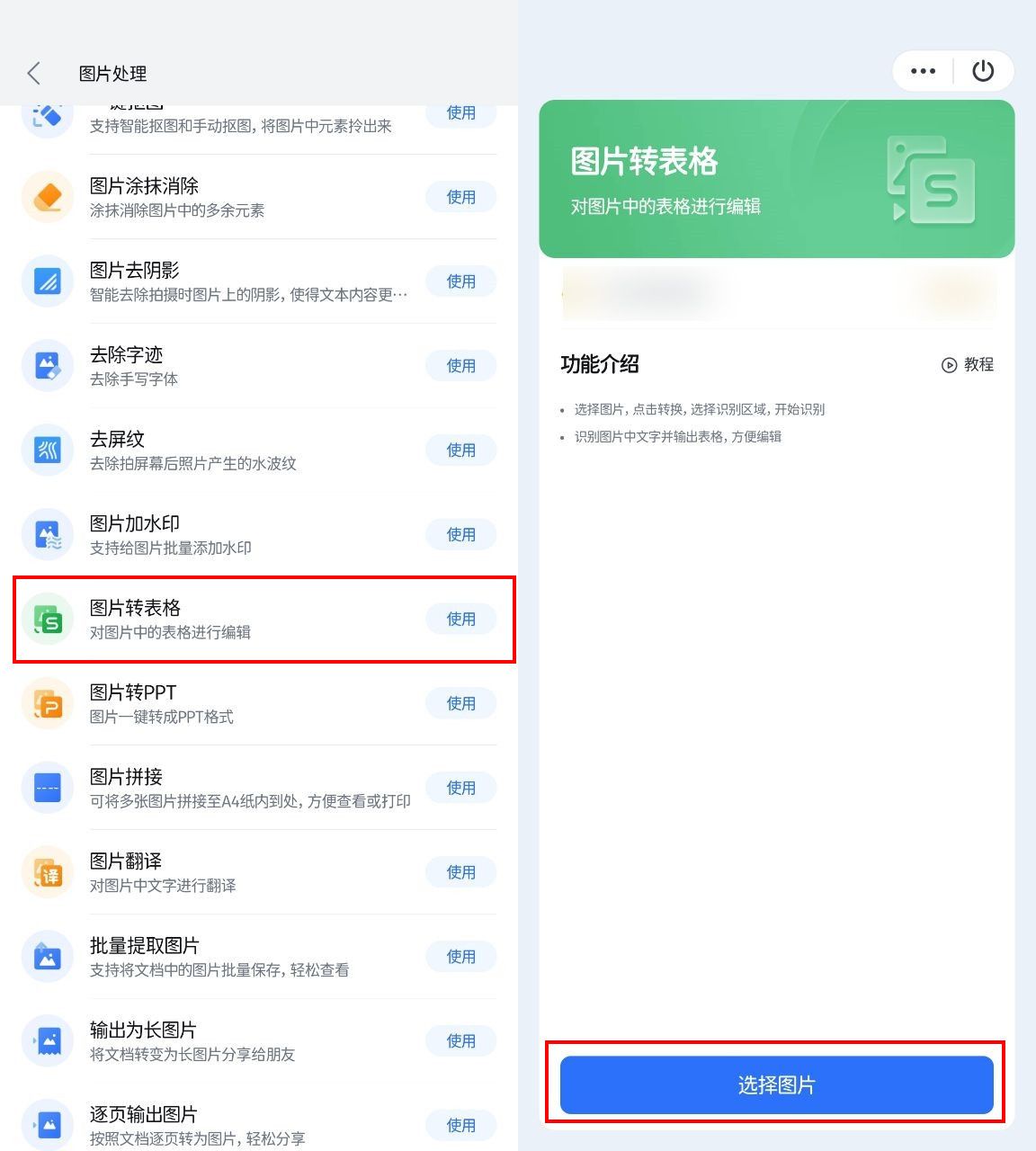
五、FormToExcel
为何它适合表格识别:
✿ 专业级转换
FormToExcel专注于将图片中的表格数据转换为Excel格式,凭借其高精度的识别技术和稳定的转换性能,赢得了众多朋友的青睐。
✿ 极速体验
无需复杂设置,只需简单上传表格图片,FormToExcel即可在极短的时间内完成识别与转换工作,让你的数据整理工作更加高效快捷。

这些工具如同你身边的得力助手,无论面对何种数据处理挑战,都能助你轻松应对。无论是紧急的工作任务,还是日常的数据整理需求,它们都能成为你不可或缺的得力帮手。别再让繁琐的数据录入成为你前进的绊脚石,赶快拥抱这些表格识别图片文字工具吧!















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









