







目 录
第1章 概述
1.1 Hello简介
P2P:from program to process ,即从程序到进程。Program是指编译出来的hello.c文件,process是指OS(进程管理)为通过编译系统(complication system)编译出的可执行文件hello在壳(shell)中利用fork函数创建子进程、调用execve函数来执行此文件等操作。

图1.1编译系统
在编译系统中,hello.c经过预处理器(cpp)预处理转换为hello.i,接着编译器(ccl)将hello.i翻译成文本文件hello.s,汇编器(as)将hello.s翻译成机器语言指令,并将这些指令打包的结果保存在目标文件hello.o中。
我们的hello程序调用了printf函数,printf存在于printf.o中,hello.o与printf.o通过链接的方式合并成可执行文件hello了。
020;from Zero-0 to Zero-0,即程序从无到有再到无。hello程序是程序员编写的hello.c经编译系统处理而来的。在OS操作系统中,shell中的execve函数加载并执行行hello,为其分配虚拟内存映射到物理内存中。接下来开始运行hello文件,当我们输入字符串“./hello”后,shell程序将字符逐一读入寄存器,再把它放到内存中。然后shell接收到我们从键盘传递的相关信号后并执行一系列指令来加载hello文件,这些指令将hello目标文件中的代码和数据从磁盘复制到主存。随后处理器就开始执行hello的main程序中的机器语言指令。这些指令将字符串中的字节从主存复制到寄存器文件,再从寄存器文件复制到显示设备,最终显示在屏幕上。就这样,hello程序已经完成了它的使命,会被shell回收,hello的生命就此结束。
1.2 环境与工具
硬件环境:X64 CPU;2GHz;2G RAM;256GHD Disk 以上
软件环境:Windows7/10 64位以上;VirtualBox/Vmware 11以上;Ubuntu 16.04 LTS 64位/优麒麟 64位 以上;
开发工具:Visual Studio 2010 64位以上;CodeBlocks 64位;vi/vim/gedit+gcc
1.3中间结果
hello.c :hello程序代码(文本文件)
hello.i :预处理产生的修改了的源程序(文本文件)
hello.s :编译产生的汇编文件(文本文件)
hello.o :可重定位的目标文件(二进制文件)
hello :可执行文件(二进制文件)
hello_rel.s :hello.o的反汇编文件
1.4 本章小结
本章简述了hello从生成到执行再到被回收的一生,并列出了本文要用到的hello相关文件。
(第1章0.5分)
第2章 预处理
2.1 预处理的概念与作用
预处理指的是预处理器(cpp)根据以字符#开头的命令,修改原始的C程序。
我们运用预处理指令进行预处理,这样使程序易于修改,使源程序在不同的执行环境下能够进行恰当的编译。
2.2在Ubuntu下预处理的命令
预处理指令:gcc -E hello.c -o hello.i
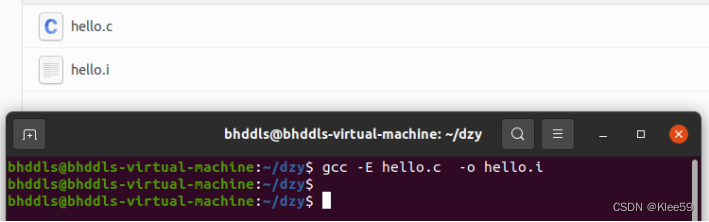
图2.1 预处理指令的结果
2.3 Hello的预处理结果解析
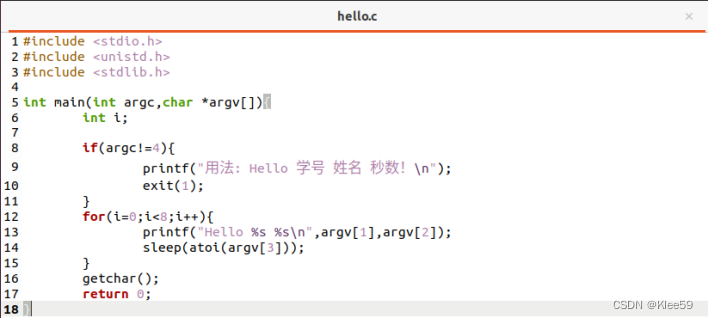
图2.2 hello.c程序
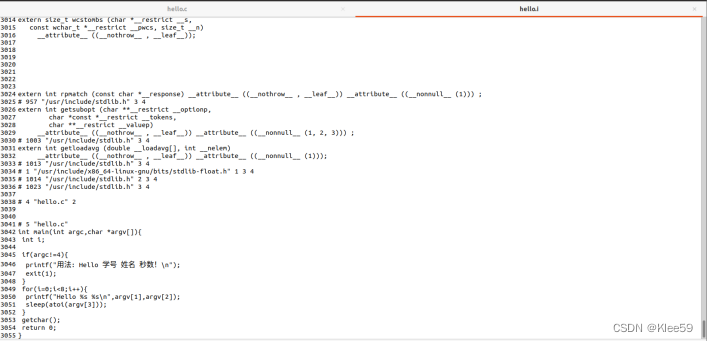
图2.3 hello.i程序
hello.c程序只有短短的十八行,而hello.i程序竟超过了3000行,其中真正程序之前是将#引入系统库的内容读进程序文本中真正对应程序代码,我们能在hello.i文件的末尾看到之前编写的hello代码。
2.4 本章小结
本章讲述了将hello.c翻译成可执行文件的第一步:预处理。预处理能够使程序易于修改,使源程序在不同的执行环境下能够进行恰当的编译,为接下来的翻译进程开辟了一条通路。
(第2章0.5分)
第3章 编译
3.1 编译的概念与作用
编译是编译器(ccl)将代码转换为汇编指令的过程。
注意:这儿的编译是指从 .i 到 .s 即预处理后的文件到生成汇编语言程序。编译的作用:编译而成的汇编语言程序中,每一条汇编语言都对应着低级机器语言指令。汇编语言为不同高级语言的不同编译器提供了通用的输出语言,这使得程序在各种情况下都能顺利翻译。
3.2 在Ubuntu下编译的命令
命令:gcc -S hello.i -o hello.s
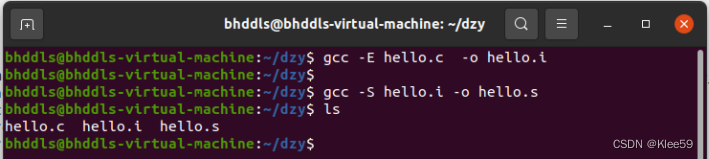
图3.1 命令的结果
3.3 Hello的编译结果解析
3.3.1 汇编代码中以“.”为开头的指令
(即伪操作(Pseudo-operation))

图3.2 汇编代码中的伪指令
其含义如以下表格:
| .file | 声明源文件 |
| .text | 代码段 |
| .global | 声明一个全局可见的名字(可能是变量,也可以是函数名) |
| .align | 对指令或数据的存放地址进行对齐 |
| .type | 用来指定一个符号的类型是函数类型或者是对象类型 |
| .size | 指定一个符号的大小 |
| .section | 定义内存段,汇编语言程序在其中定义元素 |
表3.1 汇编代码中的伪指令的含义
3.3.2 数据
3.3.2.1常量
![]()
图 3.3 常量的应用
直接用立即数表示,本图表示将%rax加16.
3.3.2.2变量
hello函数定义了局部变量int i
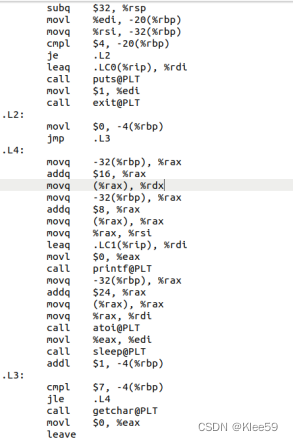
图3.3 hello.i的部分汇编代码
我们将代码与汇编代码结合,可知-4(%rbp)表示局部变量i,所以说明程序将局部变量i存放在栈中。
3.3.2.3 字符串
printf("用法: Hello 学号 姓名 秒数!\n");
printf("Hello %s %s\n",argv[1],argv[2]);
这两个printf函数中的格式字符串均被放到.rodata段,定义为.string类型,及字符串类型,如下是它们的汇编代码表示。
![]()
图3.4 printf函数内字符串的汇编代码表示
其中汉字用utf-8编码表示,每个汉字占3个字节。
3.3.2.4 数组
hello.c中含有数组argv[],汇编代码中对该数组的调用如图3.5所示:

图3.5 汇编代码中对argv[]的调用(部分)
由汇编代码可推断-32(%rbp)为argv的首地址,因为数组存放指针类型数据,大小为8,所以argv[0]地址需要加8,然后通过(%rax)寻址argv[1]。同理argv[2],argv[3]类似。
3.3.3 赋值操作
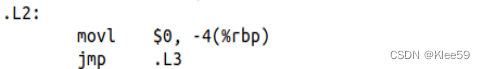
对.L2进行分析,可知.L2中第一句就是将0赋给i。赋值操作使用mov指令,根据数据大小使用不同的后缀,后面也会遇到这种情况。
| 指令 | b | w | l | q |
| 大小 | 1B | 2B | 3B | 4B |
表2 汇编指令中表示的数据大小
3.3.4 sizeof
对.L4中汇编代码进行分析,可以知道可推断-argv[0]地址加8,通过(%rax)寻址argv[1]。我们可知指针类型数据大小为8。
3.3.5 算术操作

框中进行的是subq操作,也就是减法操作。该减法操作是将栈扩充,为数组argv[]腾出寄存空间。

框中分别进行addq和leaq操作。
addq是加法操作,本框中的操作是将数组首地址加8来访问数组中的下一个元素argv[1]。
leaq是加载地址操作。框中.LC1(%rip), %rdi的含义是计算printf函数中格式串"用法: Hello 学号 姓名 秒数!\n"的地址,并传给%rdi。
3.3.6 关系操作

框中进行的是“==”操作,对应的是源代码中的if(argc!=4)语句,将argc与4比较,若不等于4,则继续执行后面的打印字符串和退出操作。
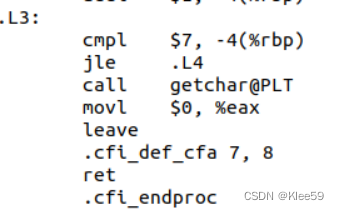
框中进行的是“<=”操作,对应的是循环中的for(i=0;i<8;i++)语句,将i与7比较,如果i不大于7,则跳转至.L4继续执行循环内操作,否则跳出循环。
3.3.7 数组操作
对.L4部分代码进行分析:-32(%rbp)为argv的首地址,并将该地址寄存到%rax中,因为数组存放指针类型数据,大小为8,所以argv[0]地址需要加8,然后通过(%rax)寻址argv[1],并将argv[1]寄存到%rsi上。同理argv[0]地址加上偏移量16,可得到argv[2]的地址,并寄存在%rdx中。
3.3.8 控制转移
3.3.8.1 if 语句
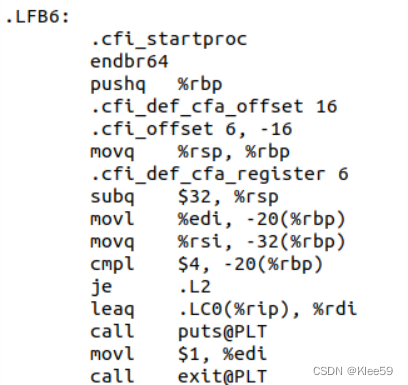
如上图:比较-20(%rbp)(即argc)与4是否相等,若相等则表明条件不满足跳到.L2执行之后的语句,若不相等则表明条件满足,继续执行if内的语句。因此这段代码对应了源代码中的if(argc!=4)语句。
3.3.8.2 for循环
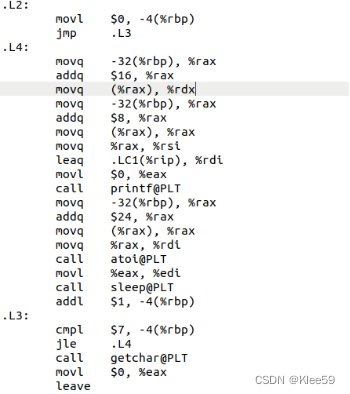
程序先在.L2中对循环变量i(即-4(%rbp))赋初值0,然后跳到.L3判断i是否满足循环条件,若满足则跳到.L4执行循环体,否则执行循环体之后的语句,在循环体.L4的最后每次对循环变量i执行加1操作。可知这些反汇编代码对应的是源代码中的“for(i=0;i<8;i++)”。
3.3.9 函数操作
3.3.9.1 参数传递
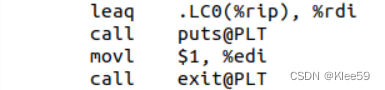
这几行代码对应源代码中的printf("用法: Hello 学号 姓名 秒数!\n")和exit(1)这两行语句。其中汇编代码将字符串内的内容传递到%rdi,并用printf函数进行传参,又将立即数1传递到%edi,并用exit函数进行传参。
3.3.9.2 函数调用
根据call指令,我们可以知道调用函数的情况,本程序中调用了puts、sleep、printf、getchar函数。
3.3.9.3 函数返回
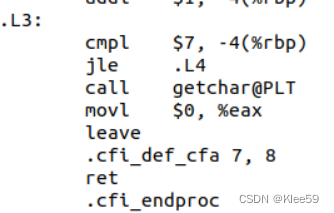
从.L3汇编代码可以看到返回%eax,而%eax的值被赋为0,相当于源代码中的“return 0”语句。
3.4 本章小结
本章我们通过汇编的概念,将hello.i编译成hello.s。我们又分析了hello.s中的汇编代码,对其汇编语言里的数据类型,条件控制,数组,字符串等等在汇编语言中的操作进行了较为详细的解释。我们可以通过源代码与汇编代码相互对照,发现汇编代码的奥秘。
(第3章2分)
第4章 汇编
4.1 汇编的概念与作用
概念:汇编器(as)将汇编程序翻译成机器语言指令,将这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件中。
作用:将汇编语言转换为机械语言,方便接下来的链接。
注意:这儿的汇编是指从 .s 到 .o 即编译后的文件到生成机器语言二进制程序的过程。
4.2 在Ubuntu下汇编的命令
gcc -c hello.s -o hello.o

图4.1 命令的结果
4.3 可重定位目标elf格式
通过命令readelf -a hello.o可查看hello.o的elf信息。
4.3.1 elf头
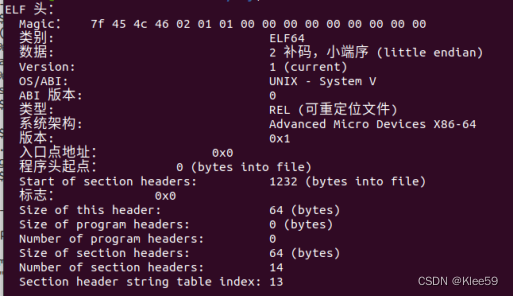
图4.2 elf头
我们可以看出ELF头以一个16字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。
通过观察,我们可以获取以下信息:
文件类型:可重定位文件(REL)
机器类型:x86-64小端(Advanced Micro Devices X86-64)
入口地址:0x0,表明程序在虚拟地址0x0处开始运行。
ELF头大小(Size of this header):64bytes
节头部表的大小(Size of section headers):64bytes
节的个数(Number of section headers):14
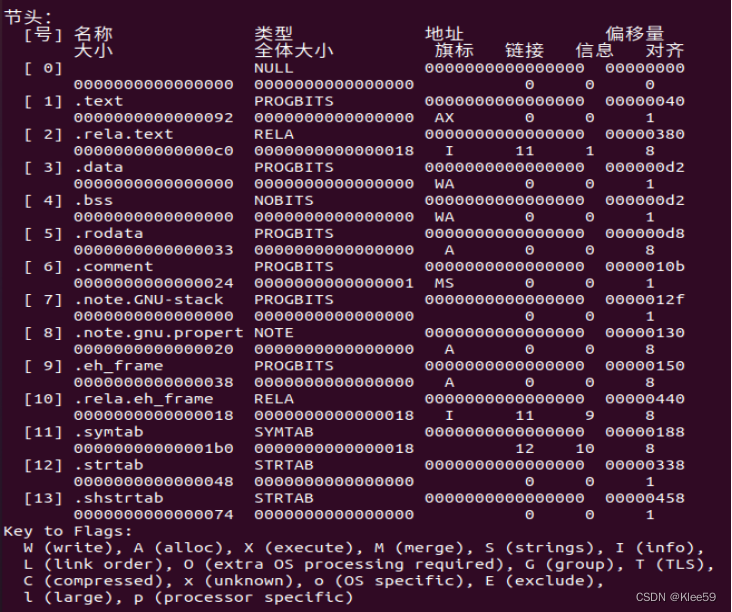
图4.3 节头部表
节头表描述了每个节的名称、大小、类型、位置和偏移。
4.3.2 代码重定位节(.rela.text节)
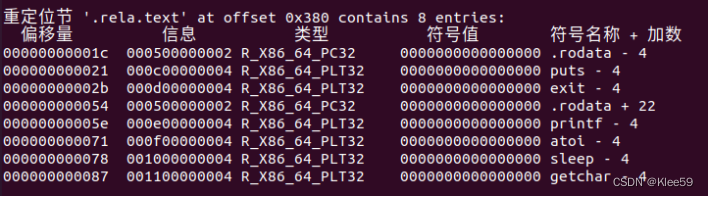
该列表体现了需要重定位条目的偏移量、重定位类型、符号值等信息。相关内容对应及作用如下:
| offset | 需要被修改的引用的字偏移 |
| type | 重定位类型告知链接器如何修改新的引用 |
| symbol | 标识被修改引用应该指向的符号 |
| addend | 有符号常数,一些类型的重定位要使用它对被修改引用的值做偏移调整 |
表4.1 .rela.text节中的重定位信息解读
其中表中的类型为最基本的类型:R_X86_64_PC32和R_X86_64_32。其中R_X86_64_PC32采用相对寻址,R_X86_64_32采用绝对寻址的方式。
除了.rela.text节,还有.rela.eh.frame节。.rela.eh.frame列表信息与前者一致,这里不再赘述。

图4.4 .rela.eh.frame表
分析hello.o的ELF格式,用readelf等列出其各节的基本信息,特别是重定位项目分析。
4.3.3 symtab节
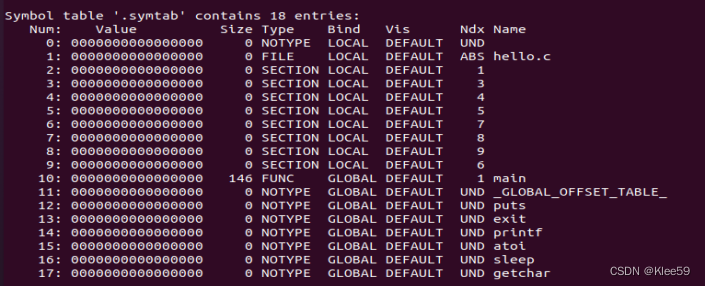
图4.5 .symtab表
符号表,用来存放程序中定义和引用的函数和全局变量的信息。重定位需要引用的符号都在其中声明。
4.4 Hello.o的结果解析
使用objdump -d -r hello.o>hello_rel.s 得到hello.o的反汇编代码,如下图所示:
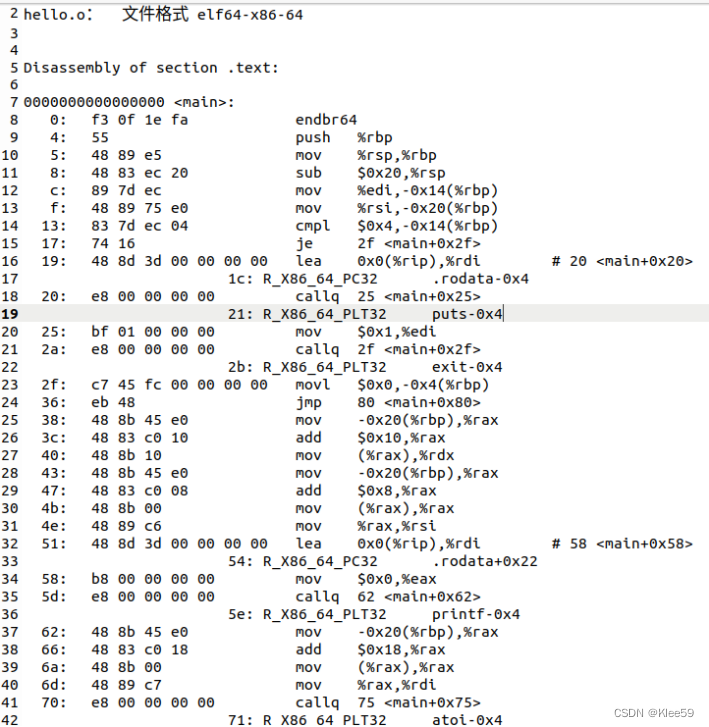
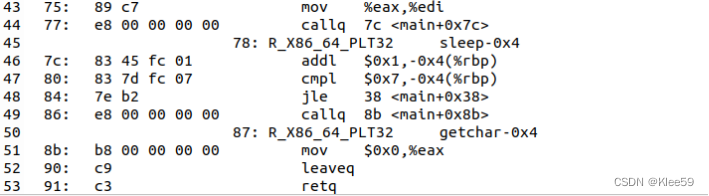
图4.6 hello.o的反汇编代码
1.反汇编.o文件得到的汇编代码和汇编.i文件得到的汇编代码的不同之处:
(1)汇编中mov、push、sub等等的指令后都有表示操作数大小的后缀,比如q、l等,反汇编得到的代码中没有。
(2)汇编代码中有很多以“.”开头的伪指令,用来指导汇编器和链接器工作,反汇编得到的代码中没有。
(3)汇编代码中调用函数是用“call 函数名”来表示,而反汇编代码中用“call 数字”表示,且相对应的机器代码中有PC相对引用的占位符。
(4)汇编代码中跳转“jmp Lable”的形式,在反汇编代码中直接为“jmp地址”的形式。
2.机器语言的构成:
机器语言由二进制的机器指令序列集合构成,机器指令由操作码和操作数组成。
与汇编语言的映射关系:一条汇编语言对应一条机器指令,其中每条机器指令的长度不一定一致。(因为X86-64为CISC(复杂指令计算机),其指令编码长度可变(0-15个字节),与RISC(精简指令计算机)相对,其指令长度固定。
4.5 本章小结
本章汇编器将汇编指令翻译成了机械指令,.s文本文件变成了.o二进制文件,为接下来的链接做铺垫。我们详细分析了hello.o的elf头相关信息,并比较了hello.o与hello.i的汇编代码的区别。
(第4章1分)
第5章 链接
5.1 链接的概念与作用
概念:链接是将各种代码和数据片段收集并组合成为一个单一文件的过程。
作用:使各种代码和数据片段组合成可被加载(复制)到内存并执行的单一文件,并使分离编译成为可能。通过链接,我们不用将一个大型的应用程序组织为一个巨大的源文件,而是可以把它分解为更小、更好管理的模块,可以独立的修改和编译这些模块。当我们改变这些模块中的一个时,只需简单地重新编译它,并重新链接应用,而不必重新编译其他文件。
注意:这儿的链接是指从 hello.o 到hello生成过程。
5.2 在Ubuntu下链接的命令
命令:
ld -o hello -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o /usr/lib/x86_64-linux-gnu/libc.so /usr/lib/x86_64-linux-gnu/crtn.o
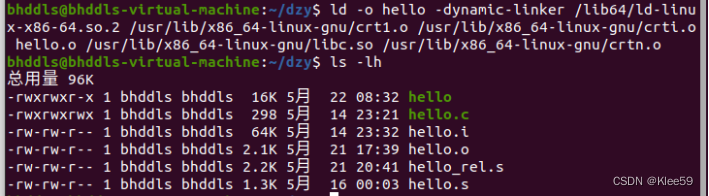
图 5.1 链接命令及结果
5.3 可执行目标文件hello的格式
5.3.1 elf头
我们输入readelf -h hello来获取hello的elf头。
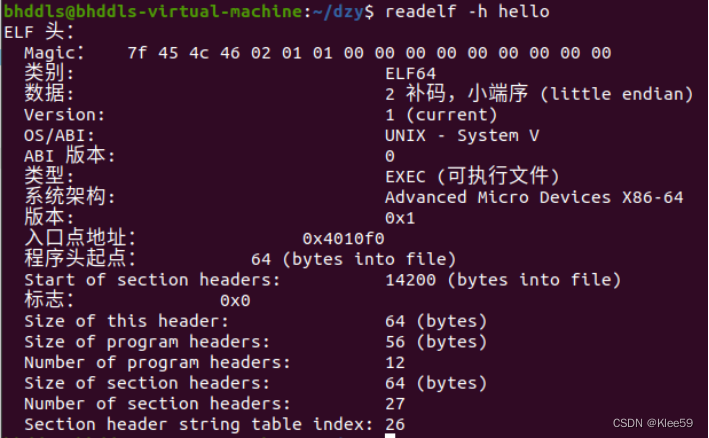
图 5.2 hello文件的elf头
hello的elf头和hello.o的elf头有许多异同点。
相同点:两者Magic、类别、版本、系统架构相同。
不同点:1.hello是可执行文件,hello.o是可重定位文件。
- hello的入口点地址不为0,hello.o的入口点地址为0。
- hello的节的个数为27大于hello.o的节的个数。
- hello的program header数目和大小均不为零,而后者为零。
5.3.2 节头
我们输入命令readelf -S hello来获取节头信息。
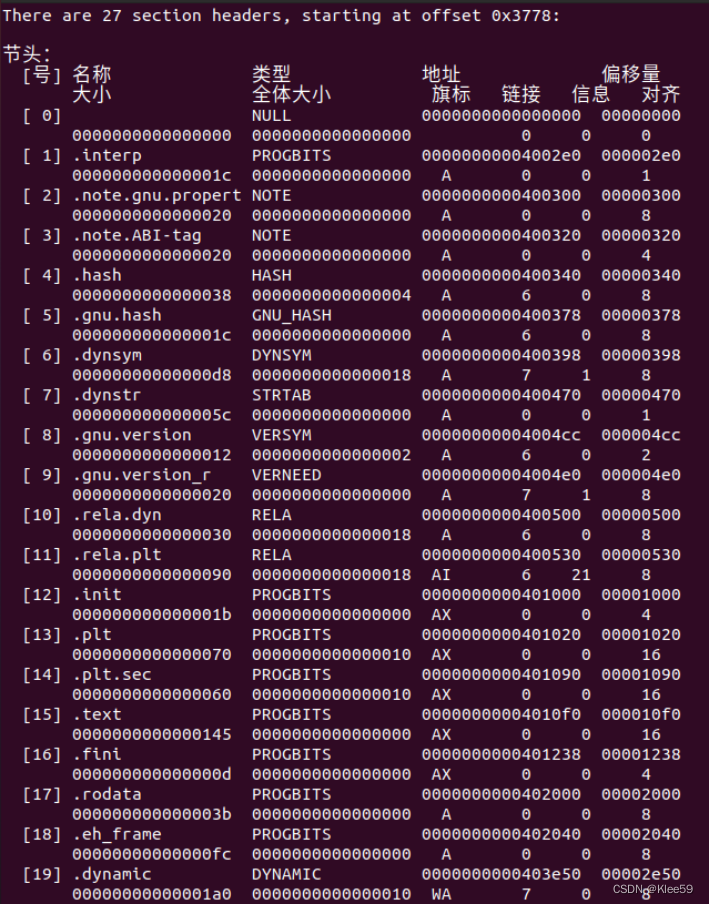
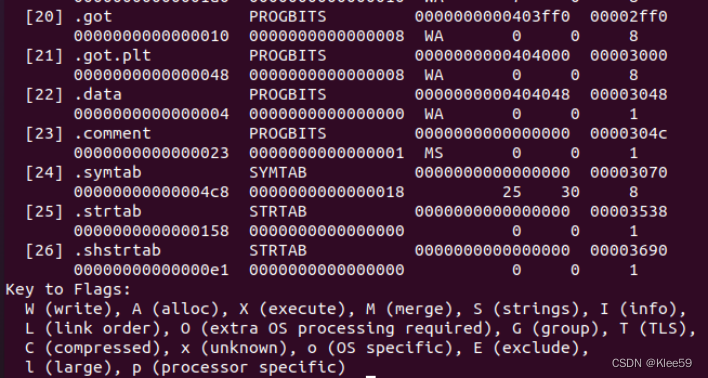
图 5.3 hello文件的节头信息
5.3.3 可重定位段
我们输入命令readelf -r hello来获取可重定位段信息。
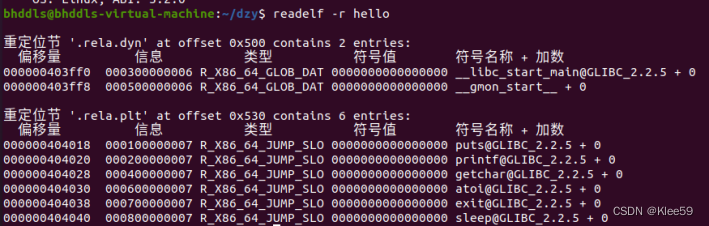
图 5.3 hello文件的可重定位段信息
5.3.3 .symtab节
我们输入命令readelf -s hello来获取symtab表信息。
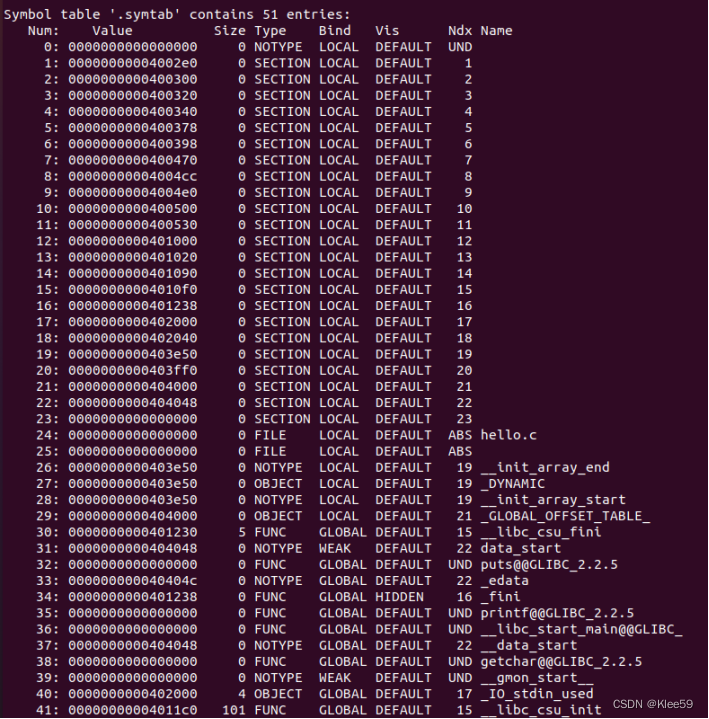
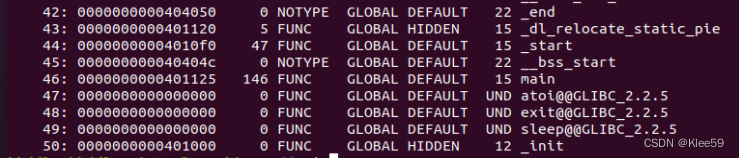
图 5.4 hello文件的symtab表信息
与hello.o的symtab表对比可知,hello的symtab表符号数量明显增大,说明经过链接之后引入了许多其他库函数的符号,并加入到symtab表中。
5.4 hello的虚拟地址空间
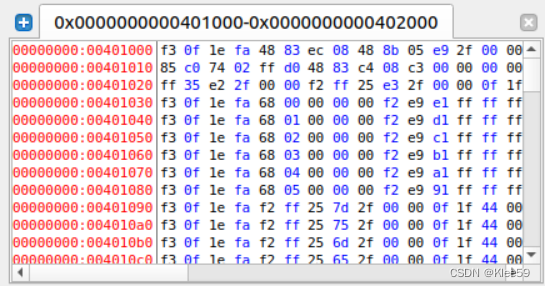
图 5.4 hello地址空间展示(部分)
hello虚拟地址空间的起始地址为0x401000,根据5.3中节头部表,我们可以找到对应的节的虚拟空间对应位置。例如我们可以根据.text节的地址0x4010f0,我们可在edb中查看该地址的相关信息。
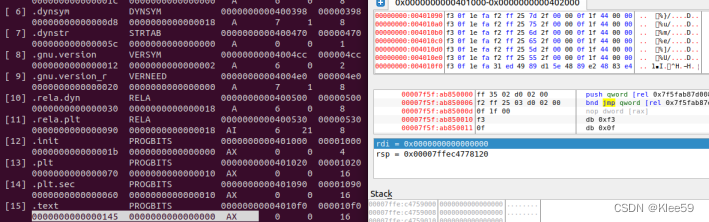
图 5.5 hello地址空间对照实例
5.5 链接的重定位过程分析
通过命令objdump -d -r hello,我们调出了hello的汇编代码。
hello与hello.o的不同点:
- hello.o中,main函数地址从0开始,hello.o中保存的是相对偏移地址;而在hello中main函数0x401125开始,即hello中保存虚拟内存地址。
- hello中多了.init节、.plt、.plt.sec和.fini段。.init节定义函数_init,用于程序的初始化代码,还有初始化程序执行环境;.plt段为程序执行时的动态链接;.fini段用于返回值。
3.在hello中加入了在hello.c中用到的函数,如exit、printf、sleep、getchar等函数,我们可以通过callq指令直白地了解hello具体调用了哪些函数。而hello中callq调用函数部分,只是简单地以main加上偏移值的地址呈现。
hello是如何重定位的:
①首先计算需要被重定位的位置
②然后链接器计算出运行时需要重定位的位置:
refaddr = ADDR(.text) + r.offset
③然后更新该位置
*refptr = (unsigned) (ADDR(r.symbol) + r.addend-refaddr)
实例分析:以hello.o中main函数反汇编代码中sleep函数为例
![]()
从中我们可以知道:
r.offset=0x78
r.symbol=sleep
r.type=R_X86_64_PLT32
r.addend=-4
由main地址可知ADDR(s)=ADDR(.text)=0x401125,
ADDR(r.symbol)=ADDR(sleep)=0x4010e0.
![]()
![]()
refaddr = ADDR(.text) + r.offset=0x40119d
*refptr = (unsigned) (ADDR(r.symbol) + r.addend-refaddr)= (unsigned)(0x3f)
我们得到对sleep的重定位引用的地址为3f与hello反汇编代码40119c中3f一致。
5.6 hello的执行流程
使用edb执行hello,说明从加载hello到_start,到call main,以及程序终止的所有过程。请列出其调用与跳转的各个子程序名或程序地址。
| 程序名称 |
| ld-2.32.so!_dl_start |
| ld-2.32.so!_dl_init |
| libc-2.32.so!__libc_start_main+0 |
| hello!puts@plt |
| hello!exit@plt |
| hello!printf@plt |
| hello!sleep@plt |
| hello!getc@plt |
| hello!_start |
| ld-2.32.so!exit |
5.7 Hello的动态链接分析
分析hello程序的动态链接项目,通过edb调试,分析在dl_init前后,这些项目的内容变化。要截图标识说明。
在程序中动态链接是通过延迟绑定来实现的,延迟绑定的实现依赖全局偏移量表GOT和过程连接表PLT实现。GOT是数据段的一部分,PLT是代码段的一部分。
PLT数组中每个条目时16字节,PTL[0]是一个特殊的条目,它跳转到动态链接器中。每个可被执行程序调用的库函数都有自己的PLT条目。PLT[1]调用_libc_start_main函数负责初始化。GOT数组中每个条目八个字节。GOT[0]和GOT[1]中包含动态链接器解析地址时会用的信息,GOT[2]包含动态链接在ld-linux.so模块的入口点。
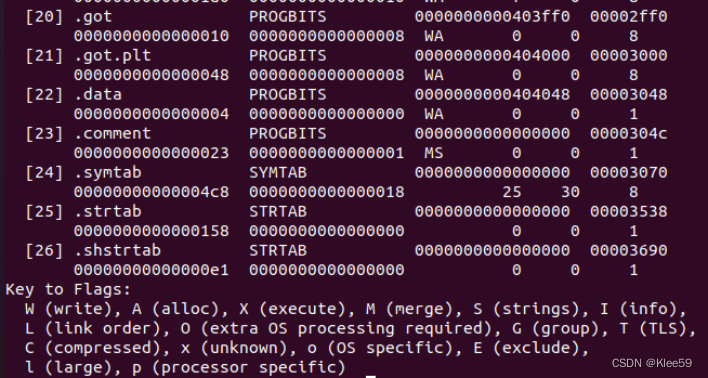
通过5.3节的表头可知.got.plt的地址为0x403048.
5.8 本章小结
通过链接,hello程序得以链接上程序启动时真正需要的一系列工作内容,包括共享库等等。在链接后,hello程序能够正式运行,至此,从hello.c的文本文件,经过编译、汇编、链接,生成了可执行文件。
(第5章1分)
第6章 hello进程管理
6.1 进程的概念与作用
概念:进程是一个执行中程序的实例。
作用:进程提供给应用程序关键抽象:
- 一个独立的逻辑控制流,它提供一个假象,好像我们的程序独占地使用处理器。
- 一个私有的地址空间,它提供一个假象,好像我们的程序独占地使用内存系统。
6.2 简述壳Shell-bash的作用与处理流程
作用:连接了用户和内核,让用户能够更加高效、安全、低成本地使用内核。
处理流程:1.读取用户输入的命令
2.将用户输入的命令进行解析,若命令为内置命令,则立即执行
3.shell通过fork创建子进程,通过execve函数加载可执行文件,shell自身则调用wait()函数来等待子进程完成
4.shell还会接收用户输入的信号并执行相应操作
5.shell会回收已执行完的进程
6.3 Hello的fork进程创建过程
Shell运行hello时,父进程通过fork函数生成这个程序的进程。这个子进程几乎与父进程相同,子进程得到与父进程相同的虚拟地址空间(独立)的一个副本,包括代码,数据段,堆,共享库以及用户栈,并且和父进程共享文件。它们之间最大的不同是PID不同。Fork函数在子进程PID为0,父进程中PID不为0.
6.4 Hello的execve过程
当创建了一个新运行的子进程后,子进程调用execve函数在当前子进程的上下文中加载并运行hello程序。execve函数加载并运行可执行目标文件hello,且带参数列表argv和环境变量列表envp。正常情况下execve调用一次且不返回。只有当出现错误时,例如找不到hello,execve才会返回到调用程序。
6.5 Hello的进程执行
进程上下文信息:内核为已经加载并运行的进程hello维持了一个上下文,上下文是内核重新启动一个被抢占的所需的状态。它由一些对象的值组成,这些对象包括通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈和各种内核数据结构,比如描述地址空间的页表、包含有关当前进程的进程表,以及包含进程已打开文件信息的文件表。
上下文切换:在进程执行的某些时刻,内核可以决定抢占当前进程,并重新开始一个先前被抢占了的进程。这种决策叫做调度。在内核调度了一个新的进程运行后,它就抢占当前进程,并使用上下文切换的机制来将控制转移到新的进程。这种切换可以出现在内核代表用户执行系统调用时、中断时等等。比如hello中对sleep函数的调用,就会使进程从用户模式切换到内核模式。在内核模式中对该进程进行适当的处理时,调度器就会执行上下文切换,重新开始另一个进程,直到原进程再次从内核模式切换到用户模式。用户模式下某些操作还会使进程切换到内核模式,以此类推。
6.6 hello的异常与信号处理
6.6.1 异常与信号的描述
1.异常的有关描述:
异常可以分为四类:中断、陷阱、故障和终止。
| 类别 | 原因 | 异步/同步 | 返回行为 |
| 中断 | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
2.信号的有关描述:
信号允许进程和内核中断其他进程。每种信号类型都对应于某种系统事件。详细的Linux信号及处理方式见下表:
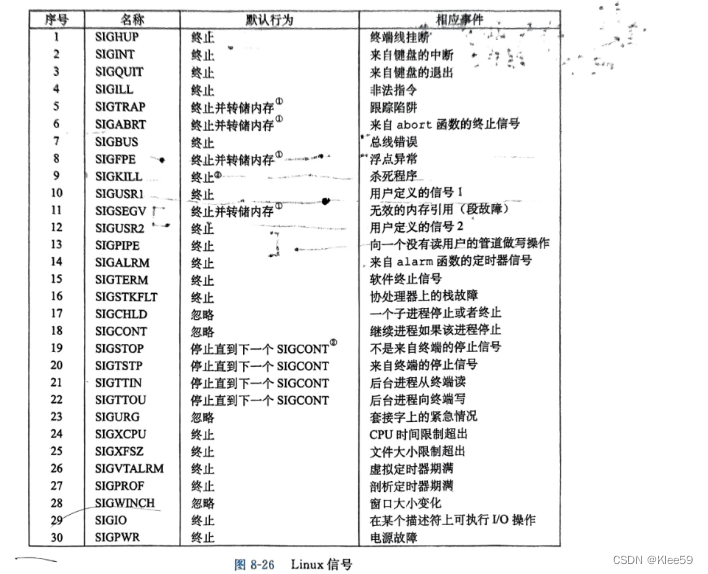
表 6-1 Linux信号表
6.6.2 键盘上各种操作导致的异常
- hello正常运行时:
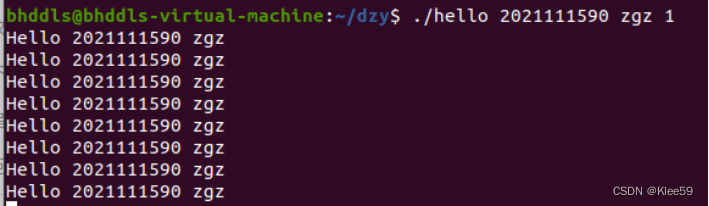
程序会输出8行所输入的字符串,此时进程已被回收。
- 使用Ctrl+Z
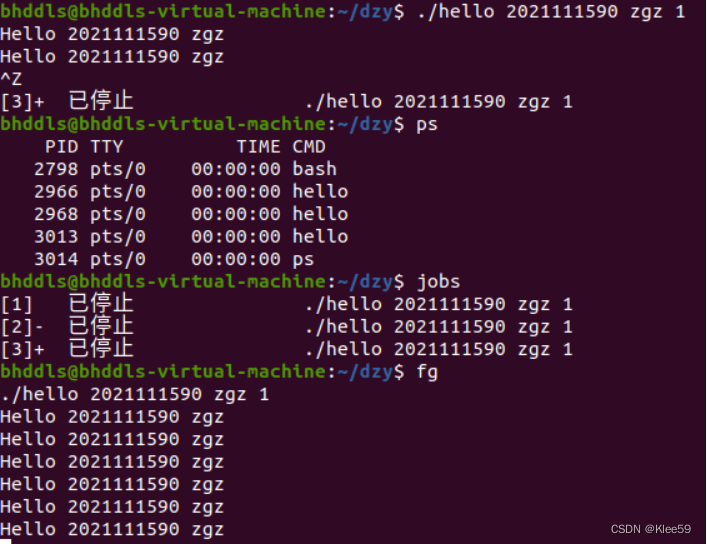
Ctrl+Z会挂起前台进程,此时hello会被挂起,但是没有终止,更没有回收。
使用ps指令看到该进程依然存在,使用jobs指令发现其作业序号不空,使用fg指令将上一个进程调度到前台,可以发现它能够继续执行。
3.使用Ctrl+C

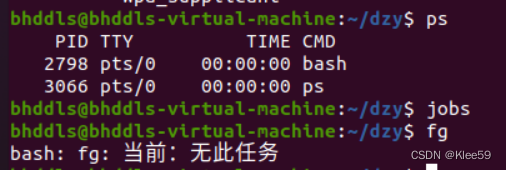
输入Ctrl+C会使hello终止并被回收。使用ps指令看到该进程不存在了,使用jobs指令发现作业序号为空,使用fg指令显示当前无此任务,可以发现它不能够继续执行了。
4.乱按

出现了很有趣的现象,乱按时字符串会进入缓冲区,在getchar时被读入。但一旦输入回车,就会在读入getchar之后当作命令行参数进行解读。
6.7本章小结
本章围绕着进程,讲述了shell的作用,并应用shell执行hello中的fork和execve函数。本章还对hello进行了异常和信号处理的相关分析。我们通过键盘向hello输入不同的指令,出现的效果也不同。Shell和信号处理真是神奇!
(第6章1分)
第7章 hello的存储管理
7.1 hello的存储器地址空间
逻辑地址:在计算机体系结构中是指应用程序角度看到的内存单元、存储单元、网络主机的地址,又叫相对地址。它是在网络层及以上使用的地址。
线性地址:线性地址是逻辑地址到物理地址变换之间的中间层。逻辑地址加上基地址就是线性地址。
虚拟地址:虚拟地址则是操作系统对存储器和I/O设备的抽象,虚拟地址系统为每一个进程都提供一个看起来独立的地址空间,形成每一个进程都运行在独立的地址空间的假象。这样做能够大大方便内存管理、简化链接、简化加载等。在hello中,我们看到的.text段的起始地址是0x4010f0,这是一个虚拟地址,需要在MMU中转化为物理地址。
物理地址: 指的是真实物理内存中地址,更具体一点就是内存地址寄存器中的地址。物理地址是内存单元真正的地址。
7.2 Intel逻辑地址到线性地址的变换-段式管理
(以下格式自行编排,编辑时删除)
逻辑地址由段标识符和段内偏移量两部分组成。段标识符由一个16位长的字段组成,称为段选择符,而段内偏移量由一个32位长的字段组成。段标识符也称为段选择符。其组成为:
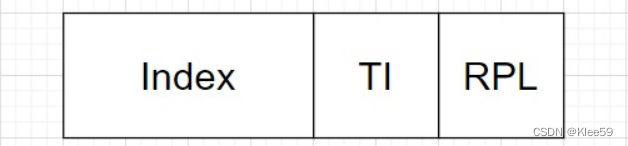
图7.1 逻辑地址结构图
Index(索引号):bit位3-15,指定相应段描述符的入口。
TI(Table Indicator)标志:bit位2,指明段描述符在GDT(TI=1)还是在LDT(TI=0)。
RPL(请求者特权级):bit位0-1,当相应的段选择符装入到CS寄存器中时指示出CPU当前的特权级。
我们可以通过索引号在段描述符表中找到一个具体的段描述符,根据TI内的值来确定段描述符的存储位置。其中,段描述符在GDT和LDT中,TI标志所指明的GDT和LDT表示的是该段描述符是在全局描述符表(GDT)还是局部描述符表(LDT)。每个段描述符都含有描述段开始位置的线性地址的Base段。要将逻辑地址转换为线性地址,首先通过索引号找到段描述符的位置,并通过其中的Base段找到段的基址。基址加上逻辑地址中的段内偏移量就是线性地址。
7.3 Hello的线性地址到物理地址的变换-页式管理
(以下格式自行编排,编辑时删除)
Linux中线性地址可认为是虚拟地址。可使用页表来实现线性地址到物理地址的转换,如下图所示:
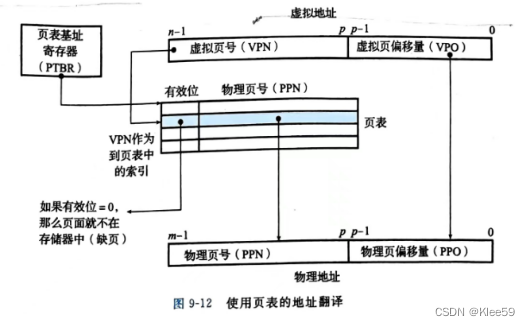
图7.2 使用页表实现线性地址到物理地址的转换
由图可知,虚拟地址由虚拟页号(VPN)和虚拟页偏移量(VPO)组成。物理地址由物理页号(PPN)和物理页偏移量(PPO)组成。其中VPO和PPO相同。虚拟地址先通过VPN在页表中寻找相匹配的PPN,PPN和VPO串联起来就实现了从虚拟地址到物理地址的翻译了。
7.4 TLB与四级页表支持下的VA到PA的变换
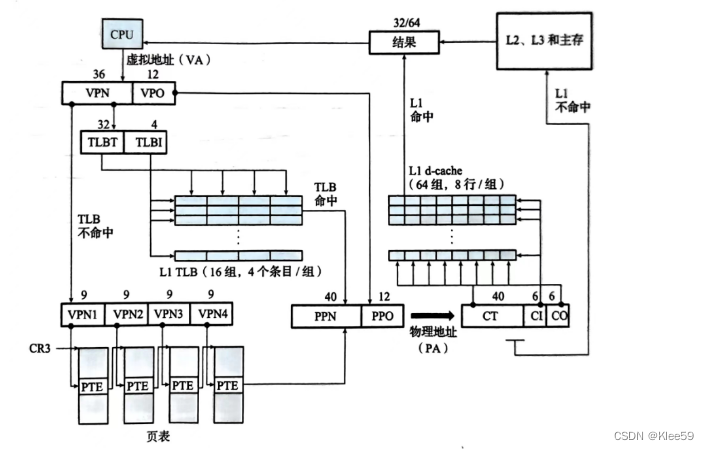
图7.3 Core i7中虚拟地址转换为物理地址的情况
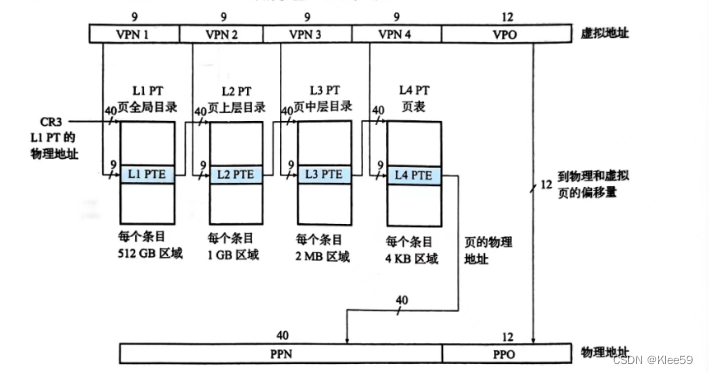
图7.4使用四级页表实现线性地址到物理地址的转换
本节以Core i7为例进行TLB与四级页表支持下VA到PA的转换。VPN由TLBT(标记位)和TLBI(索引位)组成。VPN利用这两个部分先在L1的TLB中进行查询。若发生命中,则之后的步骤同7.3节;若不发生命中则调用四级页表进行图7.4的转换步骤。
36位VPN被划分为四个9位的片,每个片被用作到一个页表的偏移量。CR3寄存器包含L1页表的物理地址。VPN提供到一个L1 PTE的偏移量,这个PTE包含L2 页表的基地址。VPN 2提供到一个L2 PTE的偏移量,以此类推。最后在L4页表中对应的PTE中取出PPN,与VPO连接,形成物理地址PA。
7.5 三级Cache支持下的物理内存访问
本节继续引用7.4节提到的Core i7继续分析。
如图7.4所示,物理地址由标记位(CT)、索引位(CI)和偏移位(CO)组成。物理地址先访问L1 d-cache,通过调用物理地址的CT、CI和CO来查找L1 d-cache中是否有匹配项。若L1命中,则直接取出数据。若L1不命中,则调用L2、L3和主存,若还是不命中,则调用U盘,直到找到为止。
7.6 hello进程fork时的内存映射
当fork函数被当前进程调用时,内核为新进程创建了各种数据结构,并分配给它一个唯一的PID。为了给这个新进程创建虚拟内存,它创建了当前进程的mm_struct、区域结构和页表的原样副本。它将两个进程中的每个页面都标记为只读,并将两个进程中的每一个区域结构都标记为私有的写时复制。当fork在新进程中返回时,新进程现在的虚拟内存刚好和调用fork时存在的虚拟内存相同。当这两个进程中的任意一个后来进行写操作时,写时复制机制就会创建新页面。
7.7 hello进程execve时的内存映射
(以下格式自行编排,编辑时删除)
execve函数在当前进程中加载并运行包含在可执行目标文件hello中的程序,用hello程序有效地替代了当前程序。加载并运行hello需要:
(1)删除已存在的用户区域。删除当前进程虚拟地址的用户部分中的已存在的区域结构。
(2)映射私有区域:为新程序hello的代码、数据、bss 和栈区域创建新的区域结构。所有这些新的区域都是私有的、写时复制的。代码和数据区域被映射为可执行文件的.text和.data区。bss区域是请求二进制零的,映射到匿名文件,其大小包含在a.out中。栈和堆区域也是请求二进制零的,初始长度为零。
(3) 映射共享区域:如果hello程序与共享对象(或目标)链接,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
(4) 设置程序计数器(PC):execve做的最后一件事情就是设置当前进程上下文中的程序计数器,使之指向代码的入口点。
7.8 缺页故障与缺页中断处理
缺页故障:DRAM缓存不命中。
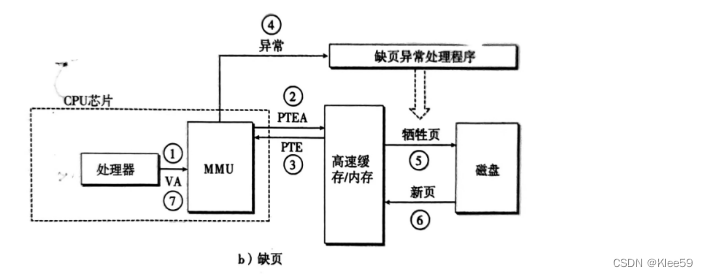
图7.5缺页的处理
当触发缺页异常时,缺页处理程序确定出物理内存中的牺牲页,如果这个页面已经被修改了,则把它移出磁盘。接着,缺页处理程序页面调入新的页面,并更新内存中的PTE。随后缺页处理程序返回到原来的进程,再次执行导致缺页的指令。CPU将引起缺页异常的虚拟地址重新发给MMU。因为虚拟页面现在缓存在物理内存中,所以就会发生命中,之后也不会再发生缺页异常了。
7.9动态存储分配管理
(以下格式自行编排,编辑时删除)
Printf会调用malloc,请简述动态内存管理的基本方法与策略。
7.10本章小结
本章首先对四个地址概念做了介绍。然后对段页式管理做了简单介绍,用Core i7介绍了TLB与页表支持下虚拟地址到物理地址的转换和cache与虚拟内存的实际使用。通过虚拟内存,我们对fork和execve函数的映射关系有了全新理解,对于hello的诞生有了更清楚认识。本章也介绍了缺页故障与缺页中断处理。可见hello的诞生离不开虚拟地址到物理地址的转换。
(第7章 2分)
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
(以下格式自行编排,编辑时删除)
设备的模型化:文件
设备管理:unix io接口
8.2 简述Unix IO接口及其函数
(以下格式自行编排,编辑时删除)
8.3 printf的实现分析
(以下格式自行编排,编辑时删除)
https://www.cnblogs.com/pianist/p/3315801.html
从vsprintf生成显示信息,到write系统函数,到陷阱-系统调用 int 0x80或syscall等.
字符显示驱动子程序:从ASCII到字模库到显示vram(存储每一个点的RGB颜色信息)。
显示芯片按照刷新频率逐行读取vram,并通过信号线向液晶显示器传输每一个点(RGB分量)。
8.4 getchar的实现分析
(以下格式自行编排,编辑时删除)
异步异常-键盘中断的处理:键盘中断处理子程序。接受按键扫描码转成ascii码,保存到系统的键盘缓冲区。
getchar等调用read系统函数,通过系统调用读取按键ascii码,直到接受到回车键才返回。
8.5本章小结
(以下格式自行编排,编辑时删除)
(第8章1分)
结论
1.hello所经历的过程:
预处理:将.c文件处理成加入了部分信息的.i文件。
编译:编译器将.i文件翻译成由汇编语言描述的.s文件。
汇编:汇编器将.s文件转化成由机器代码构成的可重定位目标文件.o。
链接:通过符号解析、重定位和一系列静态库、动态库的链接,形成真正可以被加载的可执行文件。
运行:在shell中输入hello和命令行参数,shell将运行hello程序,并用fork函数建立一个子进程并在子进程中用execve函数执行 hello程序。
异常:在运行过程中,使用Ctrl+C/Ctrl+Z向进程发送信号,进程会执行信号处理程序,进行上下文切换,调用对应程序进行对信号的处理。
内存管理:在加载过程中,虚拟内存系统为hello提供了一套独立的虚拟内存空间。通过MMU可以将虚拟地址转化为物理地址,在保证各个进程互不干扰又“看似独立运行”的背景下完成任务
程序终止:在执行完最后一个函数后,程序退出,子进程终止。等待父进程对其进行回收,至此,hello的一生就此完结。
2.感想:hello是程序员编写出来第一个程序,代码看起来只有短短十来行。但通过学习计算机系统这门课程,我们就能发现简短的代码里大有学问。我从中明白了hello从出生到生命结束居然经历了这么多过程,并大受震憾。预处理、编译、汇编、链接等环节环环相扣,从而衍生出了通用的汇编语言、虚拟内存空间等内容,我敢说计算机系统的构造是人类智慧的结晶。
(结论0分,缺失 -1分,根据内容酌情加分)
附件
| hello.c | hello源代码 |
| hello.i | 预处理之后的文本文件 |
| hello.s | hello的汇编代码 |
| hello_rel.s | hello.o的反汇编代码 |
| hello1.s | hello的反汇编代码 |
| hello | hello的可执行文件 |
| hello.o | hello的可重定位文件 |
| hello.o.elf | hello.o的elf头相关文件 |
| hello.elf | hello的elf头相关文件 |
其中hello1.s、hello.o.elf和hello.elf为终端运行指令时粘贴在.txt文件的代码
(附件0分,缺失 -1分)
参考文献
为完成本次大作业你翻阅的书籍与网站等
[1] 林来兴. 空间控制技术[M]. 北京:中国宇航出版社,1992:25-42.
[2] 辛希孟. 信息技术与信息服务国际研讨会论文集:A集[C]. 北京:中国科学出版社,1999.
[3] 赵耀东. 新时代的工业工程师[M/OL]. 台北:天下文化出版社,1998 [1998-09-26]. http://www.ie.nthu.edu.tw/info/ie.newie.htm(Big5).
[4] 谌颖. 空间交会控制理论与方法研究[D]. 哈尔滨:哈尔滨工业大学,1992:8-13.
[5] KANAMORI H. Shaking Without Quaking[J]. Science,1998,279(5359):2063-2064.
[6] CHRISTINE M. Plant Physiology: Plant Biology in the Genome Era[J/OL]. Science,1998,281:331-332[1998-09-23]. http://www.sciencemag.org/cgi/ collection/anatmorp.
[7] 大卫R.奥哈拉伦,兰德尔E.布莱恩特. 深入理解计算机系统[M]. 机械工业出版社,2016.
(参考文献0分,缺失 -1分)
















 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









