







简介
网络上有很多介绍 jieba 自定义词库的文章。
但基本都是浅显的模仿官方文档,告诉读者使用 jieba.add_word 或者 jieba.load_userdict。
但在实际生产中,需要面对:
1 自定义词典可能会非常大
2 每次重启程序都需要较长时间
3 不知道如何复用词典模型
本文将解决上述问题。
为啥要自建词库
使用默认词库,往往会把特定词语进行分词,而我们希望这些词语完整的出现,不被拆分。
使用自定义词典,将这种词语放到词库模型中,即可避免这种问题。
自建词库的两种方式
jieba.add_word 或者 jieba.load_userdict(使用方法自己查,这里暂且不表。)
坑坑
没错,就是 jieba.load_userdict。
使用这个方法,每次程序重启的时候,都要重新加载,非常耗时。本人测试 400 万条词语时,加载需要 5 分钟左右。
这个加载非常耗时的原因是:该加载自定义词库的过程,是一个单线程的 IO 过程。看源码
def load_userdict(self, f):
'''
Load personalized dict to improve detect rate.
Parameter:
- f : A plain text file contains words and their ocurrences.
Can be a file-like object, or the path of the dictionary file,
whose encoding must be utf-8.
Structure of dict file:
word1 freq1 word_type1
word2 freq2 word_type2
...
Word type may be ignored
'''
self.check_initialized()
if isinstance(f, string_types):
f_name = f
f = open(f, 'rb')
else:
f_name = resolve_filename(f)
for lineno, ln in enumerate(f, 1):
line = ln.strip()
if not isinstance(line, text_type):
try:
line = line.decode('utf-8').lstrip('\ufeff')
except UnicodeDecodeError:
raise ValueError('dictionary file %s must be utf-8' % f_name)
if not line:
continue
# match won't be None because there's at least one character
word, freq, tag = re_userdict.match(line).groups()
if freq is not None:
freq = freq.strip()
if tag is not None:
tag = tag.strip()
self.add_word(word, freq, tag)
如上源码所示,load_userdict 方法,是将自定义词典中的所有词语,循环调用 add_word。这是一个单线程操作,当然慢!因此,建议慎用该方法,并且建议看看下面的进阶玩法。当然,如果不嫌麻烦的话,也可以自己实现一个带并发的 add_word。
进阶玩法(模型复用)
先感谢 菜菜鑫 的文章(本文在此基础上进行延伸)
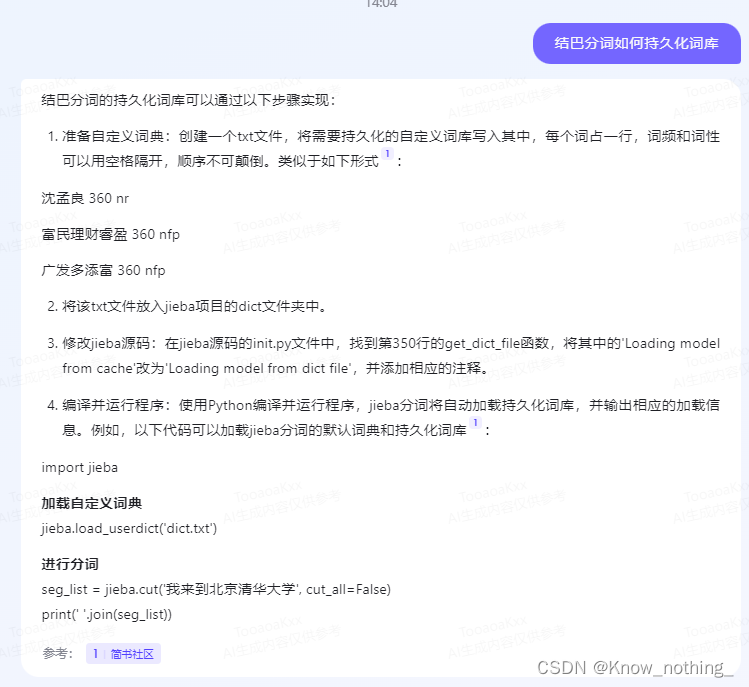
关于模型的相关理解,直接参考 如何使jieba自定义词典持久化 。
下面介绍如何实现。
准备自定义词
准备自定义词库并命名为 dict.txt,过程略。
【注意】该词库每行必须符合要求: 词语 词频 词性,词频和词性两个次不可省略,否则会报错( 不同于使用 add_word 或者 load_userdict )。
@staticmethod
def gen_pfdict(f):
lfreq = {}
ltotal = 0
f_name = resolve_filename(f)
for lineno, line in enumerate(f, 1):
try:
line = line.strip().decode('utf-8')
word, freq = line.split(' ')[:2]
freq = int(freq)
lfreq[word] = freq
ltotal += freq
for ch in xrange(len(word)):
wfrag = word[:ch + 1]
if wfrag not in lfreq:
lfreq[wfrag] = 0
except ValueError:
raise ValueError(
'invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line))
f.close()
return lfreq, ltotal
上述源码第九行,会将词库每一行进行 split 后取值,词频和词性缺失会造成索引越界。如果实在没有词频和词性,可修改源码,改为如下行
word = line.strip().decode('utf-8')
# word, freq = line.split(' ')[:2]
freq = int(9999)
lfreq[word] = freq
ltotal += freq
for ch in xrange(len(word)):
wfrag = word[:ch + 1]
if wfrag not in lfreq:
lfreq[wfrag] = 0
创建模型
新建一个脚本,执行下述代码
【重要】注意和参考资料不一样,本文更加简单直接
import jieba
# 指定词库路径
jieba.set_dictionary('./xxx.txt')
# 模型存放路径
jieba.dt.tmp_dir = './'
# 指定模型名称
jieba.dt.cache_file = 'jieba.temp'
for i in jieba.cut('上海自来水来自海上'):
print(i)
执行上述脚本,jieba 会将自定义的 dict.txt 进行加载,并将创建的模型 jieba.temp 存放到指定位置。
模型复用
在需要使用该词库的程序中,指定上述模型的路径即可。
有了上述模型,便不需要自定义的 dict.txt,可以将上述模型复制到任何机器进行复用。模型和词库的关系,仍参考 如何使jieba自定义词典持久化 。
感谢
感谢文心一言给出的不是非常准确的答案
但是能给出参考资料的网址非常好(https://www.jianshu.com/p/e23fe5d06ea2),找到了解决的方案















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









