







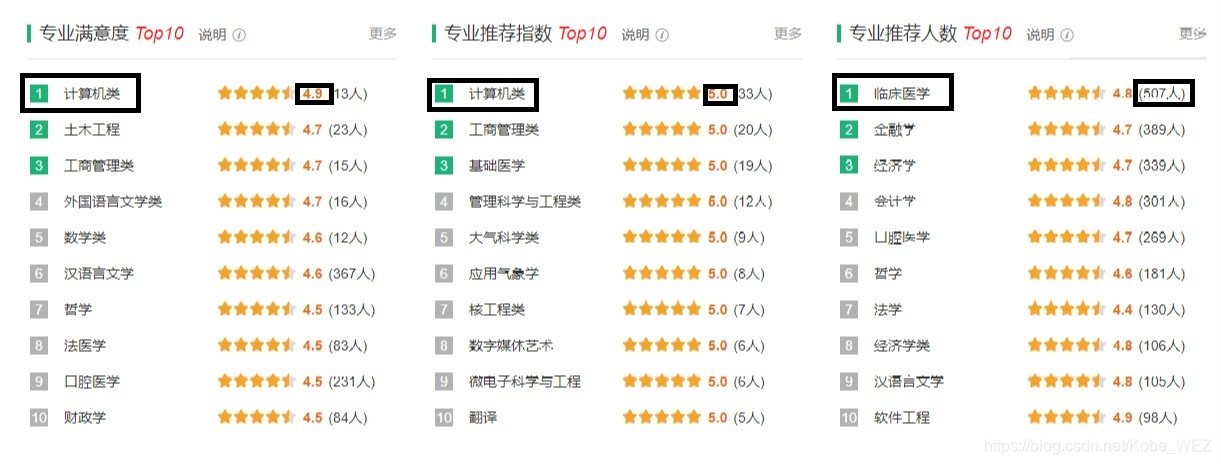
在本次学习中主要爬取的内容如下
就简单粗暴直接献上代码吧
import requests
import time
import json
from bs4 import BeautifulSoup
def get_one_page():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
num1=0
num2=0
num3=0
for n in range(0, 8):
offset = n * 20
url = 'https://gaokao.chsi.com.cn/sch/search.do?searchType=1&ssdm=44&start=0' + str(offset)
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html5lib")
hello = soup.find_all(' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1838
1838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









