






AC 自动机 = \(\text{trie}\) + \(\text{kmp}\) 的思想
AC 自动机
问题:给定 \(n\) 个模式串和一个文本串,问有多少个模式串出现在文本串中
跑 \(n\) 遍 \(\text{kmp}\) ?若数据毒瘤会超时
于是一些珂学家们发明了 AC 自动机
fail
假设模式串分别是 he she her shy say
建出 \(\text{trie}\) 树
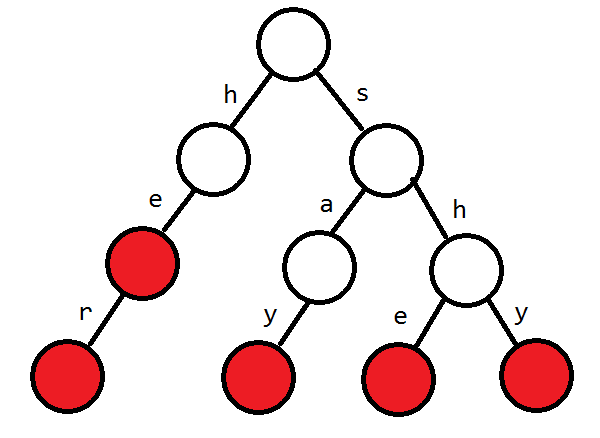
暴力匹配效率不高,考虑用 \(\text{kmp}\) 的 \(next\) 思想,在 \(\text{trie}\) 上建一个 \(fail\)
设当前串 \(S\) 以 \(u\) 结尾,则 \(fail_u\) 指向
能与 \(S\) 后缀匹配的)最长的) \(\text{trie}\) 的前缀所在的)节点
这着实有点绕,可以康康图
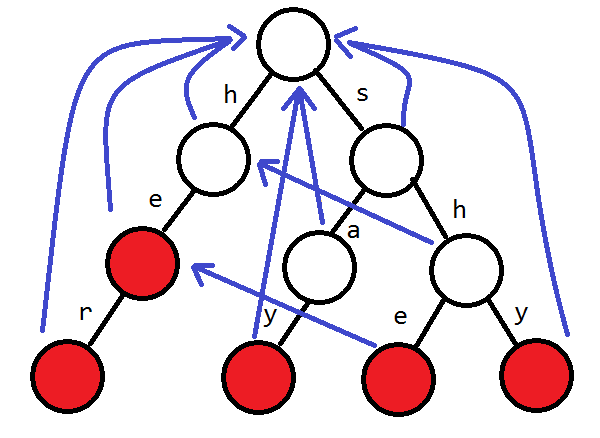
如图,能与 she 的后缀匹配的 \(\text{trie}\) 的前缀,只有 he
如何构建
考虑 bfs ,对于当前点 \(u\) 存在的儿子 \(ch_{u,i}\)
从 \(u\) 开始往上跳 \(fail\),直到一个点 \(v\) 也有 \(ch_{v,i}\) ,那么 \(ch_{u,i}\) 的 \(fail\) 指向 \(ch_{v,i}\)
特别的,如果没有符合条件的 \(v\) ,那么 \(fail\) 指向根
同时第二层的 \(fail\) 都指向跟
inline void gfail() {
for(int i=0;i<26;i++)
if(ch[0][i])q[++tl]=ch[0][i];
register int u;
while(hd<tl) {
u=q[++hd];
for(int i=0,v;i<26;i++) {
if(ch[u][i]) {
v=fail[u];
while(!ch[v][i] && v)v=fail[v];
fail[ch[u][i]]=ch[v][i];
q[++tl]=ch[u][i];
}
}
}
}查询
如何查询文本串 \(s\) 呢
指针 \(u\) 从根开始,将每个字母送入自动机
若不存在 \(ch_{u,c}\) ,则跳 \(fail\) 找到一个存在的 \(ch_{v,c}\)
然后沿着从 \(fail\) 到根的路径统计个数,
注意不要重复
inline int ask(int le) {
register int u=0,ans=0;
for(int i=1,v;i<=le;i++) {
v=s[i]-'a';
while(!ch[u][v] && u)u=fail[u];
u=ch[u][v];
for(int j=u;j && flg[j];j=fail[j])
ans+=flg[j],flg[j]=0;
}
return ans;
}trie 图
发现如果当前节点没有对应的子节点,那么就需要沿着 \(fail\) 向上走,会浪费时间
考虑在建立 \(fail\) 时补全 \(\text{trie}\) 树,形成 \(\text{trie}\) 图
若 \(u\) 不存在儿子 \(i\) ,则将儿子 \(i\) 指向 \(fail_u\) 儿子 \(i\)
否则直接将儿子的 \(fail\) 指向 \(fail_u\) 的儿子 \(i\)
inline void gfail() {
for(int i=0;i<26;i++)
if(ch[0][i])q[++tl]=ch[0][i];
register int u;
while(hd<tl) {
u=q[++hd];
for(int i=0;i<26;i++) {
if(ch[u][i]) {
fail[ch[u][i]]=ch[fail[u]][i];
q[++tl]=ch[u][i];
} else ch[u][i]=ch[fail[u]][i];
}
}
}匹配完后的查询也不需要跳 \(fail\) 了
inline int ask(int le) {
register int u=0,ans=0;
for(int i=1;i<=le;i++) {
u=ch[u][s[i]-'a'];
for(int j=u;j && flg[j];j=fail[j])
ans+=flg[j],flg[j]=0;
}
return ans;
}Code
例:模板
#include<bits/stdc++.h>
using namespace std;
const int N=1000005;
int n,ch[N][26],fail[N],flg[N],tot,hd,tl,q[N];
char s[N];
inline void ins(int le) {
register int u=0;
for(int i=1,v;i<=le;i++) {
v=s[i]-'a';
if(!ch[u][v])ch[u][v]=++tot;
u=ch[u][v];
}
flg[u]++;
}
inline void gfail() {
for(int i=0;i<26;i++)
if(ch[0][i])q[++tl]=ch[0][i];
register int u;
while(hd<tl) {
u=q[++hd];
for(int i=0;i<26;i++) {
if(ch[u][i]) {
fail[ch[u][i]]=ch[fail[u]][i];
q[++tl]=ch[u][i];
} else ch[u][i]=ch[fail[u]][i];
}
}
}
inline int ask(int le) {
register int u=0,ans=0;
for(int i=1;i<=le;i++) {
u=ch[u][s[i]-'a'];
for(int j=u;j && flg[j];j=fail[j])
ans+=flg[j],flg[j]=0;
}
return ans;
}
int main() {
scanf("%d",&n);
for(int i=1;i<=n;i++) {
scanf("%s",s+1);
ins(strlen(s+1));
}
gfail();
scanf("%s",s+1);
printf("%d",ask(strlen(s+1)));
}例:查询出现个数,一样的题
#include<bits/stdc++.h>
using namespace std;
const int N=1000005;
int n,ch[N][26],mx,ans[N],fail[N],flg[N],tot,hd,tl,q[N];
char s[N],st[200][200];
inline void ins(int le,int id) {
register int u=0;
for(int i=1,v;i<=le;i++) {
v=st[id][i]-'a';
if(!ch[u][v])ch[u][v]=++tot;
u=ch[u][v];
}
flg[u]=id;
}
inline void gfail() {
for(int i=0;i<26;i++)
if(ch[0][i])q[++tl]=ch[0][i];
register int u;
while(hd<tl) {
u=q[++hd];
for(int i=0;i<26;i++) {
if(ch[u][i]) {
fail[ch[u][i]]=ch[fail[u]][i];
q[++tl]=ch[u][i];
} else ch[u][i]=ch[fail[u]][i];
}
}
}
inline void ask(int le) {
register int u=0;
for(int i=1;i<=le;i++) {
u=ch[u][s[i]-'a'];
for(int j=u;j;j=fail[j])
ans[flg[j]]++;
}
}
int main() {
scanf("%d",&n);
while(n) {
memset(ch,0,sizeof(ch));
memset(flg,0,sizeof(flg));
memset(ans,0,sizeof(ans));
for(int i=1;i<=n;i++) {
scanf("%s",st[i]+1);
ins(strlen(st[i]+1),i);
}
gfail();
scanf("%s",s+1);
ask(strlen(s+1));
mx=0;
for(int i=1;i<=n;i++)mx=max(mx,ans[i]);
printf("%d\n",mx);
for(int i=1;i<=n;i++)
if(ans[i]==mx)printf("%s\n",st[i]+1);
scanf("%d",&n);
}
}Fail 树
用途:统计模式串出现的个数
和加强版很想?可是暴力跳巨慢?
想想匹配的过程,从头开始跳 \(fail\) ,期间到的每个点都是一个出现的串
既然可以一个一个顺着跳,同理从模式串结尾往上跳到的节点个数就是该串出现的次数
于是可以只留下反着的 \(fail\) 边,形成 \(fail\) 树
只要将属于文本串的节点标为 1 ,那么节点 \(u\) 的子树和就是 \(u\) 出现的次数
子树和可以用 \(\text{dfs}\) 序+树状数组,复杂度下降许多
例:同上















 6905
6905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









