






RAG由来
在实际应用中我们存在以下几条问题:
-
知识局限性:大模型的知识来源于训练数据,而这些数据主要来自于互联网上已经公开的资源,对于一些实时性的或者非公开的,由于大模型没有获取到相关数据,这部分知识也就无法被掌握。
-
数据安全性:为了使得大模型能够具备相应的知识,就需要将数据纳入到训练集进行训练。然而,对于企业来说,数据的安全性至关重要,任何形式的数据泄露都可能对企业构成致命的威胁。
-
大模型幻觉:由于大模型是基于概率统计进行构建的,其输出本质上是一系列数值运算。因此,有时会出现模型“一本正经地胡说八道”的情况,尤其是在大模型不具备的知识或不擅长的场景中。
为了上述这些问题,研究人员提出了检索增强生成(Retrieval Augmented Generation, RAG)的方法。这种方法通过引入外部知识,使大模型能够生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。
由于RAG简单有效,它已经成为主流的大模型应用方案之一。
RAG结构及原理
1.结构图

-
索引:将文档库分割成较短的 Chunk,即文本块或文档片段,然后构建成向量索引。
-
检索:计算问题和 Chunks 的相似度,检索出若干个相关的 Chunk。
-
生成:将检索到的Chunks作为背景信息,生成问题的回答。

从上图可以看到,线上接收到用户query后,RAG会先进行检索,然后将检索到的 Chunks 和 query 一并输入到大模型,进而回答用户的问题。
为了完成检索,需要离线将文档(ppt、word、pdf等)经过解析、切割甚至OCR转写,然后进行向量化存入数据库中。
2.离线计算
首先,知识库中包含了多种类型的文件,如pdf、word、ppt等,这些 文档(Documents)需要提前被解析,然后切割成若干个较短的 Chunk,并且进行清洗和去重。
由于知识库中知识的数量和质量决定了RAG的效果,因此这是非常关键且必不可少的环节。
然后,我们会将知识库中的所有 Chunk 都转成向量,这一步也称为 向量化(Vectorization)或者 索引(Indexing)。
向量化 需要事先构建一个 向量模型(Embedding Model),它的作用就是将一段 Chunk 转成 向量(Embedding)。如下图所示:

一个好的向量模型,会使得具有相同语义的文本的向量表示在语义空间中的距离会比较近,而语义不同的文本在语义空间中的距离会比较远。

由于知识库中的所有 Chunk 都需要进行 向量化,这会使得计算量非常大,因此这一过程通常是离线完成的。
随着新知识的不断存储,向量的数量也会不断增加。这就需要将这些向量存储到 数据库 (DataBase)中进行管理,例如 Milvus 中。
至此,离线计算就完成了。
3.在线计算
在实际使用RAG系统时,当给定一条用户 查询(Query),需要先从知识库中找到所需的知识,这一步称为 检索(Retrieval)。
在 检索 过程中,用户查询首先会经过向量模型得到相应的向量,然后与 数据库 中所有 Chunk 的向量计算相似度,最简单的例如 余弦相似度,然后得到最相近的一系列 Chunk 。
由于向量相似度的计算过程需要一定的时间,尤其是 数据库 非常大的时候。
这时,可以在检索之前进行 召回(Recall),即从 数据库 中快速获得大量大概率相关的 Chunk,然后只有这些 Chunk 会参与计算向量相似度。这样,计算的复杂度就从整个知识库降到了非常低。
召回 步骤不要求非常高的准确性,因此通常采用简单的基于字符串的匹配算法。由于这些算法不需要任何模型,速度会非常快,常用的算法有 TF-IDF,BM25 等。
另外,也有很多工作致力于实现更快的 向量检索 ,例如 faiss,annoy。
另一方面,人们发现,随着知识库的增大,除了检索的速度变慢外,检索的效果也会出现退化,如下图中绿线所示:

这是由于 向量模型 能力有限,而随着知识库的增大,已经超出了其容量,因此准确性就会下降。在这种情况下,相似度最高的结果可能并不是最优的。
为了解决这一问题,提升RAG效果,研究者提出增加一个二阶段检索——重排 (Rerank),即利用 重排模型(Reranker),使得越相似的结果排名更靠前。这样就能实现准确率稳定增长,即数据越多,效果越好(如上图中紫线所示)。
通常,为了与 重排 进行区分,一阶段检索有时也被称为 精排 。而在一些更复杂的系统中,在 召回 和 精排 之间还会添加一个 粗排 步骤,这里不再展开,感兴趣的同学可以自行搜索。
综上所述,在整个 检索 过程中,计算量的顺序是 召回 > 精排 > 重排,而检索效果的顺序则是 召回 < 精排 < 重排 。
当这一复杂的 检索 过程完成后,我们就会得到排好序的一系列 检索文档(Retrieval Documents)。
然后我们会从其中挑选最相似的 k 个结果,将它们和用户查询拼接成prompt的形式,输入到大模型。
最后,大型模型就能够依据所提供的知识来生成回复,从而更有效地解答用户的问题。
至此,一个完整的RAG链路就构建完毕了。
开源RAG框架
目前,开源社区中已经涌现出了众多RAG框架,例如:
-
TinyRAG:DataWhale成员宋志学精心打造的纯手工搭建RAG框架。
-
LlamaIndex:一个用于构建大语言模型应用程序的数据框架,包括数据摄取、数据索引和查询引擎等功能。
-
LangChain:一个专为开发大语言模型应用程序而设计的框架,提供了构建所需的模块和工具。
-
QAnything:网易有道开发的本地知识库问答系统,支持任意格式文件或数据库。
-
RAGFlow:InfiniFlow开发的基于深度文档理解的RAG引擎。
这些开源项目各具优势,功能丰富,极大的推动了RAG技术的发展。
然而,随着这些框架功能的不断扩展,学习者不可避免地需要承担较高的学习成本。
因此,本节课将以 Yuan2-2B-Mars 模型为基础,进行RAG实战。希望通过构建一个简化版的RAG系统,来帮助大家掌握RAG的核心技术,从而进一步了解一个完整的RAG链路。
1. 知识库索引:如何切分知识库效果最好?哪个向量模型更适配?
索引切分:
- 主题或领域切分:将知识库按照主题或领域进行切分,可以提高检索的相关性和效率。例如,分成技术、历史、文化等大类。
- 文档长度切分:将文档按照长度进行切分,有助于提高检索的精确度。较长的文档可以根据自然段落或逻辑结构切分成较小的片段。
- 概念切分:将信息按概念或要点切分,可以使检索结果更具针对性。例如,将每个知识点独立成条目。
向量模型:
- Word2Vec:对单词的语义进行建模,但在处理大规模文本时可能会出现精度问题。
- GloVe:通过全局词频信息捕捉语义,比Word2Vec在一些任务中表现更好。
- BERT/GPT:对于处理复杂的文本和上下文关系效果更佳,特别是在需要深入理解和生成的任务中表现突出。
- Sentence Transformers:专为生成句子级别的向量而设计,适合用于语义搜索和相似度计算。
对于大规模知识库,BERT或其变体(如RoBERTa、DistilBERT)以及Sentence Transformers通常表现较好,因为它们能够理解更复杂的上下文关系并生成高质量的向量表示。
2. 检索:大知识库的检索工具
工具与技术:
- Elasticsearch:分布式搜索引擎,适用于大规模数据的全文检索,支持快速的查询和高效的索引。
- Solr:开源搜索平台,支持强大的全文搜索功能和灵活的查询方式。
- FAISS:由Facebook开发的库,专门用于高效的相似度搜索,适合大规模向量数据。
- Pinecone:用于向量搜索的云原生平台,支持高效的向量检索。
- Annoy:由Spotify开发的近似最近邻搜索库,适用于高维空间中的相似度搜索。
这些工具可以帮助你在大规模数据中进行高效的检索,具体选择取决于你的需求和使用场景。
3. 生成:如何利用检索出的内容?如何调优prompt?
利用检索内容:
- 提取信息:从检索结果中提取关键信息,并根据这些信息生成回答或文本。
- 上下文填充:使用检索到的内容作为上下文信息,增强生成模型的回答准确性。
- 补充细节:根据检索结果补充详细信息,使生成的内容更全面和准确。
Prompt调优:
- 明确问题:确保prompt明确地描述了任务或问题,使模型能够理解要生成的内容。
- 上下文提供:在prompt中包含足够的上下文信息,这可以帮助模型更好地理解和回答问题。
- 逐步细化:通过实验逐步调整prompt,增加或减少细节,观察生成结果的变化,找到最佳效果。
- 示例驱动:提供示例或模板来引导生成模型,使其更好地遵循所需的格式和风格。
有效的prompt调优涉及多次实验和调整,确保模型能够根据具体需求生成高质量的内容。
知识库:

运行结果:

微调
模型微调也被称为指令微调(Instruction Tuning)或者有监督微调(Supervised Fine-tuning, SFT),该方法利用成对的任务输入与预期输出数据,训练模型学会以问答的形式解答问题,从而解锁其任务解决潜能。经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习的方式解决多种下游任务。
然而,值得注意的是,指令微调并非无中生有地传授新知,而是更多地扮演着催化剂的角色,激活模型内在的潜在能力,而非单纯地灌输信息。
相较于预训练所需的海量数据,指令微调所需数据量显著减少,从几十万到上百万条不等的数据,均可有效激发模型的通用任务解决能力,甚至有研究表明,少量高质量的指令数据(数千至数万条)亦能实现令人满意的微调效果。这不仅降低了对计算资源的依赖,也提升了微调的灵活性与效率。
轻量化微调
然而,由于大模型的参数量巨大, 进行全量参数微调需要消耗非常多的算力。为了解决这一问题,研究者提出了参数高效微调(Parameter-efficient Fine-tuning),也称为轻量化微调 (Lightweight Fine-tuning),这些方法通过训练极少的模型参数,同时保证微调后的模型表现可以与全量微调相媲美。
常用的轻量化微调技术有LoRA、Adapter 和 Prompt Tuning。
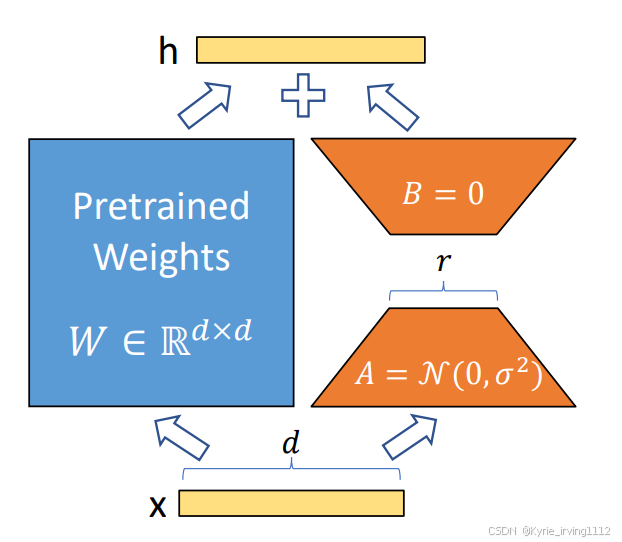
LoRA技术简介
LoRA 是通过低秩矩阵分解,在原始矩阵的基础上增加一个旁路矩阵,然后只更新旁路矩阵的参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









