









摘要
弱监督视频异常检测(WSVAD)是一个具有挑战性的课题。目前,基于弱标签生成细粒度伪标签,然后对分类器进行自训练是一种很有前途的解决方案。然而,由于现有方法仅使用RGB视觉模态,忽略了对类别文本信息的利用,从而限制了伪标签更准确的生成,影响了自训练的性能。受基于事件描述的人工标注过程的启发,本文提出了一种基于文本提示与正常性引导(TPWNG)的WSVAD伪标签生成与自训练框架。我们的想法是利用对比语言图像预训练(CLIP)模型丰富的语言视觉知识,对视频事件描述文本和相应的视频帧进行对齐,生成伪标签。具体来说,我们首先通过设计两个排名损失和一个分布不一致损失来微调CLIP的领域自适应。在此基础上,提出了一种可学习的文本提示机制,并辅以正常性视觉提示,进一步提高视频事件描述文本与视频帧的匹配精度。然后,我们设计了一个基于正态性指导的伪标签生成模块来推断可靠的帧级伪标签。最后,我们引入了一个时间上下文自适应学习模块,以更灵活、准确地学习不同视频事件的时间依赖性。大量的实验表明,我们的方法在两个基准数据集(UCF-Crime和XD-Violence)上达到了最先进的性能,证明了我们提出的方法的有效性。
引言
异常检测在计算机视觉[23,35,40,43,49]、自然语言处理[1]、智能优化[29]等多个领域得到了广泛的研究和应用。视频异常检测(VAD)是其中一个重要的研究课题。VAD的主要目的是自动识别视频中与我们期望不一致的事件或行为。
由于异常事件的罕见性帧级标注的难度,目前的VAD方法主要集中在半监督[14,16,18]和弱监督[11,26,52]范式上。半监督VAD方法旨在从正常数据中学习正常模式,偏离该模式被视为异常。然而,由于在训练阶段缺乏判别异常信息,这些模型往往容易出现过拟合,导致在复杂场景下的性能不佳。随后,弱监督视频异常检测(WSVAD)方法开始崭露头角。WSVAD在训练阶段包括正常视频和异常视频,并带有视频级标签,但异常帧的确切位置未知。目前的WSVAD方法主要有基于多实例学习(MIL)的一阶段方法[17,26,27]和基于伪标签自训练的两阶段方法[6,11,51,53]。虽然基于MIL的单阶段方法显示出令人满意的结果,但该范式倾向于关注具有突出异常特征的视频片段,而对次要异常的关注不够理想,从而限制了其进一步的性能提高。
与上述单阶段方法相比,基于伪标签自训练的两阶段方法一般使用现成的分类器或MIL获得初始伪标签,然后使用进一步细化的伪标签训练分类器。由于这些方法直接使用生成的细粒度伪标签训练分类器,因此它们在性能上显示出很大的潜力。然而,这些方法仍有两个方面没有考虑到:第一,伪标签的生成仅基于视觉模态,缺乏对文本模态的利用,这限制了生成伪标签的准确性和完整性。其次,挖掘视频帧之间的时间依赖性是不够的。
为了进一步挖掘基于伪标签的WSVAD自训练的潜力,本文致力于研究上述两个问题。我们提出第一个问题的动机是探索如何有效地利用文本模态信息来帮助生成伪标签。回顾我们手工标记视频帧的过程,我们主要基于异常事件的文本定义,即异常事件的先验知识,来准确定位视频帧。如图1所示,假设我们需要标注包含“战斗”事件的异常视频帧,我们首先关联“战斗”的文本定义,然后寻找匹配的视频帧,这实际上是一个基于先验知识的文本图像匹配过程。受这个过程的启发,我们联想到一个非常流行和强大的对比语言图像预训练(CLIP)模型来帮助我们实现这一目标。一方面,CLIP学习了网络上大量的图像-文本对,因此具有非常丰富的先验知识;另一方面,CLIP通过对比学习进行训练,这使其具有出色的图像-文本对齐能力。对于第二个动机,由于不同的视频事件具有不同的持续时间,这导致了不同的时间依赖性范围。现有的方法要么不考虑时间依赖性,要么只考虑固定时间范围内的依赖性,从而导致对时间依赖性的不充分建模。因此,为了实现更灵活和充分的时间依赖关系建模,我们应该研究能够自适应学习不同长度的时间依赖关系的方法。

基于以上两个动机,我们提出了一种新的基于文本提示与正常性引导(TPWNG)的WSVAD伪标签生成和自训练框架。我们的主要思想是利用CLIP模型将视频事件的文本描述与相应的视频帧进行匹配,然后从匹配相似度中推断出伪标签。然而,由于CLIP模型是在图像-文本级别进行训练的,因此它可能会受到域偏差的影响,并且缺乏学习视频中时间依赖性的能力。为了更好地将CLIP的先验知识转移到WSVAD任务中,我们首先构建了一个对比学习框架,通过设计两个排序损失和一个分布不一致损失对CLIP模型进行微调,使其在弱监督设置下进行领域自适应。为了进一步提高视频事件描述文本与视频帧对齐的准确性,我们采用可学习的文本提示来促进CLIP的文本编码器生成更广义的文本嵌入特征。在此基础上,我们提出了一种正常视觉提示(NVP)机制来帮助这一过程。此外,由于异常视频中也包含正常视频帧,我们设计了基于正常引导的伪标签生成(PLG)模块,可以减少个别正常视频帧对异常视频帧对齐的干扰,从而便于获得更准确的帧级标签。
此外,为了弥补CLIP中时间关系建模的不足,以及更灵活和充分地挖掘视频帧之间的时间依赖性,我们引入了一个时间上下文自适应学习(TCSAL)模块,用于时间依赖性建模,灵感来自工作[25]。TCSAL通过设计时间跨度自适应学习机制,使Transformer中的注意力模块能够根据输入自适应地调整注意广度。这有助于模型更准确、灵活地捕捉不同持续时间的视频事件的时间依赖性。
总的来说,我们的主要贡献总结如下:
-
我们提出了一种新的框架,即TPWNG,来对WSVAD进行伪标签生成和自训练。TPWNG利用设计的排名损失和分布不一致损失对CLIP进行微调,将其强大的文本-图像对齐能力转移到通过PLG模块辅助伪标签生成。
-
为了进一步提高视频事件描述文本和视频帧的对齐精度,我们设计了一种可学习的文本提示和常态正常视觉提示机制。
-
为了更灵活、准确地学习不同视频事件的时间依赖性,我们引入了TCSAL模块。据我们所知,我们是第一个为VAD引入时间上下文依赖的自适应学习思想的人。
-
在UCF-Crime和XD-Violence两个基准数据集上进行了大量的实验,实验结果表明我们的方法是有效的。
相关工作
1、视频异常检测
VAD任务得到了广泛的关注和研究,并提出了许多方法来解决这一问题。根据不同的监督模式,这些方法主要分为半监督型和弱监督型VAD。
Semi-supervised VAD
早期研究者主要采用半监督方法解决VAD问题[2,7,8,10,14,15,20,24,31,33,41 - 44,46,50]。在半监督设置中,训练阶段只能获取正常数据,目的是通过学习正常数据来建立一个能够表征正常行为模式的模型。在测试阶段,与正常模式相矛盾的数据被视为异常。常见的半监督VAD方法主要有基于单类分类器的方法[21,33,37]和基于重构[8,38]或基于预测误差的方法[14,42]。例如,Xu等人使用多个单分类器来预测基于外观和运动特征的异常分数。Hasan et al.[8]构建了一个全卷积自编码器来学习视频中的规则模式。Liu等人在[14]中提出了一种新的视频异常检测方法,该方法利用U-Net架构预测未来的帧,其中预测误差较大的帧被认为是异常的。
weakly Supervised VAD
与半监督VAD方法相比,WSVAD可以在训练阶段利用带有视频级标签的正常和异常数据,但异常事件发生的确切帧位置是未知的。在这种情况下,基于MIL的一阶段方法[3-5,13,17,22,26,27,32,34,45,54]和基于伪标签自训练的两阶段方法[6,11,51,53]是两种主流方法。例如,Sultani等人[26]首次提出了VAD的深度MIL排序框架,他们将异常视频和正常视频分别视为正包和负包,并将视频中的片段视为实例。然后使用排序损失来约束正负包中异常得分最高的片段,使其相互远离。后来,在此基础上提出了许多不同的方法。例如,Tian等人提出了一种基于top-k MIL的具有鲁棒时间特征大小学习的VAD方法。
然而,这些单阶段方法通常使用MIL框架,这导致模型倾向于只关注最重要的异常片段,而忽略不重要的异常片段。基于伪标签自我训练的两阶段方法提供了一个相对更有希望的解决方案。两阶段方法首先使用MIL或现成的分类器生成初始伪标签,然后在将标签用于分类器的监督训练之前对其进行细化。例如,Zhong等人在[53]中将WSVAD问题重新表述为由现成的视频分类器获得的噪声标签下的监督学习任务。Feng等人在[6]中介绍了一个多实例伪标签生成器,该生成器产生更可靠的伪标签,用于微调具有自训练机制的特定任务特征编码器。Zhang等人在[51]中利用完备性和不确定性来增强伪标签以进行有效的自我训练。然而,现有的方法都是基于视觉单模态信息生成伪标签,缺乏对文本模态的利用。因此,在本文中,我们努力将视觉和文本模态信息结合起来,以生成更准确、更完整的伪标签,用于分类器的自训练。
2、Large Vision-Language Models
最近,出现了一些大型视觉语言模型,这些模型通过对大规模数据集的预训练来学习视觉和文本模式之间的相互联系。在这些方法中,CLIP在许多视觉语言下游任务中表现出前所未有的性能,如图像分类[55]、目标检测[56]、语义分割[12]等。CLIP模型最近也被成功地扩展到视频领域。VideoCLIP[39]通过对比时间重叠的视频文本对和挖掘的硬否定来对齐视频和文本表示。ActionCLIP[30]将动作识别任务制定为一个多模态学习问题,而不是传统的单模态分类任务。然而,很少有人尝试利用CLIP模型来解决VAD任务。Joo等人在[9]中只是利用CLIP的图像编码器来提取更具判别性的视觉特征,而没有使用文本信息。Wu等人[36],Zanella等人[48]主要利用CLIP中的文本特征增强整体特征的表达能力,其次是基于mil的异常分类器学习。与上述工作的主要区别在于,我们的方法首先利用CLIP文本编码器编码的文本特征与视觉特征结合来生成伪标签,然后采用监督方法来训练异常分类器。
方法
1、Overall Architecture
形式上,我们首先定义集合 D a = { ( v i a , y i ) } i = 1 M D^a=\{(v_i^a,y_i)\}_{i=1}^M Da={(via,yi)}i=1M和 D n = { ( v i n , y i ) } i = 1 M D^{n}=\{(v_{i}^{n},y_{i})\}_{i=1}^{M} Dn={(vin,yi)}i=1M,分别包含 M M M个带有真值标签的异常视频和正常视频。对于每个 v i a v_i^a via,将其标记为 y i = 1 y_i=1 yi=1,表示该视频至少包含一个异常视频帧,但异常帧的确切位置未知。对于每个 v i n v_i^n vin,它被标记为 y i = 0 y_i=0 yi=0,表示该视频完全由0正常帧组成。有了这个设置,WSVAD的任务是利用粗粒度的视频级标签,使分类器能够学习预测细粒度的帧级异常分数。
图2说明了我们的方法的整个流程。CLIP的图像编码器和文本编码器分别将正常视频和异常视频以及可学习的类别提示文本编码为特征嵌入。然后,通过对CLIP的文本编码器进行微调,以产生准确匹配异常或正常视频帧的视频事件类别的文本特征嵌入,NVP在此过程中提供帮助。同时,图像特征馈送TCSAL模块进行时间依赖性的自适应学习。最后,在PLG模块获得的伪标签的监督下,训练视频帧分类器来预测异常分数。
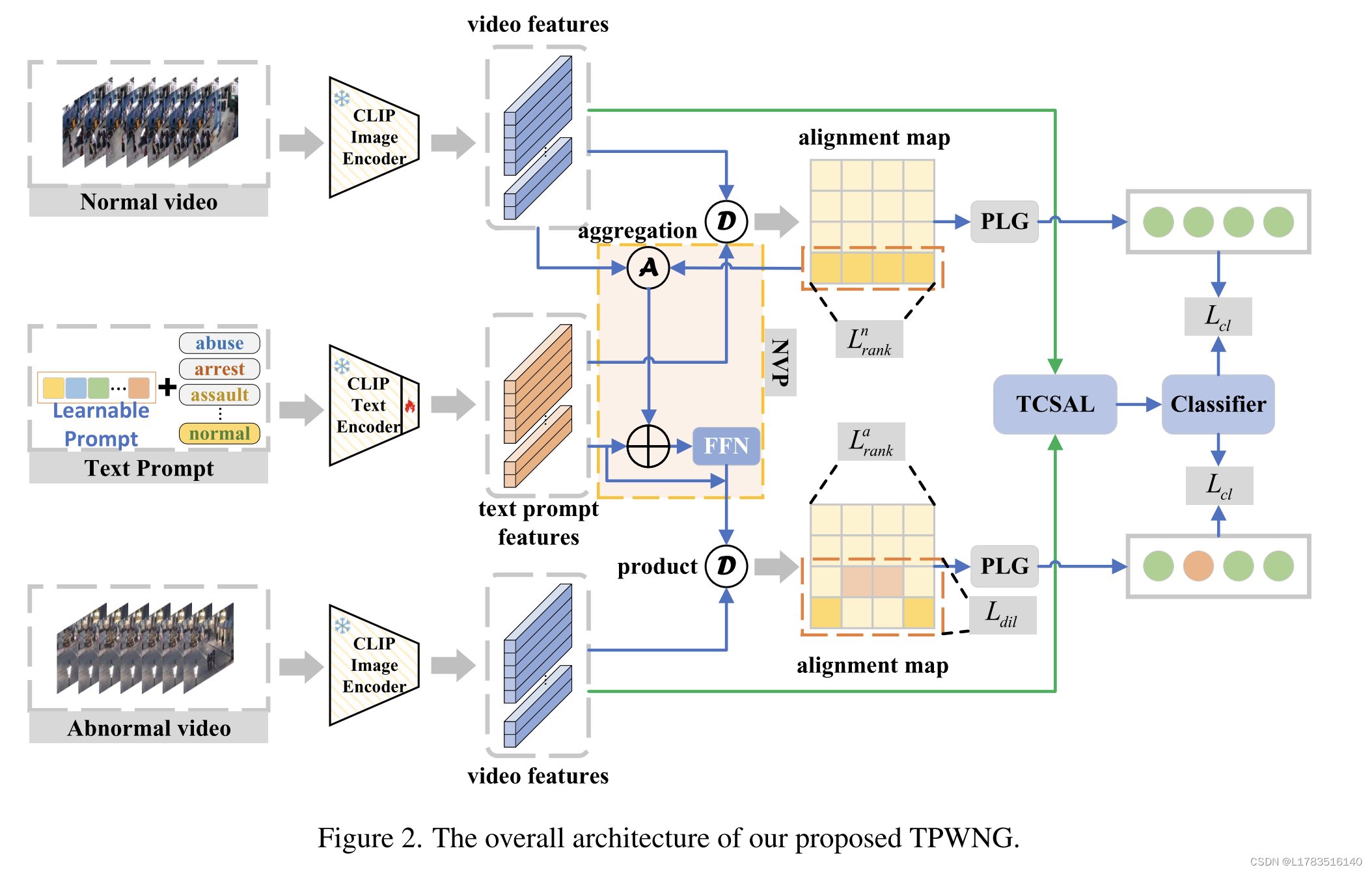
2、Text and Normality Visual Prompt
Learnable Text Prompt
构建能够准确描述各种视频事件类别的文本提示是实现文本与相应视频帧对齐的前提。然而,手动定义能够在所有不同场景中完全描述异常事件的描述文本是不切实际的。因此,受CoOp[55]的启发,我们采用可学习的文本提示机制,自适应学习具有代表性的视频事件文本提示,以对齐相应的视频帧。具体而言,我们构建了一个可学习的提示模板,该模板在标记化的类别名称前面添加了 l l l个可学习的提示向量,如下所示:
p l a b e l = ( ∂ 1 , . . . , ∂ l , T o k e n i z e r ( l a b e l ) ) , ( 1 ) p_{label}=(\partial_1,...,\partial_l,Tokenizer(label)),\quad(1) plabel=(∂1,...,∂l,Tokenizer(label)),(1)
∂ l \partial_{l} ∂l表示第 l l l个提示向量。Tokenizer正在转换原始类别标签,即“fighting”,“accident”,…, " normal "等,通过CLIP tokenizer转换为class tokens。然后,我们将相应的位置信息pos添加到可学习的提示符中,再将其输入到CLIP文本编码器 ζ t e x t \zeta_{text} ζtext中,得到视频事件描述文本的特征嵌入 T l a b e l ∈ R D T_{label}\in\mathbb{R}^D Tlabel∈RD,如下所示:
T l a b e l = ζ t e x t ( p l a b e l ⊕ p o s ) , T_{label}=\zeta_{text}(p_{label}\oplus{pos}), Tlabel=ζtext(plabel⊕pos), (2)
最后,根据式(1)和式(2)计算所有视频事件类别。得到视频事件描述文本嵌入集 E = { T 1 a , T 2 a , . . . , T k − 1 a , T k n } \begin{aligned}E~=~\{T_1^a,~T_2^a,~...,~T_{k-1}^a,~T_k^n\}\end{aligned} E = {T1a, T2a, ..., Tk−1a, Tkn},其中 { T i a } i = 1 k − 1 \{T_i^a\}_{i=1}^{k-1} {Tia}i=1k−1表示前k−1个异常事件的描述文本嵌入, T k n T_k^n Tkn表示正常事件的描述文本嵌入。
Normality Visual Prompt
对于包含异常帧和正常帧的异常视频,我们的核心任务是从异常事件描述文本与视频帧之间的匹配相似度中推断伪标签。然而,该过程容易受到异常视频中正常帧的干扰,因为它们与异常帧具有相似的背景。为了减少这种干扰,我们提出了一种NVP机制。NVP用于帮助正常事件描述文本更准确地对齐异常视频中的正常帧,从而通过分布不一致性损失间接帮助异常事件描述文本对齐异常视频中的异常视频帧,这将在第3.5节中介绍。具体来说,我们首先计算正常事件的描述文本嵌入与正常视频中的视频帧特征之间的匹配相似度 S i , k n n ∈ R F S_{i,k}^{nn}\in\mathbb{R}^{F} Si,knn∈RF。然后,将softmax运算后的匹配相似度作为权重,对正常视频帧特征进行加权,得到 NVP Q i ∈ R D \text{NVP }Q_i\in\mathbb{R}^D NVP Qi∈RD,公式表示如下:
S i , k n n = X i n ( T k n ) ⊤ , Q i = s o f t m a x ( ( S i , k n n ) ⊤ ) X i n , ( 3 ) S_{i,k}^{nn}=X_i^n(T_k^n)^\top,Q_i=softmax((S_{i,k}^{nn})^\top)X_i^n,\quad(3) Si,knn=Xin(Tkn)⊤,Qi=softmax((Si,knn)⊤)Xin,(3)
式中, X i n ∈ R F × D X_{i}^{n}\in\mathbb{R}^{F\times D} Xin∈RF×D为CLIP图像编码器获得的正常视频 v i n v_i^n vin的视觉特征,其中 F F F为视频帧数, D D D为特征维度。然后,我们在特征维度中将 Q i Q_i Qi和 T K n T_K^n TKn拼接起来,并输入一个具有跳跃连接的FFN层,以获得增强的正常事件描述的文本嵌入 T ˙ k n \dot{T}_k^n T˙kn。公式表示为:
T ˙ k n = F F N ( ( T k n ∪ Q i ) ) + T k n . \dot{T}_k^n=FFN((T_k^n\cup Q_i))+T_k^n. T˙kn=FFN((Tkn∪Qi))+Tkn.(4)
3、Pseudo Label Generation Module
在本小节中,我们将详细介绍如何生成帧级伪标签。对于正常视频,我们可以直接得到帧级伪标签,即对于包含 F F F个正常帧的 v i n = { I j } j = 1 F v_i^n=\{I_j\}_{j=1}^F vin={Ij}j=1F,它对应于一个标签集 { γ i , j n = 0 } j = 1 F \{\gamma_{i,j}^{n}=0\}_{j=1}^{F} {γi,jn=0}j=1F。我们的主要目标是推断包含异常帧和正常帧的异常视频的伪标签。为此,我们提出了一个基于正常性引导的PLG模块来推断准确的伪标签。PLG模块通过将正常事件描述文本与异常视频的匹配相似度作为引导,纳入相应异常事件描述文本与异常视频的匹配相似度中,推断出帧级伪标签。
具体来说,我们首先计算NVP增强的正常事件描述文本嵌入与异常视频特征之间的匹配相似度 S i , k a n = X i a ( T ˙ k n ) ⊤ S_{i,k}^{an}=X_i^a(\dot{T}_k^n)^\top Si,kan=Xia(T˙kn)⊤,其中 X i a ∈ R F × D X_{i}^{a}\in\mathbb{R}^{F\times D} Xia∈RF×D表示CLIP图像编码器获得的异常视频 v i a v_i^a via的视觉特征。同样,我们计算相应的 τ − t h ( 1 ⩽ τ ⩽ k − 1 ) \tau\mathrm{-th~}(1\leqslant\tau\leqslant k-1) τ−th (1⩽τ⩽k−1)真实异常类别的描述文本嵌入 T τ a T_{\tau}^{a} Tτa与异常视频特征 X i a X_i^{a} Xia之间的匹配相似度 S i , τ a a = X i a ( T τ a ) ⊤ S_{i,\tau}^{aa}=X_i^a(T_\tau^a)^\top Si,τaa=Xia(Tτa)⊤。
理论上,对于 S i , τ a a S_{i,\tau}^{aa} Si,τaa,它对应异常帧的匹配相似度应该很高,对应正常帧的匹配相似度应该很低。但它可能会受到来自具有相同背景的同一视频的正常帧的干扰。为了减少正常帧的干扰,我们将具有一定权重的正常事件描述文本对应的匹配相似度作为引导,纳入到对应的真实异常事件描述文本的匹配相似度中,从而推断出伪标签。具体来说,我们首先对 S i , τ a a S_{i,\tau}^{aa} Si,τaa和 S i , k a n S_{i,k}^{an} Si,kan进行归一化和融合操作,如下所示:
ψ i = α S ~ i , k a n + ( 1 − α ) ( 1 − S ~ i , τ a a ) , \psi_i=\alpha\tilde{S}_{i,k}^{an}+(1-\alpha)(1-\tilde{S}_{i,\tau}^{aa}), ψi=αS~i,kan+(1−α)(1−S~i,τaa),(5)
其中, ∗ ~ \tilde{*} ∗~表示归一化操作,α表示引导权重。在得到 ψ i \psi_{i} ψi之后,我们同样对其进行归一化运算得到 ψ ~ i \tilde{\psi}_{i} ψ~i。然后,我们在 ψ ~ i \tilde{\psi}_{i} ψ~i上设置阈值 θ \theta θ得到异常视频的帧级伪标签。如下所示:
γ i , j a = { 1 , ψ ~ i , j ≥ θ ; 0 , ψ ~ i , j < θ , i = 1 , 2 , . . . , M ; j = 1 , 2 , . . . , F ( 6 ) \left.\gamma_{i,j}^a=\left\{\begin{array}{c}1,\tilde{\psi}_{i,j}\geq\theta;\\0,\tilde{\psi}_{i,j}<\theta,\end{array}\right.\right.i=1,2,...,M;j=1,2,...,F\quad(6) γi,ja={1,ψ~i,j≥θ;0,ψ~i,j<θ,i=1,2,...,M;j=1,2,...,F(6)
式中, γ i , j a \gamma_{i,j}^a γi,ja表示第 i i i个异常视频第 j j j帧的伪标签。最后,我们将正常视频和异常视频的帧级伪标签 γ i , j n \gamma_{i,j}^{n} γi,jn和 γ i , j a \gamma_{i,j}^{a} γi,ja结合起来,得到总的伪标签集 { γ i , j } j = 1 F \{\gamma_{i,j}\}_{j=1}^F {γi,j}j=1F。
4、Temporal Context Self-adaptive Learning
为了根据输入的视频数据自适应调整时间关系的学习范围,受[25]工作的启发,我们引入了TCSAL模块。TCSAL的主干是Transformer-encoder,但与原始Transformer不同的是,注意力的跨越范围由每层每个自注意头的软掩码函数 χ z \chi_{z} χz控制。 χ z \chi_{z} χz是一个分段函数,将距离映射到[0,1]之间的值,如下所示:
χ z ( h ) = min [ max [ 1 R ( R + z − h ) , 0 ] , 1 ] , ( 7 ) \chi_z(h)=\min\left[\max\left[\frac1R(R+z-h),0\right],1\right],\quad(7) χz(h)=min[max[R1(R+z−h),0],1],(7)
其中 h h h表示当前视频中的第 t t t帧与过去时间范围内第 r r r ( r ∈ [ 1 , t − 1 ] ) (r\in[1,t-1]) (r∈[1,t−1])帧之间的距离。 R R R是一个用于控制softness的超参数。 z z z是一个可学习的参数,随着输入自适应调整如下:
z = F σ ( C ⊤ X + b ) , z=F\sigma(C^\top X+b), z=Fσ(C⊤X+b),(8)
其中σ表示sigmoid运算, C C C和 b b b是模型训练时的可学习参数。利用软掩码函数 χ z \chi_{z} χz,在该掩码内计算相应的注意权值 ω t , r \omega_{t,r} ωt,r,即
ω t , r = χ z ( t − r ) exp ( β t , r ) ∑ q = 1 t − 1 χ z ( t − q ) exp ( β t , q ) , \omega_{t,r}=\frac{\chi_z(t-r)\exp(\beta_{t,r})}{\sum_{q=1}^{t-1}\chi_z(t-q)\exp(\beta_{t,q})}, ωt,r=∑q=1t−1χz(t−q)exp(βt,q)χz(t−r)exp(βt,r),(9)
这里 β t , r \beta_{t,r} βt,r表示视频中第 t t t帧对应的Query与过去第 r r r帧对应的Key的点积输出。在 χ z \chi_{z} χz的控制下,自注意力头能够根据输入自适应调整自注意力广度。
最后,将时间上下文自适应学习后的视频特征输入到分类器中,预测帧级异常分数 { η i , j } j = 1 F \{\eta_{i,j}\}_{j=1}^{F} {ηi,j}j=1F。
5、Objective Function
首先,我们微调CLIP文本编码器。对于一个正常视频,我们进一步计算了其他k−1个异常事件的描述文本与正常帧之间的匹配相似度集 φ i n a = { S i , τ n a = X i n ( T τ a ) ⊤ ∣ 1 ⩽ τ ⩽ k − 1 } \varphi_i^{na}=\{S_{i,\tau}^{na}=X_{i}^{n}(T_{\tau}^{a})^{\top}|1\leqslant\tau\leqslant k-1\} φina={Si,τna=Xin(Tτa)⊤∣1⩽τ⩽k−1}。我们期望相似性集 φ i n a \varphi_i^{na} φina中的最大值尽可能小,而相似性集 S i , k n n S_{i,k}^{nn} Si,knn中的最大值尽可能大。因此,我们设计约束的排序损失如下:
L r a n k n = max ( 0 , 1 − max ( S i , k n n ) + max ( max ( φ i n a ) ) . ( 10 ) L_{rank}^n=\max(0,1-\max(S_{i,k}^{nn})+\max(\max(\varphi_i^{na})).(10) Lrankn=max(0,1−max(Si,knn)+max(max(φina)).(10)
对于一个异常视频,我们首先计算正常事件描述文本嵌入与异常视频特征之间的相似度 S i , k a n = X i a ( T ˙ k n ) ⊤ S_{i,k}^{an}=X_i^a(\dot{T}_k^n)^\top Si,kan=Xia(T˙kn)⊤,第 τ \tau τ ( 1 ⩽ τ ⩽ k − 1 ) (1\leqslant\tau\leqslant k-1) (1⩽τ⩽k−1)个真实异常事件类别描述文本嵌入与异常视频特征之间的相似度 S i , τ a a = X i a ( T τ a ) ⊤ S_{i,\tau}^{aa}=X_i^a(T_\tau^a)^\top Si,τaa=Xia(Tτa)⊤,以及其他k−2个异常事件类别的描述文本嵌入与异常视频特征之间的相似度集 φ i a a = { S i , g a a = X i a ( T g a ) ∣ ∣ 1 ⩽ g ⩽ k − 1 , g ≠ τ } \varphi_{i}^{aa}=\{S_{i,g}^{aa}=X_{i}^{a}(T_{g}^{a})^{|}|1\leqslant g\leqslant k-1,g\neq\tau\} φiaa={Si,gaa=Xia(Tga)∣∣1⩽g⩽k−1,g=τ}。我们期望 S i , k a n S_{i,k}^{an} Si,kan的最大值应该大于 φ i a a \varphi_{i}^{aa} φiaa的最大值。同样, S i , τ a a S_{i,\tau}^{aa} Si,τaa的最大值应大于 φ i a a \varphi_{i}^{aa} φiaa的最大值。简而言之,就是我们期望真实的异常事件和正常事件的描述文本分别以尽可能高的相似度与异常视频中的异常帧和正常帧相匹配。因此,异常视频的排名损失设计如下:
L r a n k a = max ( 0 , 1 − max ( S i , k a n ) + max ( max ( φ i a a ) ) ) + max ( 0 , 1 − max ( S i , τ a a ) + max ( max ( φ i a a ) ) ) . \begin{array}{c}L_{rank}^a=\max(0,1-\max(S_{i,k}^{an})+\max(\max(\varphi_i^{aa})))+\\\max(0,1-\max(S_{i,\tau}^{aa})+\max(\max(\varphi_i^{aa}))).\end{array} Lranka=max(0,1−max(Si,kan)+max(max(φiaa)))+max(0,1−max(Si,τaa)+max(max(φiaa))).(11)
此外,为了进一步保证真实异常事件和正常事件的描述文本能够分别准确对齐异常视频中的异常和正常视频帧,我们设计了分布不一致损失(DIL)。DIL用于约束真实异常事件描述文本与视频帧之间的相似度,使其与正常事件描述文本与视频帧之间的相似度分布不一致。我们使用余弦相似度来执行这个损失:
L d i l = 1 M F ∑ i = 1 M ∑ j = 1 F S ~ i , j , τ a a ⋅ S ~ i , j , k a n ∥ S ~ i , j , τ a a ∥ 2 ⋅ ∥ S ~ i , j , k a n ∥ 2 . ( 12 ) L_{dil}=\frac{1}{MF}\sum_{i=1}^{M}\sum_{j=1}^{F}\frac{\tilde{S}_{i,j,\tau}^{aa}\cdot\tilde{S}_{i,j,k}^{an}}{\left\|\tilde{S}_{i,j,\tau}^{aa}\right\|_{2}\cdot\left\|\tilde{S}_{i,j,k}^{an}\right\|_{2}}.\quad(12) Ldil=MF1∑i=1M∑j=1F∥S~i,j,τaa∥2⋅∥S~i,j,kan∥2S~i,j,τaa⋅S~i,j,kan.(12)
然后,在工作[26]之后,为了使生成的伪标签在时间顺序上满足稀疏性和平滑性,我们对相似向量 S ~ i , τ a a \tilde{S}_{i,\tau}^{aa} S~i,τaa施加稀疏性和平滑性约束 L s p = ∑ j = 1 F ( S ~ i , j , τ a a − S ~ i , j + 1 , τ a a ) 2 , L s m = ∑ j = 1 F S ~ i , j , τ a a L_{sp}=\sum_{j=1}^{F}\left(\tilde{S}_{i,j,\tau}^{aa}-\tilde{S}_{i,j+1,\tau}^{aa}\right)^{2},L_{sm}=\sum_{j=1}^{F}\tilde{S}_{i,j,\tau}^{aa} Lsp=∑j=1F(S~i,j,τaa−S~i,j+1,τaa)2,Lsm=∑j=1FS~i,j,τaa。
然后,我们计算分类器预测的异常分数 η i , j \eta_{i,j} ηi,j与伪标签 γ i , j \gamma_{i,j} γi,j之间的二元交叉熵作为分类损失:
L c l = − 1 M F ∑ i = 1 M ∑ j = 1 F [ η i , j log ( γ i , j ) + ( 1 − η i , j ) log ( 1 − γ i , j ) ] . L_{cl}=-\frac{1}{MF}\sum_{i=1}^{M}\sum_{j=1}^{F}[\eta_{i,j}\log(\gamma_{i,j})+(1-\eta_{i,j})\log(1-\gamma_{i,j})]. Lcl=−MF1∑i=1M∑j=1F[ηi,jlog(γi,j)+(1−ηi,j)log(1−γi,j)].(13)
经λ1和λ2平衡后的最终总体目标函数设计如下:
L a l l = L r a n k n + L r a n k a + L d i l + L c l + λ 1 L s p + λ 2 L s m . (14) L_{all}=L_{rank}^n+L_{rank}^a+L_{dil}+L_{cl}+\lambda_1L_{sp}+\lambda_2L_{sm}.\text{(14)} Lall=Lrankn+Lranka+Ldil+Lcl+λ1Lsp+λ2Lsm.(14)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









