







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
在 Java 中,文件的输入和输出是通过流(Stream)来实现的,流的概念源于 UNIX 中管道(pipe)的概念。在 UNIX 系统中,管道是一条不间断的字节流,用来实现程序或进程间的通信,或读写外围设备、外部文件等。
一个流,必有源端和目的端,它们可以是计算机内存的某些区域,也可以是磁盘文件,甚至可以是 Internet 上的某个 URL。对于流而言,不用关心数据是如何传输的,只需要从源端输入数据(读),向目的端输出数据(写)。
一、File类
常用方法及作用
/**
* /**
* File类的使用:
* -File类的一个对象,代表一个文件或一个文件目录(俗称文件夹)
* —File类声明在java.io包下
* -相对路径:相较于某个路径下,指明的路径
* -绝对路径:包含盘符在内的文件或文件目录的路径
* 路径分隔符和系统有关:
* -windows和Dos系统默认使用"“来表示
* -UNIX和URl使用”/"来表示
* 如何创建File类的实例:
* File(String filePath)
* File(String parentPath,String childPath)
* File(File parentFile,String childPath)
* File类中涉及到关于文件或目录的创建,删除,重命名,修改时间,文件大小等方法,并未涉及到写入或读取文件内容的操作。
* 如果需要读取写入文件内容,必须使用IO流来完成
*
* 后续File类的对象常会作为对象,传入到流的构造器中,指明读取或写入的终点。
*
* 注意:
* IDEA:如果使用单元测试方法,相对路径基于当前moudle
* 如果使用main方法,相对路径基于当前工程
* Eclipse:不管是单元测试方法还是main方法,相对路径都是基于当前工程
*/
* public String getAbsolutePath():获取绝对路径
* public String getpath():获取路径
* public String getName():获取名称
* public String getParent():获取上层文件目录路径,若无,返回null
* public long length():获取文件长度(即:字节数)不能获取目录的长度
* public long lastModified():获取最后一次修改文件的时间,毫秒值
* 如下两个方法适用于文件目录:
* public String[] list():获取指定目录下的所有文件或者文件目录的名称的数组
* public File[] listFiles():获取指定目录下的所有文件或者文件目录的File数组(返回以绝对路径的方式)
*
* public boolean isDirectory():判断是否是文件目录
* public boolean isFile():判断是否为文件
* public boolean exists():判断是否存在
* public boolean canRead():判断是否可读
* public boolean canWrite():判断是否可写
* public boolean isHidden():判断是否可隐藏
*
* 创建硬盘中对应的文件或文件目录
* File类的创建功能:
* 上层目录指的是多个目录,不止一个
* public boolean createNewFile():创建文件,若文件存在,则不创建,返回false
* public boolean mkdir():创建文件目录,如果此文件目录存在,就不创建,如果此文件目录的上层目录不存在,也不创建
* public boolean mkdirs():创建文件目录,如果上层文件目录不存在,则一并创建
* 注意:如果创建的文件或者文件目录没有写盘符路径,那么默认在相对路径下
* 删除磁盘中对应的文件或者文件目录
* File类的删除功能:
* public boolean delete():删除文件或者文件夹(要想删除成功,其当前文件不能有子目录或者文件)
* 注意:java中的删除不走回收站,要删除一个文件目录,请注意该文件目录内不能包含文件或者文件目录
*/
案例:
1.递归删除指定目录下的所有文件
package IO;
import java.io.File;
import java.util.Scanner;
public class Test {
public static void del(File file){
File[] listFiles = file.listFiles();//找出当前文件夹下的所有文件和文件加
if(listFiles != null) {
for (File f : listFiles) {
//判断当前文件是文件夹还是文件,如果是文件则删除,否则,接着递归,找出所有的文件然后删除。
if(f.isDirectory()){
if(f == null){
f.delete();
continue;
}
del(f);
}
f.delete();
}
}
}
public static void main(String[] args) {
System.out.println("请输入一个目录(删除所有的文件):");
String s = new Scanner(System.in).nextLine();
del(new File(s));
}
}
2.找出指定磁盘下后缀为.java的文件(递归)
package IO;
import java.io.File;
import java.util.Scanner;
public class Test {
public static void find(File file){
File[] list = file.listFiles();
if(list != null) {
for (int i = 0; i < list.length; i++) {
if (list[i].isFile()) {
String s = list[i].getName();//获取文件名
if (s.endsWith(".java")) {//判断是否以.java结尾
System.out.println(s);
}
}
find(list[i]);
}
}
}
public static void main(String[] args) {
String s = new Scanner(System.in).nextLine();
find(new File(s));
}
}
二、IO流介绍?
在 I/O 处理中,最常见的就是对文件的操作。java.io 包中所提供的文件操作类包括:
- 用于读写本地文件系统中的文件:FileInputStream 和 FileOutputStream
- 描述本地文件系统中的文件或目录:File、FileDescriptor 和 FilenameFilter
- 提供对本地文件系统中文件的随机访问支持:RandomAccessFile
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
流一般分为输入流(Input Stream)和输出流(Output Stream)两类,但这种划分并不是绝对的。比如一个文件,当向其中写数据时,它就是一个输出流;当从其中读取数据时,它就是一个输入流。当然,键盘只是一个输入流,而屏幕则只是一个输出流。(其实我们可以通过一个非常简单的方法来判断,只要是向内存中写入就是输入流,从内存中写出就是输出流)。
三、流的分类
- —操作数据单位:字节流,字符流
- —数据的流向:输入流,输出流
- —流的角色:节点流,处理流
1 .字节输入流输出流
案例:文件的复制,代码如下(示例):
@Test
public void test2() throws IOException {
//文件的复制(边读边写)
FileInputStream fileInputStream = new FileInputStream("d:/桌面/概念.txt");
FileOutputStream outputStream = new FileOutputStream("d:/桌面/概念copy.txt");
int len;
byte[] arr = new byte[1024];
while((len = fileInputStream.read(arr)) != -1){//读取文件
//向另一个文件中写入内容
outputStream.write(arr,0,len);
}
outputStream.close();
fileInputStream.close();
}
注意:
1.对于文本文件(.txt .java .c .cpp)使用字符流处理
2.对于非文本文件(.jpg .doc .mp3 .mp4 .avi .ppt…),使用字节流处理
3.对于文本文件,使用字节流可以复制,但是不能在复制的过程中查看,要想在控 制台层面查看,必须使用字符流
2.字符输入输出流
读取指定文件的几种方式:
@Test
public void test() {
//1.实例化File类的对象,指明要操作的文件
File file = new File("hello.txt");//相较于当前moudle下
//2.提供集体的流
FileReader f = null;
try{
f = new FileReader(file);
//3.数据的读入
//read():返回读入的一个字符,如果到达文件末尾返回-1
//说明:异常处理:为了保证流资源一定可以执行关闭操作,需要使用try - catch - finally结构
//读入的文件一定要存在,否则就会报FileNotFoundException的异常。
//方式一:
// int data = f.read();
// while(data != -1){
// System.out.print((char) data);
// data = f.read();
// }
//方式二:语法上的修改
int data;
while((data = f.read()) != -1){
System.out.println(data);
}}catch(IOException e){
e.printStackTrace();
}
//4.流的关闭操作
finally {
try {
if (f != null){
f.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
//对read()操作升级:使用read的重载方法
@Test
public void Test2(){
FileReader f = null;
try{
//1.File类的实例化
File file = new File("Test\\hehe.txt");
//2.FileReader流的实例化
f = new FileReader(file);
//3.读入的操作
//read(char cbuf):返回每次读入cbuf数组中的字符的个数,如果到达文件末尾返回-1
char[] arr = new char[5];
int len;
while((len = f.read(arr)) != -1){
//方式一:
// for(int i = 0;i < len;i++){
// System.out.print(arr[i]);
// }
//方式二:
String s = new String(arr, 0, len);
System.out.print(s);
}
}catch(IOException e){
e.printStackTrace();
}
//4.资源关闭
finally {
try {
if (f != null) {
f.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件的输出
/**
* 从内存中写出数据到硬盘的文件里
*
* 说明:
* 1.输出操作,对应的File可以不存在,如果不存在,在输出的过程中会自动创建此文件。
* 2.File对应的硬盘的文件如果存在:
如果流使用的构造器是:FileWriter(file,false)/FileWriter(file):就会覆盖掉原有的文件数据
* 如果流使用的构造器是:FileWriter(file,true):不会对原有文件内容覆盖,而是追加在该文件后面
*
*/
@Test
public void FileWriter(){
FileWriter fileWriter = null;
try {
//1.File类的实例化
File file = new File("Test\\hehe.txt");
//2.FileWriter流的实例化
// fileWriter = new FileWriter(file);
//表示追加的方式
fileWriter = new FileWriter(file,true);
//3.写出的操作
//方式一
// fileWriter.write("万物皆对象!!!");
//方式二
fileWriter.write("\n人生苦短,我爱Python".toCharArray());
//4.流资源的关闭
}catch(IOException e){
e.printStackTrace();
}finally {
try {
if(fileWriter != null) {
fileWriter.close();
}
}catch(IOException e){
e.getMessage();
}
}
}
write和read方法的几种重载说明
在 InputStream 类中,方法 read() 提供了三种从流中读数据的方法:
- int read():从输入流中读一个字节,形成一个 0~255 之间的整数返回(是一个抽象方法)。
- int read(byte b[]):从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
- int read(byte b[],int off,int len):从输入流中读取长度为 len 的数据,写入数组 b 中从索引 off 开始的位置,并返回读取得字节数。
对于这三个方法,若返回 -1,表明流结束,否则,返回实际读取的字符数。
OutputStream 类方法:
| 方法 | 说明 |
|---|---|
| write(int b)throws IOException | 将指定的字节写入此输出流(抽象方法) |
| write(byte b[])throws IOException | 将字节数组中的数据输出到流中 |
| write(byte b[], int off, int len)throws IOException | 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流 |
| flush()throws IOException | 刷新此输出流并强制写出所有缓冲的输出字节 |
| close()throws IOException | 关闭流 |
3.缓冲流
# 缓冲流的运行机制
- 类 BufferedInputStream 和 BufferedOutputStream 实现了带缓冲的过滤流,它提供了缓冲机制,把任意的 I/O 流“捆绑”到缓冲流上,可以提高 I/O 流的读取效率。
- 在初始化时,除了要指定所连接的 I/O 流之外,还可以指定缓冲区的大小。缺省时是用 32 字节大小的缓冲区;最优的缓冲区大小常依赖于主机操作系统、可使用的内存空间以及机器的配置等;一般缓冲区的大小为内存页或磁盘块等的整数倍。
- BufferedInputStream 的数据成员 buf 是一个位数组,默认为 2048 字节。当读取数据来源时例如文件,BufferedInputStream 会尽量将 buf 填满。当使用
read ()方法时,实际上是先读取 buf 中的数据,而不是直接对数据来源作读取。当 buf 中的数据不足时,BufferedInputStream 才会再实现给定的 InputStream 对象的 read() 方法,从指定的装置中提取数据。 - BufferedOutputStream 的数据成员 buf 是一个位数组,默认为 512 字节。当使用
write()方法写入数据时,实际上会先将数据写至 buf 中,当 buf 已满时才会实现给定的 OutputStream 对象的write()方法,将 buf 数据写至目的地,而不是每次都对目的地作写入的动作。
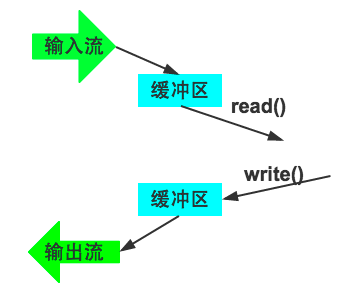
## 缓冲流的作用
- 处理流之一:缓冲流的使用
- 1.缓冲流:
-
BufferedInputStream -
BufferedOutputStream -
BufferedReader -
BufferedWriter - 2.作用:提高流的读取写入效率
- 速度提高的原因:内部提供了一个缓冲区
- 3.处理流,就是套接在已有的流的基础上
案例:使用缓冲流复制一段文本
//复制一段文本
@Test
public void test2(){
BufferedReader fr = null;
BufferedWriter fw = null;
try {
fr = new BufferedReader(new FileReader("hello.txt"));
fw = new BufferedWriter(new FileWriter("Test.txt"));
//方式一:
// char[] arr = new char[1024];
// int len;
// while ((len = fr.read(arr)) != -1) {
// fw.write(arr, 0, len);
// }
//方式二:readLine():表示读取一行,没有换行符,可以使用 newLine(),增加一个换行符
String data;
while((data = fr.readLine()) != null){
//方式一:
// fw.write(data + "\n");
//方式二:
fw.write(data);
fw.newLine();
}
System.out.println("复制成功!");
}catch(IOException e){
e.printStackTrace();
}finally{
if(fr != null){
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fw != null){
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
4.转换流
1.转换流:
InputStreamReader:将一个字节的输入流转换为字符的输入流
OutputStreamWriter:将一个字符的输出流,转换为字节的输出流
2.作用:提供字节流与字符流之间的转换
3.解码:字节,字节数组 —> 字符数组,字符串
编码:字符数组,字符串 —> 字节,字节数组
示例代码:
package com.example;
import org.junit.jupiter.api.Test;
import java.io.*;
import java.nio.charset.StandardCharsets;
public class HandleTest {
@Test
public void test() throws Exception {
//将字符流转换成字节流输出
}
public static void main(String[] args) throws Exception {
File file = new File("D:\\桌面\\文件.txt");
//以字节流的方式读入
FileInputStream inputStream = new FileInputStream(file);
//将字节流转换成字符流,同时设置字符集,以防止出现乱码
InputStreamReader inputStreamReader = new InputStreamReader(inputStream, StandardCharsets.UTF_8);
//将字符流转换成字节流保存到text.txt文件中
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream("d:/桌面/text.txt"), StandardCharsets.UTF_8);
char[] arr = new char[1024];
int len;
while((len = inputStreamReader.read(arr)) != -1){
String s = new String(arr, 0, len);
//输出到控制台
System.out.println(s);
//同时将文件内容写到text.txt中
outputStreamWriter.write(arr,0,len);
}
//刷新缓冲区,关闭文件
outputStreamWriter.close();
inputStreamReader.close();
}
}
5.数据流
- 为了方便的操作java语言的基本数据类型和String类型数据,可以使用数据流。
数据流有两个类,用于读取和写出基本数据类型,String类型的数据。 - DataInputStream和DataOutputStream分别套接在InputStream和OutPutStream子类的流上。
- 方法:
boolean readBoolean()
char readChar()
double readDouble()
long readLong()
String readUTF()
byte readByte()
float readFloat()
short readShort()
int readInt()
void readFully(byte[] b)
DataOutPutStream中的方法只需要把read改为write即可。
示例代码:
package com.example;
import java.io.*;
public class DataTest {
public static void main(String[] args) throws IOException {
DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("d:/桌面/数据流.txt"));
//写入基本数据类型
dataOutputStream.writeInt(1);
dataOutputStream.writeDouble(1.1);
//写入字符串
dataOutputStream.writeUTF("人生苦短");
//关闭流
dataOutputStream.close();
//读取该文件,注意要按顺序读取,否则会出现错误
DataInputStream dataInputStream = new DataInputStream(new FileInputStream("d:/桌面/数据流.txt"));
int i = dataInputStream.readInt();
System.out.println(i);
double v = dataInputStream.readDouble();
System.out.println(v);
String s = dataInputStream.readUTF();
System.out.println(s);
}
}
6. 对象流
/**
- 对象流的使用:
- 1.ObjectInputStream 和 ObjectOutputStream
- 2.作用:用于存储和读取基本数据类型和对象的处理流。它的强大之处在于可以把java中的对象写入到数据源中,也能把对象从数据源中还原回来
- 3.要想一个java对象是可序列化的,需要满足的要求,见Person.java
- 注意:凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量:private static final long serialVersionUID,
- 如果类没有显示定义这个静态变量,它的值是java运行时环境根据类的内部细节自动生成的,若类的实例变量作了修改,serialVersionUID可能发生变化,所以建议显示赋值
- ObjectInputStream 和 ObjectOutputStream不能序列化static和transient修饰的成员变量
*/
## 示例代码:
public class ObjectInputOutputTest {
/**
* 序列化过程:将内存中的java对象保存到磁盘中或通过网络传输出去,使用ObjectOutputStream实现
*
*/
@Test
public void test1(){
ObjectOutputStream ops = null;
try {
ops = new ObjectOutputStream(new FileOutputStream("Object.dat"));
ops.writeObject(new String("hello world"));
ops.flush();
ops.writeObject(new Person("laowang",15));
ops.flush();
ops.writeObject(new Person("xiaoming",24,new Account(15)));
System.out.println("存储成功");
}catch(IOException e){
e.printStackTrace();
}finally {
if(ops != null){
try {
ops.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 反序列化过程:将磁盘中的java对象输出到内存的层面,使用ObjectInputStream实现
*/
@Test
public void test2(){
ObjectInputStream fr = null;
try{
fr = new ObjectInputStream(new FileInputStream("Object.dat"));
Object str = fr.readObject();
System.out.println((String) str);
System.out.println((Person)fr.readObject());
System.out.println((Person)fr.readObject());
}catch (IOException e){
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
## ```对自定义类使用序列化和反序列化
```java
package IO;
import java.io.Serializable;
/**
* person类需要满足以下要求,方可序列化
* 1.需要实现serializable接口
* 2.需要当前类提供一个常量:serialVersionUID
* 3.除了当前类需要实现Seriavalizable接口之外,还必须保证其内部所有属性也必须是可序列化的。(默认情况下基本数据类型可序列化)
*/
public class Person implements Serializable {
private String name;
private int age;
private Account count;
//序列版本号
public static final long serialVersionUID = 4651365245l;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public Person() {
}
public Person(String name, int age, Account count) {
this.name = name;
this.age = age;
this.count = count;
}
}
class Account implements Serializable{
public static final long serialVersionUID = 13511531l;
int banlance;
public Account(int banlance){
this.banlance = banlance;
}
public static long getSerialVersionUID() {
return serialVersionUID;
}
public int getBanlance() {
return banlance;
}
public void setBanlance(int banlance) {
this.banlance = banlance;
}
@Override
public String toString() {
return "Account{" +
"banlance=" + banlance +
'}';
}
}
序列化和反序列化
- 序列化就是在保存数据时,保存数据的值和数据类型
- 反序列化就是在恢复数据时,恢复数据的值和数据类型
- 需要让某个对象支持序列化机制,则必须让其类是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一:
- Serializable//这是一个标记接口
- Externalizable//,一般使用上边的接口
- 序列化的类中建议添加 SerialVersionUID,为了提高版本的兼容性
- 序列化对象时,默认将里面所有属性都进行序列化,但除了static或transient修饰的成员
- 序列化对象时,要求里面属性的类型也需要实现序列化接口
- 序列化具备可继承性,也就是如果某类已经实现了序列化,则它的所有子类也已经默认实现了序列化















 1287
1287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









