







 本文介绍了组lasso的概念及其在逻辑回归中的应用,详细讨论了正交化问题和坐标下降法。针对组lasso求解速度慢的问题,提出了快速解法,包括MM算法优化。还分享了在R中实现group lasso的grplasso包及其优化技巧,如active set和warm start策略。
本文介绍了组lasso的概念及其在逻辑回归中的应用,详细讨论了正交化问题和坐标下降法。针对组lasso求解速度慢的问题,提出了快速解法,包括MM算法优化。还分享了在R中实现group lasso的grplasso包及其优化技巧,如active set和warm start策略。
一、引言
在现实生活中,协变量之间存在一些组结构,那么在进行变量选择时都应该同时选入模型中。
例1:在分类数据中,我们通常处理方式是将其变成哑变量。如地域:江苏、浙江、上海。这时需要设置2个哑变量(n-1,n=3)。“地域(1)”=1,浙江;0,非浙江。“地域(2”)=1,上海;0,非上海。从而得到:
江苏= 0 ,0;
浙江 =1, 0;
上海 =0 ,1。
在变量选择时候,我们将其归为一个组。即会同时选进来,同时剔除。
例2:在多项式模型中,如:针对x变量采用多项式 αX2+βX 去拟合,则这两项可以认为是一个组,即有着同时选进来同时剔除的特点。
二、group lasso
Yuan在2006年将lasso方法推广到group上面,诞生了group lasso。形式如下:
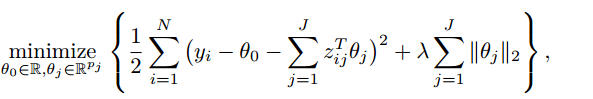
针对含有组的回归方程,加上L1的组惩罚。其中在运算前,我们对定义的组变量 xj 进行正交标准化。简单提一下,多篇论文对正交标准化有着探讨。因为将 xj 正交后,变量形式有所改变,对其估计得到的 beta 也会有影响。
对于 xj 的标准正交基,我们可以利用Gram-Schmidt算法形式进行计算,也可以用其推广形式QR分解。如果矩阵 xj 非奇异,那么QR分解唯一,Q为列正交矩阵。由此可知,分类数据哑变量的矩阵是奇异矩阵,其标准正交基形式多样,这就会导致不一样的计算结果。Kim利用谱分解的方法重新定义得到标准正交基。
参见grplasso包中的代码:
blockstand <- function(x, ipen.which, inotpen.which)
{
n <- nrow(x)
x.ort <- x
scale.pen <- list(); length(scale.pen) <- length(ipen.which)
scale.notpen <- NULL
if(length(inotpen.which) > 0){
one <- rep(1, n)
scale.notpen <- sqrt(drop(one %*% (x[,inotpen.which]^2)) / n)
x.ort[,inotpen.which] <- scale(x[,inotpen.which], FALSE, scale.notpen)
}
for(j in 1:length(ipen.which)){
ind <- ipen.which[[j]]
decomp <- qr(x[,ind])
if(decomp$rank < length(ind)) ## Warn if block has not full rank
stop("Block belonging to columns ", paste(ind, collapse = ", "),
" has not full rank! \n")
scale.pen[[j]] <- qr.R(decomp) * 1 / sqrt(n)
x.ort[,ind] <- qr.Q(decomp) * sqrt(n)
}
list(x = x.ort, scale.pen = scale.pen, scale.notpen = scale.notpen)
} 针对上述提到的正交化问题,Friedman提出了sparse group lasso。这里不深入探讨。
在进行参数估计之后,我们需要将参数转化为原始数据中。
Yuan在求解group lasso问题中参考FU(1998)年的针对lasso的求解提出shooting算法,求解得到待估参数的解析解,形式如下:
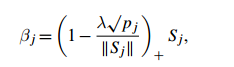
推导过程如下:
Xtj(Y−Xβ−j−Xjβj)+λβjpj√
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









