









import requests
import re
import queue
import threading
import time
Headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
# 获取斗图网图片的url 并放入队列中
def get_detail_url(url,queue):
r = requests.get(url,headers=Headers)
img_urls = re.findall(r'<img src=.*?data-original="([^"]*)',r.text)
img_names = re.findall(r'<img src=.*?alt="([^"]*)',r.text)
for i in zip(img_names,img_urls):
queue.put(i)
# 从队列中获取url,下载图片
def download_img(queue):
global Headers
while True:
if queue.empty():
break
img_info = queue.get()
r = requests.get(img_info[1],headers = Headers)
filename = img_info[0]
filename = re.sub(r'[,。?\.!!?]*','',filename)
with open("images/{}.jpg".format(filename),'wb') as fp:
fp.write(r.content)
def main():
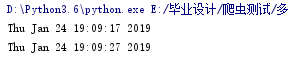
print(time.ctime())
imgs_queue = queue.Queue(1000) # 创建一个存放img相关信息的队列
get_imgurl_thread = [] # 存放获取图片url的线程
download_thread = [] # 存放下载图片线程的列表
urls = "https://www.doutula.com/photo/list/?page={}"
# 创建获取img相关信息的线程
for i in range(1,6):
t = threading.Thread(target = get_detail_url,args = (urls.format(i),imgs_queue))
get_imgurl_thread.append(t)
# 启动线程获取img相关信息
for i in range(0,5):
get_imgurl_thread[i].start()
time.sleep(3)
# 创建下载的线程放入列表中
for i in range(0,5):
t = threading.Thread(target=download_img,args=(imgs_queue,))
download_thread.append(t)
# 启动线程下载
for i in range(0,5):
download_thread[i].start()
# 阻塞不往下走,直至线程下载完成
for i in range(0, 5):
download_thread[i].join()
print(time.ctime())
if __name__ == '__main__':
main()
单线程下载要40s所有,换成多线程之后,基本10s就能解决。可以说 很牛x。。。。














 5730
5730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









